摘要
在本文中,我们研究了掩码自动编码器(MAE)预训练的视频基于匹配的下游任务,包括视觉目标跟踪(VOT)和视频对象分割(VOS)。MAE的一个简单扩展是在视频中随机掩码帧块并重建帧像素。然而,我们发现这种简单的基线严重依赖于空间线索,而忽略了帧重建的时间关系,从而导致VOT和VOS的时间匹配表示次优。为了缓解这一问题,我们提出了DropMAE,它在帧重构中自适应地执行空间注意退出,以促进视频中的时间对应学习。
此外,我们还发现,预训练视频中的运动多样性比场景多样性对于提高VOT和VOS的性能更重要。
引言
在视频对象跟踪(VOT)中,最近的两项工作,SimTrack和OSTrack,探索使用MAE预训练的ViT模型作为跟踪主干。而监督训练学习的是对外观变化不变的与高水平的类相关的特征。尽管取得了很好的性能,但由于图像和视频之间的自然差距,图像网络上的MAE预训练仍然是跟踪任务的次最优训练,即在**静态图像中无法学习到先前的时间对应信息。**然而,以往的跟踪方法已经表明,**时间对应学习(时序关系)是开发一个鲁棒和鉴别跟踪器的关键。**因此,有机会进一步开发专门针对匹配基视频任务的MAE框架,如VOT和VOS。
将MAE扩展到视频的一种简单方法是随机掩蔽视频剪辑中的帧补丁(即视频帧对),然后重建视频剪辑。我们将这个简单的基线表示为双胞胎MAE(TwinMAE)。


给定一个掩码的补丁查询(a masked patch query),如图所示。2 & 4,我们发现TwinMAE严重依赖于邻近的空间在同一帧内重建补丁,这意味着一个沉重的协同适应空间线索(帧内标记)重建和可能导致学习次优时间表示基于匹配的下游任务如视频对象跟踪和分割。
为了解决TwinMAE基线的这个问题,我们提出了专门设计的DropMAE,用于预训练基于匹配的视频下游任务(如VOT和VOS)的掩码自动编码器。我们的DropMAE自适应地执行空间注意退出,以在框架重建过程中打破空间线索(帧内标记)之间的协同适应,从而鼓励更多的时间交互,促进预训练阶段的时间对应学习。
有趣的是,我们通过DropMAE获得了几个重要的发现:
-
