antialias
内网穿透
测试用例
nlp
JUC
flink watermark
NPDP认证
html静态网页制作
C6678
论文写作
免费批量下载图片的插件
GcPDF
图像像素点测量温度
责任链模式
Linux运维脚本
金仓数据库
AO-RF
深度卷积神经网络
结构完整性
android 9
spider
2024/4/15 15:21:18
爬虫进阶:Scrapy 入门
进阶前言 学Py和写爬虫都有很长一段时间了,虽然工作方面主要还是做Java开发,但事实上用python写东西真的很爽。之前都是用RequestsBeautifulSoup这样的第三方库爬一些简单的网站,好处简单上手快,坏处也明显,单线程速度…
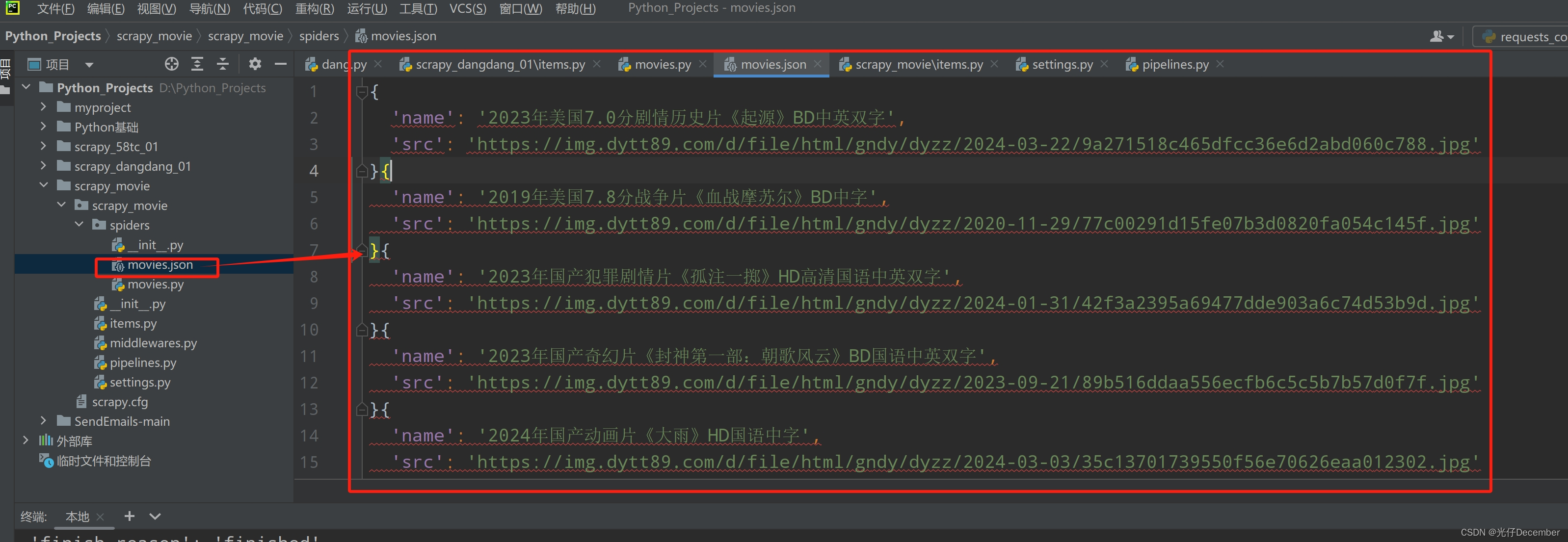
【Python从入门到进阶】51、电影天堂网站多页面下载实战
接上篇《50、当当网Scrapy项目实战(三)》 上一篇我们讲解了使用Scrapy框架在当当网抓取多页书籍数据的效果,本篇我们来抓取电影天堂网站的数据,同样采用Scrapy框架多页面下载的模式来实现。
