linux
微信小程序
maven
音视频
gazebo
位置编码
Hash
flink 最后一个窗口
产品设计误区
ReentrantLock
Documents PDF
File的创建功能
材料计算
简便轻巧的UML流程图制作工具
数据治理
创客DIY
CSDN
应力强度因子
轮廓绘制
react
文本分类
2024/4/12 0:04:54
文本分类 之 词向量平均模型 Word Average Model
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw 代码请参考:文本分类
第一个最…
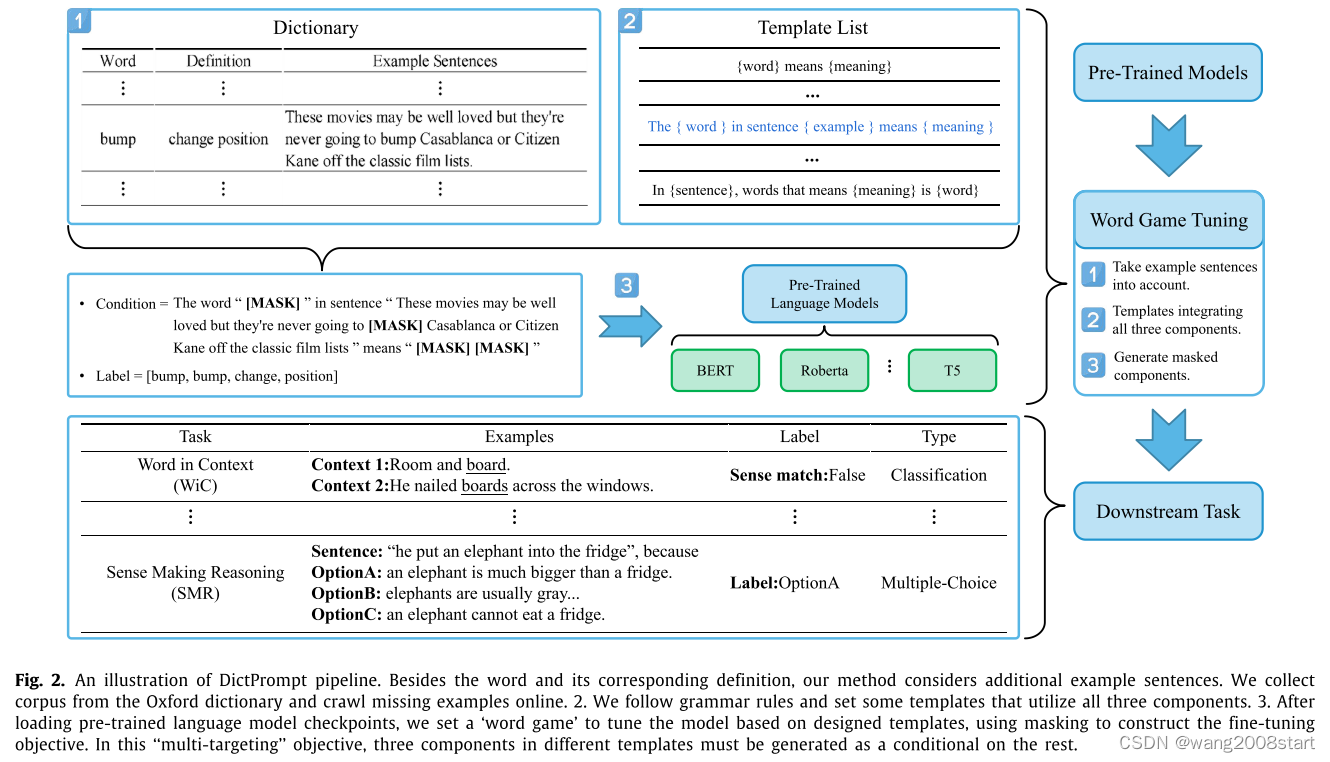
基于Prompt Learning的信息抽取
PTR: Prompt Tuning with Rules for Text Classification
清华;liuzhiyuan;通过规则制定subpromptRelation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning Relation Extraction as Open-book Examination: Retrieval-enhance…
文本分类之 residual-connection+selfAttention的词向量平均模型
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw 代码请参考:文本分类 和博客co…

