1 数组
1.1 集合、列表、数组的联系与区别
集合:由一个或多个确定的元素所构成的整体。类型不一定相同、确定、无序、互异。
列表(又称线性列表):按照一定的线性顺序,排列而成的数据项的集合。类型不一定相同、有序、不一定互异。包括数组、栈、队列、链表等
数组(Array):是一种元素在内存中连续存储的线性列表数据结构。类型相同(静态语言)或类型可不同(动态语言)、有序、不一定互异。
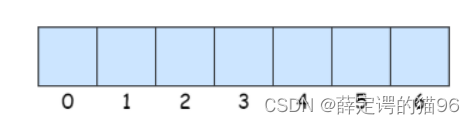
1.2 数组基本操作
读取元素:通过数组的 索引(下标)访问数组中的元素。随机访问——时间复杂度O(1)。
为什么数组下标从0开始?
因为,下标从0开始的计算机寻址公式:

相比下标从1开始,a[1]表示数组的首地址的寻址公式:
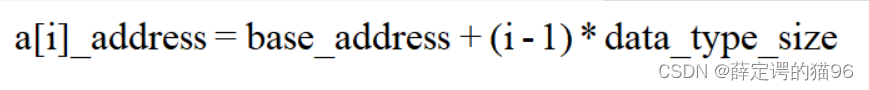
访问数组元素少一次减法运算,这对于CPU来说,就是少了一次减法指令。
查找元素:从索引 0 处开始,逐步向后查询。时间复杂度 O(n);
插入元素:
- 尾部插入,通过数组的长度计算出即将插入元素的内存地址,然后将该元素插入到尾部。时间复杂度O(1);
- 非尾部插入,将尾部到索引下标之间的元素依次后移,将元素插入索引对应的空出空间。时间复杂度O(n)。
- JavaScript超出数组长度范围插入,对超出部分会自动设置为undefined。
删除元素:
- 尾部删除,直接删除。时间复杂度O(1) ;
- 非尾部删除,删除指定索引元素,后续元素依次向前填补,时间复杂度为 O(n);
更改元素:通过数组的索引(下标)赋值更改。时间复杂度O(1);
二维数组的本质上仍然是一个一维数组,内部的一维数组仍然从索引 0 开始。m * n的二维数组寻址公式为:
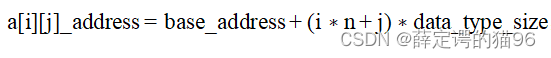 ,
,
其中第k个一维数组的首元素的地址为:
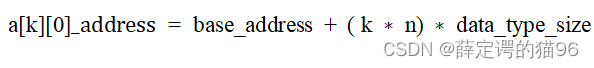 。
。
1.3 数组的优劣
高效O(1)的随机访问,低效O(n)的查找、插入和删除元素。因此,数组所适合的是读、改操作多,查、删操作少的场景。
1.4 剑指 offer 数组算法题(typescript 版)
二维数组的查找
旋转数组的最小数字
调整数组顺序使奇数位于偶数前面
数组中出现次数超过一半的数字
连续子数组的最大和
把数组排成最小的数
数组的逆序对
数字在排序数组的出现次数
数组中只出现一次的两个数字(其余出现均两次)
数组中重复的数字
构建乘积数组
顺时针打印矩阵
最小的K个数
和为S的两个数字
扑克牌中的顺子
滑动窗口的最大值
唯一只出现一次的数字(其余均出现两次)
2 字符串
字符串是由零个或多个字符组成的有限序列。用成对双引号或成对单引号的形式存在
2.1 字符串基本操作
与数组类似,通过下标访问其中字符。
字符串可能是可变(C++),也可能是不可变的(python,JavaScript),不可变意味着初始化后不能修改其中字符。对于不可变的字符串,连接操作意味着首先为新字符串分配足够的空间,复制旧字符串中的内容并附加到新字符串,时间复杂度为O(N)。
2.2 剑指 offer 字符串算法题(typescript 版)
字符串的排列
字符串的空格替换
第一个只出现一次的字符
左旋字符串
翻转单词顺序
把字符串转换成数字
正则表达匹配
表示数值的字符串
字符串中重复次数最多的字符
Hex颜色值转rgb
无重复字符的最长子串
千分位分隔数字
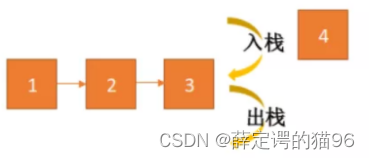
3 栈
栈是一种后入先出(LIFO)的线性逻辑存储结构。只允许在栈顶进行进出操作。

3.1 栈基本操作
基本操作包括:入栈(push)/出栈(pop)/获取栈顶元素(peek)。
栈的实现主要有两种: 1. 数组实现,即顺序栈 2. 链表实现,即链式栈
无论是以数组还是以链表实现,入栈、出栈的时间复杂度都是O(1)。
栈的应用比如函数执行/括号匹配/表达式计算/浏览器前进后退。

3.2 设计栈
3.2.1 数组实现栈
class ArrayStack<T> {
items: T[];
constructor() {
this.items = [];
}
/**
* 入栈
* @param item
*/
push(item: T) {
this.items.push(item);
}
/**
* 出栈
* @returns
*/
pop() {
if (this.isEmpty()) throw new Error('栈空');
return this.items.pop();
}
/**
* 获取栈顶元素
* @returns
*/
peek() {
if (this.isEmpty()) throw new Error('栈空');
return this.items[this.items.length - 1];
}
/**
* 判空
* @returns
*/
isEmpty() {
return this.items.length === 0;
}
/**
* 获取栈元素的个数
* @returns
*/
getSize() {
return this.items.length;
}
}3.2.2 链表实现栈
class LinkStack<T> {
// 栈的长度
size: number;
// 栈顶指针
top: LinkNode<T> | null;
constructor() {
this.size = 0;
this.top = null;
}
/**
* 入栈
* @param item
*/
push(val: T) {
let node = new LinkNode(val);
if (this.top === null) {
// 栈空
this.top = node;
} else {
// 栈非空
node.next = this.top;
this.top = node;
}
this.size = this.size + 1;
}
/**
* 出栈
* @returns
*/
pop() {
if (this.top === null) {
// 栈空
throw new Error('栈空');
} else {
// 栈非空
const data = this.top.val; // 栈顶元素值
this.top = this.top.next; // 新栈顶
this.size = this.size - 1;
return data;
}
}
/**
* 获取栈顶元素
* @returns
*/
peek() {
if (this.top === null) {
// 栈空
throw new Error('栈空');
} else {
return this.top.val;
}
}
/**
* 判空
* @returns
*/
isEmpty() {
return this.top === null;
}
/**
* 获取栈元素的个数
* @returns
*/
getSize() {
return this.size;
}
}
3.3 剑指 offer 栈算法题( typescript 版)
包含min函数的栈
栈的压入、弹出序列
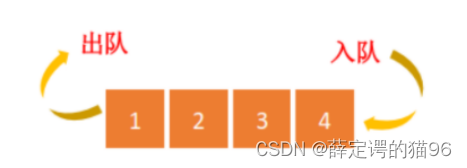
4 队列
队列是一种先入先出(FIFO)的线性逻辑存储结构。只允许在队首进行出队(即delete删除)操作,队尾进行入队(即insert插入)操作。
4.1 队列基本操作
队列的基本操作包括:入队 (enqueue)/ 出队 (dequeue)/ 获取队头元素(peek)
队列的实现主要有两种: 1. 数组实现,即顺序队列 2. 链表实现,即链式队列。
无论是以数组还是以链表实现,入队、出队的时间复杂度都是O(1)。
4.2 设计队列
4.2.1 数组顺序队列
使用数组实现,使用shift出队时每次都要移动队列元素,效率不高。改进方案是可以队列初始化时就需要规定队列长度,通过判断队尾是否有空间,有就让元素一直入队,直到队尾没有空间位置,然后进行整体进行一次搬移,这样优化了入队的效率,平均时间复杂度还是 O(1)。
class ArrayQueue<T> {
items: T[];
constructor() {
this.items = [];
}
/**
* 入队
* @param item
*/
push(item: T) {
this.items.push(item);
}
/**
* 出队
* @returns
*/
pop() {
if (this.isEmpty()) throw new Error('队列空');
return this.items.shift();
}
/**
* 获取队顶元素
* @returns
*/
peek() {
if (this.isEmpty()) throw new Error('队列空');
return this.items[0];
}
/**
* 判空
* @returns
*/
isEmpty() {
return this.items.length === 0;
}
/**
* 获取队元素的个数
* @returns
*/
getSize() {
return this.items.length;
}
}4.2.2 数组循环队列
数组实现,初始化需指定队列容量capacity,留一个空位,队空条件 head = tail,队满条件 head =( tail + 1) % capacity,队列元素个数(tail - head + capacity) % capacity)。
class LoopQueue {
// 存放元素的数组
values: (number | undefined)[];
// 当前元素个数
count: number;
// 队的长度
capacity: number;
// 队尾
head: number;
// 队尾
tail: number;
constructor(capacity: number) {
this.head = 0;
this.tail = 0;
this.capacity = capacity;
this.count = 0;
this.values = new Array(capacity);
}
/**
* 入队
* @param item
*/
enQueue(val: number) {
if (this.isFull()) {
throw new Error('队满');
}
this.values[this.tail] = val;
this.tail = (this.tail + 1) % this.capacity;
this.count = this.count + 1;
return true;
}
/**
* 出队
* @returns
*/
deQueue(): number {
if (this.isEmpty()) {
throw new Error('队空');
}
const value = this.values[this.head] as number;
this.values[this.head] = undefined;
this.head = (this.head + 1) % this.capacity;
this.count = this.count - 1;
return value;
}
/**
* 获取队头元素
* @returns
*/
peek() {
if (this.isEmpty()) {
throw new Error('队空');
}
const value = this.values[this.head];
return value;
}
/**
* 判空
* @returns
*/
isEmpty() {
// 或 return this.head === this.tail
return this.count === 0;
}
/**
* 判满
* @returns
*/
isFull() {
// 或 return this.head === (this.tail + 1) % this.capacity
return this.count === this.capacity - 1;
}
/**
* 获取队元素的个数
* @returns
*/
getSize() {
return this.count;
}
/**
* 清空队列
* @returns
*/
clear() {
this.head = 0;
this.tail = 0;
this.count = 0;
this.values = new Array(this.capacity);
return true;
}
}4.2.3 链式顺序队列
class LinkQueue<T> {
// 队的长度
size: number;
// 队尾指针
head: LinkNode<T> | null;
// 队尾指针
tail: LinkNode<T> | null;
constructor() {
this.size = 0;
this.head = null;
this.tail = null;
}
/**
* 入队
* @param item
*/
enQueue(val: T) {
let node = new LinkNode(val);
if (this.size === 0) {
this.head = node;
this.tail = node;
} else {
this.tail!.next = node;
this.tail = this.tail!.next;
}
this.size = this.size + 1;
}
/**
* 出队
* @returns
*/
deQueue() {
if (this.size === 0) {
// 队空
throw new Error('队空');
} else {
// 队非空
const node = this.head;
this.head = node!.next;
this.size = this.size - 1;
return node!.val;
}
}
/**
* 获取队头元素
* @returns
*/
peek() {
if (this.size === 0) {
// 队空
throw new Error('队空');
} else {
return this.head!.val;
}
}
/**
* 判空
* @returns
*/
isEmpty() {
return this.size === 0;
}
/**
* 获取队元素的个数
* @returns
*/
getSize() {
return this.size;
}
}
4.3 剑指 offer 队列算法题( typescript 版)
5 链表