一、抓取需求
打开电影天堂网站&…
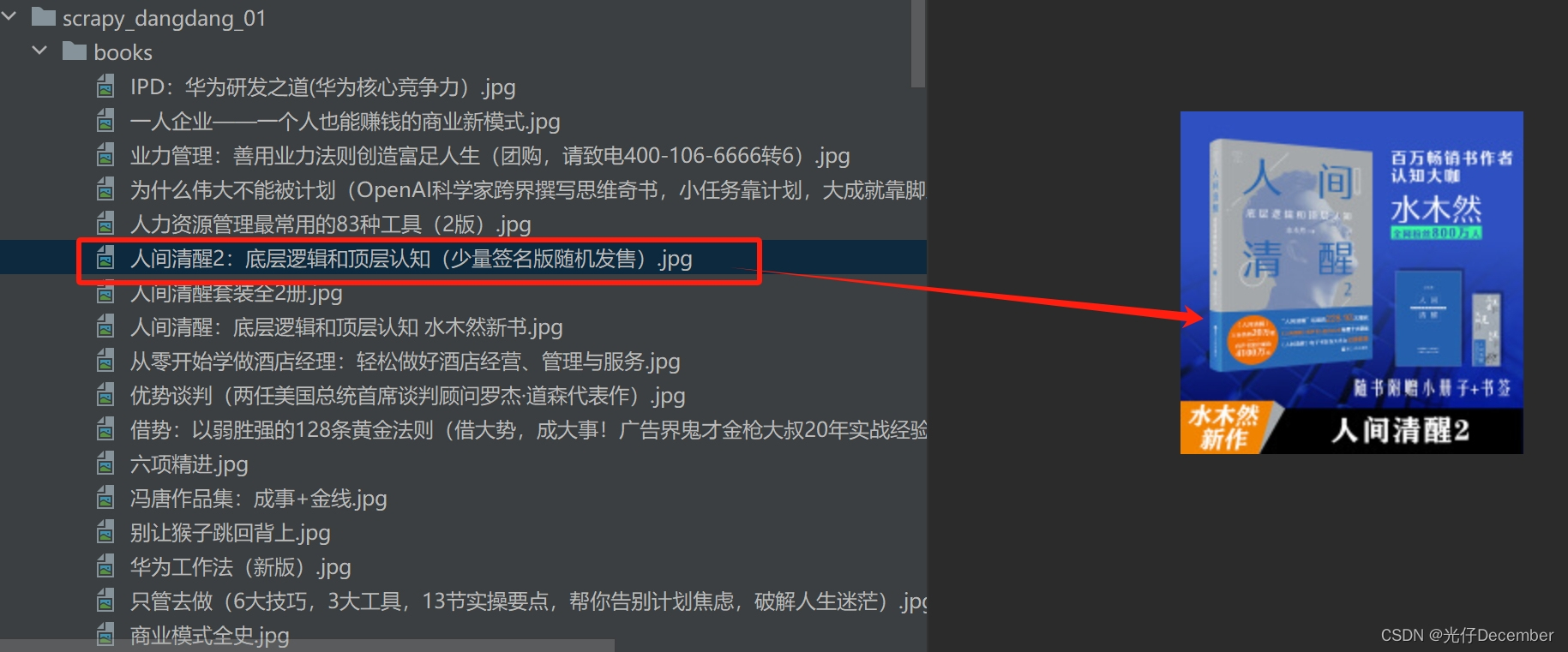
【Python从入门到进阶】49、当当网Scrapy项目实战(二)
接上篇《48、当当网Scrapy项目实战(一)》 上一篇我们正式开启了一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。本篇我们继续编写该当当网的项目,讲解刚刚编写的Spider与item之间的关系,以及如何使用itemÿ…
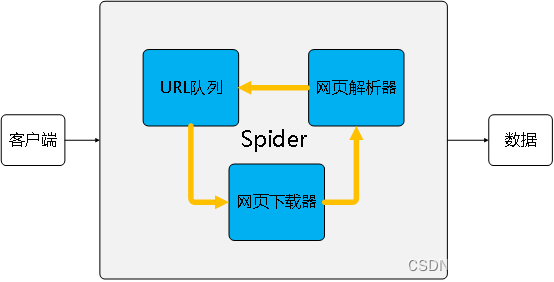
一文图解爬虫(spider)
—引导语 互联网(Internet)进化到今天,已然成为爬虫(Spider)编制的天下。从个体升级为组合、从组合联结为网络。因为有爬虫,我们可以更迅速地触达新鲜“网事”。 那么爬虫究竟如何工作的呢?允许…
