pytorch
.netcore
python内置函数
IO
二次元
layui
交互
博通蓝牙vendor
线程池
Fiori
XAML
skill 命令
ue4
大模型
内存管理
雷电游戏
MySQL集群
权限控制
程序员浪漫
轻量应用服务器
CV
2024/4/12 13:23:39

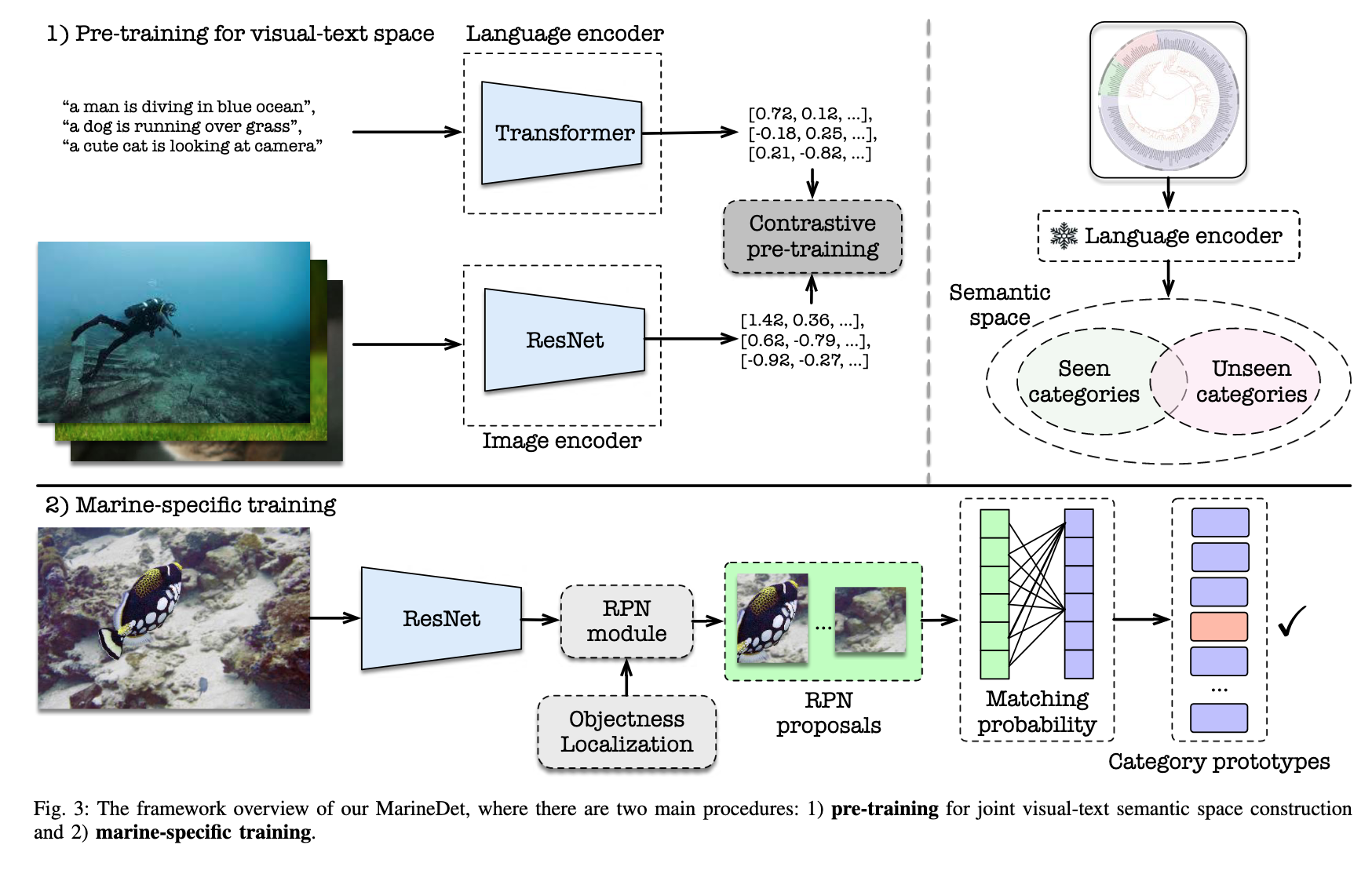
目标检测的图像特征提取之(一)HOG特征
目标检测的图像特征提取之(一)HOG特征 zouxy09qq.com http://blog.csdn.net/zouxy09 1、HOG特征: 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述…

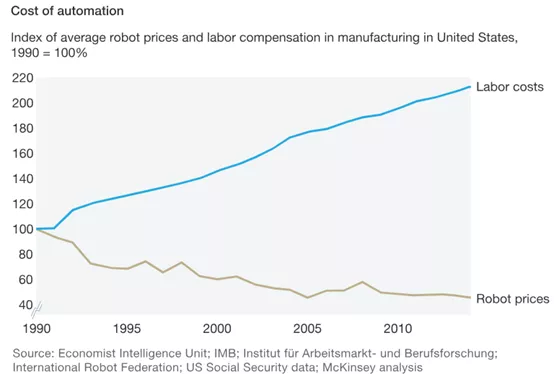
探索计算机视觉的无限可能
计算机视觉(CV)是人工智能领域的一个热门分支,它涉及到从图像和视频中提取信息,理解其内容,并执行各种任务。在这个博客中,我们将深入探讨计算机视觉的原理、应用和最新技术。
一、计算机视觉简介
计算机…
Tracking相关的文章
Tracking相关文章 一、Surveyand benchmark: 1. PAMI2014:VisualTracking_ An Experimental Survey,代码:http://alov300pp.joomlafree.it/trackers-resource.html 2. CVPR2013:Online Object Tracking: A Benchmark(需…
CNN中感受野的计算
感受野(receptive field)是怎样一个东西呢,从CNN可视化的角度来讲,就是输出featuremap某个节点的响应对应的输入图像的区域就是感受野。 比如我们第一层是一个3*3的卷积核,那么我们经过这个卷积核得到的featuremap中的…
图片数据归一化normalize(python脚本)
调用opencv的normalize函数完成图片数据归一化到0-1的值,最后再乘以255. 版本:python3.6
import os
import io
import math
import sys
import cv2
import shutil
import random
import numpy as np
from collections import namedtuple, OrderedDi…
cv conference paper search and download
会议论文搜索和下载
1.http://dblp.uni-trier.de/db/conf 比如CVPR
http://dblp.uni-trier.de/db/conf/cvpr/index.html
3DV
http://dblp.uni-trier.de/db/conf/3dim/ 2. http://www.cvpapers.com/

ridge regression 脊回归 / 岭回归
岭回归,脊回归 (ridge regression, Tikhonov regularization)
是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符…
tracking in opencv
opencv_contrib在新版本中已经加入了tracking的一些最新成果
下面简单列举下
GOTURN KCF Median Flow MIL TLD Boosting SVM

Tracking-Learning-Detection
Tracking-Learning-Detection(TLD)是Zdenek Kalal提出的一种对视频中单个物体长时间跟踪的算法。我主要会根据他在2010年发表的论文《Tracking-Learning-Detection》来分析TLD算法的原理。该项目的首页中有几段视频展示了TLD实时跟踪的效果和性能&#x…

目标检测的图像特征提取之(二)LBP特征
目标检测的图像特征提取之(二)LBP特征 zouxy09qq.com http://blog.csdn.net/zouxy09 LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的…

Going deeper with convolutions-GoogLeNet(阅读)
Abstract 网络结构称为Inception,名字的获得来自Network in Network。这个网络是一个分类和检测的网络。该网络最大的特点就是提升了计算资源的利用率。在网络需要的计算不变的前提下,通过工艺改进来提升网络的宽度和深度。最后基于Hebbian Principle和多…

基于Box Supervision的弱监督图像语义分割
简介
为什么要“弱监督”做图像语义分割
让我们来看看论文怎么说的。
ICCV 2015 BoxSup[1], “But pixel-level mask annotations are time-consuming, frustrating, and in the end commercially expensive to obtain.” ICCV 2015 WSSL[2], “Acquiring such data is an e…
用Caffe提取深度特征
用Caffe提取深度特征 发表于 2015-05-28 | 1条评论最近做对比实验,要比较非深度的方法加上deep feature之后的效果。于是就用Caffe提了一把特征,过程不困难但是有点繁琐,姑且记录下来,留个参考。 准备工作 用Caffe提取深度特征&…

【OpenCV】数字图像灰度直方图
灰度直方图是数字图像中最简单且有用的工具,这一篇主要总结OpenCV中直方图CvHistogram的结构和应用。 灰度直方图的定义 灰度直方图是灰度级的函数,描述图像中该灰度级的像素个数(或该灰度级像素出现的频率):其横坐标是…

BOW--创建和训练目标检测器
BOW--创建和训练目标检测器
1、bow方法的实现步骤
去一个样本数据集对样本集中的每幅图像提取描述符(采用SIFT,SURF等方法)将每一个描述符都加入到BOW训练器中将描述符聚类到K簇中(聚类的中心就是视觉单词)
接下来要测试一下分类…

Grabcut图像分割
GrabCut图像分割
1、算法步骤
1、在图片中定义含有(一个或多个)物体的矩形
2、在矩形外的区域被自动认为是背景
3、对于用户定义的矩形区域,可以用背景中的数据来区别他里面的前景和背景区域
4、用高斯混合模型来对背景和前景进行建模&a…
傅里叶变换、滤波器、边缘检测
傅里叶变换和滤波器
1、图像的幅度谱
图像的幅度谱是另一种图像,幅度谱图像呈现了原始图像在变化方面的一中表示:把图像中最明亮的像素放到图像中央,然后逐渐变暗,在边缘上的像素最暗,这样可以发现图像中有多少量的像…
帧差运动检测和颜色检测(C++)
基于视频的烟火检测
首先,对图像进行预处理:
1.对图像分块,将图像分为24*24的小块
2.对每块图像进行运动检测及颜色检测
然后,使用训练好的神经网络对图像进行分类
分块帧差运动检测
#include <opencv2/core/core.hpp>
#include <opencv2…
Bresenham's line and circle algorithm
今天看了计算机图形学中的画线和画圆算法
Bresenham算法只使用整形加减法和移位
可以说是非常优秀的算法了 说起“最大位移方向”,就会引入一个坐标概念(octant)。我称它为八等分圆坐标。如下图: Fig. 1 Bresenhams line and circle algorithm算法中最…