TextCNN文本分类实践
CNN介绍
CNN是特殊的全连接层,包含两个特性:平移不变性和只和周边位置相关
CNN用于处理图像,也可以处理文本和语音,处理图像时,基础的CNN不能解决旋转和放大缩小问题,因为神经网络输入是一行像素转换成向…
文本分类 之 带有selfAttention的词向量平均模型
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw 代码请参考:文本分类
文本分类…
文本分类概述(nlp)
文本分类问题: 给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个 文本分类应用: 常见的有垃圾邮件识别,情感分析 文本分类方向: 主要有二分类,多分类,多标签…
文本分类 之 有Attention的词向量平均模型 Word Average Model with Attention
这是一个文本分类的系列专题,将采用不同的方法有简单到复杂实现文本分类。 使用Stanford sentiment treebank 电影评论数据集 (Socher et al. 2013). 数据集可以从这里下载 链接:数据集 提取码:yeqw
本文的方法是在WordAverageModel的基础上…


自然语言处理工具pyhanlp分词与词性标注
Pyhanlp分词与词性标注的相关内容记得此前是有分享过的。可能时间太久记不太清楚了。以下文章是分享自“baiziyu”所写(小部分内容有修改),供大家学习参考之用。
简介
pyhanlp是HanLP的Python接口。因此后续所有关于pyhanlp的文章中也会写成…
深度学习之----TextCNN文本分类
1.卷积神经网络
英文名称:(Convolutional Neural Network),简称CNN。由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC。是深度学习技术中极具代表的网络结构之一,最早应用在图像处理当中࿰…
文本分类心得(Bert模型使用)
正式入职了一段时间,接手了NLP相关任务,作为一个初学者,分享一点最近的所学心得和体会。
稍后有时间更新,现在项目催的很紧,能力比较强的可以找我内推阿里秋招。可以私信我联系方法,个人会进行第一遍简历筛…

【NLP+机器学习】实现对评论的情感倾向分析,预测,评估
前言
对文本的情感分析采用了两种思路——文本分类和文本聚类
有监督的学习无监督的学习训练集包括输入和由人工标注的输出(x,y)其训练集没有人为标注的输出(x)分类(classify)聚类(…

Python数据分析案例33——新闻文本主题多分类(Transformer, 组合模型) 模型保存
案例背景
对于海量的新闻,我们可能需要进行文本的分类。模型构建很重要,现在对于自然语言处理基本都是神经网络的方法了。
本次这里正好有一组质量特别高的新闻数据,涉及 教育 科技 社会 时政 财经 房产 家居 七大主题,基本涵盖…
【2023】数据挖掘课程设计:基于TF-IDF的文本分类
目录
一、课程设计题目 基于TF-IDF的文本分类
二、课程设计设置
1. 操作系统
2. IDE
3. python
4. 相关的库
三、课程设计目标
1. 掌握数据预处理的方法,对训练集数据进行预处理;
2. 掌握文本分类建模的方法,对语料库的文档进行建模…
(10) 朴素贝叶斯
文章目录 1 概述2 不同分布下的贝叶斯2.1 高斯朴素贝叶斯GaussianNB2.1.1 认识高斯朴素贝叶斯2.1.2 探索贝叶斯:高斯朴素贝叶斯擅长的数据集2.1.3 探索贝叶斯:高斯朴素贝叶斯的拟合效果与运算速度 2.2 概率类模型的评估指标2.2.1 布里尔分数Brier Score2…

TensorFlow2实战-系列教程9:RNN文本分类1
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 1、文本分类任务
1.1 文本分类
数据集构建:影评数据集进行情感分析&…
对pytorch中的文本分类实例代码进行逐行注释
实例代码网址:https://pytorch.org/tutorials/beginner/text_sentiment_ngrams_tutorial.html
注意:代码适用于jupyter notebook分块运行
第一步、导入数据集并查看
import torch
from torchtext.datasets import AG_NEWS # 导入数据集train_iter i…