【Python从入门到进阶】46、58同城Scrapy项目案例介绍
接上篇《45、Scrapy框架核心组件介绍》 上一篇我们学习了Scrapy框架的核心组件的使用。本篇我们进入实战第一篇,以58同城的Scrapy项目案例,结合实际再次巩固一下项目结构以及代码逻辑的用法。
一、案例网站介绍
58同城是一个生活服务类平台,…

11.Scrapy框架基础-使用Scrapy抓取数据并保存到mongodb
目录
一、Scrapy安装
1.mac系统
2.windows系统
二、使用scrapy爬取数据
1.新建一个scrapy工程
2.在spiders下新建一个爬虫文件
3.提取网页数据
三、保存数据到mongodb
四、再多学一点
1.添加请求头
2.Robot.txt设置
3.爬取多个页面
五、作业(这是一个考…
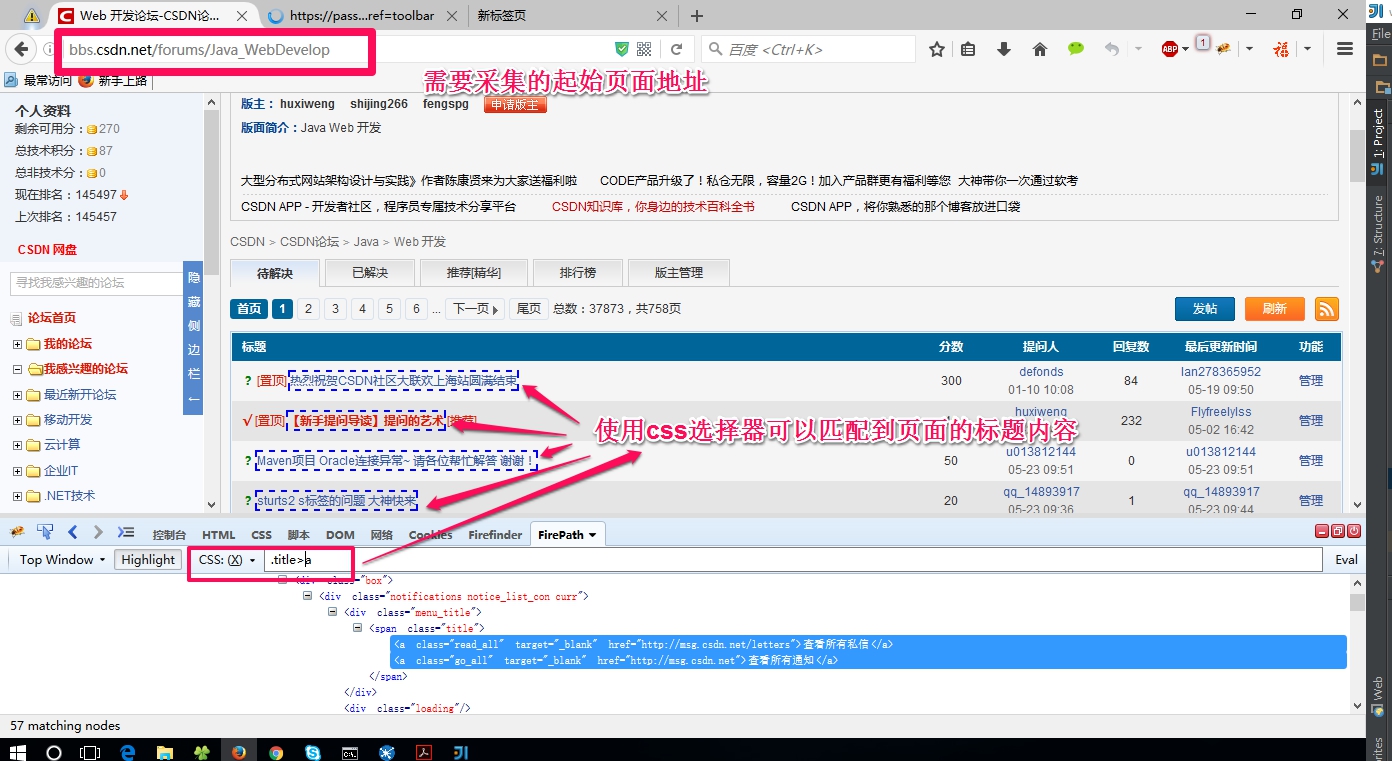
webmagic采集CSDN的Java_WebDevelop页面