DropMAE是一种有效的时间对应学习器,它在基于匹配的任务上比基于imagenet的MAE获得更好的微调结果,预训练速度快2×。
-
预训练视频中的运动多样性比场景多样性对于提高VOT和VOS的性能更为重要。
总之,我们的工作的主要贡献是:
-
据我们所知,我们是第一个研究基于时间匹配的下游任务的掩码自动编码器视频预训练的任务。具体来说,我们探索了各种视频数据源进行预训练,并建立了一个TwinMAE基线来研究其在时间匹配任务上的有效性。
-
我们提出了DropMAE,它在帧重构中自适应地执行空间注意退出,以促进视频中有效的时间对应学习。
相关工作
跟踪和分割
自监督学习
方法
我们提出了一种自监督的视频预训练方法来学习基于时间匹配的下游任务的鲁棒表示,包括VOT和VOS任务。我们首先介绍了一个简单的将MAE扩展到从视频中进行的时间匹配表示学习。然后,我们说明了TwinMAE基线的局限性,并提出了一种空间注意退出策略来促进时间对应学习,记为DropMAE。
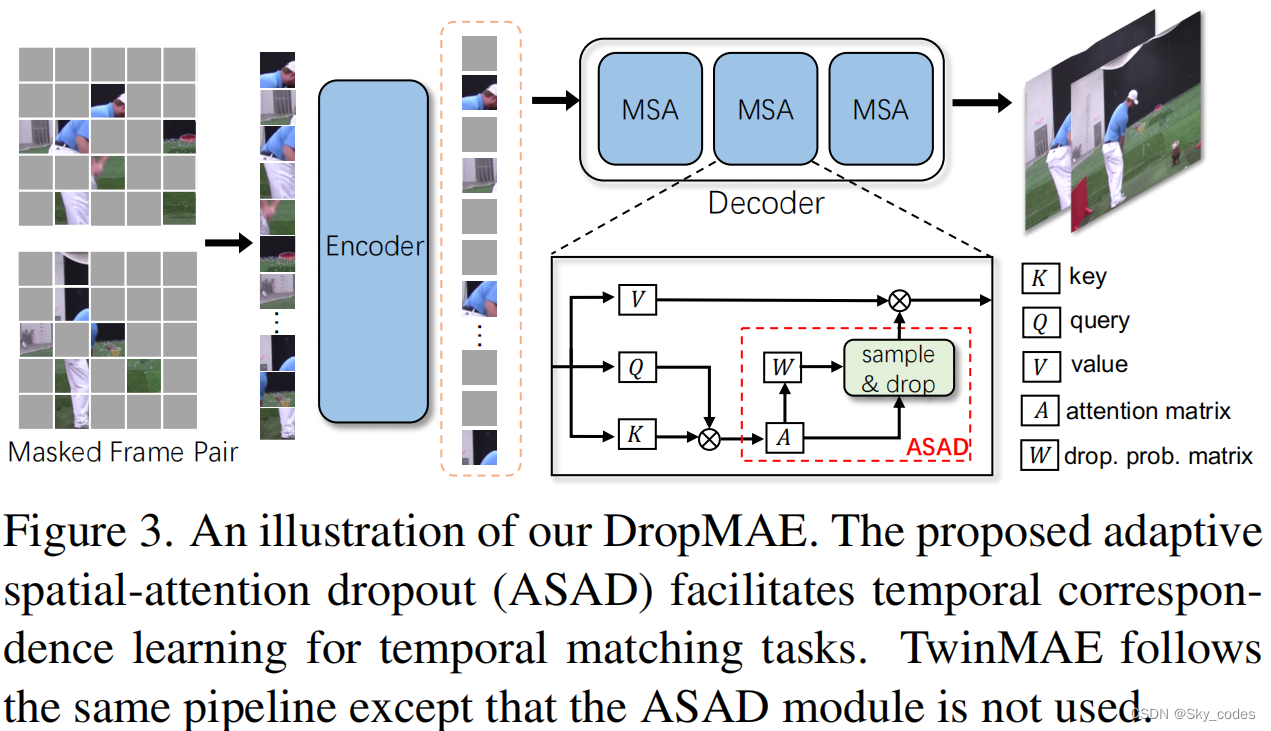
TwinMAE
掩码自动编码器(MAE)模型由编码器和解码器组成。它的基本思想是随机屏蔽图像中的大一部分(例如75%)补丁,然后重建图像像素。具体来说,编码器只将可见块作为特征学习的输入,然后将解码器同时输入可见块和掩蔽块,以进行图像重建。为了适应下游的基于视频匹配的任务,一个简单的扩展是直接将MAE应用于连接的视频帧,希望从视频帧对中学习时间匹配表示,我们称之为TwinMAE。
需要注意的是,现有的将MAE扩展到视频表示学习的作品]主要是为视频动作识别的下游任务设计的,其中一个长视频剪辑(如16帧)用于基于重构的预训练。为了与我们的VOT/VOS下游任务保持一致,我们遵循对象跟踪中使用的一般训练设置,其中从一个视频中采样两帧作为输入到TwinMAE进行预训练。与现有的视频预训练方法相比,由于vit的二次复杂度,这种自适应大大降低了计算和内存成本。