TensorFlow2实战-系列教程11:RNN文本分类3
🧡💛💚TensorFlow2实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Jupyter Notebook中进行 本篇文章配套的代码资源已经上传 6、构建训练数据
所有的输入样本必须都是相同shape(文本长度,…
项目记录与总结--理清思路
需要对推文来进行很好的过滤,在这里我主要考虑的是推文外部特征的过滤,需要知道到底有哪些外部特征,没有涉及到语义的那些特征。
判断的依据: 第一:推文单词数很少的时候,认为表述不清事件信息࿰…

《机器学习系统设计》之应用scikit-learn做文本分类(上)
前言: 本系列是在作者学习《机器学习系统设计》([美] WilliRichert)过程中的思考与实践,全书通过Python从数据处理,到特征工程,再到模型选择,把机器学习解决问题的过程一一呈现。书中设计的源代…

Document Modeling with Gated Recurrent Neural Network for Sentiment Classification 论文阅读笔记
Paper: Document Modeling with Gated Recurrent Neural Network for Sentiment Classification
Author: Duyu Tang, et al.
Publication: 2015, EMNLP.文章目录1 背景2 创新点3 核心方法3.1 句子表达3.2 文本表达3.3 情感分类4 实验4.1 实验设置4.2 实验结果1 背景
文本级别的…
基于python利用支持向量机实现中文文本分类(附完整代码)
准备好数据食材、去停用词并利用结巴**(jieba)进行分词处理** 数据食材选用参考:NLP中必不可少的语料资源 jieba分词模块参考官方文档啦~ # 本程序用于将搜狗语料库中的文本进行分词,并且去除停用词# coding=utf-8importjiebaimportjieba.possegaspsegimporttimeimportos
训…
如何用词向量做文本分类(embedding+cnn)
1、数据简介
本文使用的数据集是著名的”20 Newsgroup dataset”。该数据集共有20种新闻文本数据,我们将实现对该数据集的文本分类任务。数据集的说明和下载请参考(http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html…

大规模文本分类参考(转发)
前几天在网上看到了一个blog关于大规模文本分类的内容,在这里转发保存一下。
大规模文本分类实践-知乎看山杯总结 原文地址:http://coderskychen.cn/2017/08/20/zhihucup/ 本文主要介绍了我在知乎看山杯机器学习挑战赛中的一些实验和总结,代…

深度学习的文本多分类思维导图
此思维导图大部分整理自知乎用户https://zhuanlan.zhihu.com/p/25928551,有兴趣的可以看看原文,我把它整理成了这样一个框架,会比较好记忆理解一些,无实质工作,再次感谢知乎用户清淞的素材。
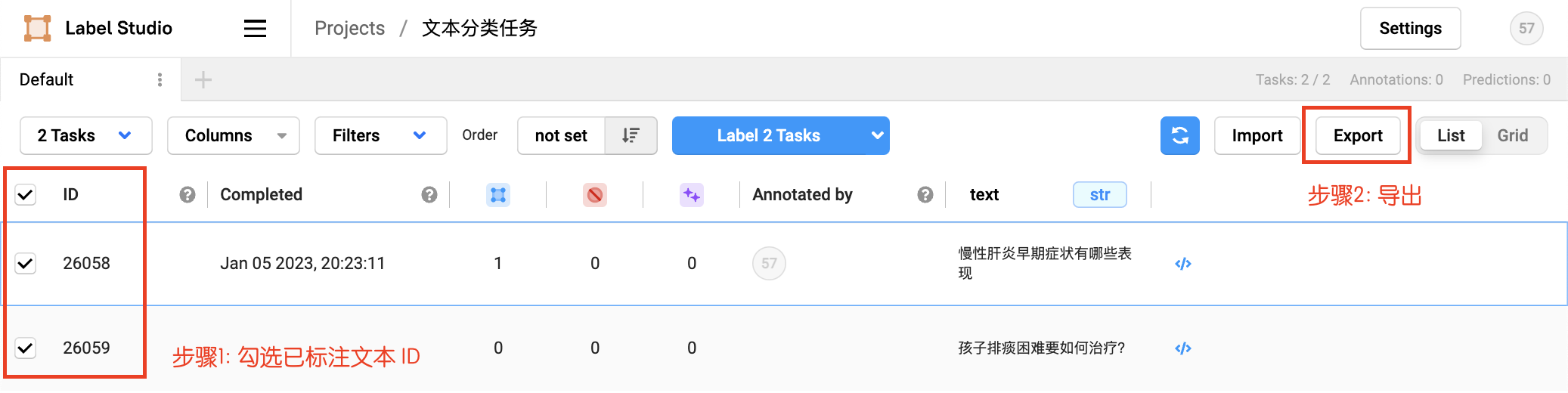
3.基于Label studio的训练数据标注指南:文本分类任务
文本分类任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…

