Windowing TVFs
Windowing table-valued functions (Windowing TVFs),即窗口表值函数
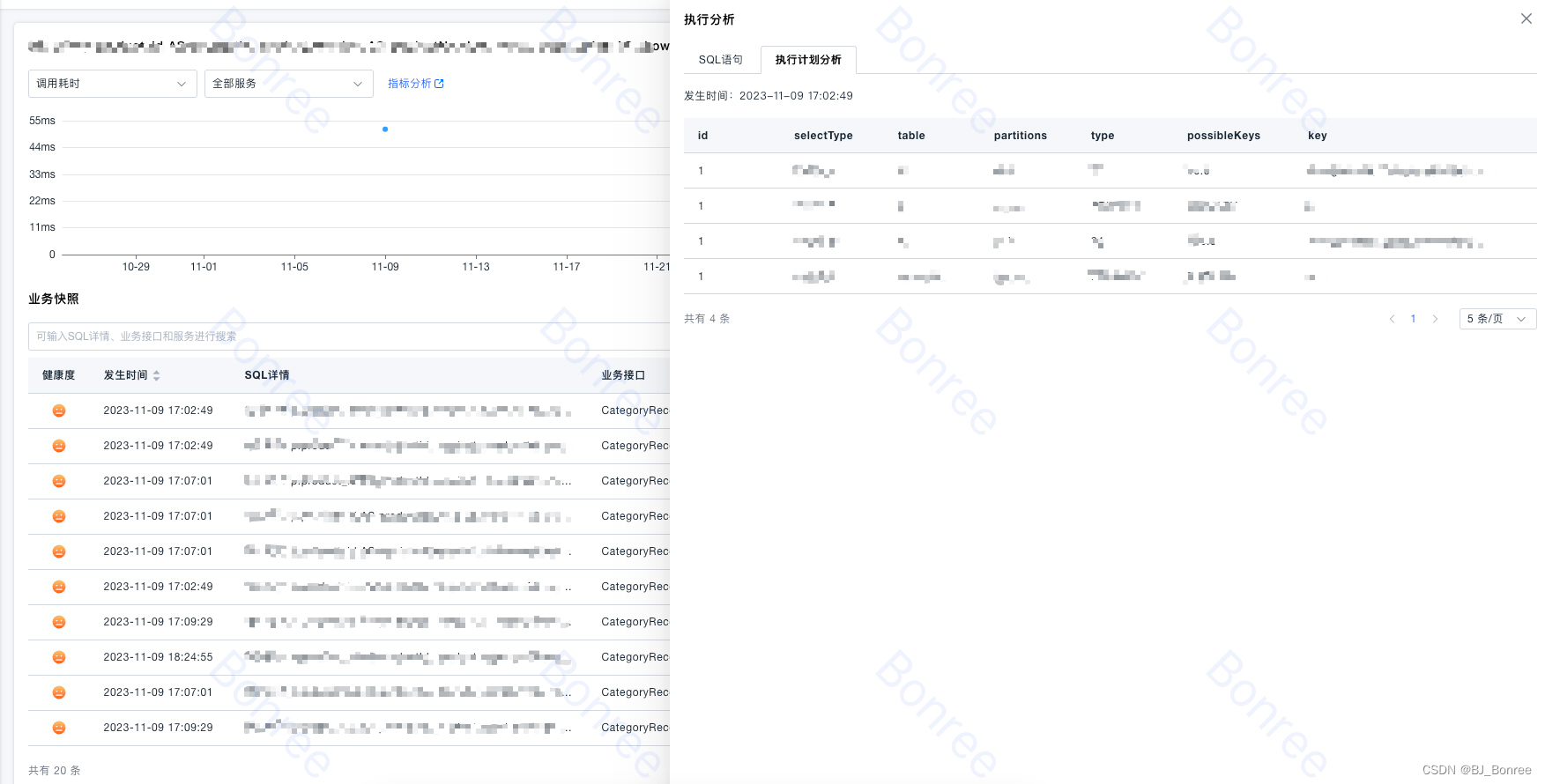
注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,window_end
-
TUMBLE函数采用三个必需参数,一个可选参数:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到滚动窗口。
size:是指定翻滚窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
HOP采用 4 个必需参数和 1 个可选参数:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到跳跃窗口。
slide:是指定连续跳跃窗口开始之间的持续时间的持续时间
size:是指定跳跃窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
CUMULATE采用 4 个必需参数和 1 个可选参数:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到累积窗口。
step:是指定连续累积窗口末尾之间增加的窗口大小的持续时间。
size:是指定累积窗口最大宽度的持续时间。size必须是 的整数倍step。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。
滚动窗口
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
create view tmp as
select
COALESCE(cur['group_name'], src['group_name']) group_name,
COALESCE(cur['batch_number'], src['batch_number']) batch_number,
event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name
滑动窗口
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
create view tmp as
select
COALESCE(cur['group_name'], src['group_name']) group_name,
COALESCE(cur['batch_number'], src['batch_number']) batch_number,
event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(HOP(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name
累计窗口
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
create view tmp as
select
COALESCE(cur['group_name'], src['group_name']) group_name,
COALESCE(cur['batch_number'], src['batch_number']) batch_number,
event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' HOUR,INTERVAL '24' HOURS)) --从零点开始累计
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' MINUTE,INTERVAL '1' HOURS))
group by window_start,window_end,window_time,group_name
窗口聚合-多维分析
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
create view tmp as
select
COALESCE(cur['group_name'], src['group_name']) group_name,
COALESCE(cur['batch_number'], src['batch_number']) batch_number,
event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区
--实例1:整体聚合
select window_start,window_end,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end
--实例2:根据字段聚合,n个维度
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,group_name
--实例3:多维分析GROUPING SETS
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name)) --等同于 实例2
group by window_start,window_end,GROUPING SETS((group_name), ()) --等同于 实例1 union all 实例2
--实例4:多维分析GROUPING SETS,多个字段
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name,batch_number),(group_name),(batch_number),())
--实例5:多维分析CUBE 2^n个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,CUBE(group_name) --等同于group by window_start,window_end,GROUPING SETS((group_name), ())
group by window_start,window_end,CUBE(group_name,batch_number) --等同于实例4