首先,我们在一个具有预定义的最大帧间隙的视频中随机采样2帧。对于每一帧,我们遵循普通的ViT将其划分为不重叠的patches。然后,从两帧中提取的patches被连接在一起,形成完整的patches序列。然后,我们随机掩码patches序列中的patches,直到达到预定义的掩码比率。请注意,我们使用与原始MAE相同的掩码比(即75%),因为两帧的信息冗余应该类似于单个图像。可见补丁通过线性投影嵌入,掩码补丁使用共享的可学习掩码令牌嵌入。所有嵌入的补丁都添加位置嵌入。
帧标识嵌入 ,为了区分两个帧在同一空间位置上的掩码标记,我们使用两个可学习的帧标识嵌入来表示两个输入帧。在每个嵌入的补丁中添加相应的帧标识嵌入。
按照原始MAE [37]中的自动编码管道,编码器只将可见的嵌入的补丁作为输入,解码器输入所有的嵌入的补丁,用于掩码补丁重构。我们使用相同的来自MAE的归一化像素损失来训练整个网络架构。
TwinMAE基线的限制
我们的TwinMAE基线的重建的可视化如图2所示。我们还定量地比较了图4中重建过程中帧内和帧间的平均注意度。有趣的是,我们发现TwinMAE重建严重依赖于帧内斑块或空间线索,这可能导致基于匹配的视频任务的次优时间表征。

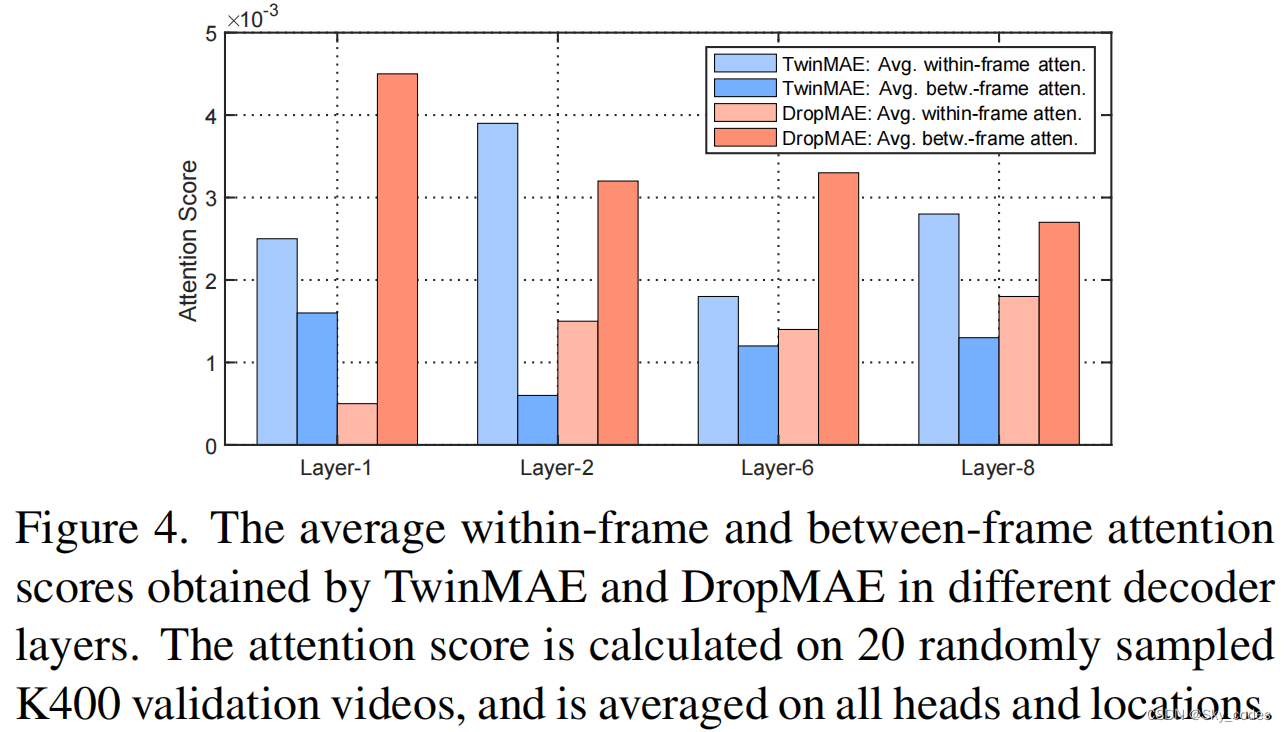
当只使用帧内空间线索时,解码器将只使用相邻补丁中的上下文信息进行重建,因此学习到的编码器表示将嵌入上下文信息。相反,当使用帧间线索时,解码器将学习对帧间的补丁进行匹配,从而在另一帧中恢复相应的目标补丁。因此,使用帧间线索进行解码将使编码器学习支持帧间时间匹配的表示。先前在目标跟踪[3,86]方面的工作也表明,时间对应学习在开发一个鲁棒和有区别的跟踪器中起着关键作用。由于TwinMAE更多地依赖于上下文信息,因此它对于下游跟踪任务仍然是次优的。
Adaptive Spatial-Attention Dropout
解决讨论的TwinMAE问题。我们提出了一种自适应空间注意辍学(ASAD)来促进时间MAE中的时间对应学。
给定一个查询令牌,我们的基本思想是自适应地删除部分帧内线索,以便于模型学习更可靠的时间对应关系,即帧间线索。也就是说,我们限制了同一帧中的查询令牌和令牌之间的交互,并通过操作转换器中计算出的空间注意,鼓励与另一帧中的令牌进行更多的交互。因此,为了最小化重建损失,该模型易于学习更好的时间匹配能力,这是基于匹配的视频任务的关键。