【多标签文本分类】《采用平衡函数的大规模多标签文本分类》
阅读摘要: 使用最常见的BERTfc的多标签文本分类模型,只是改进了一下损失函数。 参考文献: [1] 陈钊鸿,洪智勇,余文华,张昕.采用平衡函数的大规模多标签文本分类[J/OL].计算机工程与应用:1-11[2023-04-02]. 参考论文信息 论文名称&…
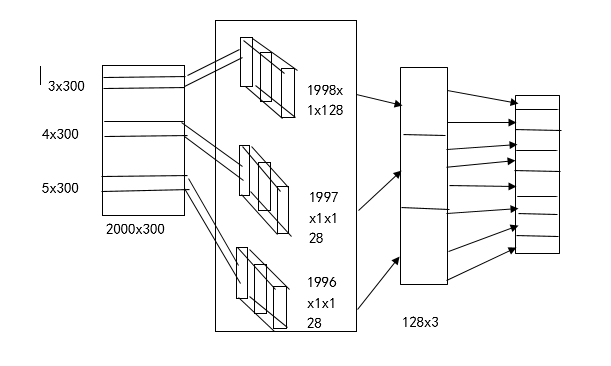
一张图帮你弄懂text-cnn
1、何为textcnn
利用卷积神经网络对文本进行分类的算法,那如何用卷积神经网络对文本进行分类呢。这里就tensorflow版本的textcnn源码分析一波。要知道,对文本向量化之后一般是一个一维向量来代表这个文本,但是卷积神经网络一般是对图像进行处理的&#x…
开源AI引擎:文本自动分类在公安及消防执法办案自动化中的应用
一、实际案例介绍
通过文本分类算法自动化处理文本数据,快速识别案件性质和关键特征,极大地提高了案件管理和分派的效率。本文将探讨这两种技术如何帮助执法机构优化资源分配,确保案件得到及时而恰当的处理,并增强公共安全管理的…
微调大型语言模型(LLM):应用案例示例
微调大型语言模型(LLM):应用案例示例
摘要: 本文讨论了大型语言模型(LLM)的微调,这是一种通过少量数据训练已经预训练好的模型以执行特定任务的过程。微调可以让LLM在翻译、文本分类、文本生成…
Bert文本聚类实践
问题来源:先做的huggingface-bert文本分类(参考text-classification,情感分类,数据集可以考虑SST2),但是数据量太大了,无法穷举所有的类别,故而先用分类来做,但这样也有一…

基于多种CNN模型在清华新闻语料分类效果上的对比
该实验项目目录如图: 1、 模型
1.1. TextCNN
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npclass Config(object):"""配置参数"""def __init__(self, dataset, embedd…
【AI实战】BERT 文本分类模型自动化部署之 dockerfile
【AI实战】BERT 文本分类模型自动化部署之 dockerfile BERTBERT 文本分类模型基于中文预训练bert的文本分类模型针对多分类模型的loss函数样本不均衡时多标签分类时 dockerfile编写 dockerfilebuild镜像运行docker测试服务 参考 本文主要介绍:
基于BERT的文本分类模…