--实例6:多维分析ROLLUP n+1个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,ROLLUP(group_name) --等同于 实例1 union all 实例2
group by window_start,window_end,ROLLUP(group_name,batch_number) --等同于GROUPING SETS((group_name,batch_number),(group_name),())
窗口topN
Window Top-N 语句的语法:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name) -- relation applied windowing TVF
WHERE rownum <= N [AND conditions]
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
create view tmp as
select
COALESCE(cur['group_name'], src['group_name']) group_name,
COALESCE(cur['batch_number'], src['batch_number']) batch_number,
event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区
--方式1:窗口 Top-N 紧随窗口聚合之后
create view tmp_window as
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS))
group by window_start,window_end,window_time,group_name;
--计算每个翻滚 24小时窗口内pv最高的前 3 名机构(即每天PV最高的前三名)
select * from
(
select * ,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY cnt DESC) as rn
from tmp_window
) t
where rn <=3
--计算每个机构pv最高的前 3天
select * from
(
select * ,ROW_NUMBER() OVER (PARTITION BY group_name ORDER BY cnt DESC) as rn
from tmp_window
) t
where rn <=3
--方式2:窗口 Top-N 紧随窗口 TVF 之后
select *
from
(
select
window_start
,window_end
,window_time
,group_name
,ts
,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY ts DESC) AS rn
from TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS))
)
where rn <=3
窗口去重
Flink使用去重的方式,就像Window Top-N查询ROW_NUMBER()的方式一样。理论上,
窗口重复数据删除是窗口 Top-N 的一种特殊情况,其中 N 为 1,并且按处理时间或事件时间排序
Window Deduplication 语句的语法:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]
ORDER BY time_attr [asc|desc]) AS rownum
FROM table_name) -- relation applied windowing TVF
WHERE (rownum = 1 | rownum <=1 | rownum < 2) [AND conditions]
CREATE TABLE kafka_table(
mid bigint,
db string,
sch string,
tab string,
opt string,
ts bigint,
ddl string,
err string,
src map < string, string >,
cur map < string, string >,
cus map < string, string >,
group_name as COALESCE(cur['group_name'], src['group_name']),
batch_number as COALESCE(cur['batch_number'], src['batch_number']),
event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)
WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't0',
'properties.bootstrap.servers' = 'xx.xx.xx.xx:9092',
'scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset
'format' = 'json'
);
select *
from
(
select
window_start
,window_end
,group_name
,event_time
,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY event_time DESC) AS rn
from TABLE(TUMBLE(TABLE kafka_table, DESCRIPTOR(event_time), INTERVAL '24' HOURS))
)
where rn =1
![[BUG] Hadoop-3.3.4集群yarn管理页面子队列不显示任务](https://img-blog.csdnimg.cn/img_convert/37336e757cd0f068ab4399b7ee2fb63b.png)


![[OCR]Python 3 下的文字识别CnOCR](https://img-blog.csdnimg.cn/direct/65b58a3cdc23427fbe0d9dcdc33baf63.png)