项目中使用到了webmagic,采集论坛一类的页面时需要一些特殊的配置。在此记录一下 先来看看我要采集的页面 点击第2页可以看到它的url是http://bbs.csdn.net/forums/Java_WebDevelop?page2
点击尾页可以看到它的url是http://bbs.csdn.net/forums/Java_WebDevelop?…

用 Python 统计你的简书数据
写在前面 说来也巧,之前有一次无意间留意到简书好像没有做文章总阅读量的统计(准确的说法应该叫展示),刚好最近有时间,趁这个机会就用Python写了这么个功能,既是学习也是练手。
展示效果 再继续往下之前&a…

scrapy简记之抓取小说示例
scrapy 网络爬虫核心工作 通过网络向指定的 URL 发送请求,获取服务器响应内容使用某种技术(如正则表达式、XPath 等)提取页面中我们感兴趣的信息高效地识别响应页面中的链接信息,分析这些链接递归执行此处介绍的第 1、2、3 步使用…
scrapy runspider 导出json文件时乱码
scrapy runspider 导出乱码 初步判断 ,输入输出编码不一致 ,查阅官方与导出相关的配置说明如下 FEED_EXPORT_ENCODING Default: None The encoding to be used for the feed If unset or set to None (default) it uses UTF-8 for everything except JSO…
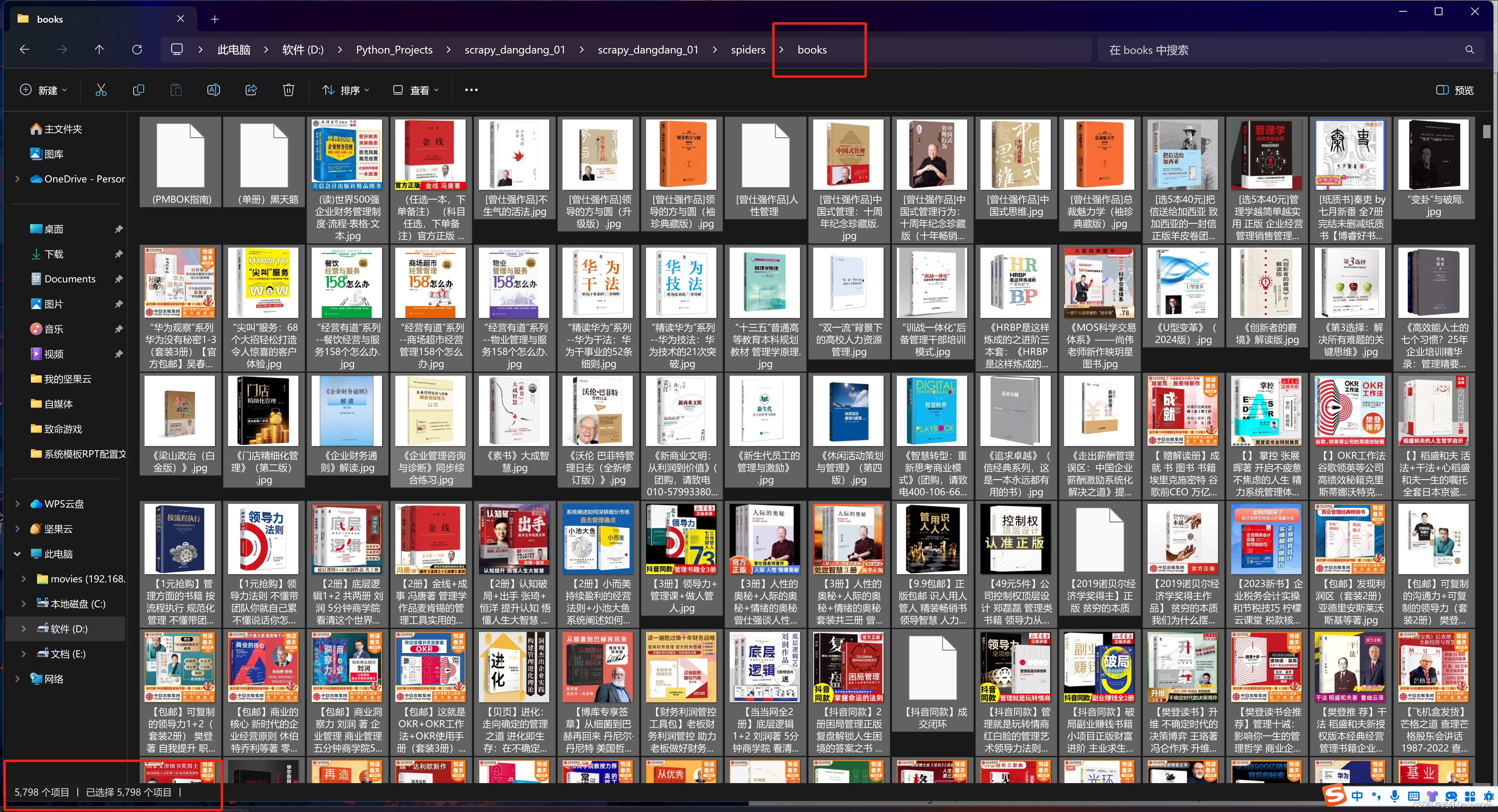
【Python从入门到进阶】50、当当网Scrapy项目实战(三)
接上篇《49、当当网Scrapy项目实战(二)》 上一篇我们讲解了的Spider与item之间的关系,以及如何使用item,以及使用pipelines管道进行数据下载的操作,本篇我们来讲解Scrapy的多页面下载如何实现。
一、多页面下载原理分…
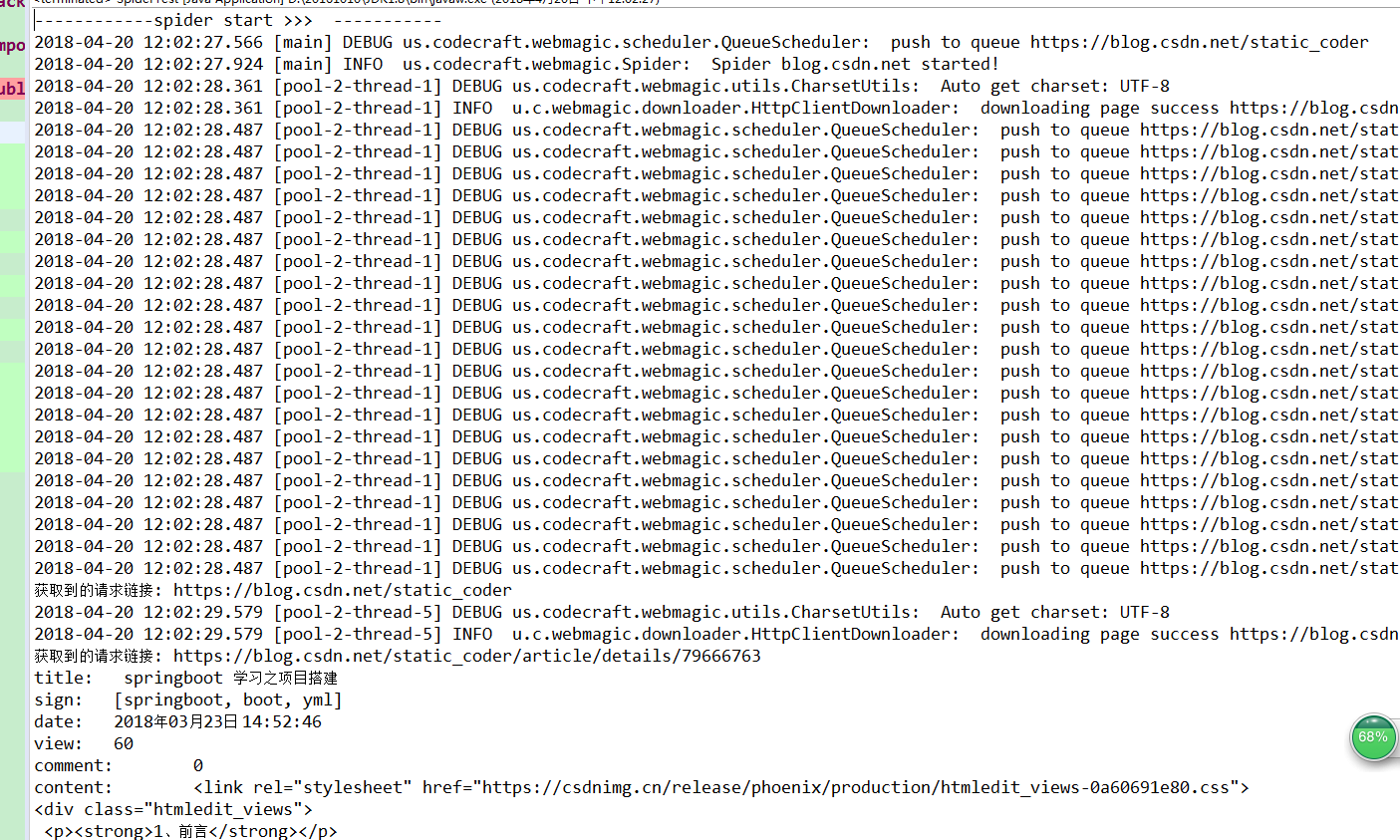
基于webmagic爬虫的简单编写
1、前言
前一段时间修改了一个项目的功能,项目基于webmagic编写的爬虫。于是开始一些学习。现在整理整理(该项目基本笔者的csdn博客的爬取为例),算是从小白到入门吧。之前使用httpclient和jsoup玩过一点点,但是感觉好麻…
PHPCrawler抓取酷狗精选集歌单
一、PHPCrawler的介绍与安装先了解一下什么是抓取?抓取就是网络爬虫,也就是人们常说的网络蜘蛛(spider)。是搜索引擎的一个重要组成部分,按照一定的逻辑和算法抓取和下载互联网上的信息和网页。一般的爬虫从一个start …

【Python从入门到进阶】44、Scrapy的基本介绍和安装
接上篇《43.验证码识别工具结合requests的使用》 上一篇我们学习了如何使用验证码识别工具进行登录验证的自动识别。本篇我们开启一个新的章节,来学习一下快速、高层次的屏幕抓取和web抓取框架Scrapy。
一、Scrapy框架的背景和特点 Scrapy框架是一个为了爬取网站数…