LeNet 5 pytorch实现
import torch.nn as nn
import torch
from torchinfo import summary
#img is 32*32*1
datatorch.ones(size(10,1,32,32))
class LeNet_5(nn.Module):def __init__(self): #定义神经网络所需的全部元素super().__init__()self.conv1nn.Conv2d(1,6,5) #322pad-kernel /1 1s…
Hough-直线和圆的检测
Hough-直线和圆的检测
1、直线检测
HoughLines:使用标准的Hough变换HoughLinesP:使用概率Hough变换,之所以称之为概率版本的Hough变换是因为他只通过分析点的子集并估计这些点都属于一条直线的概率该函数的计算代价会少一些,执行…

计算机视觉的应用18-一键抠图人像与更换背景的项目应用,可扩展批量抠图与背景替换
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用18-一键抠图人像与更换背景的项目应用,可扩展批量抠图与背景替换。该项目能够让你轻松地处理和编辑图片。这个项目的核心功能是一键抠图和更换背景。这个项目能够自动识别图片中的主体&…
基于web的亚热带常见自然林病虫害识别系统——开篇
文章目录 前言概要论文组织结构相关理论技术简介TensorflowDjango web 开发框架图像的分类的发展感受 绪论研究背景与意义国内外研究现状 前言
随着年底的到来,我相信越来越多的小伙伴也要开始着手自己的毕业设计,这里打算分享我自己的毕业设计…

KCF目标跟踪方法分析与总结
看了KCF,发现几篇博文总结的很棒,后面仅贴上最详细的链接 http://www.cnblogs.com/YiXiaoZhou/p/5925019.html
http://blog.csdn.net/shenxiaolu1984/article/details/50905283
http://www.jianshu.com/p/9aacd075a689 读"J. F. Henriques, R. …

经典算法之SRC分类器
自从05、06年开始,稀疏表示开始成为研究的热点。自从陶哲轩和他的小伙伴们解决了稀疏表示的理论问题,压缩感知或Sparse Representation成为学术界的研究热点。2008年,有Wright在PAMI上发表了一篇Sparse Representation based Classifier&…
paddlex模型预测视频(python脚本)
概述
利用paddlex模型预测视频,目前官方提供的pdx.det.visualize接口只能预测图片,而且当你预测多张图片的时候,两张图片的类别颜色不固定,个人觉得属于paddlex的一个bug,望后期能改善。使用的环境是windows、ppyolo模…
Caffe提取任意层特征并进行可视化
现在Caffe的Matlab接口 (matcaffe3) 和python接口都非常强大, 可以直接提取任意层的feature map以及parameters, 所以本文仅仅作为参考, 更多最新的信息请参考: http://caffe.berkeleyvision.org/tutorial/interfaces.html 原图 conv1层可视化结果 (96个filter得到的…
循环矩阵傅里叶对角化
All circulant matrices are made diagonal by the Discrete Fourier Transform (DFT), regardless of the generating vector x. 任意循环矩阵可以被傅里叶变换矩阵对角化。 文献中,一般用如下方式表达这一概念: XC(x)F⋅diag(x^)⋅FH其中X是循环矩阵…

OpenCV-Python 颜色识别(红色)并拟合矫正目标区域
OpenCV版本:4.6.0.66
算法实现思路: 颜色识别(红色)形态学去噪轮廓检测多边形拟合透视矫正代码实现:
import cv2
import numpy as np# 可视化
def img_show(name, img):cv2.namedWindow(name, 0)cv2.resizeWindow(name, 1000, 500)cv2.imsh…


利用hash算法计算图片相似度
计算两张图片的相似性,利用官方的hash python代码(https://github.com/zhangsong8/imagehash)测试图片相似度,算法源代码都在工程里面,非常方便,简单易懂。 下面是我自己写的python测试脚本,批量…

【AI视野·今日CV 计算机视觉论文速览 第280期】Mon, 1 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Mon, 1 Jan 2024 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Learning Vision from Models Rivals Learning Vision from Data Authors Yonglong Tian, Lijie Fan, Kaifeng Chen, Dina K…

【CS231n Winter 2016 Lecture 2 (Image classifier,NN/KNN/linear classifier)】
Lecture 2
上一讲结束后,李飞飞就回家生孩子了。这一讲是Andrej Karpathy讲 语速较快,不过听着还行,当练练听力。
上来就说先把image classifier给搞定了,然后各种渲染classifier is a challengeable task. 举的是猫的例子&…

【CS231n winter2016 Lecture 3 (Linear classification II/loss function/optimization/SGD)】
一上课就说作业的截止日期只有7天,想起原来该课程还是有作业的,不做的话可能达不到效果,要不等到课程中段了或者看完整个课后再写吧。。另外自己在想找个时间把凸优化和乔丹推荐的书单开始学习了。 Lecture 3
回顾上一讲,image c…
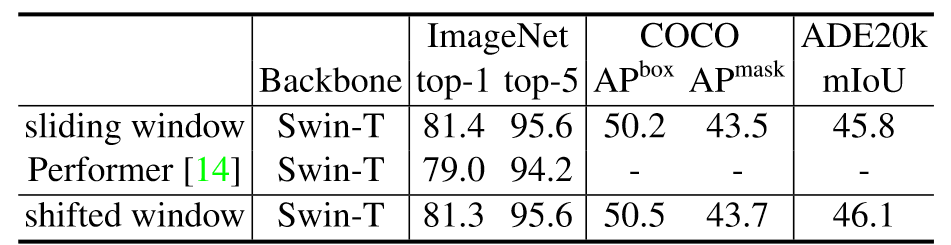
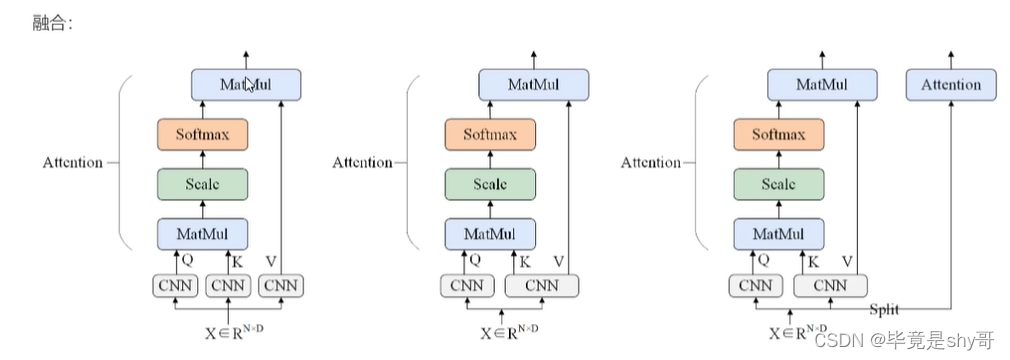
【论文精读】Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 前言Abstract1. Introduction2. Related Work3. Method3.1. Overall Architecture3.2. Shifted Window based Self-AttentionSelf-attention in non-overlapped windowsShifted window partitioning …

Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks論文研讀與問題討論
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks論文研讀與問題討論前言本篇亮點簡介(1)背景介紹共享卷積層生成候選框的方法RPN簡介多尺度目標檢測模型表現(2)相關方法生成候選框的方法目標檢測…
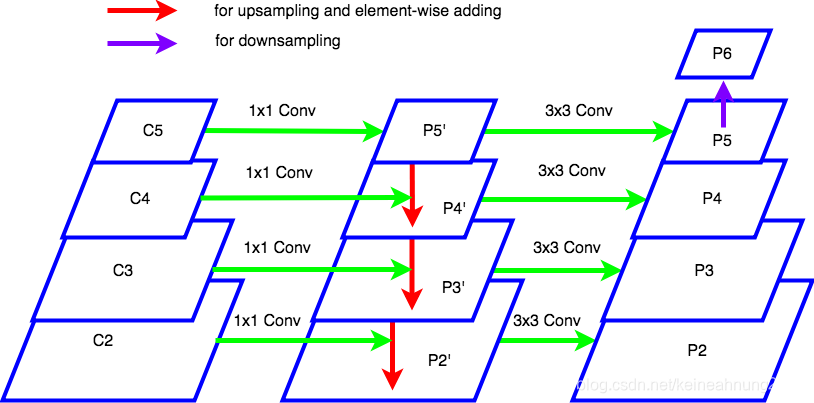
Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份
Mask_RCNN代碼研讀(matterport版本)系列文(二)- Feature Pyramid Network部份前言訓練及推論模式中的共同部份Feature Pyramid Network小結參考連結前言
在本系列的第一篇Mask_RCNN代碼研讀(matterport版本࿰…
SIFT算法的应用--目标识别之Bag-of-words模型
SIFT算法的应用 -目标识别之用Bag-of-words模型表示一幅图像 作者:wawayu,July。编程艺术室出品。 出处:http://blog.csdn.net/v_JULY_v 。

【AI视野·今日CV 计算机视觉论文速览 第251期】Thu, 21 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 21 Sep 2023 Totally 76 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚FreeU, Diffusion U-Net提升生成模型的质量。(from 南洋理工) Daily Computer Vision Papers
DreamLLM: Synergistic Multi…
激发创新,助力研究:CogVLM,强大且开源的视觉语言模型亮相
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

【AI视野·今日CV 计算机视觉论文速览 第256期】Thu, 28 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 28 Sep 2023 Totally 96 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
SHACIRA: Scalable HAsh-grid Compression for Implicit Neural Representations Authors Sharath Girish, Abhinav Shriva…
python通过ctypes调用C++程序
环境:
windows系统visual studio MSVC编译环境python3.7. (注意:windows系统下要用MSVC编译成动态库dll,用qt中的MinGW编译出来的动态库调用报错,具体原因不明。如果使用MSVC编译器,就需要调用的第三方ope…