PyTorch入门(五)使用CNN模型进行中文文本分类
本文将会介绍如何在PyTorch中使用CNN模型进行中文文本分类。 使用CNN实现中文文本分类的基本思路:
文本预处理将字(或token)进行汇总,形成字典文件,可保留前n个字文字转数字,不在字典文件中用表示对文…
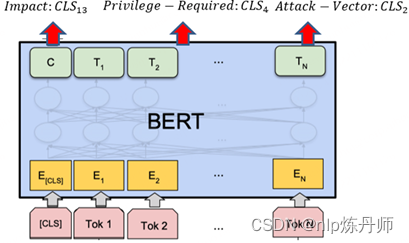
CCF大数据与计算智能大赛-基于人工智能的漏洞数据分类冠军方案
基于人工智能的漏洞数据分类
前言
为及时跟踪国际信息安全趋势,需对国际公开的漏洞数据内容进行及时统计和梳理,例如CVE漏洞平台。CVE平台的漏洞信息包含有CVE编号、漏洞评分、漏洞描述等内容,其中漏洞描述含有对漏洞的利用条件、受影响的范…
![[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)](https://img-blog.csdnimg.cn/direct/48f1bd6566364ab88ba1f5fb9cb9b583.png)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)
[自然语言处理|NLP] 文本分类与情感分析,数据预处理流程,包括了同义词替换和拼写纠正,以及使用NLTK库和TextBlob库进行标记化和情感分析(附代码)。
自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要分支,涉及了处理和理解人类语言的技术…