链表是线性数据结构(数据元素之间存在着“一对一”关系),链表中的每个元素是一个包含数据data和引用字段的对象,引用字段只有next为单向链表,同时又prev和next为双向链表。
5.1 链表基本操作
链表读取第 i 个节点或查找指定值的节点,均需要从头遍历,时间复杂度为O(n)。
在不考虑查找节点的过程的情况下,更新(替换data),插入(新节点next指针指向插入位置节点,前一节点的next指针指向新节点)、删除(前一节点next指针指向下一节点,当前节点置空),时间复杂度均为O(1)。
5.2 设计链表
设计单向链表的实现。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。假设链表中的所有节点都是 0 ~ size - 1 的。
class LinkNode<T> {
val: T;
next: LinkNode<T> | null;
constructor(val: T, next?: LinkNode<T> | null) {
this.val = val;
this.next = next ?? null;
}
}
class MyLinkedList<T> {
size: number; // 链表长度
head: LinkNode<T> | null; // 头结点
constructor() {
this.size = 0;
this.head = null;
}
/**
* 获取链表中 index 位置的节点。如果索引无效,则返回 null。
* @param index
*/
getNode(index: number): LinkNode<T> | null {
if (index < 0 || index >= this.size) {
return null;
}
// index 有效,所以 node.next 和 node.val 是存在的。
let node = this.head as LinkNode<T>;
for (let i = 0; i < index; i++) {
node = node.next as LinkNode<T>;
}
return node;
}
/**
* 获取链表中 index 位置的节点值。如果索引无效,则返回-1。
* @param index
*/
get(index: number): T | -1 {
const node = this.getNode(index);
return node?.val ?? -1;
}
/**
* 在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
* @param val
*/
addAtHead(val: T): void {
const newHead = new LinkNode(val);
newHead.next = this.head;
this.head = newHead;
this.size = this.size + 1;
}
/**
* 将值为 val 的节点追加到链表的最后一个元素。
* @param val
*/
addAtTail(val: T): void {
const oldTailNode = this.getNode(this.size - 1);
const newTailNode = new LinkNode(val);
this.size = this.size + 1;
if (oldTailNode === null) {
this.head = new LinkNode(val);
return;
}
oldTailNode.next = newTailNode;
}
/**
* 在链表中的 index 位置之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果 index 小于0,则在头部插入节点。
* @param index
* @param val
*/
addAtIndex(index: number, val: T): void {
if (index > this.size) return;
// 尾插
if (index === this.size) {
this.addAtTail(val);
return;
}
// 头插
if (index < 0) {
this.addAtHead(val);
return;
}
const prevNode = this.getNode(index - 1) as LinkNode<T>;
const node = new LinkNode(val);
node.next = prevNode.next;
prevNode.next = node;
this.size = this.size + 1;
}
/**
* 如果索引 index 有效,则删除链表中的第 index 个节点。
* @param index
*/
deleteAtIndex(index: number): void {
// index 无效
if (index < 0 || index >= this.size || this.size === 0) return;
this.size = this.size - 1;
// 删除头节点
if (index === 0) {
this.head = this.head?.next as LinkNode<T> | null;
return;
}
const prevNode = this.getNode(index - 1) as LinkNode<T>;
const deleteNode = prevNode.next as LinkNode<T>;
prevNode.next = deleteNode.next;
}
}5.3 剑指 offer 链表算法题(typescript 版)
从尾到头打印链表
链表倒数第k个节点
反转链表
复杂链表的复制
删除链表中的重复节点
两个链表的第一个公共节点
链表中环的入口节点
6 树
6.1 基本概念
树是非线性逻辑结构,是n(n≥0)个节点的有限集。当n=0时,称为空树。树的每个节点有一个节点值和包含所有子节点的列表,从图的角度看,即N个节点的N - 1条边的有向无环图。树的最大层级数,被称为树的高度或深度。树中最多子节点数称为树的度。
而最常用且典型的是二叉树,即每个节点最多只有两个子节点。两个孩子节点的顺序是固定的(与二度树不同)。
满二叉树的所有非叶子节点都存在左右孩子,并且所有叶子节点都在同一层级上。
完全二叉树是具有与同深度的按层级顺序1 到 n 编号的满二叉树完全对应的节点编号的二叉树。
二叉树是逻辑结构,物理结构可以是链式存储结构,或者是数组。
链式存储结构:存储数据的data变量、指向左孩子的left指针、指向右孩子的right指针。
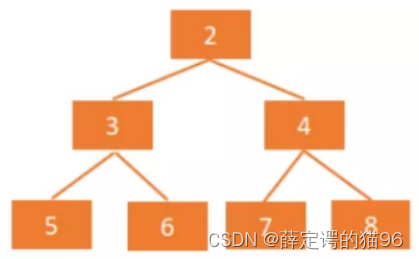
数组:按层级顺序把二叉树的节点放到数组中对应的位置上。如果某一个节点的左孩子或右孩子空缺,则数组的相应位置也空出来:
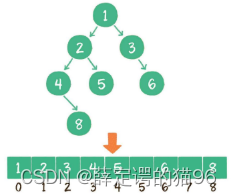
如上图,当前节点的下标是parent,那么它的左孩子节点下标就是2 × parent + 1;右孩子节点下标就是2 × parent + 2。反过来,假设一个左孩子节点的下标是lChild,那么它的父节点下标就是(lChild - 1)/ 2,同理,假设一个右孩子节点的下标是rChild,那么它的父节点下标就是(rChild - 2)/ 2,因此任何一个节点下标为child,其父节点下标为 Math.floor((child - 1) / 2)。数组存储更适合完全二叉树和满二叉树,对于稀疏二叉树,无疑是浪费空间的。
二叉树的应用主要是查找和维持相对顺序,比如二叉查找树(二叉搜索树)(左孩子 < 父节点 < 右孩子)和二叉堆(大根堆:左孩子 < 父节点 > 右孩子,小根堆:左孩子 > 父节点 < 右孩子)。对于一个节点分布相对均衡的二叉查找树来说,如果节点总数是n,那么搜索节点的时间复杂度就是O(logn),和树的深度是一样的。而如果考虑插入有序的序列,树的高度和搜索时间都会退化成O(n),就需要采用二叉树的自平衡,其应用有:红黑树、AVL树(二叉平衡树)等 。
6.2 二叉树的实现与遍历
二叉树遍历包括前序遍历,中序遍历,后序遍历,层序遍历。实现方法为递归遍历和迭代遍历。
二叉树的实现和递归遍历:
class BinaryTreeNode {
key: string | number; // 节点的键
parent: BinaryTreeNode | null; // 节点的父节点
value: any; // 节点的值
left: BinaryTreeNode | null; // 指向节点左孩子的指针
right: BinaryTreeNode | null; // 指向节点右孩子的指针
constructor(key: string | number, value = key, parent = null) {
this.key = key;
this.value = value;
this.parent = parent;
this.left = null;
this.right = null;
}
get isLeaf() {
return this.left === null && this.right === null;
}
get hasChildren() {
return !this.isLeaf;
}
}
class BinaryTree {
// 根节点
root: BinaryTreeNode;
constructor(key: string, value = key) {
this.root = new BinaryTreeNode(key, value);
}
/**
* 中序遍历 (首先遍历左子树,然后访问根节点,最后遍历右子树)
* @param node
*/
*inOrderTraversal(node = this.root) {
if (node) {
const { left, right } = node;
if (left) yield* this.inOrderTraversal(left);
yield node;
if (right) yield* this.inOrderTraversal(right);
}
}
/**
* 后序遍历 (首先遍历左子树,然后遍历右子树,最后访问根节点)
* @param node
*/
*postOrderTraversal(node = this.root) {
if (node) {
const { left, right } = node;
if (left) yield* this.postOrderTraversal(left);
if (right) yield* this.postOrderTraversal(right);
yield node;
}
}
/**
* 前序遍历 (首先访问根节点,然后遍历左子树,最后遍历右子树)
* @param node
*/
*preOrderTraversal(node = this.root) {
if (node) {
const { left, right } = node;
yield node;
if (left) yield* this.preOrderTraversal(left);
if (right) yield* this.preOrderTraversal(right);
}
}
/**
* 插入一个节点作为给定父节点的子节点
* @param parentNodeKey
* @param key
* @param value
* @param param3
* @returns
*/
insert(parentNodeKey: any, key: string, value = key, { left, right } = { left: true, right: true }) {
for (const node of this.preOrderTraversal()) {
if (node.key === parentNodeKey) {
// 插入到某父节点下,如果不指定则插入到左右孩子中的空的那个
const canInsertLeft = left && node.left === null;
const canInsertRight = right && node.right === null;
if (!canInsertLeft && !canInsertRight) return false; // 该父节点孩子节点不空余
if (canInsertLeft) {
node.left = new BinaryTreeNode(key, value, node);
return true;
}
if (canInsertRight) {
node.right = new BinaryTreeNode(key, value, node);
return true;
}
}
}
return false;
}
/**
* 从二叉树中删除一个节点及其子节点
* @param key
* @returns
*/
remove(key: string) {
for (const node of this.preOrderTraversal()) {
if (node.left.key === key) {
node.left = null;
return true;
}
if (node.right.key === key) {
node.right = null;
return true;
}
}
return false;
}
/**
* 检索给定节点
* @param key
* @returns
*/
find(key: string) {
for (const node of this.preOrderTraversal()) {
if (node.key === key) return node;
}
return undefined;
}
}前序遍历(迭代):
/**
* 前序遍历 (首先访问根节点,然后遍历左子树,最后遍历右子树)
*/
function preOrderTraversal(root: BinaryTreeNode | null) {
if (root === null) return [];
const result: number[] = [];
const stack = [root];
while (stack.length !== 0) {
const current = stack.pop()!;
result.push(current.value);
const lChild = current.left;
const rChild = current.right;