Resnet-18和Resnet34 pytorch实现
残差块: 18层:(2222)*211
import torch.nn as nn
from torchinfo import summary
import torchclass BasicBlock(nn.Module):expansion 1def __init__(self, inplanes, planes, stride1, downsampleNone):""":…

OpenCV-Python 图像全景拼接stitch及黑边处理
OpenCV版本:4.5.3.56 算法实现思路: 图像拼接全景轮廓提取轮廓最小正矩形腐蚀处理裁剪代码实现:
import cv2
import numpy as npdef stitch(image):# 图像拼接# stitcher cv2.createStitcher(False) # OpenCV 3.X.X.X使用该方法stitcher …

【论文笔记】Unsupervised Discovery of Mid-Level Discriminative Patches
阅读论文:Singh, S., Gupta, A., & Efros, A. A. (2012). Unsupervised Discovery of Mid-Level Discriminative Patches. ECCV. 相关链接:http://graphics.cs.cmu.edu/projects/discriminativePatches/最近试图从中层特征入手研究物体识别ÿ…

【OpenCV】访问图像中每个像素的值
转载请注明出处:http://blog.csdn.net/xiaowei_cqu/article/details/7557063 !!此篇是基于IplImage* (C接口或者说2.1之前版本的接口,新的Mat的访问方式请参考博文:《访问Mat图像中每个像素的值》ÿ…
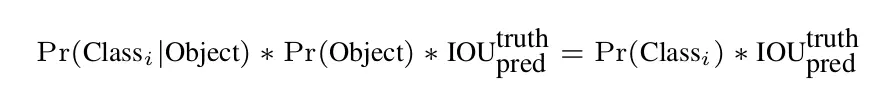
掌握 yolo - 解码核心思想,v3、v4、v5上手不是梦....
文章目录0x01 背景0x02 编解码2.1 编码2.2 解码2.3 小脑袋有大大的问号0x03 Coding3.1 加载图片 & 推理3.2 解码3.3 置信度3.3.1 单个类别且只需要一个框3.3.2 多个类别参考资料0x01 背景 目的:识别出图片中概率最大的人形生物,并给出坐标 仅讨论 yo…

总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
前言
此片有很多别人的东西,直接搬过来了,都有注释,里面也有一些自己的理解和需要注意的地方,以此记录一下,总结如下,思想不够成熟,以后再补充,如有错误请不吝指正 犀利的开头 在机…

【AI视野·今日CV 计算机视觉论文速览 第258期】Mon, 2 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Mon, 2 Oct 2023 (showing first 100 of 112 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚*****The Dawn of LMMs, GPT4-V视觉大语言模型综述。(from Microsoft Corporation)
&…
仿真机器人-深度学习CV和激光雷达感知(项目2)day8【作业2与答案2】
文章目录 前言作业2答案2前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个项目 💫欢迎大家的关注,我的博客主要关注于考研408以及AIoT的内容 🌟 预置知识:基本Python语法,基本linux命令行使用 以下的几个专栏是本人比较满意的…
python openCV调用摄像头进行人脸识别
整个过程很简单,因为不是自己训练人脸特征模型,而是使用的官方的Haar分类器(但是这样的话实测识别不是很准确)。
版本信息:
python: 3.7
cv2: 4.1.0haar分类器下载
过程可以概括为:
1、调用电脑摄像头&a…
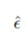
Classifier-Free Guidance
1.为什么需要分类引导 顾名思义,在原来扩散模型的基础上加上一个引导,让扩散模型朝着我们想要的方向去生成图像 从上图可以了解到生成下一张图像是有分类器参与的 无分类器就是这种形式要参与下一张图像的生成
yolov7和yolov5对比有哪些优势?yolov7改进-yolov7详解
YOLOv7发布至今已过去三个月,因为涉及到较多新的知识,可能读起来不算容易。很多人还是依然选择使用YOLOv5。但实际上最新版的YOLOv7比其他版本精密度和速率都要好。下面详细给大家说明一下。
yolov7有哪些优势?
Yolov7超过了目前已知的所有…

Text-to-SQL小白入门(二)——Transformer学习
摘要
本文主要针对NLP任务中经典的Transformer模型的来源、用途、网络结构进行了详细描述,对后续NLP研究、注意力机制理解、大模型研究有一定帮助。
1. 引言
在上一篇《Text-to-SQL小白入门(一)》中,我们介绍了Text-to-SQL研究…
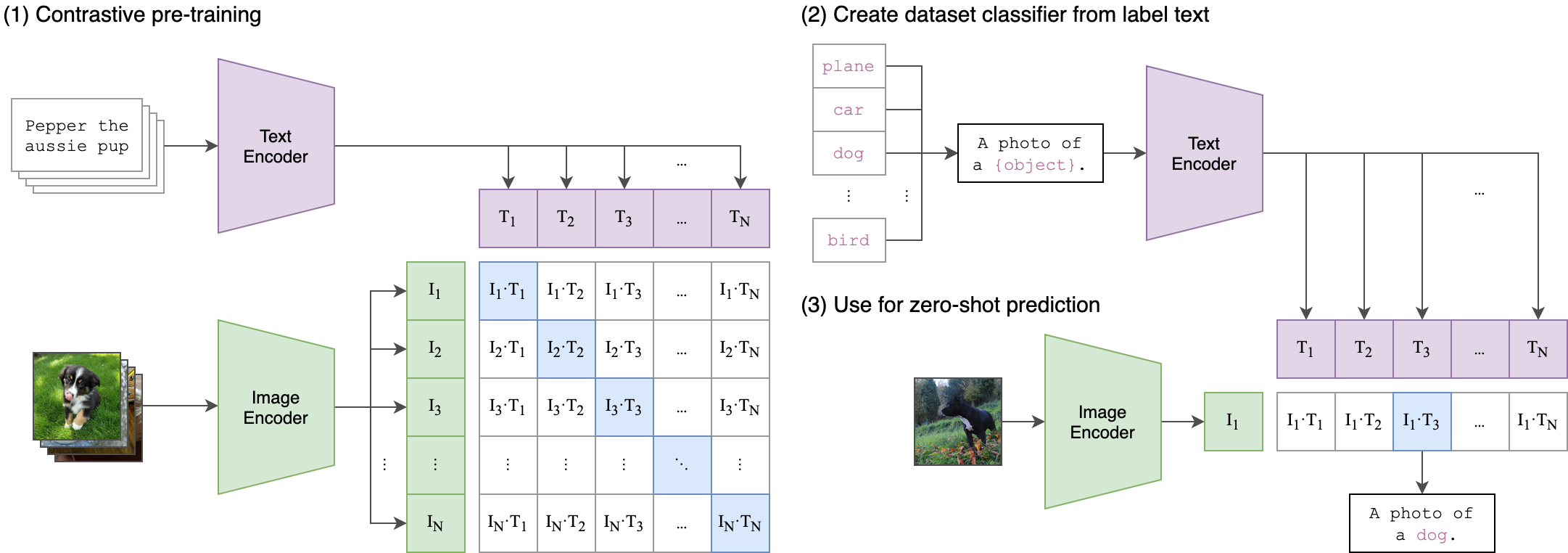
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…
module ‘cv2.cv2‘ has no attribute ‘HAAR_SCALE_IMAGE‘,
报错:module ‘cv2.cv2’ has no attribute ‘HAAR_SCALE_IMAGE’,子模块cv已从opencv 3.0中移除。
解决方法:改为cv2.CASCADE_SCALE_IMAGE,亲测有效!

【AI视野·今日CV 计算机视觉论文速览 第262期】Fri, 6 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 6 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Improved Baselines with Visual Instruction Tuning Authors Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee大型多模…
YOLO物体检测-系列教程4:YOLOV3项目实战1(coco图像数据集/darknet预训练模型)
1、整体项目
1.1 环境
一个有debug功能的IDE,建议PycharmPyTorch深度学习开发环境下载COCO数据集: 训练集,是很大的数据验证集,是很大的数据
1.2 数据
依次进入以下地址: 项目位置\PyTorch-YOLOv3\data\coco\imag…
图像识别-YOLO V8安装部署-window-CPU-Pycharm
前言
安装过程中发现,YOLO V8一直在更新,现在是2023-9-20的版本,已经和1月份刚发布的不一样了。
eg: 目录已经变了,旧版预测:在ultralytics/yolo/v8/下detect
新版:ultralytics/models/yolo/detect/predict.py
1.安…

【AI视野·今日CV 计算机视觉论文速览 第289期】Fri, 12 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Fri, 12 Jan 2024 Totally 79 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Distilling Vision-Language Models on Millions of Videos Authors Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun …

双视图特征点匹配———使用RANSAC法剔除误差点
本文使用SIFT算法得到两张图的初始特征匹配集合,然后着重总结如何使用基于8点法的RANSAC法将匹配集合中的误差点(外点)剔除。
基础矩阵介绍
进行8点法之前首先需要知道基础矩阵的定义。
如图1-1所示,沿着空间点X和相机中心点之间的连线,可以在图像上找到对应的点x。那么…
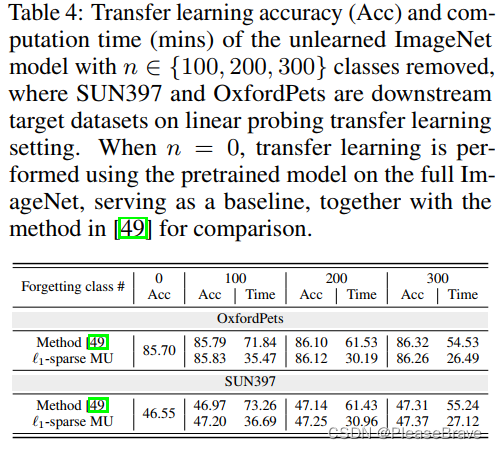
【论文阅读】 Model Sparsity Can Simplify Machine Unlearning
Model Sparsity Can Simplify Machine Unlearning 背景主要内容Contribution Ⅰ:对Machine Unlearning的一个全面的理解Contribution Ⅱ:说明model sparsity对Machine Unlearning的好处Pruning方法的选择sparse-aware的unlearning framework Experiments…