VIT:设 z ∈ R N × D z∈R^{N×D} z∈RN×D为两个连接的输入帧的输入序列,N为两帧中的总patch数,D为特征维数。标准的多头自注意可表述为:
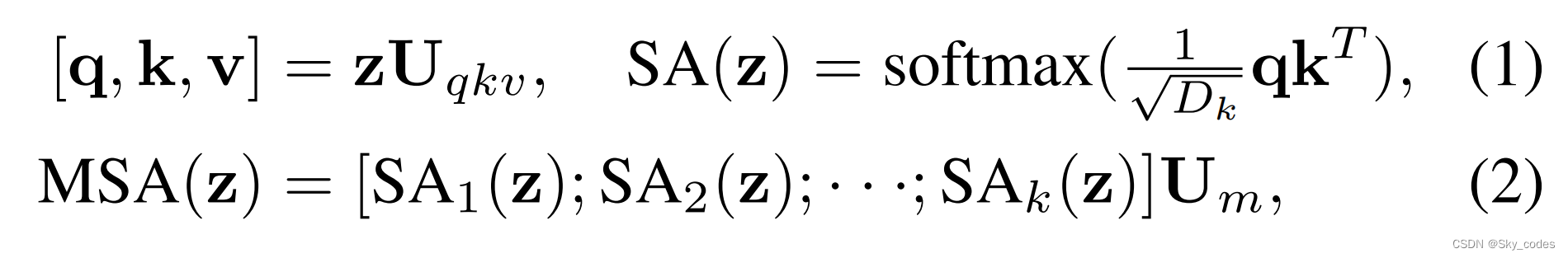
设 A = q k T D k ∈ R N × N A=\frac{qk^T}{\sqrt{D_{k}}}\in R^{N×N} A=DkqkT∈RN×N表示注意矩阵。我们的ASAD在A上执行空间注意退出,以消除一些帧内交互。
Temporal matching probability
我们首先需要考虑应用ASAD的最佳令牌。直观地说,在另一帧中有强匹配的查询标记应该是一个很好的候选对象,因为在没有帧内线索的情况下,它仍然可以使用另一帧中的时间线索很好地重建。在这里,我们定义了一个时间匹配函数 f t e m ( ⋅ ) f_{tem}(·) ftem(⋅)来度量第i个查询令牌的时间匹配概率:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uXb0xmio-1680667872624)(null)]](https://img-blog.csdnimg.cn/b7e584195eef467a9f784861abaf17de.png)
其中,softmax函数应用于A的每一,, f t e m ( ⋅ ) ∈ [ 0 , 1 ] f_{tem}(·)∈[0,1] ftem(⋅)∈[0,1],Ωt(i)表示第i个查询标记的时间索引集,它包含另一帧的所有标记索引。 f t e m ( ⋅ ) f_{tem}(·) ftem(⋅)值越大,表示第i个查询标记在另一帧中匹配的概率越大,因此是一个很好的ASAD候选对象。 f t e m ( ⋅ ) f_{tem}(·) ftem(⋅)的可视化图如图5所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3KYy0e5p-1680667873312)(null)]](https://img-blog.csdnimg.cn/26d518c8914c4c26908c047789be00c9.png)