// 栈后进先出,因此先右孩子入栈,然后左孩子入栈
if (rChild !== null) stack.push(rChild);
if (lChild !== null) stack.push(lChild);
}
return result;
}中序遍历(迭代):
/**
* 中序遍历 (首先遍历左子树,然后访问根节点,最后遍历右子树)
*/
function inOrderTraversal(root: BinaryTreeNode | null) {
if (root === null) return [];
const result: number[] = [];
const stack: BinaryTreeNode[] = [];
let current: BinaryTreeNode | null = root;
while (stack.length !== 0 || current !== null) {
while (current !== null) {
// 一直遍历到最左孩子节点
stack.push(current);
current = current.left;
}
if (stack.length !== 0) {
// 栈非空
const node = stack.pop()!;
result.push(node.value);
current = node.right; // 当前 -> 右
}
}
return result;
}后序遍历(迭代):
/**
* 后序遍历 (首先遍历左子树,然后遍历右子树,最后访问根节点)
* @param node
*/
function postOrderTraversal(root: BinaryTreeNode | null) {
if (root === null) return [];
const result: number[] = [];
// 转变成遍历 根节点 -> 右节点 -> 左节点
// 遍历结果数组进行reverse, 即得到左节点 -> 右节点 -> 根节点
let stack = [root];
while (stack.length !== 0) {
let current = stack.pop()!;
result.push(current.value);
let lChild = current.left;
let rChild = current.right;
// 交换和前序的顺序
if (lChild !== null) stack.push(lChild);
if (rChild !== null) stack.push(rChild);
}
return result.reverse(); // 反转即可
}层序遍历:
/**
* 层序遍历 (逐层遍历树结构,借助队列实现)
* @param node
*/
function leverOrderTraversal(root: BinaryTreeNode | null) {
if (root === null) return [];
const result: number[] = [];
const queue = [root]; // 队列(先入先出)
while (queue.length !== 0) {
// 队列非空
const current = queue.shift()!; // 队首出队
result.push(current.value);
const leftChild = current.left;
const rightChild = current.right;
if (leftChild !== null) queue.push(leftChild);
if (rightChild !== null) queue.push(rightChild);
}
return result;
}6.3 剑指offer树算法题(typescript 版)
二叉树的深度
重建二叉树
从上到下打印二叉树
镜像二叉树
平衡二叉树
二叉树中和为某一值的路径
对称二叉树
二叉搜索树的后序遍历序列
二叉搜索树的第k大节点
树的子结构
二叉树的下一个节点
序列化二叉树
二叉搜索树与双向链表
7 图
7.1 图的基本操作
图是一种非线性逻辑结构,由一组节点或顶点以及一组表示这些节点之间连接的边组成。图可以是有向的或无向的,而它们的边可以分配数字权重。
7.2 图的设计与实现
interface Edge {
a: GraphNode; // 边的起始节点
b: GraphNode; // 边的目标节点
weight?: number; // 边的可选数字权重值
}
interface GraphNode {
key: string; // 节点的键
value: any; // 节点的值
}
class Graph {
directed: boolean;
nodes: GraphNode[];
edges: Map<string, Edge>;
constructor(directed = true) {
this.directed = directed;
this.nodes = [];
this.edges = new Map();
}
/**
* 插入具有特定键和值的新节点
* @param key
* @param value
*/
addNode(key: string, value = key) {
this.nodes.push({ key, value });
}
/**
* 在两个给定节点之间插入一条新边,可选择设置其权重
* @param a
* @param b
* @param weight
*/
addEdge(a: GraphNode, b: GraphNode, weight?: number) {
this.edges.set(JSON.stringify([a, b]), { a, b, weight });
if (!this.directed) this.edges.set(JSON.stringify([b, a]), { a: b, b: a, weight });
}
/**
* 删除具有指定键的节点
* @param key
*/
removeNode(key: string) {
this.nodes = this.nodes.filter((n: { key: string }) => n.key !== key);
[...this.edges.values()].forEach(({ a, b }) => {
if (a.key === key || b.key === key) this.edges.delete(JSON.stringify([a, b]));
});
}
/**
* 删除两个给定节点之间的边
* @param a
* @param b
*/
removeEdge(a: any, b: any) {
this.edges.delete(JSON.stringify([a, b]));
if (!this.directed) this.edges.delete(JSON.stringify([b, a]));
}
/**
* 检索具有给定键的节点
* @param key
* @returns
*/
findNode(key: string) {
return this.nodes.find((x: { key: string }) => x.key === key);
}
/**
* 检查图在两个给定节点之间是否有边
* @param a
* @param b
* @returns
*/
hasEdge(a: any, b: any) {
return this.edges.has(JSON.stringify([a, b]));
}
/**
* 设置给定边的权重
* @param a
* @param b
* @param weight
*/
setEdgeWeight(a: any, b: any, weight: any) {
this.edges.set(JSON.stringify([a, b]), { a, b, weight });
if (!this.directed) this.edges.set(JSON.stringify([b, a]), { a: b, b: a, weight });
}
/**
* 获取给定边的权重
* @param a
* @param b
* @returns
*/
getEdgeWeight(a: any, b: any) {
return this.edges.get(JSON.stringify([a, b]))?.weight;
}
/**
* 从给定节点查找存在边的所有节点
* @param key
* @returns
*/
adjacent(key: string) {
return [...this.edges.values()].reduce((acc, { a, b }) => {
if (a.key === key) acc.push(b);
return acc;
}, [] as GraphNode[]);
}
/**
* 计算给定节点的总边数
* @param key
* @returns
*/
inDegree(key: string) {
return [...this.edges.values()].reduce((acc, { a, b }) => (b.key === key ? acc + 1 : acc), 0);
}
/**
* 计算给定节点的总边数
* @param key
* @returns
*/
outDegree(key: string) {
return [...this.edges.values()].reduce((acc, { a, b }) => (a.key === key ? acc + 1 : acc), 0);
}
}7.3 深度优先搜索和广度优先搜索
深度优先搜索 (DFS) 是一种用于遍历或搜索树或图数据结构的算法。一个从根开始(在图的情况下选择某个任意节点作为根)并在回溯之前沿着每个分支尽可能地探索。
广度优先搜索 (BFS) 则是从树根(或图的某个任意节点,有时称为“搜索key”)开始,首先探索邻居节点,然后再移动到下一级邻居。
7.4 剑指 offer 搜索题(typescript 版)
矩阵中的路径
机器人的运动范围
8 堆
8.1 堆的基本操作
堆是具有以下性质的完全二叉树,有两种堆:
大顶堆(大根堆):每个节点值大于等于左、右孩子节点的值,大根堆的堆顶是整个堆中的最大元素。
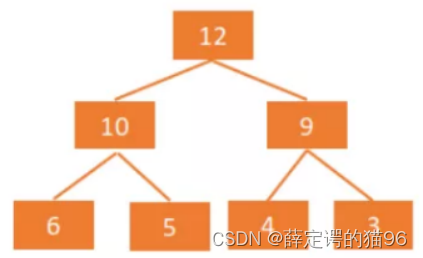
小顶堆(小根堆):每个节点值小于等于左、右孩子节点的值,小根堆的堆顶是整个堆中的最小元素。
存储形式:数组
应用:优先级队列(多个定时器任务问题)、求前n个最大/最小的数。
堆的基本操作包括(均依赖于堆的自我调整使其满足大/小根堆特性):
- 插入节点:插入位置是在堆的末尾,然后对该节点进行上浮操作(上浮即和它的父节点比较大小);
- 删除节点:删除位置在堆顶,然后将堆尾元素放到堆顶,对此元素进行下沉操作(下沉即和它的左、右孩子比较大小),不断递归,直到无法下沉;
- 构建堆:把一个无序的完全二叉树调整为大/小根堆,从下往上、从左往右的对所有非叶子节点进行下沉操作。
8.2 设计堆
利用数组,实现具有插入,删除操作的大根或小根堆。
class Heap {
container: number[];
cmp: Function;
/**
* 默认是大顶堆
* @param type
*/
constructor(type: 'max' | 'min' = 'max') {
this.container = [];
this.cmp = type === 'max' ? (x, y) => x > y : (x, y) => x < y;
}
/**
* 对堆中的两个节点进行交换
* @param i
* @param j
*/
swap(i: number, j: number) {
[this.container[i], this.container[j]] = [this.container[j], this.container[i]];
}
/**
* 插入节点,在堆末尾插入,并对节点进行上浮操作
* @param data
* @returns
*/
insert(data: number) {
this.container.push(data);
// 上浮操作
let index = this.container.length - 1;
while (index) {
// 直到遍历到堆顶
// 父节点位置
const parent = Math.floor((index - 1) / 2);
if (!this.cmp(this.container[index], this.container[parent])) {
// 大顶堆:当前节点不大于父节点,到达最终位置
return;
}
// 交换
this.swap(index, parent);
index = parent;
}
}
/**
* 删除节点,删除堆顶元素与堆尾元素后的堆尾所在元素,再对堆顶元素执行下沉操作
* @returns
*/
delete(): number {
if (this.isEmpty()) return NaN;
// 将堆顶元素与堆尾元素进行交换,并删除堆尾元素
const size = this.getSize();
this.swap(0, size - 1);
const top = this.container.pop()!;
// 当前节点位置
let index = 0;
// 交换节点位置,大顶堆:子节点中的较大者
let exchange = index * 2 + 1;
while (exchange < size) {
// 右子节点位置
let right = index * 2 + 2;
if (right < length && this.cmp(this.container[right], this.container[exchange])) {
// 大顶堆:存在右节点且右节点较大
exchange = right;
}
if (!this.cmp(this.container[exchange], this.container[index])) {
// 大顶堆:子节点较大者小于当前节点
return NaN;
}
// 交换
this.swap(exchange, index);
index = exchange;
exchange = index * 2 + 1;
}
return top;
}
/**
* 获取堆顶元素,堆空则返回 NaN
* @returns
*/
top(): number {