【CV中的Attention机制】语义分割中的scSE模块
摘要: 本文介绍了一个用于语义分割领域的attention模块scSE。scSE模块与之前介绍的BAM模块很类似,不过在这里scSE模块只在语义分割中进行应用和测试,对语义分割准确率带来的提升比较大。 提出scSE模块论文的全称是:《Concurrent Spatial and …
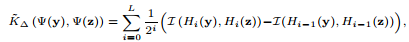
Histogram intersection(直方图交叉核,Pyramid Match Kernel)
看关于LBP人脸识别的论文时提到了Histogram intersection这个方法,方法最初来自The Pyramid Match Kernel:Discriminative Classification with Sets of Image Features这篇论文,用来对特征构成的直方图进行相似度匹配,下面介绍下原理。 假设…
仿真机器人-深度学习CV和激光雷达感知(项目2)day6【数学基础-坐标变换】
文章目录 前言坐标变换的作用旋转与平移二维变换旋转平移推广到三维齐次坐标问题引入定义用法变换矩阵旋转的其他表示方法*前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个项目 💫欢迎大家的关注,我的博客主要关注于考研408以及…

仿真机器人-深度学习CV和激光雷达感知(项目2)day03【机器人简介与ROS基础】
文章目录 前言机器人简介机器人应用与前景机器人形态机器人的构成 ROS基础ROS的作用和特点ROS的运行机制ROS常用命令 前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个项目 💫欢迎…
仿真机器人-深度学习CV和激光雷达感知(项目2)day5【作业1与答案1】
文章目录 前言作业1答案1 前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个项目 💫欢迎大家的关注,我的博客主要关注于考研408以及AIoT的内容 🌟 预置知识…

openCV: 利用python和cv2绘出一个笑脸
import cv2
import numpy as np
from matplotlib import pyplot as pltimg np.zeros((512,512,3),np.uint8) # 生成一个彩色图像
cv2.circle(img,(200,200),50,(0,0,255),-1) # 绘制左眼
cv2.circle(img,(400,200),50,(0,0,255),-1) # 绘制右眼
cv2.ellipse(img,(300,400),(15…

【AI视野·今日CV 计算机视觉论文速览 第266期】Thu, 12 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 12 Oct 2023 Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
PAD: A Dataset and Benchmark for Pose-agnostic Anomaly Detection Authors Qiang Zhou, Weize Li, Lihan Jiang, Guoli…
(2023版)斯坦福CS231n学习笔记:DL与CV教程 (16) | 3D视觉( Vision)
前言 📚 笔记专栏:斯坦福CS231N:面向视觉识别的卷积神经网络(23)🔗 课程链接:https://www.bilibili.com/video/BV1xV411R7i5💻 CS231n: 深度学习计算机视觉(2017…
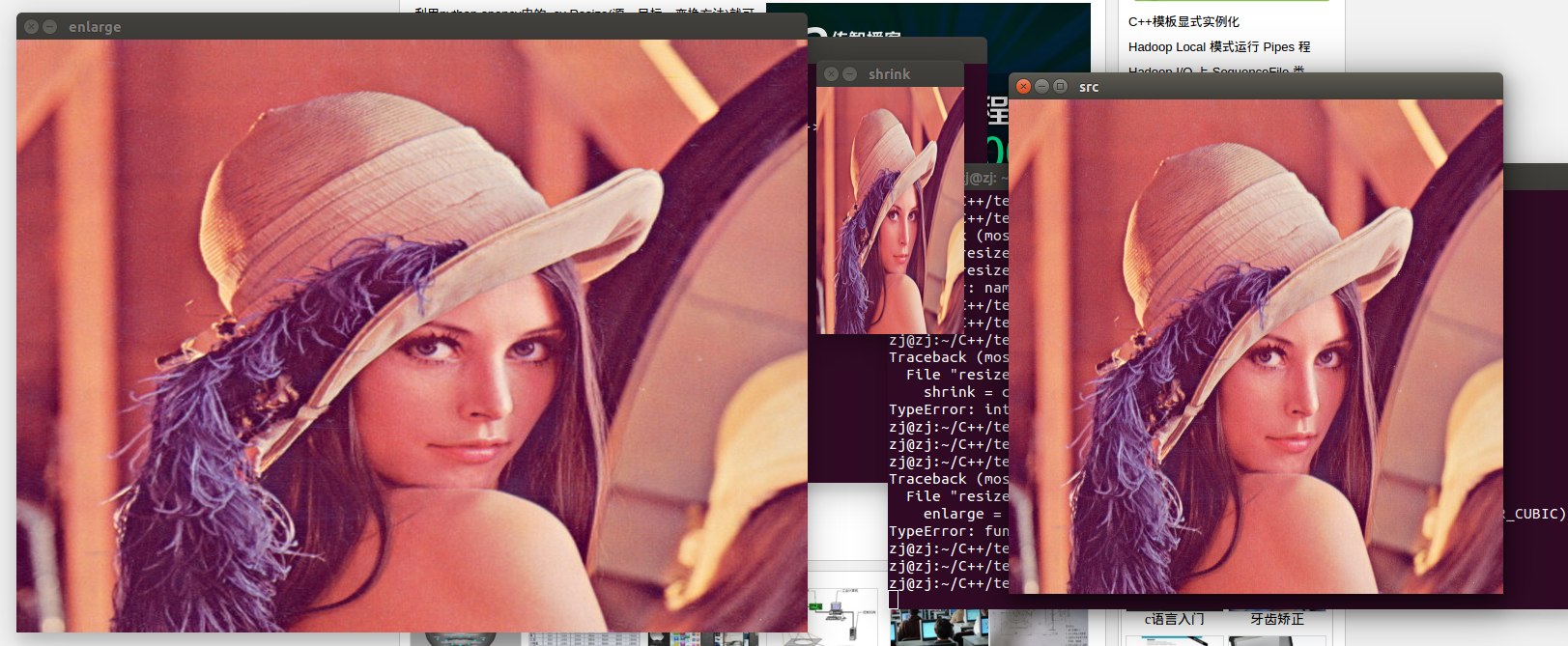
cv.resize()详解
resize是opencv库中的一个函数
函数功能: 缩小或者放大函数至某一个大小 resize(InputArray src, OutputArray dst, Size dsize, double fx0, double fy0, int interpolationINTER_LINEAR )
参数解释:InputArray src :输入,原图像ÿ…
![深度学习应用篇-计算机视觉-图像增广[1]:数据增广、图像混叠、图像剪裁类变化类等详解](https://img-blog.csdnimg.cn/img_convert/0dacfa2d1614c59f191480d8ed48c719.png)
深度学习应用篇-计算机视觉-图像增广[1]:数据增广、图像混叠、图像剪裁类变化类等详解
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…

opencv3.0 人脸识别基础实验入门
一,基于图像识别 在上一篇我们将环境搭建好之后,这次开始实践 实验准备:自己在网上找一张带人物的头像就可以。 我们使用使用的分类器:haar opencv中有三种分类器: "haar"特征主要用于人脸检测, …
深度学习——SAM(Segment-Anything)代码详解
目录 引言代码目录segment-anything 代码详解build_sam.pypredictor.pyautomatic_mask_generator.py 引言
从去年年初至今,SAM(Segment Anything )已经问世快一年了,SAM凭借其强大而突出的泛化性能在各项任务上取得了优异的表现,广大的研究者…
C++拷贝构造函数和=赋值运算符详解
首先明确一点: 系统已经提供了默认的 拷贝构造函数 和 复制运算符。 即所谓的浅拷贝。 但有时,我们必须提供自己重写。一般是在有指针的情况下重写。 举个简单的例子,没有指针,其实不必重写,只是为了演示:…

YOLO算法系列之YOLOv1精讲
目录
YOLOv1网络结构
YOLOv1输入与输出映射
YOLOv1损失函数
坐标损失函数
置信度损失函数
类别损失函数
总结 大家好,我是羽峰,今天要和大家分享的是YOLOv1算法. 本文有文字和视频,感兴趣的话可以看视频,视频在我主页能找到…

医学诊断报告生成论文综述
摘要
由Image/Video Captioning、VQA等图像理解任务的不断往前发展,以及目前智能医疗的兴起,有些学者自然而然地想到图像理解是否可以应用到医学领域,因此根据CT、核磁等图像自动生成诊断报告(病例),这个任务被提了出来。
2018年…

利用OpenGL学习计算机图形学
使用OPENGL (Open Graphics Library)可以用来进行虚拟模型的渲染,OPENGL一个跨语言、跨平台的图形编程接口,具有2D/3D 建模、坐标变换、交互技术、纹理映射等功能,包含几百个核心函数,通过这些函数可以便捷…
opencv使用问题记录一二
opencv介绍
opencv是一个计算机视觉处理软件库,拥有强大的功能和高效的性能。
但是由于早期版本的原因,存在一些与目前主流使用不兼容的问题
问题与解决
RGB通道顺序
一般图片处理类库的通道顺序就是RGB,但是opencv的是反过来的…

OpenCV-Python 通过边缘检测识别物体并批量提取(大米识别为例)——minAreaRect批量生成物体的最小外接矩形(旋转矩形)并批量裁剪
OpenCV版本:4.0.0.21(已兼容4.5.2.X版本)
算法实现思路如下:
对图像做降噪滤波处理提取边缘检测轮廓检测轮廓最小外接矩形(旋转矩形)旋转图像裁剪
代码如下:
import cv2
import numpy as npimage cv2.imread("…