Overall dropout probability measurement
位置 (i, j) 的总体空间注意力辍学概率是使用时间匹配概率和归一化空间重要性来测量的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GE93wXgj-1680667872631)(null)]](https://img-blog.csdnimg.cn/10e1bcf84c254ec9bdec51d9b5f7db2b.png)
其中 Ωs(i) 是包含所有其他标记索引(即,不包括查询索引本身)与第 i 个查询位于同一帧中。当 W i , j W_{i,j} Wi,j较大时,第i个查询标记在帧间匹配良好,并且第j个帧内标记对于第i个注意评分查询很重要。在这种情况下,在A中删除注意元素(i,j)有助于模型使用帧间(时间匹配的)标记来进行标记学习或重建。
需要注意的是,总共有N(N/2−1)(即不包括自我注意元素),只有这些空间注意元素被考虑退出。通过预先定义的辍学比P,我们从A中全局剔除了全部Nd = P N(N/2−1)注意元素。
Sampling for Dropout
我们从基于退出概率矩阵w的多项分布中提取Nd元素,然后通过将它们的值设为−∞,将其放到A中。在(1)中应用softmax函数后,去除相应的空间注意权值。其他操作与ViT中使用的原始多头自注意机制相同。类似于pytorch的伪代码在补充部分中显示。
由于gpu中的有效矩阵操作,我们的ASAD方法与TwinMAE相比,额外的时间成本可以忽略不计。在训练前阶段,我们将ASAD应用于解码器中的每一层,以学习支持时间匹配的编码器表示。在下一节中,我们将介绍基于预先训练良好的ViT模型的下游任务微调。
下游任务
在获得预先训练的DropMAE模型后,我们对下游时间匹配任务,即VOT和VOS的编码器(即ViT模型)进行微调。