if (this.isEmpty()) return NaN;
return this.container[0];
}
/**
* 判断堆是否为空
* @returns
*/
isEmpty(): boolean {
return this.getSize() === 0;
}
/**
* 堆中元素个数
* @returns
*/
getSize(): number {
return this.container.length;
}
}
8.3 剑指 offer 堆算法题( typescript 版)
数据流中的中位数
9 散列表
9.1 Hash表的基本操作
Hash表是一种是使用哈希函数来组织数据,支持快速插入和搜索的线性数据结构。关键是通过哈希函数将键映射到存储桶。哈希函数的选取取决于键的值范围和桶的数量。
a) 插入新的键,哈希函数计算被存储的桶;
b) 搜索一个键,使用相同的哈希函数计算所在桶, 然后在桶中搜索。
9.2 设计Hash表
关键是选择哈希函数和进行冲突处理
哈希函数:分配一个地址存储值。理想情况下,每个键都应该有一个对应唯一的散列值。
冲突处理:哈希函数的本质就是从 A 映射到 B。但是多个 A 键可能映射到相同的 B。
将哈希key转换为字符串的函数如下:
/**
* @description: 将 item 也就是 key 统一转换为字符串
*/
export function defaultToString(item: any): string {
// 对于 null undefined和字符串的处理
if (item === null) {
return 'NULL';
} else if (item === undefined) {
return 'UNDEFINED';
} else if (typeof item === 'string' || item instanceof String) {
return `${item}`;
}
// 其他情况时调用数据结构自带的 toString 方法
return item.toString();
}冲突解决策略:
1) 单独链接法(链表法):对于相同的散列值,我们将它们放到一个桶中,每个桶是相互独立的
// 单独链接法(链表)
export class HashTableSeparateChaining<K, V> {
protected table: Map<number, MyLinkedList<{ key: K; value: V }>>;
constructor(protected toStrFn: (key: K) => string = defaultToString) {
this.table = new Map();
}
/**
* @description: 哈希函数(djb2函数(或者loselose函数)
*/
private hashCodeHelper(key: K): number {
if (typeof key === 'number') {
return key;
}
const tableKey = this.toStrFn(key);
let hash = 5381;
for (let i = 0; i < tableKey.length; i++) {
hash = hash * 33 + tableKey.charCodeAt(i);
}
return hash % 1013;
}
/**
* @description: 哈希函数封装
*/
hashCode(key: K): number {
return this.hashCodeHelper(key);
}
/**
* @description: 更新散列表
*/
put(key: K, value: V): boolean {
if (key !== null && value !== null) {
const position = this.hashCode(key);
// 当该 hashcode 不存在时,先创建一个链表
if (this.table.get(position) == null) {
this.table.set(position, new MyLinkedList<{ key: K; value: V }>());
}
// 再给链表push值
this.table.get(position)!.addAtTail({ key, value });
return true;
}
return false;
}
/**
* @description: 根据键获取值
*/
get(key: K): V | undefined {
const position = this.hashCode(key);
const linkedList = this.table.get(position);
if (linkedList && linkedList.size !== 0) {
let current = linkedList.head;
// 去链表中迭代查找键值对
while (current !== null) {
if (current.val.key === key) {
return current.val.value;
}
current = current.next;
}
}
}
/**
* @description: 根据键移除值
*/
remove(key: K): boolean {
const position = this.hashCode(key);
const linkedList = this.table.get(position);
if (linkedList && linkedList.size !== 0) {
let current = linkedList.head;
let index = 0;
while (current !== null) {
if (current.val.key === key) {
break;
}
index = index + 1;
current = current.next;
}
linkedList.deleteAtIndex(index);
// 关键的一点,当链表为空以后,需要在 table 中删除掉 hashcode
if (linkedList.size === 0) {
this.table.delete(position);
}
return true;
}
return false;
}
/**
* @description: 返回是否为空散列表
*/
isEmpty(): boolean {
return this.size() === 0;
}
/**
* @description: 散列表的大小
*/
size(): number {
let count = 0;
// 迭代每个链表,累计求和
for (const [hashCode, linkedList] of this.table) {
count += linkedList.size;
}
return count;
}
/**
* @description: 清空散列表
*/
clear() {
this.table.clear();
}
/**
* @description: 返回内部table
*/
getTable() {
return this.table;
}
/**
* @description: 替代默认的toString
*/
toString(): string {
if (this.isEmpty()) {
return '';
}
let objStringList: string[] = [];
for (const [hashCode, linkedList] of this.table) {
let node = linkedList.head;
while (node) {
objStringList.push(`{${node.val.key} => ${node.val.value}}`);
node = node.next;
}
}
return objStringList.join(',');
}
}2) 开放地址法(线性探测):每当有碰撞,则根据我们探查的策略找到一个空的槽为止。
// 开放地址法(线性探测)
export default class HashTableLinearProbing<K, V> {
protected table: Map<number, { key: K; value: V }>;
constructor(protected toStrFn: (key: K) => string = defaultToString) {
this.table = new Map();
}
/**
* @description: 哈希函数(djb2函数(或者loselose函数))
*/
private hashCodeHelper(key: K): number {
if (typeof key === 'number') {
return key;
}
const tableKey = this.toStrFn(key);
let hash = 5381;
for (let i = 0; i < tableKey.length; i++) {
hash = hash * 33 + tableKey.charCodeAt(i);
}
return hash % 1013;
}
/**
* @description: 哈希函数封装
*/
hashCode(key: K): number {
return this.hashCodeHelper(key);
}
/**
* @description: 更新散列表
*/
put(key: K, value: V): boolean {
if (key !== null && value !== null) {
const position = this.hashCode(key);
if (this.table.get(position) == null) {
// 当hashcode位置为空时,可以直接添加
this.table.set(position, { key, value });
} else {
// 否则需要迭代查找最近的空位置再添加
let index = position + 1;
while (this.table.get(index) !== null) {
index++;
}
this.table.set(index, { key, value });
}
return true;
}
return false;
}
/**
* @description: 根据键获取值
*/
get(key: K): V | undefined {
const position = this.hashCode(key);
if (this.table.get(position)) {
// 如果查到的hashcode位置就是要查的key,则直接返回
if (this.table.get(position)!.key === key) {
return this.table.get(position)!.value;
}
// 否则需要迭代着向下查找
let index = position + 1;
while (this.table.get(index) != null && this.table.get(index)!.key !== key) {
index++;
}
if (this.table.get(index) !== null && this.table.get(index)!.key === key) {
return this.table.get(position)!.value;
}
}
// 最后也没查到,就返回 undefined
return undefined;
}
/**
* @description: 根据键移除值
*/
remove(key: K): boolean {
const position = this.hashCode(key);
if (this.table.get(position)) {
// 同理,如果hashcode对应位置就是要查的key,则直接删除
if (this.table.get(position)!.key === key) {
this.table.delete(position);
// 删除后处理副作用
this.verifyRemoveSideEffect(key, position);
return true;
}
// 同理,如果hashcode对应的位置不是要查的key,就迭代查到
let index = position + 1;
while (this.table.get(index) !== null && this.table.get(index)!.key !== key) {
index++;
}
if (this.table.get(index) !== null && this.table.get(index)!.key === key) {
this.table.delete(index);
// 同样在删除后处理副作用
this.verifyRemoveSideEffect(key, index);
return true;
}
}
return false;
}
/**
* @description: 处理移除键值对后的副作用
*/
private verifyRemoveSideEffect(key: K, removedPosition: number) {
const hash = this.hashCode(key);
let index = removedPosition + 1;
// 迭代着处理后面的每一个键值对
while (this.table.get(index) !== null) {
const posHash = this.hashCode(this.table.get(index)!.key);
// 挨个向前挪动,关键点在于,hashcode值比较小的键值对尽量先向前补位
// 详细的说:如果当前元素的 hash 值小于或等于原始的 hash 值
// 或者当前元素的 hash 值小于或等于 removedPosition(也就是上一个被移除 key 的 hash 值),
// 表示我们需要将当前元素移动至 removedPosition 的位置
if (posHash <= hash || posHash <= removedPosition) {
this.table.set(removedPosition, this.table.get(index)!);
this.table.delete(index);
removedPosition = index;
}
index++;
}
}
/**