【计算机视觉】三、图像处理——实验:图像去模糊和去噪、提取边缘特征
文章目录 0. 实验环境1. 理论基础1.1 滤波器(卷积核)1.2 PyTorch:卷积操作 2. 图像处理2.1 图像读取2.2 查看通道2.3 图像处理 3. 图像去模糊4. 图像去噪4.1 添加随机噪点4.2 图像去噪 0. 实验环境 本实验使用了PyTorch深度学习框架,相关操作…
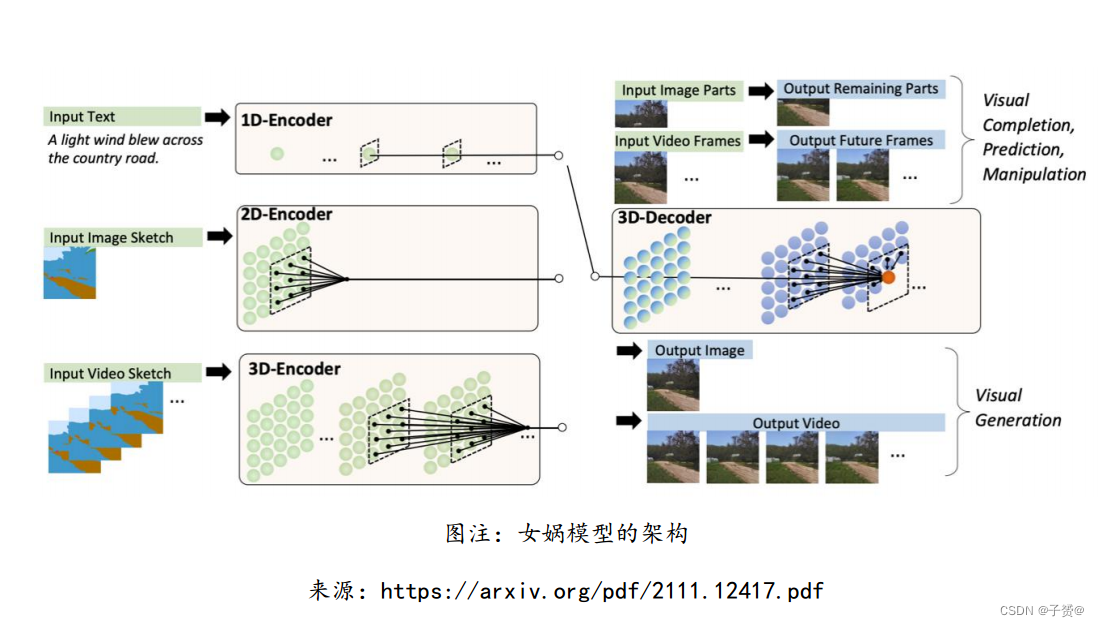
计算机视觉cv模型最新进展速看:
华为诺亚实验室等研究者提出动态分辨率网络 DRNet
深度卷积神经网络通畅采用精细的设计,有着大量的可学习参数,在视觉任务上实现很高精 确度要求。为了降低将网络部署在移动端成本较高的问题,近来发掘在预定义架构上的冗余 已经取得了巨大的…
softmax梯度矩阵向量化实现推导
前言
前面的SVM梯度矩阵向量化实现,其实不能算是推导出来的,应该算是“凑出来的”,由结果推过程,今天又遇到了softmax的梯度矩阵,我觉得不能再逃避了,思考了很久,终于算真正地把这个搞明白
预…
SfM——八点法计算F矩阵(基础矩阵)与三角测量
1 八点法计算F矩阵(基础矩阵)
基础矩阵用于描述两个视图之间的几何关系 基础矩阵:基础矩阵 F F F 是描述两个视图之间相机投影关系的矩阵。对于两个对应的图像坐标点 ( x , y , 1 ) (x, y, 1) (x,y,1) 和 ( u , v , 1 ) (u, v, 1) (u,v,1…
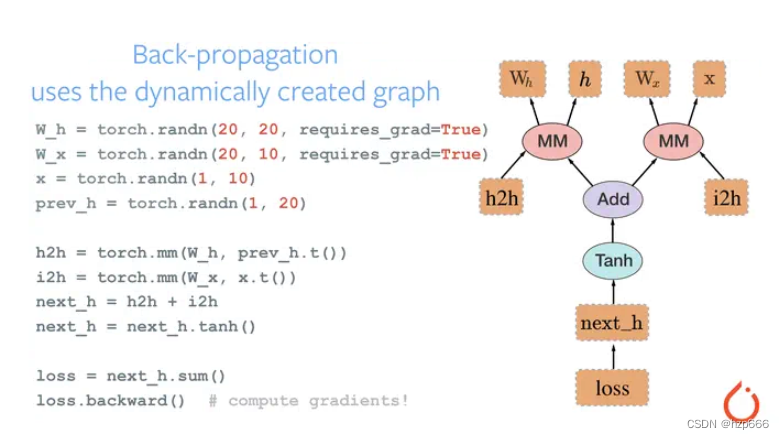
Pytorch_training2——network build+model (load+modify)
link
import torchvision
from torchvision import models
resnet50 models.resnet50(pretrainedTrue) #pretrainedTrue 加载模型以及训练过的参数
print(resnet50) # 打印输出观察一下resnet50到底是怎么样的结构visit&modify nn_layer
resnet50models.resnet50(pretr…


【计算机视觉】二、图像形成——实验:2D变换编辑(Pygame)
文章目录 一、向量和矩阵的基本运算二、几何基元和变换1、几何基元(Geometric Primitives)2、几何变换(Geometric Transformations)2D变换编辑器0. 程序简介环境说明程序流程 1. 各种变换平移变换旋转变换等比缩放变换缩放变换镜像变换剪切变换 2. 按钮按钮类创建按钮 3. Pygam…

opencv背景处理pmog方式(效果较差值差掉,个人感觉降噪不是很到位)
至于环境自己想去搭建,搭建完直接拷贝运行即可。 这个是实时的视频提取前景物
#include "opencv2/opencv.hpp"
using namespace cv;
using namespace std;int main()
{VideoCapture cap; // 定义VideoCapture类用以打开指定视频Mat source, image, fore…

图像相关小成果:停车自动计费装置
停车自动计费装置(大四的一些小成果)
1.引言
1.1 项目背景: 近年来,随着经济建设的快速发展,人民物质生活水平不断丰富,汽车拥有量不断增加,给人民出行带来便利的同时,也使得城市交…

马赛克,克星,真来了!v2.0
大家好,今天继续聊聊 AI 开源项目
AI 开源项目
1、DemoFusion
AI 绘画的潜力还没有充分挖掘出来,仍然还有上升的空间。
DemoFusion 就是这么一个开源项目,继续深挖了 AI 绘画在高分辨率图片生成的效果。
提高分辨率,马赛克&a…

opencv 侵蚀erode 膨胀dilate 开运算 闭运算等形态学转换操作
文章目录1. 侵蚀 (白色区域减小)demo效果2. 扩张demo效果3. 形态学变化(组合)3.1开运算 cv::MORPH_OPENdemo效果3.2 闭运算 cv::MORPH_CLOSEdemo效果3.3 形态学梯度 cv::MORPH_GRADIENTdemo效果3.4 顶帽 cv::MORPH_TOPHATdemo效果3.5 黑帽 cv::MORPH_BLA…
浅谈-什么是计算机视觉
1什么是计算机视觉
计算机视觉(Computer Vision)是指用计算机实现人的视觉功能——对客观世界的三维场景的感知、识别和理解。这意味着计算机视觉技术的研究目标是使计算机具有通过二维图像认知三维环境信息的能力。因此不仅需要使机器能感知三维环境中物…

【AI视野·今日CV 计算机视觉论文速览 第281期】Tue, 2 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Tue, 2 Jan 2024 Totally 95 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Refining Pre-Trained Motion Models Authors Xinglong Sun, Adam W. Harley, Leonidas J. Guibas考虑到在视频中手动注释运…
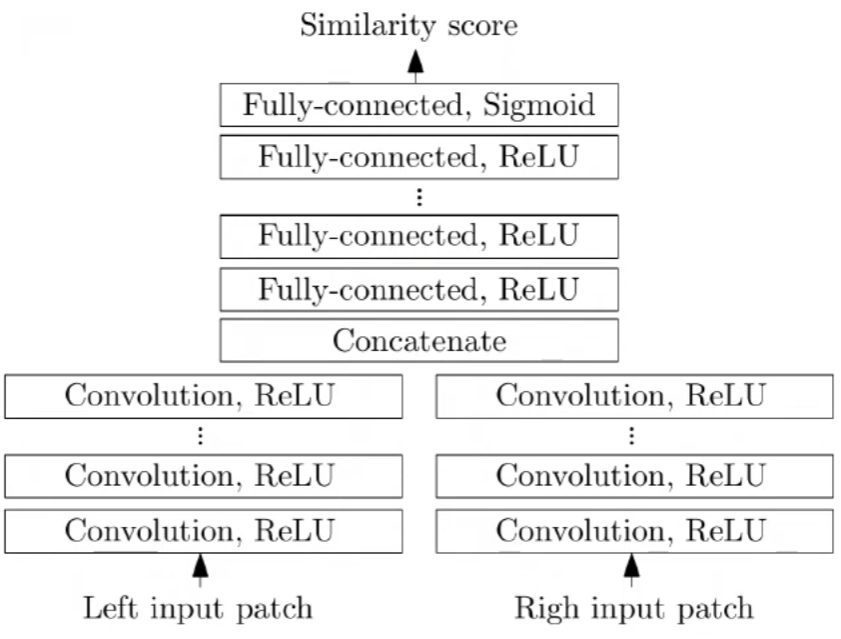
SAD法(附python实现)和Siamese神经网络计算图像的视差图
1 视差图
视差图:以左视图视差图为例,在像素位置p的视差值等于该像素在右图上的匹配点的列坐标减去其在左图上的列坐标
视差图和深度图: z f b d z \frac{fb}{d} zdfb 其中 d d d 是视差, f f f 是焦距, b b…