Video Object Tracking
最近,在ImageNet上预训练的MAE ViT模型被应用于VOT,显示了令人印象深刻的结果。我们使用最先进的跟踪器OSTrack 作为我们的微调基线跟踪器。在OSTrack中,裁剪后的模板和搜索图像首先被序列化成序列并连接在一起。然后将整个序列加入位置嵌入和输入到ViT主干中,进行联合特征提取和交互。最后,将更新后的搜索特征输入到预测头部,以预测目标边界框。
在微调阶段,我们使用预先训练过的DropMAE编码器权值来初始化OSTrack中使用的ViT主干。同时,在模板嵌入和搜索嵌入中分别添加两个帧标识嵌入,以保持与预训练阶段的一致性。我们使用了与原来的OSTrack相同的训练损失。详细的训练参数见补充资料,以供参考。
Video Object Segmentation
对于VOS,目前还没有基于ViT的方法。因此,我们构建了一个简单的VOS基线。
输入序列化。给定一个带有二进制掩码的模板帧,VOS的目标是在视频的每一帧中分割感兴趣的对象。与训练前阶段相似,首先将二进制掩模映射、模板和搜索帧转换为补丁序列,然后进行线性投影并添加位置嵌入。向模板和搜索嵌入中添加两个框架标识嵌入,并将掩码嵌入添加到模板嵌入中以进行掩码编码。
联合特征提取和交互作用。模板和搜索嵌入被连接在一起,并输入到ViT主干中进行联合特征提取和匹配。我们使用从ViT的最后一层中提取的更新后的搜索特征来进行掩模预测。
掩码预测。现有的VOS方法采用多分辨率特征进行掩模预测。然而,更新后的搜索功能是单分辨率的。我们遵循,通过两个反卷积模块将搜索特征上采样到2×和4×大小。最后,我们使用与中相同的解码器进行掩码预测。
训练损失。我们使用常用的交叉熵损失来训练整个网络架构。在线推断在在线推理过程中,我们使用具有掩码标注的第一帧作为搜索帧中在线目标匹配的记忆帧。管道图和更多的实现细节可以在补充资料中找到。
实验

比较
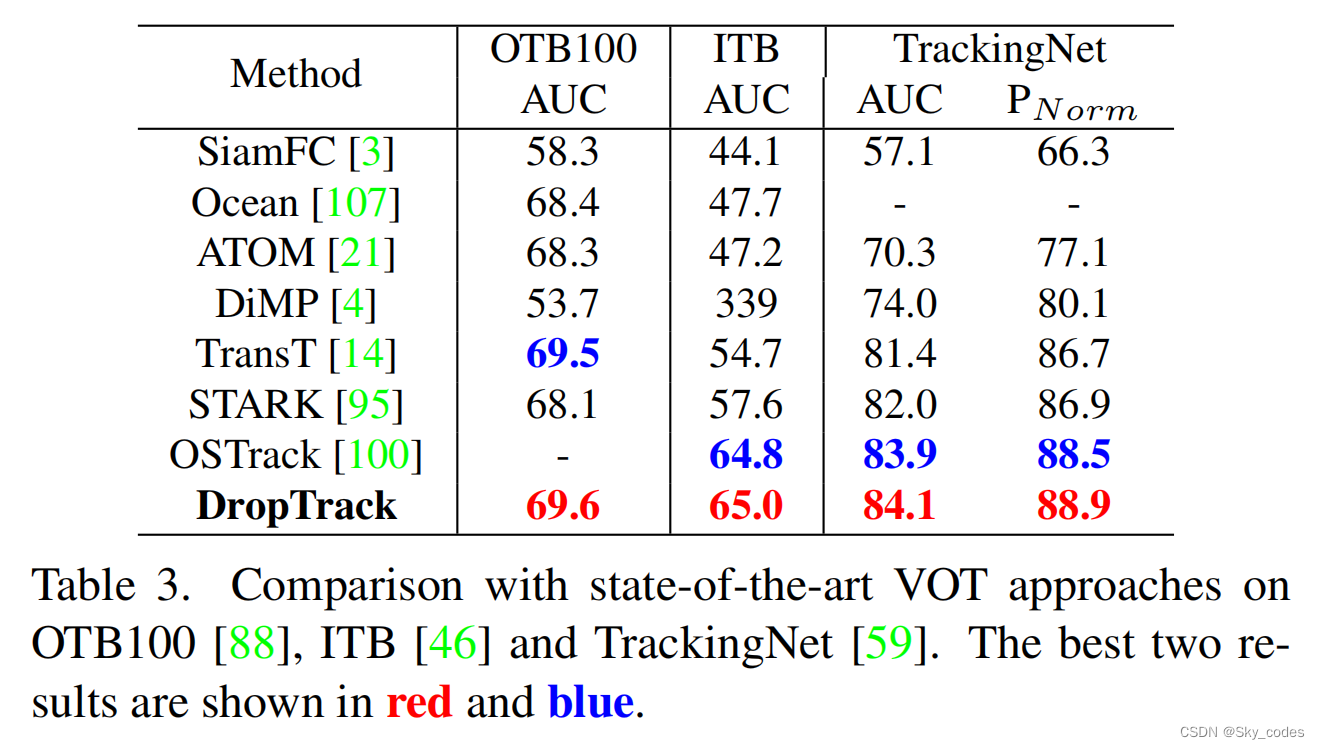