* @description: 返回是否为空散列表
*/
isEmpty(): boolean {
return this.size() === 0;
}
/**
* @description: 散列表的大小
*/
size(): number {
return this.table.size;
}
/**
* @description: 清空散列表
*/
clear() {
this.table.clear();
}
/**
* @description: 返回内部table
*/
getTable(): Map<number, { key: K; value: V }> {
return this.table;
}
/**
* @description: 替代默认的toString
*/
toString(): string {
if (this.isEmpty()) {
return '';
}
let objStringList: string[] = [];
for (const [hashCode, { key, value }] of this.table) {
objStringList.push(`{${key} => ${value}}`);
}
return objStringList.join(',');
}
}上述实现中使用到的 djb2函数(或者loselose函数),原理是借助字符串各个位上的 UTF-16 Unicode 值进行计算,然后对 特定值取余即为哈希值。
3) 双散列法:使用两个哈希函数计算散列值,选择碰撞更少的地址。
JavaScript内置哈希表的典型设计是:
键值可以是任何具有可哈希码(映射函数获取存储区索引)的可哈希化的类型。每个桶包含一个数组,用于在初始时将所有值存储在同一个桶中。 如果在同一个桶中有太多的值,这些值将被保留在一个高度平衡的二叉树搜索树(BST)中。
插入和搜索的平均时间复杂度仍为 O(1)。最坏情况下插入和搜索的时间复杂度是 O(logN)。使用高度平衡的 BST是在插入和搜索之间的一种权衡。
10 查找表
查找表是同一数据类型构成的集合。只进行查找操作的称为静态查找表;在查找的同时进行插入和删除操作的称为动态查找表。
查找算法衡量好坏的依据为:查找成功时,查找的关键字和查找表中比较过的数据元素的个数的平均值,称为平均查找长度(Average Search Length,用 ASL 表示)。计算公式为

其中 Pi 为第 i 个数据元素被查找的概率,所有元素被查找的概率的和为 1;Ci 表示在查找到第 i 个数据元素之前已进行过比较的次数。比如线性查找中,若表中有 n 个数据元素,从后往前查找,查找第一个元素时需要比较 n 次;查找最后一个元素时需要比较 1 次,所以有 Ci = n – i + 1 。
对于查找算法来说,查找成功和查找失败的概率是相同的。查找算法的平均查找长度应该为查找成功时的平均查找长度加上查找失败时的平均查找长度。计算公式为:

10.1 顺序查找
算法思想:在原始顺序表中添加目标关键字作为“监视哨”,然后从表中的第一个数据元素开始,逐个同记录的目标关键字做比较,如果匹配成功,则查找成功;反之,如果直到表中最后一个关键字查找完才成功匹配,则说明原始顺序表中查找失败。
实现:
// 哨兵法
function sequentialSearch(nums: number[], target: number): number {
nums.push(target);
let i = 0;
while (nums[i] !== target) {
i = i + 1;
}
return i === nums.length - 1 ? -1 : i;
}
其平均查找长度为:

10.2 二分查找(折半查找)
算法思想:假设静态查找表中的数据是有序的。指针 low 和 high 分别指向查找表的第一个关键字和最后一个关键字,指针 mid 指向处于 low 和 high 指针中间位置的关键字。在查找的过程中每次都同 mid 指向的关键字进行比较,由于整个表中的数据是有序的,因此在比较之后就可以知道要查找的关键字的在 [low, mid] 还是 [mid, right]。
实现:
function binarySearch(nums: number[], target: number): number {
let low = 0;
let high = nums.length - 1;
while (low <= high) {
const mid = Math.floor((low + high) / 2);
const midNum = nums[mid];
if (midNum === target) {
return mid;
} else if (midNum > target) {
high = mid - 1;
} else {
low = mid + 1;
}
}
return -1;
}

查找成功的平均查找长度等于判定树上每一层的内节点(能查找成功的)数乘以该层的内节点数,然后求和,最后除以内节点数。
查找失败的平均查找长度等于每一层的外节点(查找失败的区域)数乘以乘以[外节点所在层 - 1],然后求和,除以外节点数。
10.3 二叉查找(搜索)树和平衡二叉树(AVL)
10.3.1 二叉查找树(二叉搜索树、二叉排序树)
空树或满足:
- 非空左子树所有节点值小于根节点;
- 非空右子树所有节点值大于根节点;
- 左右子树也是二叉查找树;
是一种动态查找表,在查找过程中插入或者删除表中元素。查找的时间复杂度取决于树的高度。
插入节点:查找失败时插入位置一定位于查找失败时访问的最后一个结点的左孩子(小于)或者右孩子(大于)。
对一个查找表进行查找以及插入操作时,可以从空树构建出一个含有表中所有关键字的二叉排序树,使得一个无序序列可以通过构建一棵二叉排序树,从而变成一个有序序列(中序遍历)。
删除节点(假设为p节点):
1. p节点为叶节点,直接删除并改变父节点指针为null;
2. p节点只有左子树或只有右子树,直接将子树替换p节点;
3. p节点同时有左右子树:
a) 左子树替换p节点,同时右子树成为p节点直接前驱的右子树
b) 或者直接将节点p的值替换为其直接前驱的值,再对原直接前驱进行删除操作(以下实现采用)。
// 比较结果的枚举值
enum Compare {
LESS_THAN = -1,
BIGGER_THAN = 1,
EQUALS = 0,
}
// 规定自定义Compare的类型
type ICompareFunction<T> = (a: T, b: T) => number;
/**
* 默认的大小比较函数
* @param {T} a
* @param {T} b
* @return {Compare} 返回 -1 0 1 代表 小于 等于 大于
*/
function defaultCompare<T>(a: T, b: T): Compare {
if (a === b) {
return Compare.EQUALS;
}
return a < b ? Compare.LESS_THAN : Compare.BIGGER_THAN;
}
function cb<T>(node: BinarySearchTreeNode<T>) {
console.log(node);
return node;
}
class BinarySearchTreeNode<T> {
constructor(
public key: T,
public value: any = key,
public left: BinarySearchTreeNode<T> | null = null,
public right: BinarySearchTreeNode<T> | null = null
) {}
get isLeaf() {
return this.left === null && this.right === null;
}
get hasChildren() {
return !this.isLeaf;
}
get hasBothChildren() {
return this.left !== null && this.right !== null;
}
get hasLeftChild() {
return this.left !== null;
}
}
class BinarySearchTree<T> {
protected root: BinarySearchTreeNode<T> | null;
constructor(key: T, value = key, protected compareFn: ICompareFunction<T> = defaultCompare) {
this.root = new BinarySearchTreeNode(key, value);
}
*inOrderTraversal(node = this.root, callback: (node: BinarySearchTreeNode<T>) => BinarySearchTreeNode<T>) {
if (node) {
const { left, right } = node;
if (left) yield* this.inOrderTraversal(left, callback);
yield callback(node);
if (right) yield* this.inOrderTraversal(right, callback);
}
}
*postOrderTraversal(node = this.root, callback: (node: BinarySearchTreeNode<T>) => BinarySearchTreeNode<T>) {
if (node) {
const { left, right } = node;
if (left) yield* this.postOrderTraversal(left, callback);
if (right) yield* this.postOrderTraversal(right, callback);
yield callback(node);
}
}
*preOrderTraversal(node = this.root, callback: (node: BinarySearchTreeNode<T>) => BinarySearchTreeNode<T>) {
if (node) {
const { left, right } = node;
yield callback(node);
if (left) yield* this.preOrderTraversal(left, callback);
if (right) yield* this.preOrderTraversal(right, callback);
}
}
/**
* 插入元素
*/
insert(key: T, value = key) {
if (this.root == null) {
// 边界情况:插入到根节点
this.root = new BinarySearchTreeNode(key, value);
} else {
// 递归找到插入位置
this.insertNode(this.root, key, value);
}
}
/**
* 递归插入方法
*/
protected insertNode(node: BinarySearchTreeNode<T>, key: T, value = key) {
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
// key 比 node.key 小就向左查
if (node.left == null) {
// 基线条件:左面为空直接赋值
node.left = new BinarySearchTreeNode(key, value);
} else {
// 否则就接着递归
this.insertNode(node.left, key);
}
} else {
// key 比 node.key 大就向右查
if (node.right == null) {
// 基线条件:右面为空直接赋值
node.right = new BinarySearchTreeNode(key, value);
} else {
// 否则就接着递归
this.insertNode(node.right, key, value);
}
}
}
/**
* 是否存在某个节点
* @param key
* @returns
*/
has(node: BinarySearchTreeNode<T> | null, key: T) {
for (const current of this.postOrderTraversal(node, cb)) {
if (current.key === key) return true;
}
return false;
}
/**
* 搜索某个节点
* @param key
* @returns
*/
find(node: BinarySearchTreeNode<T> | null, key: T) {
for (const current of this.postOrderTraversal(node, cb)) {
if (current.key === key) return current;
}
return undefined;
}
/**
* 移除指定元素
*/
remove(key: T) {
this.root = this.removeNode(this.root, key);
}
/**
* 移除某个节点
* @param key
* @returns
*/
protected removeNode(node: BinarySearchTreeNode<T> | null, key: T): BinarySearchTreeNode<T> | null {
let current = this.find(node, key);
if (!current) return null;
if (current.isLeaf) {
// 删除叶子节点
current = null;
return current;
}
if (current.hasBothChild) {
// 有两个节点
const aux = this.minNode(current.right)!;
current.key = aux.key;
this.removeNode(current.right, aux.key);
}
if (current.hasLeftChild) {
// 只有左节点
current = current.left;
return current;
}
// 只有右节点