分类模型--ResNet系列--ResNet50
ResNet是什么?解决了?
Residual net(残差网络):将靠前若干层的某一层数据输出直接跳过多层引入到后面的数据层的输入部分;表明了后面的特征层的内容会有一部分由前面的某一层线性贡献。结构如下࿱…

「图像 cv2.seamlessClone」无中生有制造数据
上一篇博客【「图像 merge」无中生有制造数据 】写的是图片直接融合,此方法生成的图片相对而言比较生硬,虽然目标图片已经透明化处理过了,但是生成的图片依旧很假 除了上述上述的图片叠加融合之外,还有一种更加自然的融合方法&…

gnuplot 入门教程 1
几年前写的一篇短文,今天找东西时翻出来了,感觉写的还是比较实用的。放在这里供有需要的人参考。 现在在网上可以找的科学作图软件有不少,其中不乏优秀者,Win平台上有大名鼎鼎的Origin、Tecplot、SigmaPlot等,类UNIX上…
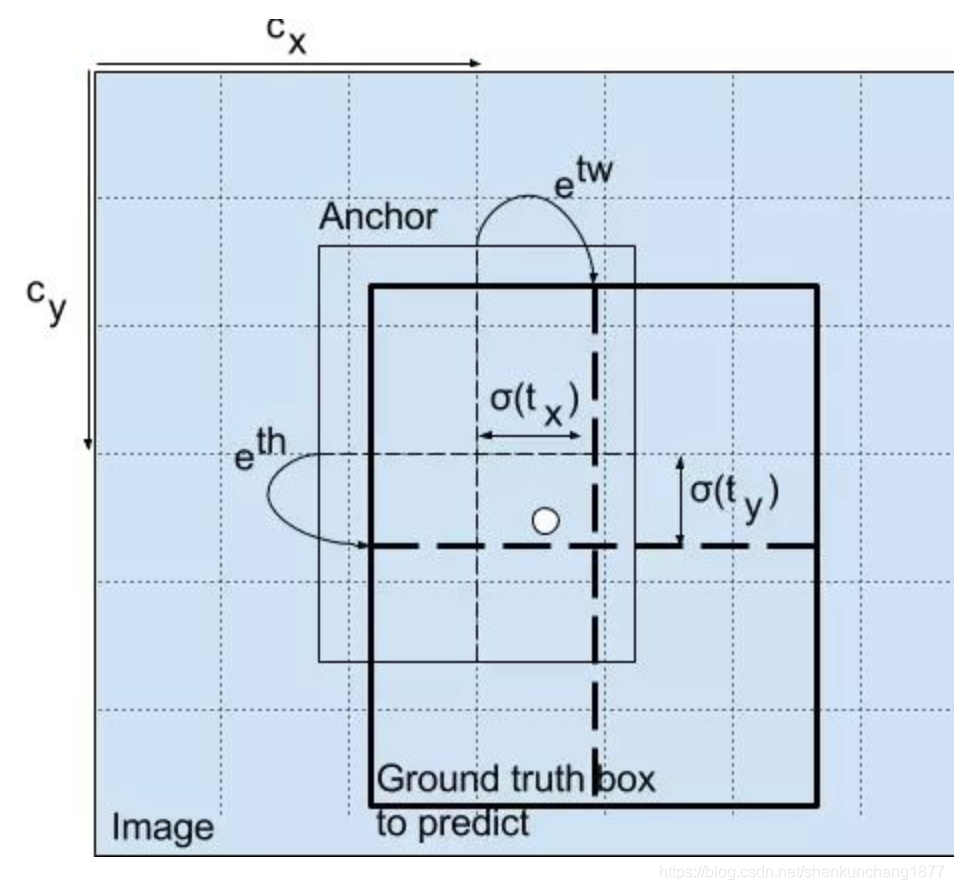
YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解
虽然阅读量不是很多,但是没想到居然能得到这么多收藏和赞,大家提出的问题,我会不断更新,尽量把过程解释得让大家都能了解清楚。
PS:这篇文章是自己学习纪录下的笔记,主要是通过阅读paddle复现的yolov3源码…

拼接不同文件夹中同名图片的方法
有时候为了方便对比不同文件夹中同名图片,需要拼接在一起,这里提供一个拼接方法,当然不同命文件也可以实现拼接,稍微改改就能实现
如下图,在文件夹中有五个文件夹中的图片需要拼接,拼接后的图片存放在img_…
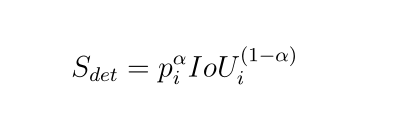
IoU-aware Single-stage Object Detector for Accurate Localization-----论文阅读笔记
IoU-aware Single-stage Object Detector for Accurate Localization-----论文阅读笔记原文和代码:Abstract存在的问题?解决办法Introduction总结:问题:作者解决方案:2. Related Work3. Method3.1. IoU-aware single-s…
【AI视野·今日CV 计算机视觉论文速览 第260期】Wed, 4 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Wed, 4 Oct 2023 Totally 79 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚DREAM, 基于功能核磁共振信号重建人类看见的视觉图像。(from UCL London) 📚RSRD,公路路面数据集(from 清华 )
w…
仿真机器人-深度学习CV和激光雷达感知(项目2)day7【ROS关键组件】
文章目录 前言Launch 文件了解 XML 文件Launch 文件作用Launch 文件常用标签实例--作业1的 Launch 文件TF Tree介绍发布坐标变换--海龟例程获取坐标变换--海龟自动跟随例程rqt_工作箱前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个…
python-图片批量处理成正方形
我们平时获取的图片都是矩阵居多,现在如何怎么这些矩形处理成正方形呢
正方形的处理方式一般有这两种,一种是裁剪掉较长边的长度与宽等长,另一种则是填充将较宽的边与较长边等长。
1.裁剪成正方形-单张图片处理
代码如下:
from PIL import Image
a = "1234.png&qu…
仿真机器人-深度学习CV和激光雷达感知(项目2)day04【简单例程】
文章目录 前言简单例程运行小海龟仿真启动节点查看计算图发布 Topic调用 Serviece 用 Python 发布和接收 Topic创建工作空间创建功能包,编译编写 Topic Publisher 节点编写 Topic Subscriber 节点运行节点 自定义消息类型用 Python 注册和调用 Serviece新建功能包在…
BOW vs FisherVector vs VLAD
特征聚合 BOW是把特征点做kmeans聚类,然后用离特征点最近的一个聚类中心去代替该特征点,损失较多信息; fisher Vector. 本质上是用似然函数的梯度vector来表达一幅图像,这个梯度向量的物理意义就是表达了参数往哪个方向修正才能最…
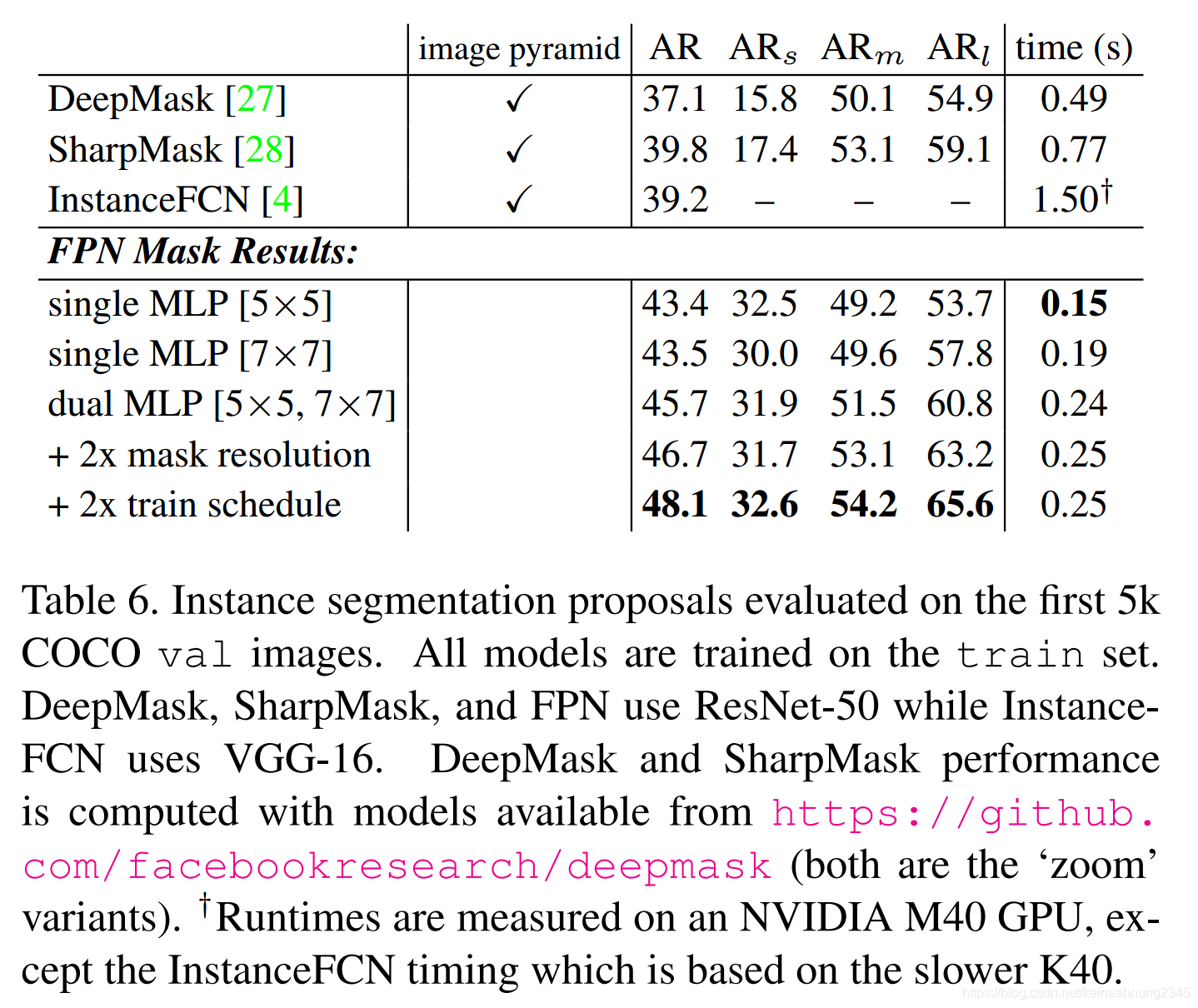
Feature Pyramid Networks for Object Detection論文研讀與問題討論
Feature Pyramid Networks for Object Detection論文研讀與問題討論前言(1)背景介紹Featurized Image PyramidsFast & Faster R-CNN使用deep ConvNet固有的feature hierarchySingle Shot DetectorFeature Pyramid Network(2)相…
Pytorch深度学习入门与实战二——卷积神经网络
1.卷积神经网络基本单元 空洞卷积 通过在卷积核中添加空洞(0元素),从而增大感受野,获取更多的信息。 感受野:在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,即特征映…
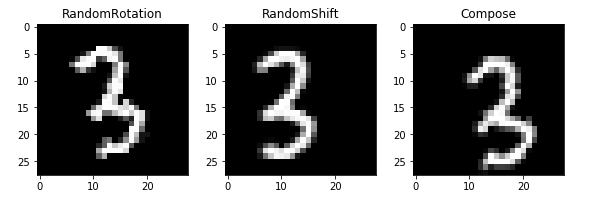
全网最详细最好懂 PyTorch CNN案例分析 识别手写数字
先来看一下这是什么任务。就是给你手写数组的图片,然后识别这是什么数字: 喜欢的话请关注我们的微信公众号~《你好世界炼丹师》。
公众号主要讲统计学,数据科学,机器学习,深度学习,以及一些参加Kaggle竞赛…
Ubuntu下安裝Python版OpenCV
Ubuntu下安裝Python版OpenCV前言安裝指令踩坑記錄測試參考連結前言
筆者試著要在Ubuntu系統下安裝Python版的OpenCV,一開始只使用pip來安裝,但卻會報錯。後來才發現原來它還需要幾個debian的package才能成功運行。
安裝指令
這裡直接給出可以成功執行…