在本节中,我们将将微调后的VOT和VOS模型,表示为DropTrack和DropSeg,与VOT和VOS基准测试上的最新方法进行比较。我们使用在800个时代的K700上训练的DropMAE作为VOT和VOS微调的预训练模型。
Video Object Tracking
为了证明提出的DropMAE对VOT的有效性,我们在7个具有挑战性的跟踪基准上将我们的DropTrack与最先进的跟踪器进行了比较。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CKdZ8u5S-1680667872552)(null)]](https://img-blog.csdnimg.cn/303526114f5144b9a580b2d2cc7faddc.png)
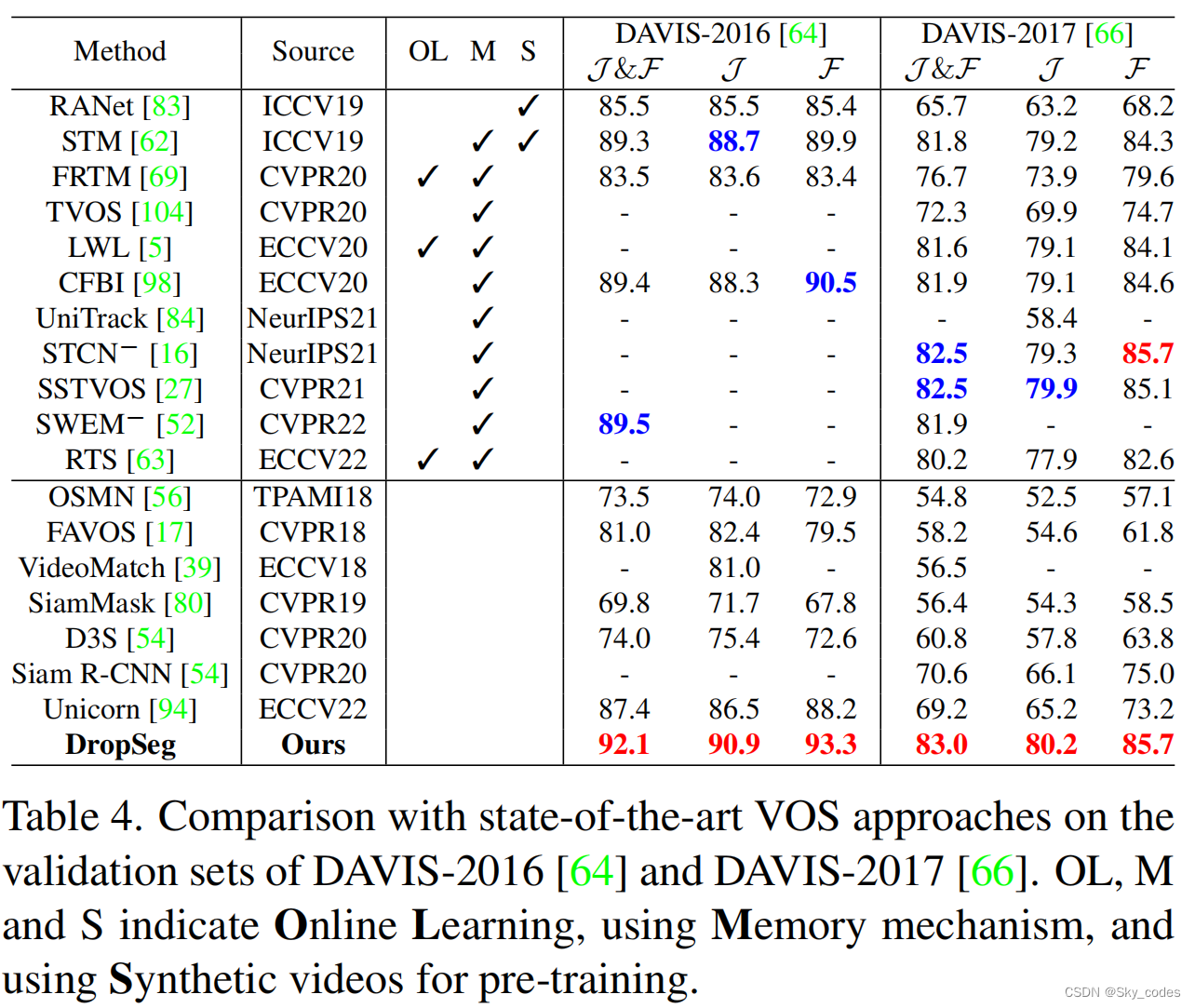
Video Object Segmentation
消融研究
在本节中,我们将进行消融研究,以对我们的方法进行更详细的分析。我们使用DropMAE和400个时代的预训练来进行消融研究。
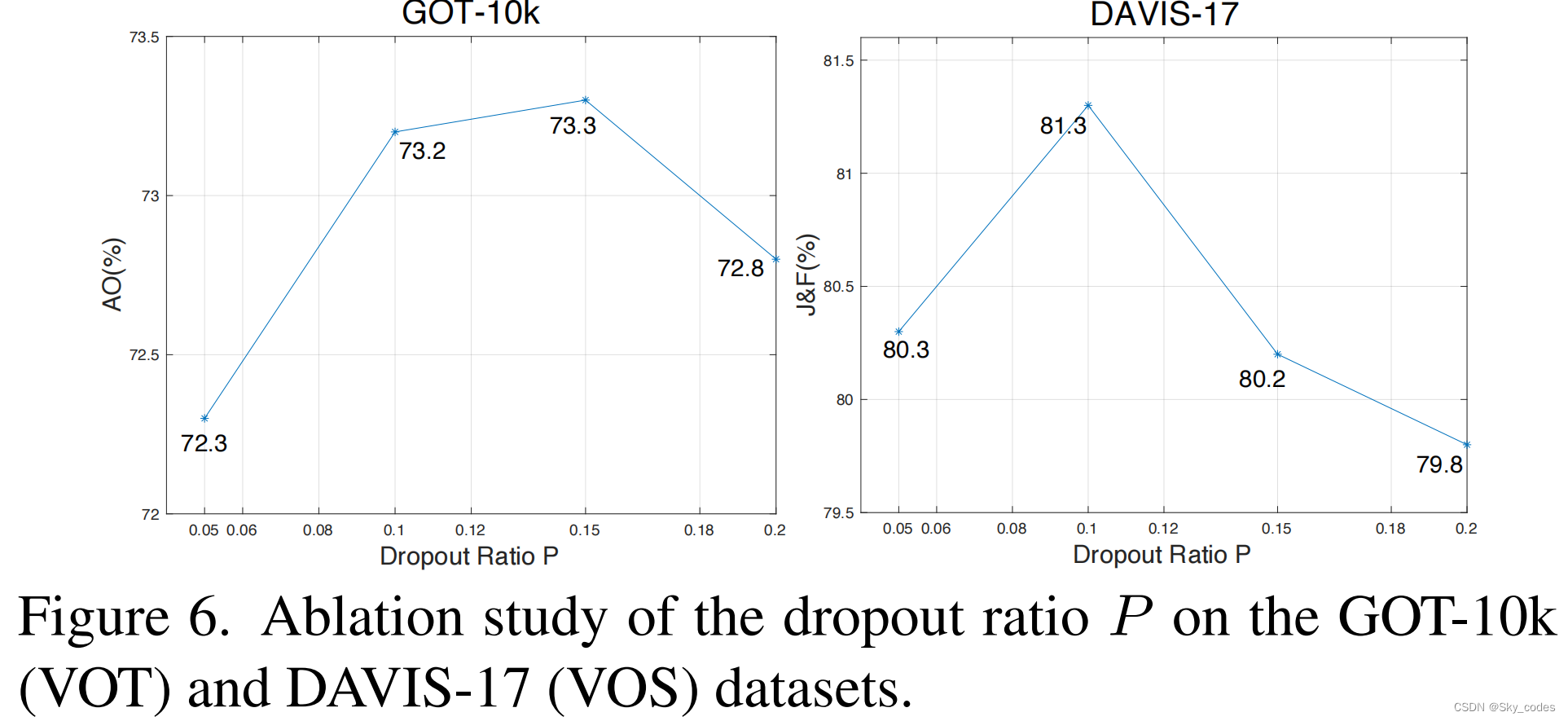
The effect of dropout ratio P.
我们在图6中研究了辍学率P的影响。P = 0.1相对较小的辍学率在VOT和VOS任务中都很有效。同时,减少过多的空间线索(如P=0.2)会降低下游任务,这主要是因为空间线索对准确的定位和分割也很有用。P = 0.1是最优设置,因此我们在下面的实验中采用它。
Pre-training video sources.
由于我们是第一个探索掩码的时间匹配任务的自动编码器预训练,所以不清楚哪个视频数据集是预训练的最佳选择。下游跟踪结果见表5。即使在WebVid中使用96万个视频进行预训练,性能也不好。这说明WebViD并不是跟踪预训练的好选择,这主要是因为它是一个视频标题数据集,专注于场景多样性,缺乏丰富的物体运动。跟踪从丰富的动作类(即700个K700动作类)的预训练中获益,该模型可以从中学习到更强的时间匹配能力。
Applying ASAD to the encoder.