Pattern-Exploiting Training MLM任务用于文本匹配【代码解读】
一、总结 • 原文:
# PET-文本分类的又一种妙解:https://xv44586.github.io/2020/10/25/pet/
# ccf问答匹配比赛(下):如何只用“bert”夺冠:https://xv44586.github.io/2021/01/20/ccf-qa-2/三、代码注释
原始链接:h…
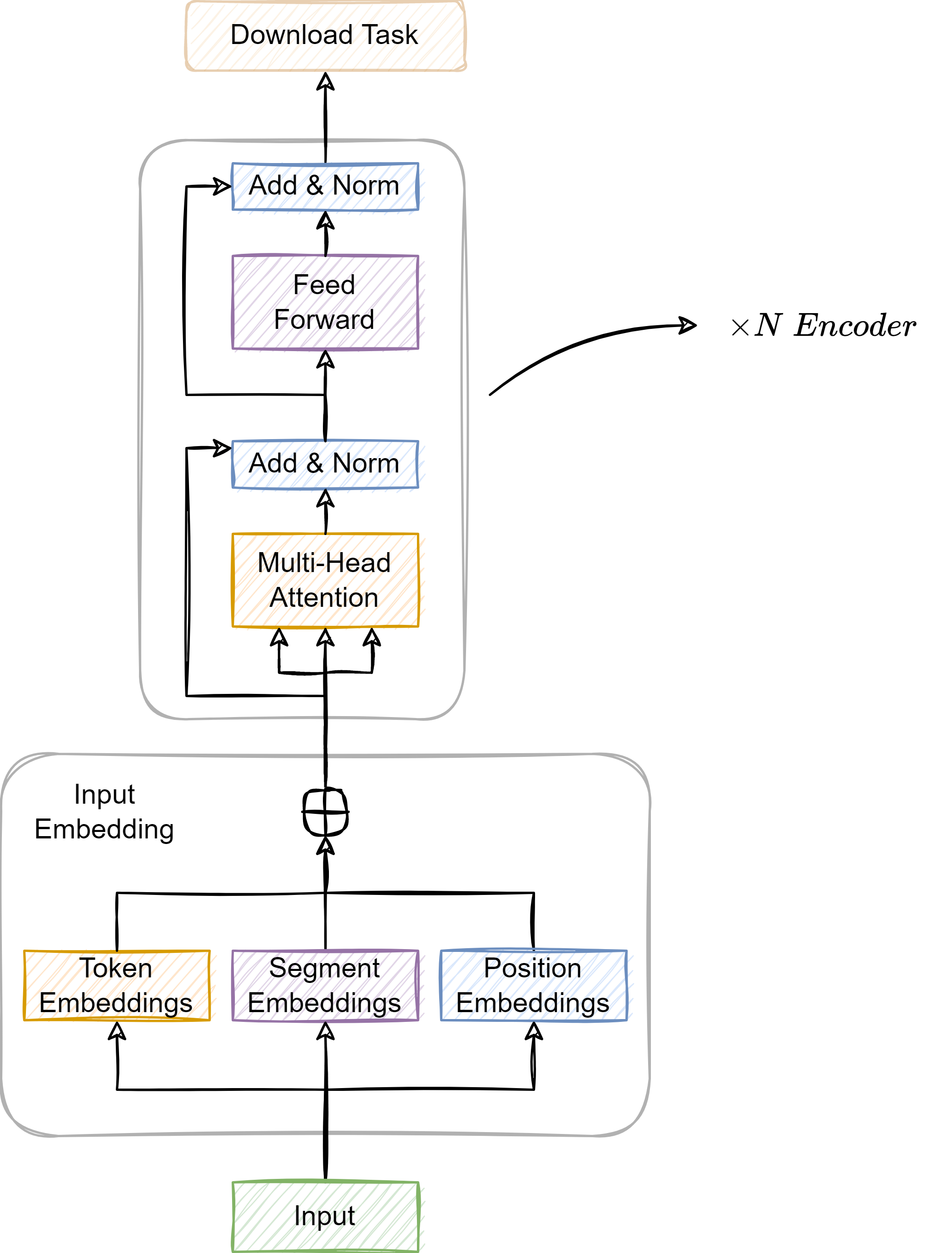
简洁高效的 NLP 入门指南: 200 行实现 Bert 文本分类 (Pytorch 版)
简洁高效的 NLP 入门指南: 100 行实现 Bert 文本分类 Pytorch 版 概述NLP 的不同任务Bert 概述MLM 任务 (Masked Language Modeling)TokenizeMLM 的工作原理为什么使用 MLM NSP 任务 (Next Sentence Prediction)NSP 任务的工作原理NSP 任务栗子NSP 任务的调整和局限性 安装和环…
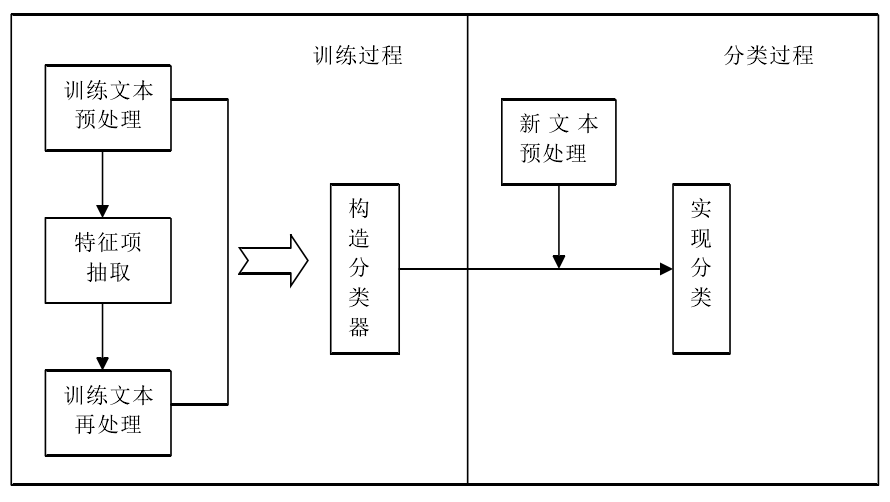
基于支持向量机SVM的文本分类的实现
基于支持向量机SVM的文本分类的实现
1 SVM简介 支持向量机(SVM)算法被认为是文本分类中效果较为优秀的一种方法,它是一种建立在统计学习理论基础上的机器学习方法。该算法基于结构风险最小化原理,将数据集合压缩到支持向量集合&a…