【AI视野·今日CV 计算机视觉论文速览 第275期】Wed, 25 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Wed, 25 Oct 2023 Totally 61 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Synthetic Data as Validation Authors Qixin Hu, Alan Yuille, Zongwei Zhou这项研究利用合成数据作为验证集,…

【AI视野·今日CV 计算机视觉论文速览 第254期】Tue, 26 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Tue, 26 Sep 2023 (showing first 100 of 170 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Chop & Learn: Recognizing and Generating Object-State Compositions Authors…
ECCV 2014 Oral Paper
今年的ECCV 的paper已经挂到了网上,本文整了其中Oral Paper。 一,Tracking and Activity Recognition

在VS2010中应用SIFT(C)源码
SIFT的实现有很多版本,具体方式都是那么几个,找个好用的不太容易,因为对于代码不熟练者各种版本用起来都有点水土不服,需要调整调整才行。本人是在VS2010下使用的Rob Hess的源码。
一、前提 安装Opencv,详见ÿ…
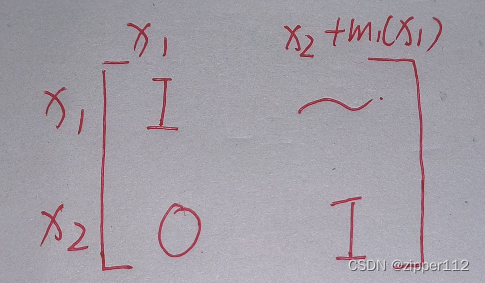
Flow-based models(NICE);流模型+NICE+代码实现
参考:
李宏毅春季机器学习NICE: Non-linear Independent Components Estimationhttps://github.com/gmum/nice_pytorch 文章目录 大致思想数学预备知识Jacobian矩阵行列式以及其几何意义Change of Variable Theorem Flow-based modelNICE理论代码 大致思想
Flow-B…
处理文件、摄像头和图形用户界面
处理文件、摄像头和图形用户界面
1、图像的读取和图片格式的改写
import cv2img cv2.imread("./pic.jpg",cv2.IMREAD_GRAYSCALE)
cv.imwrite("./pic.pgm,img)
图片文件的改写:只需要制定要保存的文件格式就可以,(.pgm .p…
2021.5.10开始实习了
五一之前,师兄说新大楼有招聘,拿着简历我就去了,投了两家公司的算法实习,其中一家公司约了我5.6面试,其实五一期间准备面试很少,都在学习,所在6号面试的时候就显得捉襟见肘,问了我几…
Caffe + Ubuntu 15.04 + CUDA 7.5 新手安装配置指南
Caffe Ubuntu 15.04 CUDA 7.5 新手安装配置指南 返回 特别说明: 0. Caffe 官网地址:http://caffe.berkeleyvision.org/ 1. 本文为作者亲自实验完成,但仅限用于学术交流使用,使用本指南造成的任何不良后果由使用者自行承担&#…
推荐收藏!腾讯算法岗面试题9道(含答案)
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂同学、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
今天我整…
区域生长算法的一种C++实现
区域生长算法的一种C实现 区域生长算法是一种图像分割方法,能够将图像中具有相同特征的连通区域分割出来,同时保证较好的边缘信息。 区域生长算法的优点是简单,容易实现;但空间和时间复杂度较高,对分割图像要求较高&am…
![A.[OCR]基于PaddleOCR的多视角集装箱箱号检测识别,实现检测识别模型串联推理。](https://img-blog.csdnimg.cn/img_convert/b580fb04427f29dd71f5a0531b6313bd.jpeg)
A.[OCR]基于PaddleOCR的多视角集装箱箱号检测识别,实现检测识别模型串联推理。
基于PaddleOCR的多视角集装箱箱号检测识别
一、项目介绍
集装箱号是指装运出口货物集装箱的箱号,填写托运单时必填此项。标准箱号构成基本概念:采用ISO6346(1995)标准
标准集装箱箱号由11位编码组成,如:…
Mask_RCNN代碼研讀(matterport版本)系列文(一)- ResNet部份
Mask_RCNN代碼研讀(matterport版本)系列文(一)- ResNet部份前言訓練及推論模式中的共同部份ResNet Graphidentity_blockconv_blockresnet_graphStage 1Stage 2Stage 3Stage 4Stage 5小結前言
在開始閱讀這近三千行的代碼之前&…
Invarient facial recongnition
for later~
代码阅读
1. 加载trainset
import argparse
import logging
import os
import numpy as npimport torch
from torch import distributed
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom backbones import get_…
【公益项目】你一定要来看看!高中生使用swiftUI调用苹果OCR API,离线扫描图书文字并朗读,帮助视障人士阅读纸质书籍IOS软件
《 ReadingEyes阅目 》是身为高中生和前OIer的我,在暑期构思并学习,利用闲暇时间编写的项目,效果视频已上传至BILIBILI,点此查看
该软件是利用苹果OCR API来实现扫描图书文字并朗读,旨在帮助视障人士阅读纸质书籍的IO…
DSO直接法SLAM相关资料整理
论文:Direct sparse odometry 一份不错的中文代码注释:https://github.com/alalagong/DSO 一些不错的博客: 高翔博士关于DSO直接法的理论推导 直接法光度误差导数推导——很棒 DSO初始化流程 DSO初始化 DSO追踪与优化 从数据流看DSO calcResA…

『论文精读』Data-efficient image Transformers(DeiT)论文解读
『论文精读』Data-efficient image Transformers(DeiT)论文解读 文章目录 一. DeiT简介二. 知识蒸馏(knowledge distillation)2.1. KLDivloss2.2. 蒸馏温度 τ \tau τ2.3. distillation in transformer 三. better hyperparameter四. data augmentation五. label smoothing参…
小红书多模态团队建立新「扩散模型」:解码脑电波,高清还原人眼所见
近些年,研究人员们对探索大脑如何解读视觉信息,并试图还原出原始图像一直孜孜不倦。去年一篇被 CVPR 录用的论文,通过扩散模型重建视觉影像,给出了非常炸裂的效果—— AI 不光通过脑电波知道你看到了什么,并且帮你画了…

YOLOv3 阅读笔记
# YOLOv3 阅读笔记
论文链接:https://arxiv.org/abs/1804.02767
代码链接:https://github.com/pjreddie/darknet 非官方winLinux版:https://github.com/AlexeyAB/darknet 一句话总结:概述:结果论文细节:detection网络结构anchor获取与设定以上网络结构与anchor与源码对应: 实…
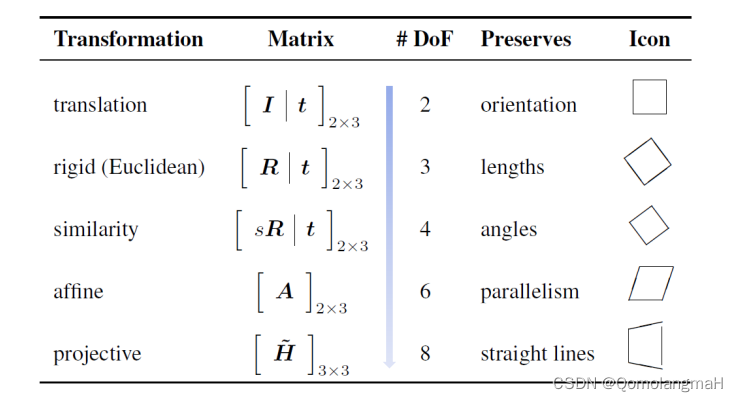
【计算机视觉】二、图像形成:2、几何基元和几何变换:2D变换
文章目录 一、向量和矩阵的基本运算二、几何基元和变换1、几何基元(Geometric Primitives)2、几何变换(Geometric Transformations)1. 各种变换的关系2. 变换公式3. 2D变换的层次4. python实现 一、向量和矩阵的基本运算
【计算机视觉】二、图像形成:1、向量和矩阵…