在这里,我们测试应用ASAD到所有的层,包括掩码自动编码器的编码器和解码器。如表6所示,该变体比原始基线有了改进(SR在0.75中为0.6%)。考虑到其额外的成本和有限的性能改进,我们只将ASAD应用于解码器
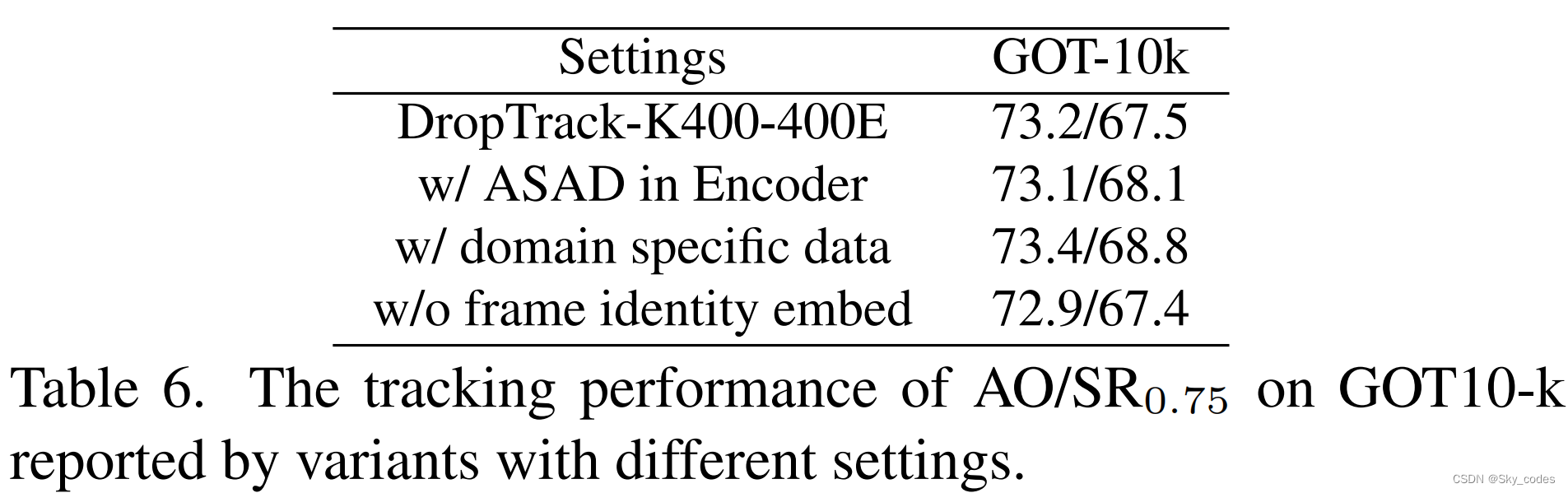
Domain specific data.
我们还将跟踪训练数据(不使用方框注释),包括跟踪gnet、LaSOT和GOT-10k,添加到K400中进行预训练。使用较大的预训练集的下游跟踪性能为73.4/68.8,优于基线。结果表明,特定领域的数据有助于弥合领域的差距,这可以作为未来扩展动力学数据集与更多的跟踪视频的工作。
Frame identity embedding.
在预训练过程中,使用帧身份嵌入来识别两帧相同二维位置的掩蔽补丁。从表6中,我们可以发现,没有帧标识嵌入的下游微调比没有嵌入它的性能更差,因为不使用它与预训练阶段不一致。
结论
本文研究了基于时间匹配的下游任务的掩码自编码预训练。具体来说,提出了一种自适应空间注意退出方法,以促进视频自监督预训练中的时间对应学习。我们表明,我们提出的训练前方法DropMAE在VOT和VOS上比基于图像的MAE可以获得更好的下游性能,同时使用50%的预训练时间。此外,作为研究这个问题的第一个工作,我们展示了在预训练前选择视频源的指导方针,即选择具有丰富运动信息的视频更有利于基于时间匹配的下游任务。
附录
我们在算法1中展示了我们提出的自适应空间注意退出(ASAD)的伪代码。可以看出,该实现是简单和简洁的,它可以灵活地集成到现有的方法中,如MAE [37]中。该实现主要包括三个步骤: 1)时间匹配概率f tem的计算;2)帧内空间归一化注意A spa的计算;3)多项分布的退出抽样。我们的代码和预先训练过的模型将在论文发表后公开使用。

实施细节
在本节中,我们将详细介绍DropMAE预训练的实现细节,以及下游VOT和VOS任务的微调细节。
Downstream VOT Fine-Tuning
根据跟踪基线OSTrack ,我们分别使用192×192和384×384像素的模板和搜索大小,并使用跟踪特定的数据来微调我们的DropMAE模型(见秒。4 NVIDIA A100gpu。在OSTrack中提出的候选消除模块也被用于一个公平的比较。对于完整的300历元微调,详细的超参数如表8所示。在对GOT- 10k进行微调时,总训练历元减少到100,学习率在80历元时衰减。我们的DropTrack的推理速度与基线OSTrack相同,它是在单个GPU上测量的58.1 FPS。
可视化
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jc6QjvgU-1680667872654)(null)]](https://img-blog.csdnimg.cn/b79ecdcbd3fd465b9a7274c705161cc0.png)
在图8中,我们展示了由我们的DropTrack和其他3个比较跟踪器获得的定性跟踪结果。所选的序列包含各种挑战,包括显著的外观变化、背景簇、照明变化和类似的对象。由于强大的DropMAE预训练模型,我们的DropTrack很好地处理了这些挑战。
Frame Reconstruction

我们在图10中显示了由我们的DropMAE得到的视频帧重建结果。可以看出,虽然在重建过程中利用的空间线索较少,但我们的DropMAE仍然通过探索时间线索或帧间斑块获得了良好的重建结果。