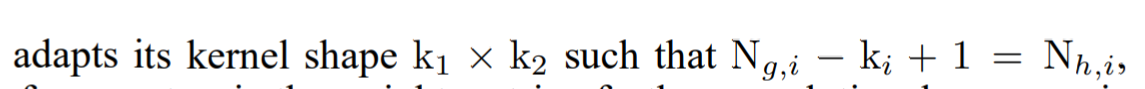使用relation的蒸馏代替传统的feature map或者logits蒸馏
如何建模relation?
就是feature map的内积
比如两个residual block,输出的feature map大小相等,但channel数可能不同,比如F1:(h,w,m),F2:(h,w,n),输出relation:(m,n),其实就是F1的m个channel和F2的n个channel之间的关系。
F1的m个channel分别和F2的n个channel相乘,每次会得到一个值,最后就得到了(m,n)的矩阵
如何比较T和S的relation
首先T和S得有相同数量的relation,也就是说,如果T分为了10个block,也就是说会有9个relation map,那么S也得分为10个block,得到9个relation map,不过如果T和S的relation map不一样大怎么办?比如T是(m,n),S是(m1,n1)怎么办?=>本文不考虑这种情况

比如上图,一个是32个residual layers的resnet,一个是14层的,上面每5个layer划一个大block,下面每2个layer划一个大block,最终得到的relation map数量是一样多的,因此可以一一对应
由于residual modules不会改变feature map大小(因为CNN加了padding),pooling是单独做的,因此上面划大block其实都是在pooling处加的,这样T和S的relation map的大小也能对上。
这样一对一计算L2 loss,然后求个平均,就得到了一阶段的Loss。
第二阶段
一阶段是用relation loss来训,二阶段就直接用gt来训