pytorch CV入门 - 汇总
初次编辑:2024/2/14;最后编辑:2024/3/9
参考网站-微软教程:https://learn.microsoft.com/en-us/training/modules/intro-computer-vision-pytorch
更多的内容可以参考本作者其他专栏:
Pytorch基础:https…
计算机视觉任务不能或缺的库opencv简单介绍和概述
OpenCV是一个开源的计算机视觉库,提供了数百种计算机视觉算法。这个库采用了模块化的结构,包含多个库。主要模块包括核心功能、图像处理、视频分析、相机校准与3D重建、2D特征框架、对象检测、高级GUI和视频输入/输出等。每个模块提供了一系列相关的功能…
2024淘天阿里妈妈算法工程师一面&二面 面试题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
今天我们…
数字图像处理(研究生)课程总结——面试CV岗备用
数字图像处理(研究生)课程总结——面试CV岗备用
一.边缘检测 DoG和LoG算子 知识链接:https://blog.csdn.net/gnehcuoz/article/details/52793654 霍夫变换原理——检测间断点边界形状。 简述:它通过将图像坐标空间变换到参数空间…
用sklearn+opencv-python过简单的4位数字验证码
目录
生成验证码图片
用opencv-python处理图片
制作训练数据集
训练模型
识别验证码
总结与提高 在本节我们将使用sklearn和opencv-python这两个库过掉简单的4位数字验证码,验证码风格如下所示。 生成验证码图片
要识别验证码,我们就需要大量验证…
DLT算法求解单应性矩阵
DLT算法求解单应性矩阵
原理:
单应性矩阵描述了两个图像之间的投影变换关系,即从一张图到另一张图的变换。
下面是DLT算法的基本原理:
构建投影方程: 对于两个图像中的对应点 ( x , y , 1 ) (x, y, 1) (x,y,1) 和 ( u , v ,…
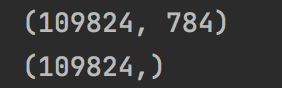
使用pyscenedetect进行视频场景切割
1. 简介
在视频剪辑有转场一词:一个视频场景转换到另一个视频场景,场景与场景之间的过渡或转换,就叫做转场。 本篇介绍一个强大的开源工具PySceneDetect,它是一款基于opencv的视频场景切换检测和分析工具,项目地址: h…

深度学习入门 | HOG梯度直方图特征
文章目录HOG特征1. 数据预处理2. 计算梯度大小和方向3. 计算88cells的梯度直方图4. 1616 Block Normalization即block归一化5. 得到HOG特征向量,计算维度可视化HOGHOG特征
Histogram of Oriented Gradients 直译过来就是向量梯度直方图,用来记录边缘特征…
整理了197个经典SOTA模型,涵盖图像分类、目标检测、推荐系统等13个方向
今天来帮大家回顾一下计算机视觉、自然语言处理等热门研究领域的197个经典SOTA模型,涵盖了图像分类、图像生成、文本分类、强化学习、目标检测、推荐系统、语音识别等13个细分方向。建议大家收藏了慢慢看,下一篇顶会的idea这就来了~
由于整理的SOTA模型…
基于SIFT+Kmeans+LDA的图片分类器的实现
http://www.cnblogs.com/freedomshe/archive/2012/04/24/2468747.html PS: 很久没做CV的事情了,这是很早以前刚入门时候的一篇,以后再有CV相关工作会发布在新的个人站点:http://my.phirobot.com/blog/category/cv.html CV分类下。 posted 2…

【计算机视觉】二、图像形成——实验:2D变换编辑器2.0(Pygame)
文章目录 一、向量和矩阵的基本运算二、几何基元和变换1、几何基元(Geometric Primitives)2、几何变换(Geometric Transformations)2D变换编辑器0. 项目结构1. Package: guibutton.pywindow.py1. __init__(self, width, height, title)2. add_buttons(self)3. clear(self)4. dr…

目标检测新SOTA:YOLOv9 问世,新架构让传统卷积重焕生机
在目标检测领域,YOLOv9 实现了一代更比一代强,利用新架构和方法让传统卷积在参数利用率方面胜过了深度卷积。 继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了!
我们知道,YOLO 是一种基于图像全局信息进行…

文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks 1. 内容简介2. 模型结构 1. 数据处理2. 模型结构设计3. 模型训练 3. 实验结果 1. 图文联合任务 1. Visual Question Answering (VQA)2. Visual Reasoning3. Imag…

【AI视野·今日CV 计算机视觉论文速览 第261期】Thu, 5 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 5 Oct 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models Authors Jianglong Ye, …
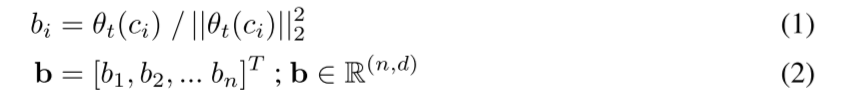
论文解读Language-based Action Concept Spaces Improve Video Self-Supervised Learning
Language-based Action Concept Spaces Improve Video Self-Supervised Learning
基于语言的动作概念空间改善视频自我监督学习
备注: 最近研究需要,先将翻译概括内容放这里
论文地址:论文
https://arxiv.org/pdf/2307.10922v3.pdf 摘要
最近的对比…

「图像 merge」无中生有制造数据
在进行一个新项目的时候,往往缺少一些真实数据,导致没办法进行模型训练,这时候就需要算法工程师自行制作一些数据了,比如这篇文章分享的 bag 目标检测,在检测区域没有真实的 bag数据
此时,就可以采用图像拼…

【AI视野·今日CV 计算机视觉论文速览 第259期】Tue, 3 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Tue, 3 Oct 2023 (showing first 100 of 167 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
GPT-Driver: Learning to Drive with GPT Authors Jiageng Mao, Yuxi Qian, Hang Zha…
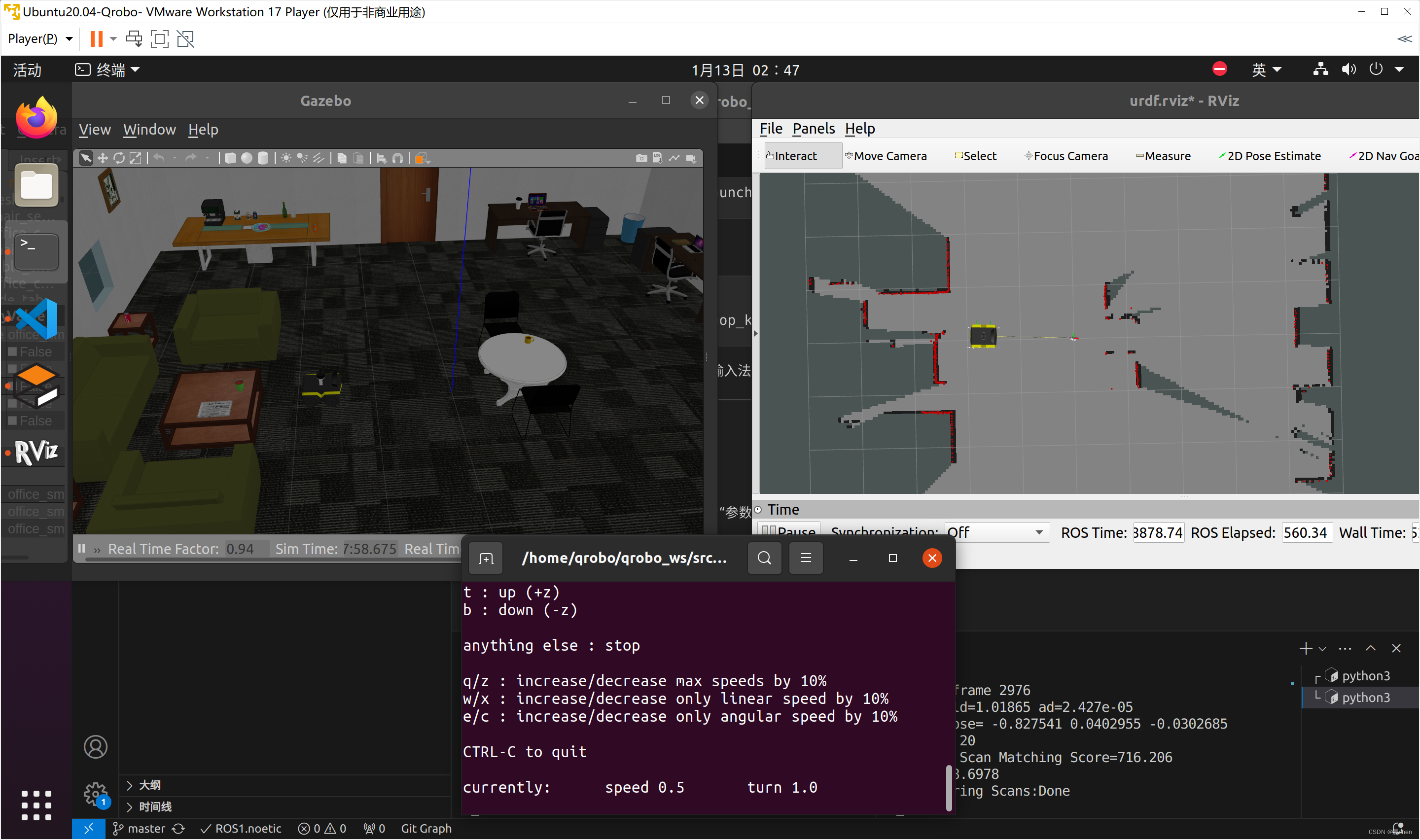
仿真机器人-深度学习CV和激光雷达感知(项目2)day01【项目介绍与环境搭建】
文章目录 前言项目介绍功能与技术简介硬件要求环境配置虚拟机运行项目demo 前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫本文内容是我为复试准备的第二个项目 💫欢迎大家的关注,我的博客主要关注…