current = current.right;
return current;
}
/**
* 返回根节点
*/
getRoot(): BinarySearchTreeNode<T> | null {
return this.root;
}
/**
* 返回树中的最小元素
*/
min(): BinarySearchTreeNode<T> | null {
// 调用迭代方法
return this.minNode(this.root);
}
/**
* 返回指定子树下的最小元素
*/
protected minNode(node: BinarySearchTreeNode<T> | null): BinarySearchTreeNode<T> | null {
let current = node;
// 不断向左查
while (current != null && current.left != null) {
current = current.left;
}
return current;
}
/**
* 返回树中的最大元素
*/
max(): BinarySearchTreeNode<T> | null {
// 调用迭代方法
return this.maxNode(this.root);
}
/**
* 返回指定子树下的最大元素
*/
protected maxNode(node: BinarySearchTreeNode<T> | null): BinarySearchTreeNode<T> | null {
let current = node;
// 不断向右查
while (current != null && current.right != null) {
current = current.right;
}
return current;
}
/**
* 搜索元素
*/
search(key: T): boolean {
// 调用递归方法
return this.searchNode(this.root, key);
}
/**
* 递归搜索
*/
private searchNode(node: BinarySearchTreeNode<T> | null, key: T): boolean {
// 查到尽头返回 false
if (node == null) {
return false;
}
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
// key 比 node.key 小,向左查
return this.searchNode(node.left, key);
}
if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
// key 比 node.key 大,向右查
return this.searchNode(node.right, key);
}
return true;
}
}
10.3.2 平衡二叉树 (AVL)
平衡二叉树 (AVL):
1) 满足二叉查找树的所有特性;
2) 每个节点的平衡因子(节点的左右子树高度差)绝对值不大于1
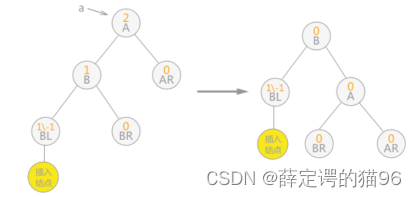
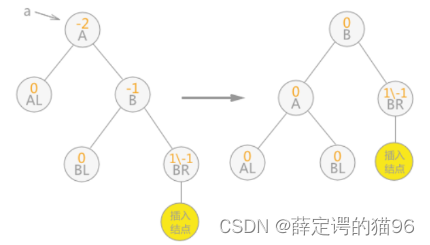
在动态查找过程中,可能会破坏其平衡性,需要做出调整(假设距离插入节点最近的不平衡节点为a):
1) 在a的左子树的左子树上插入节点(LL),即右旋
2) 在a的右子树的右子树上插入节点(RR),即左旋
3) 在a的左子树的右子树上插入节点(LR),即先左旋再右旋

4) 在a的右子树的左子树上插入节点(RL),即先右旋再左旋

// 平衡因子枚举
enum BalanceFactor {
UNBALANCED_RIGHT = -2, // 右重
SLIGHTLY_UNBALANCED_RIGHT = -1, // 轻微右重
BALANCED = 0, // 完全平衡
SLIGHTLY_UNBALANCED_LEFT = 1, // 轻微左重
UNBALANCED_LEFT = 2, // 右重
}
class AVLTree<T> extends BinarySearchTree<T> {
protected root: BinarySearchTreeNode<T> | null;
constructor(key: T, value = key, protected compareFn: ICompareFunction<T> = defaultCompare) {
super(key, value, compareFn);
this.root = new BinarySearchTreeNode(key, value);
}
/**
* 获取节点高度
* @param node
* @returns
*/
private getNodeHeight(node: BinarySearchTreeNode<T> | null): number {
if (node === null) return 0;
const { left, right } = node;
return 1 + Math.max(this.getNodeHeight(left), this.getNodeHeight(right));
}
/**
* 获取节点的平衡因子
* @param node
* @returns
*/
private getBalanceFactor(node: BinarySearchTreeNode<T>): BalanceFactor {
if (node === null) {
return BalanceFactor.BALANCED;
}
const { left, right } = node;
// 左子树重 减去 右子树重
const heightDiff = this.getNodeHeight(left) - this.getNodeHeight(right);
// 再返回对应的枚举值
switch (heightDiff) {
case -2:
return BalanceFactor.UNBALANCED_RIGHT;
case -1:
return BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT;
case 1:
return BalanceFactor.SLIGHTLY_UNBALANCED_LEFT;
case 2:
return BalanceFactor.UNBALANCED_LEFT;
default:
return BalanceFactor.BALANCED;
}
}
/**
* 左子树的左子树上插入节点,左左情况: 向右单旋转
* 左侧子节点的高度大于右侧子节点的高度时,并且左侧子节点也是平衡或左侧较重的,为左左情况
*
* a b
* / \ / \
* b c -> rotationLL(a) -> d a
* / \ | / \
* d e 插入节点 e c
* |
* 插入节点
*
* @param node 旋转前的子树根节点
* @returns 返回旋转后的子树根节点
*/
private rotationLL(node: BinarySearchTreeNode<T>): BinarySearchTreeNode<T> {
const pivot = node.left;
node.left = node.right;
pivot!.right = node;
return pivot!;
}
/**
* 右子树的右子树上插入节点,右右情况: 向左单旋转
* 右侧子节点的高度大于左侧子节点的高度,并且右侧子节点也是平衡或右侧较重的,为右右情况
* a c
* / \ / \
* b c -> rotationRR(a) -> a e
* / \ / \ |
* d e b d 插入节点
* |
* 插入节点
*
* @param node 旋转前的子树根节点
* @returns 返回旋转后的子树根节点
*/
private rotationRR(node: BinarySearchTreeNode<T>): BinarySearchTreeNode<T> {
const pivot = node.right;
node.right = pivot!.left;
pivot!.left = node;
return pivot!;
}
/**
* 左子树的右子树上插入节点, 左右情况: 先左转子节点后右转
* 左侧子节点的高度大于右侧子节点的高度,并且左侧子节点右侧较重
*
* a a e
* / \ / \ / \
* b c -> rotationRR(b) -> e c -> rotationLL(a) -> b a
* / \ / / \ \
* d e b d 插入节点 c
* | / \
* 插入节点 d 插入节点
*
* @param node
*/
private rotationLR(node: BinarySearchTreeNode<T>): BinarySearchTreeNode<T> {
// 先把节点左子左转
node.left = this.rotationRR(node.left!);
// 再把节点本身右转
return this.rotationLL(node);
}
/**
* 右子树的左子树上插入节点, 右左情况: 先右转子节点后左转
* 右侧子节点的高度大于左侧子节点的高度,并且右侧子节点左侧较重
*
* a a d
* / \ / \ / \
* b c -> rotationLL(c) -> b d -> rotationRR(a) -> a c
* / \ | \ / \ \
* d e 插入节点 c b 插入节点 e
* | \
* 插入节点 e
*
* @param node
*/
private rotationRL(node: BinarySearchTreeNode<T>): BinarySearchTreeNode<T> {
// 先把节点左子左转
node.left = this.rotationRR(node.left!);
// 再把节点本身右转
return this.rotationLL(node);
}
/**
* 对子树进行平衡
*/
keepBalance(node: BinarySearchTreeNode<T> | null): BinarySearchTreeNode<T> | null {
if (node === null) return node;
// 校验树是否平衡
const balanceState = this.getBalanceFactor(node);
const { left, right } = node;
if (left && balanceState === BalanceFactor.UNBALANCED_LEFT) {
// 左左情况
if (
this.getBalanceFactor(left) === BalanceFactor.BALANCED ||
this.getBalanceFactor(left) === BalanceFactor.SLIGHTLY_UNBALANCED_LEFT
) {
return this.rotationLL(node);
} else if (this.getBalanceFactor(left) === BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT) {
// 左右情况
return this.rotationLR(node);
}
} else if (right && balanceState === BalanceFactor.UNBALANCED_RIGHT) {
// 右右情况
if (
this.getBalanceFactor(right) === BalanceFactor.BALANCED ||
this.getBalanceFactor(right) === BalanceFactor.SLIGHTLY_UNBALANCED_RIGHT
) {
return this.rotationRR(node);
} else if (this.getBalanceFactor(right) === BalanceFactor.SLIGHTLY_UNBALANCED_LEFT) {
// 右左情况
return this.rotationRL(node);
}
}
return node;
}
/**
* @description: 插入节点的递归方法,递归插入完后,需要校验树是否仍然平衡,若不平衡则需要旋转
* @param {Node} node 要插入到的节点
* @param {T} key 要插入的键
* @return {Node} 为了配合 insert 方法,一定要返回节点
*/
protected insertNode(node: BinarySearchTreeNode<T> | null, key: T, value = key): BinarySearchTreeNode<T> | null {
// 与二叉搜索树的插入方式一致
if (node == null) {
return new BinarySearchTreeNode<T>(key, value);
}
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
node.left = this.insertNode(node.left, key);
} else if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
node.right = this.insertNode(node.right, key);
} else {
return node; // 重复的 key
}
// 校验树是否平衡
return this.keepBalance(node);
}
/**
* @description: 删除节点的递归方法,递归完成后也需要再平衡
* @param {Node} node 要从中删除的节点
* @param {T} key 要删除的键
* @return {Node} 同样为了配合remove方法,一定要返回节点
*/
protected removeNode(node: BinarySearchTreeNode<T> | null, key: T): BinarySearchTreeNode<T> | null {
// 与二叉搜索树的删除方式一致
if (!node) return null;
if (this.compareFn(key, node.key) === Compare.LESS_THAN) {
node.left = this.removeNode(node.left, key);
} else if (this.compareFn(key, node.key) === Compare.BIGGER_THAN) {
node.right = this.removeNode(node.right, key);
} else {
if (node.isLeaf) {
// 删除叶子节点
node = null;
} else if (node.hasBothChildren) {
const aux = this.minNode(node.right)!;
node.key = aux.key;
node.right = this.removeNode(node.right, aux.key);
} else if (node.hasLeftChild) {
node = node.left;
} else {
node = node.right;
}
}
// 校验树是否平衡
return this.keepBalance(node);
}
}
10.4 B-树和B+树
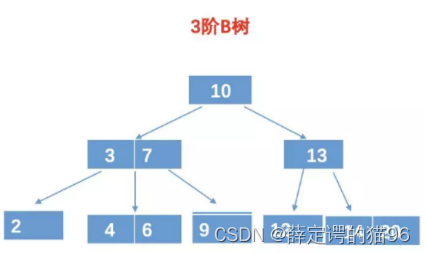
10.4.1 B-树(B树)
是多叉查找树,一颗m阶B树满足(m = 3指的是度最大为3):
1. 根节点至少有子节点;
2. 每个中间节点(非叶、根节点)都包含 k - 1 个元素和 k 个孩子(m/2 <= k <= m);
3. 每一个叶子节点都包含 k - 1 个元素(m/2 <= k <= m);
4. 所有的叶子节点都位于同一侧;
5. 每个节点中的元素从小到大排列,节点当中的 k - 1 个元素划分k个孩子所属的值域范围。
进行数值的比较是在内存(内存运算速度比磁盘IO快)中进行的,B树的比较次数虽然比二叉查找树多,然而由于B树每个节点存储的数据更多,磁盘加载次数更少,效率更高。磁盘加载次数可能与树的高度相同(因为不同的节点可能存储在不同的磁盘页中),所以选择这种矮胖的树形结构。注意:受到内存大小和磁盘页数限制,并不是越矮胖越好。
B树的基本操作:
1. 插入:首先自顶向下查找元素的插入位置。如果插入后节点元素个数等于m。对当前节点的中心节点向上升级,直到当前节点元素个数小于m。

2. 删除:首先自顶向下查找删除位置,删除后如果不满足B树的特性,找出父节点和其子节点的中位数进行向上升级
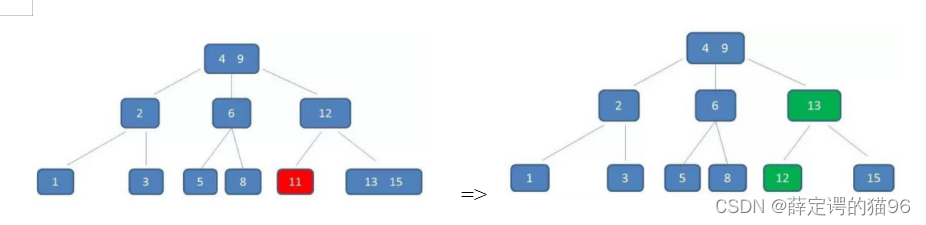
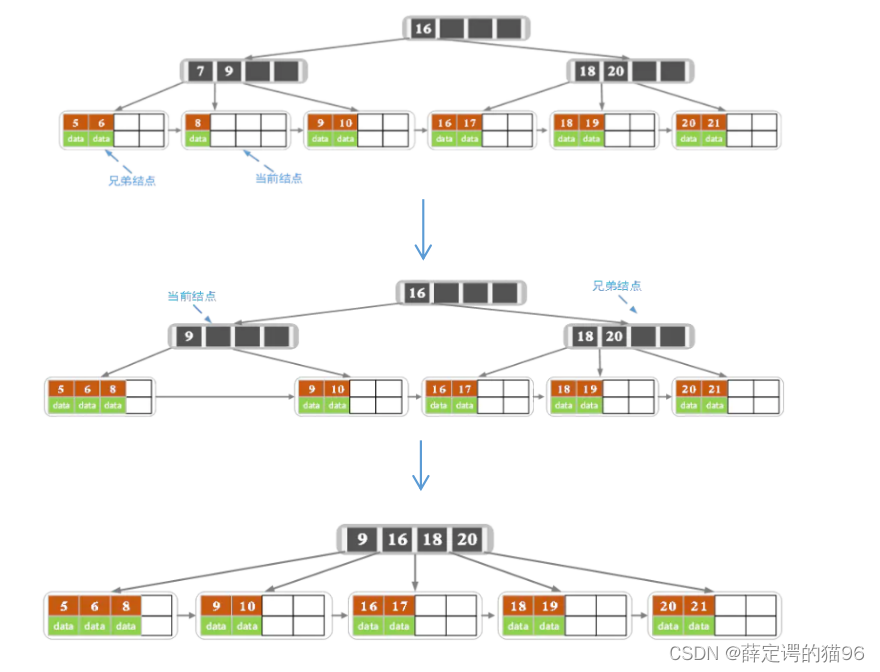
10.4.2 B+树
是多叉查找树,一颗m阶B+树满足(m = 3指的是度最大为3):
1. 中间节点的元素个数和其子树个数相等,均为k(m/2 <= k <= m),且中间节点的索引元素值是子节点中元素的最大(或最小)值;
2. 所有叶子节点包括了全部索引元素,和指向卫星数据的指针,且所有叶子节点形成有序链表;
B+ 树基本操作:
1. 插入:空树直接插入;找到插入位置插入后,节点元素个数等于m就进行分裂(中位数升级),直到当前节点元素个数小于m。(插入7):

2. 删除:首先自顶向下查找删除位置,删除后如果个数小于Math.ceil(m/2) – 1,进行向兄弟节点借或与兄弟节点合并,自底向上判断节点个数是否小于Math.ceil(m/2) – 1。(删除7):
B+树非叶子节点不存在卫星数据(索引元素所指向的数据记录,在B-树中,无论是中间节点还是叶子结点都带有卫星数据,而在B+树当中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联),因此可以存储更多的中间节点,意味着在数据量相同情况下,B+树比B树存储更矮胖,磁盘IO次数更少。
补充:在数据库的聚簇索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚簇索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。
B+树的优点:
- 所有查询都需要到叶子节点,查询性能稳定。
- 叶子节点形成有序链表,相较B树便于范围查询。
文件系统和数据库的索引都是存在硬盘上的,并且如果数据量大的话,不一定能一次性加载到内存中,所以要用到B树或B+树的多路存储分页加载。
MySQL采用B+树索引的原因:进行多条数据的查询或范围查询时,对于B树需要做中序遍历跨层访问磁盘页,而B+树全部数据都在叶子节点且叶子节点之间是链表结构,找到首尾即可取出所有数据。Hash索引对等值查询具有优势,效率O(1),前提是哈希冲突较少。Hash无序性不适用于范围查询,查询出来的数据需要再次排序(模糊匹配like本质也是范围查询)。多列联和索引的最左匹配规则只能是B+树,首先是先对第一列排序,对于第一列相同的再按照第二列排序,依次类推。
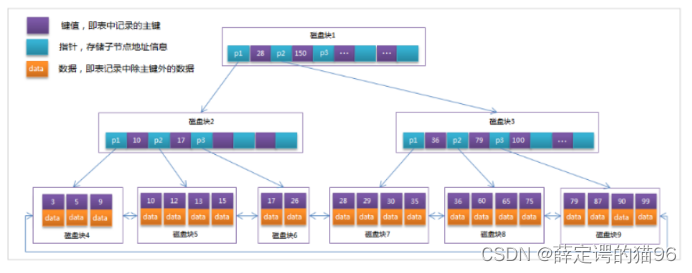
MySQL中的 B+Tree 索引结构图如下(叶子节点循环双向链表):
11 排序
11.1 冒泡排序(bubble sort)
算法思想:基于交换,以从前往后冒泡为例,第一趟冒泡从第一个元素开始,到倒数第二个元素,比较相邻的元素,如果前一个元素大于后一个即交换。下一趟从第一个元素开始,只到倒数第三个元素(因为上一趟倒数第一个元素确定其最终位置)。依此类推。由于相同的元素在冒泡过程中不会交换,属于稳定排序,时间复杂度O(n2),空间复杂度O(1)。
优化:有序的标志即一趟冒泡没有发生元素的交换,因此可以提前中止。同时,从算法思想可得,有序区的长度至少等于冒泡的趟数,甚至大于。在一趟冒泡过程中,最后一次交换的下标即是有序区第一个元素,下一趟的冒泡只需要遍历至该下标的上一个元素。
实现:
// 冒泡排序
function bubbleSort(nums: number[]): number[] {
const len = nums.length;
let firstOrderedIndex = len - 1; // 有序区的左边界
let lastExchangeIndex = 0; // 每一趟最后一次交换的位置;
for (let i = 0; i < len; i++) {
let isExchange = false;
for (let j = 0; j < firstOrderedIndex; j++) {
if (nums[j] > nums[j + 1]) {
[nums[j], nums[j + 1]] = [nums[j + 1], nums[j]];
lastExchangeIndex = j; // 发生交换,更新有序去边界
isExchange = true;
}
}
firstOrderedIndex = lastExchangeIndex;
if (!isExchange) break; // 若没发生交换,说明一件有序
}
return nums;
}
11.2 简单插入排序(insert sort)
算法思想:对于具有n个元素的待排序序列,第k趟假设前k(k >=1)个已经有序,后n - k个元素是无序,选取第k+1个元素,在前k个元素中寻找它的插入位置(即第一个比它大的元素的位置)进行插入。由于插入位置在有序区中比它大的第一个元素处,属于稳定排序,时间复杂度O(n2),空间复杂度O(1)。
优化:查找插入位置时,使用二分查找。
实现:
// 简单插入排序
function insertSort(nums: number[]): number[] {
const len = nums.length;
for (let i = 1; i < len; i++) {
const element = nums[i];
// 查找插入位置
let left = 0;
let right = i - 1;
while (left <= right) {
const mid = Math.floor((left + right) / 2);
if (element < nums[mid]) {
// 插入点在左半区
right = mid - 1;
} else {
// 值相同时, 切换到右半区,保证稳定性
left = mid + 1;
}
}
// 插入位置 left 之后的元素全部后移一位
for (let j = i; j > left; j--) {
nums[j] = nums[j - 1];
}
nums[left] = element;
}
return nums;
}
11.3 选择排序(select sort)
算法思想:对于具有n个元素的待排序序列,第k趟假设前k(k >=1)个已经有序,后n - k个元素是无序,从这n-k元素中选择最小的元素和第k个元素交换。因此这是在时间复杂度上最稳定的排序算法,无论如何都是O(n2),空间复杂度O(1)。由于最小元素交换时可能导致相等元素相对位置改变([31, 5, 32, 2, 9] => [2, 5, 32, 31, 9]),属于不稳定排序。
实现:
// 选择排序
function selectSort(nums: number[]): number[] {
const len = nums.length;
for (let i = 0; i < len; i++) {
// 从 n - i 个元素中找出最小值
let minIndex = i; // 初始化最小元素下标为 n - i 个元素 中的第一个
for (let j = i + 1; j < len; j++) {
if (nums[j] < nums[minIndex]) {
// 当前元素更小,更新下标
minIndex = j;
}
}
// 交换
[nums[i], nums[minIndex]] = [nums[minIndex], nums[i]];
}
return nums;
}
11.4 快速排序(quick sort)
算法思想:选取一个基准元素pivot,基准元素将待排序数组分为小于和大于的左右独立的两部分。然后再递归的分别对左右两个独立部分进行相同的操作。比如选择基准元素为左侧第一个元素,通过使用一个指针指向基准元素的下一个元素,同时遍历基准元素右侧元素,若元素小于基准元素,则交换当前遍历元素和指针指向元素,且移动该指针,最终指针所在位置就是大于等于基准元素的第一个元素位置。遍历结束,交换指针前一位元素和基准元素,基准元素到达最终位置。由于在左边等于基准元素的元素可能会被放到右边,属于不稳定排序,时间复杂度O(nlogn),空间复杂度O(logn)。
实现:
// 快速排序
function quickSort1(nums: number[]) {
function partition(nums: number[], left: number, right: number) {
let index = left + 1; // 最左边元素为基准元素,index 是为了找到大于基准元素的第一个元素位置
for (let i = index; i <= right; i++) {
if (nums[i] < nums[left]) {
// 区域内的值小于基准值
i !== index && ([nums[i], nums[index]] = [nums[index], nums[i]]);
index = index + 1; // 每发现一个比基准元素小的,index 右移一位
}
}
[nums[left], nums[index - 1]] = [nums[index - 1], nums[left]];
return index - 1;
}
function quickSortCore(nums: number[], left: number, right: number) {
if (left < right) {
const partitionIndex = partition(nums, left, right);
quickSortCore(nums, left, partitionIndex - 1);
quickSortCore(nums, partitionIndex + 1, right);
}
}
quickSortCore(nums, 0, nums.length - 1);
return nums;
}
function quickSort2(nums: number[]): number[] {
let len = nums.length;
if (len <= 1) return nums; // 递归退出条件
const pivot = nums.splice(Math.floor(len / 2), 1)[0]; // 中间为基准元素
const left: number[] = [];
const right: number[] = [];
for (let item of nums) {
// 分成左右两部分
if (item < pivot) {
left.push(item);
} else {
right.push(item);
}
}
// 递归进行左右两部分排序
return quickSort2(left).concat(pivot, quickSort2(right));
}
function quickSort3(nums: number[]): number[] {
function partition(nums: number[], left: number, right: number) {
const pivot = nums[left];
while (left < right) {
while (left < right && nums[right] >= pivot) {
right = right - 1;
}
nums[left] = nums[right];
while (left < right && nums[left] <= pivot) {
left = left + 1;
}
nums[right] = nums[left];
}
nums[left] = pivot;
return left;
}
function quickSortCore(nums: number[], left: number, right: number) {
if (left < right) {
const partitionIndex = partition(nums, left, right);
quickSortCore(nums, left, partitionIndex - 1);
quickSortCore(nums, partitionIndex + 1, right);
}
}
quickSortCore(nums, 0, nums.length - 1);
return nums;
}
11.5 归并排序(merge sort)
算法思想:对于具有n个元素的待排序序列,分成两个长度为n/2的子序列,分别对两个子序列进行归并排序,将排序好的子序列合并。递归划分至子序列长度为1,两路合并。由于相等的元素在合并的过程中位置不变,属于稳定排序。时间复杂度O(nlogn),空间复杂度O(n)。
实现:
// 归并排序
function mergeSort(nums: number[]): number[] {
const len = nums.length;
// 只有一个元素,说明有序
if (len < 2) return nums;
// 划分成两个等长的子区域
const mid = Math.floor(len / 2);
// 合并两个有序数组
function merge(left: number[], right: number[]): number[] {
// 存放合并后的结果
const merged: number[] = [];
// 两个子序列的遍历指针
let i = 0;
let j = 0;
const leftSize = left.length;
const rightSize = right.length;
while (i < leftSize && j < rightSize) {
const leftElement = left[i];
const rightElement = right[j];
if (leftElement <= rightElement) {
merged.push(leftElement);
i = i + 1;
} else {
merged.push(rightElement);
j = j + 1;
}
}
while (i < leftSize) {
merged.push(left[i]);
i = i + 1;
}
while (j < rightSize) {
merged.push(right[j]);
j = j + 1;
}
return merged;
}
return merge(mergeSort(nums.slice(0, mid)), mergeSort(nums.slice(mid)));
}11.6 计数排序(counting sort)
算法思想:找到要排序数组的最大值和最小值。以最大值 - 最小值 + 1为长度创建一个计数数组。遍历要排序的数组,以当前遍历的元素 - 最小值为索引,在计数数组中自增出现次数。遍历计数数组,判断当前遍历到的元素是否大于0,如果大于0就取当前遍历到的索引 + 最小值,替换待排序数组中的元素。计数排序适合用来排序范围不大的数字,时间复杂度为O(n + m),空间复杂度为O(m)。
优化:上述方法只适合用来排序范围不大的数字,且无法保证重复时的稳定性,需要进行优化—需要对计数数组中所有的计数进行累加(从计数数组的第二个元素开始,每一项和前一项相加,作为计数数组当前项的值);最后,通过反向遍历排序数组,填充目标排序数组:将每个元素放在目标排序数组的当前元素减去最小值的索引处的统计值对应的目标排序数组的索引处,每放一个元素就将统计数组中当前元素减去最小值的索引处的统计值减去1。
实现:
// 计数排序
function countingSort1(nums: number[]): number[] {
const len = nums.length;
const max = Math.max(...nums);
const min = Math.min(...nums);
const counterLen = max - min + 1;
const counter = new Array(counterLen).fill(0);
// 统计出现次数
for (let i = 0; i < len; i++) {
const index = nums[i] - min;
counter[index] = counter[index] + 1;
}
let sortedIndex = 0;
for (let i = 0; i < counterLen; i++) {
while (counter[i] > 0) {
nums[sortedIndex] = i + min;
sortedIndex = sortedIndex + 1;
counter[i] = counter[i] - 1;
}
}
return nums;
}
// 计数排序
function countingSort2(nums: number[]): number[] {
const len = nums.length;
const max = Math.max(...nums);
const min = Math.min(...nums);
const counterLen = max - min + 1;
const counter = new Array(counterLen).fill(0);
// 统计出现次数
for (let i = 0; i < len; i++) {
const index = nums[i] - min;
counter[index] = counter[index] + 1;
}
// 累加统计值
for (let i = 1; i < len; i++) {
counter[i] = counter[i] + counter[i - 1];
}
const sortedNums = new Array(len);
for (let i = len - 1; i >= 0; i--) {
// 可以简化为 sortedNums[--counter[nums[i] - min]] = nums[i];
const counterIndex = nums[i] - min;
counter[counterIndex] = counter[counterIndex] - 1;
const index = counter[counterIndex];
sortedNums[index] = nums[i];
}
return nums;
}
11.7 桶排序(bucket sort)
算法思想:桶排序在所有元素平分到各个桶中时的表现最好。如果元素非常稀疏,则使用更多的桶会更好。如果元素非常密集,则使用较少的桶会更好。创建桶,数量等于原始数组的元素数量,这样,每个桶的长度为 (最大值- 最小值) / (桶数量 - 1),然后通过(元素值 - 最小值 )/ 桶长度,将原始数组中的每个桶分布到不同的桶中,对每个桶中的元素执行某个排序算法使桶内有序,最后将所有桶合并成排序好后的结果数组。
实现:
// 桶排序
function bucketSort(nums: number[]): number[] {
const max = Math.max(...nums);
const min = Math.min(...nums);
const bucketCount = nums.length;
// 桶的间隔 = (最大值 - 最小值)/ 元素个数
const bucketSize = (max - min) / (bucketCount - 1);
const buckets: number[][] = new Array(bucketCount);
for (let i = 0; i < bucketCount; i++) {
buckets[i] = [];
}
// 将每个元素放到桶里
for (let i = 0; i < bucketCount; i++) {
// 计算需要将元素放到哪个桶中,公式为: 当前遍历到的元素值与数组的最小值的差值 / 桶间隔
buckets[Math.floor((nums[i] - min) / bucketSize)].push(nums[i]);
}
// 对每个桶内部进行排序(使用内部算法)
for (let i = 0; i < bucketCount; i++) {
buckets[i].sort((a, b) => a - b);
}
const sortedNums: number[] = [];
for (let i = 0; i < bucketCount; i++) {
sortedNums.push(...buckets[i]);
}
return sortedNums;
}
11.8 堆排序(heap sort)
算法思想:利用堆的性质,对于具有n个元素的待排序序列,第k (k >= 1)趟,将n - k + 1个元素维持为大根堆,将堆顶元素和第n - k + 1个元素交换。如此,后k个元素为有序区。由于交换导致相等元素的相对位置发生改变,属于不稳定排序, 时间复杂度O(nlogn),空间复杂度O(1)。
实现:
// 堆排序
function heapSort(nums: number[]): number[] {
const len = nums.length;
// 对非叶子节点下沉进行堆调整
function heapfiy(nums: number[], index: number, heapSize: number) {
// 交换节点位置,大顶堆:子节点中的较大者
let exchange = index * 2 + 1;
while (exchange < heapSize) {
let right = index * 2 + 2;
if (right < heapSize && nums[right] > nums[exchange]) {
exchange = right;
}
if (nums[exchange] <= nums[index]) {
// 子节点中较大者小于当前节点
break;
}
[nums[index], nums[exchange]] = [nums[exchange], nums[index]];
index = exchange;
exchange = index * 2 + 1;
}
}
// 对待排序数组构建具有数组长度的初始大根堆
for (let i = Math.floor(len / 2) - 1; i > 0; i--) {
heapfiy(nums, i, len);
}
// 第i趟将堆顶元素与倒数第 i 个元素交换,再调整堆顶元素
for (let i = len - 1; i > 0; i--) {
[nums[0], nums[i]] = [nums[i], nums[0]];
heapfiy(nums, 0, i);
}
return nums;
}11.9 基数排序(radix sort)
算法思想:根据数字的有效位或基数将整数分布到桶中。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。对于十进制数,使用10个桶用来分布元素并且首先基于个位数字进行稳定的计数排序,然后基于十位数字,然后基于百位数字。
实现:
// 基数排序
function radixSort(nums: number[], radix = 10): number[] {
const len = nums.length;
const max = Math.max(...nums);
const min = Math.min(...nums);
let significantDigit = 1;
while ((max - min) / significantDigit >= 1) {
// 对当前位进行计数排序
const counter: number[] = [];
for (let i = 0; i < radix; i++) {
counter[i] = 0;
}
// 对当前位进行计数
for (let i = 0; i < len; i++) {
const index = Math.floor(((nums[i] - min) / significantDigit) % radix);
counter[index] = counter[index] + 1;
}
// 计算累积值
for (let i = 1; i < radix; i++) {
counter[i] = counter[i] + counter[i - 1];
}
const aux = new Array(len);
for (let i = 0; i < len; i++) {
// 可以简化为 aux[--counter[Math.floor(((nums[i] - min) / significantDigit) % radix)]] = nums[i];
const counterIndex = Math.floor(((nums[i] - min) / significantDigit) % radix);
counter[counterIndex] = counter[counterIndex] - 1;
const index = counter[counterIndex];
aux[index] = nums[i];
}
nums = aux;
significantDigit *= radix;
}
return nums;
}12 动态规划与数学
动态规划(Dynamic programming,简称DP)是通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。动态规划常常适用于有重叠子问题、最优子结构性质和无后效性质的问题:
- 最优子结构性质。如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构性质(即满足最优化原理)。
- 无后效性。即子问题的解一旦确定,就不再改变,不受在这之后、包含它的更大的问题的求解决策影响。
- 子问题重叠性质。子问题重叠性质是指在用递归算法自顶向下对问题进行求解时,每次产生的子问题并不总是新问题,有些子问题会被重复计算多次。动态规划算法正是利用了这种子问题的重叠性质,对每一个子问题只计算一次,然后将其计算结果保存在一个表格中,当再次需要计算已经计算过的子问题时,只是在表格中简单地查看一下结果,从而获得较高的效率,降低了时间复杂度。
状态转移方程:相同问题在不同规模下的关系。寻找状态转移方程的一般性步骤:
- 找到相同问题(即重叠子问题),相同问题能适配不同的规模。
- 找到重叠子问题之间的关系。
- 找到重叠子问题的特殊解。
12.1 剑指offer动态规划算法题( typescript 版)
斐波那契数列(青蛙普通跳台阶)
青蛙变态跳台阶
丑数
0-1背包问题
不同路径
打家劫舍
地下城游戏
矩形覆盖
最小路径和
12.2 剑指 offer 数学算法题( typescript 版)
二进制中1的个数
数值的整数次方
求1+2+3+...+n
和为S的连续正数序列
圆圈中最后剩下的数(小孩报数问题?)
出现1的次数
剪绳子
不用加减乘除做加法
实现大数相加
实现大数相乘
十进制转k进制