点击上方“Java秃头哥”,选择“星标”
每天分享优质干货

1、对查询进行优化,应尽可能避免全表扫描
首先应考虑在 where 及 order by 涉及的列上建立索引。
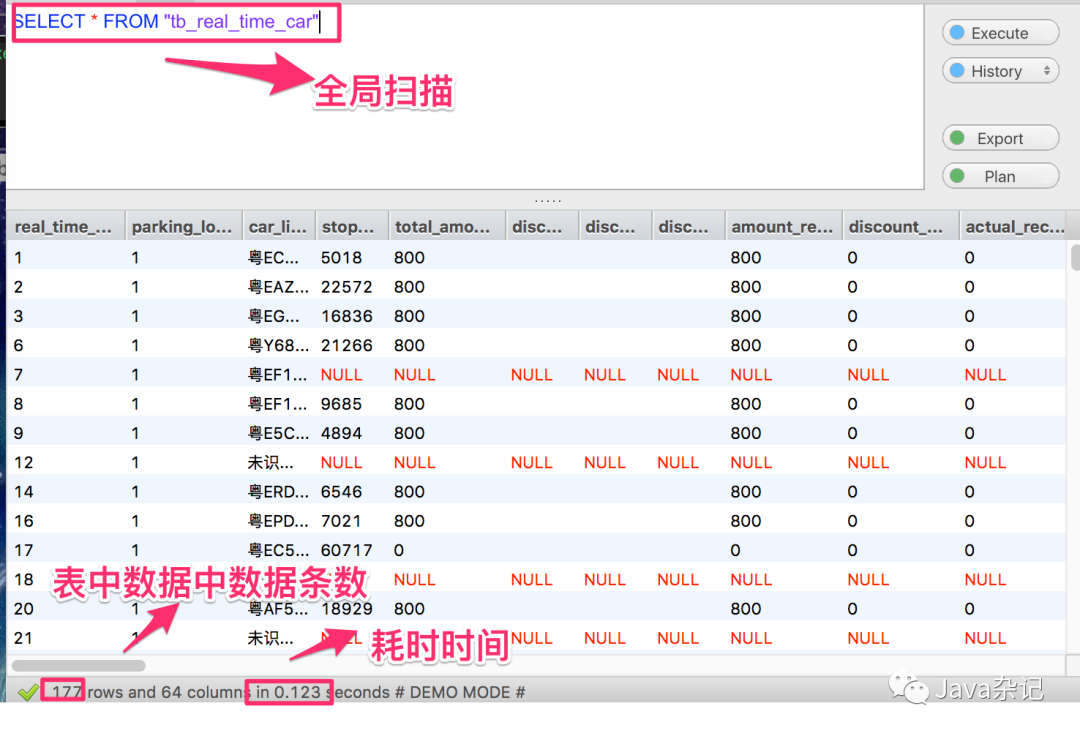
下面我们来以一个表中177条数据比较一下,全表扫描与建立索引之后性能的一个比较.
1.1 全表查询
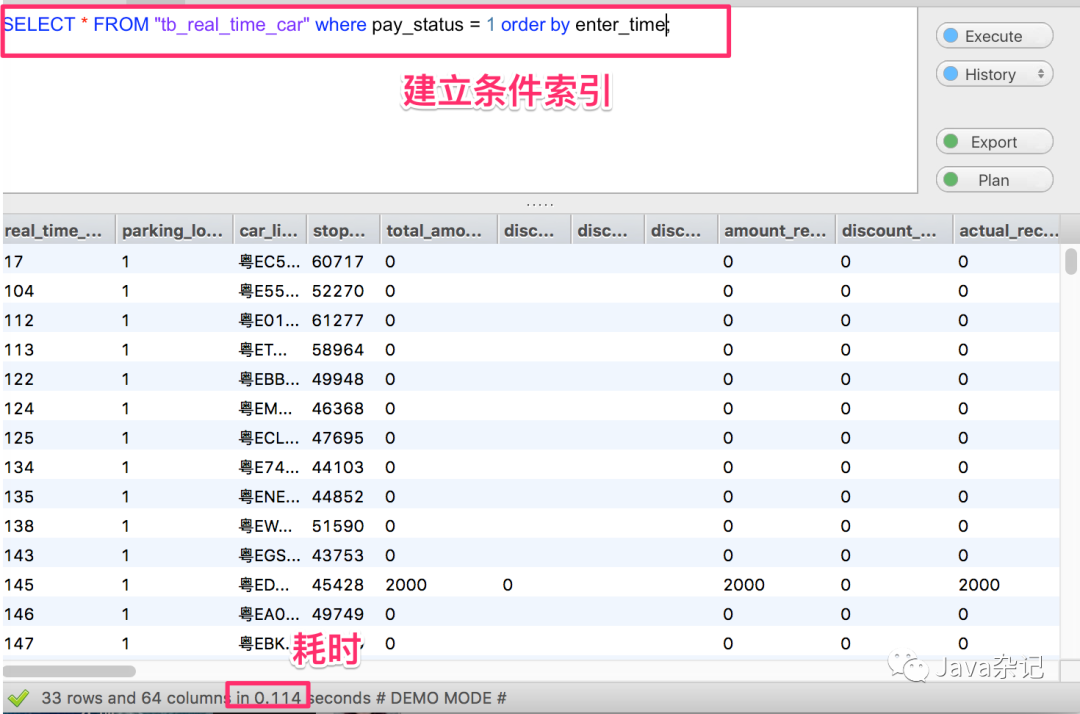
 1.2 建立索引查询
1.2 建立索引查询
1.3 结论
从这两种方式查询数据库结果看,建立索引之后查询速度提高了些,现在数据量还不明显,如果表中有10万条速度,差异就会很明显了.
2、写数据语句时尽可能减少表的全局扫描
2.1 减少where 字段值null判断
SELECT * FROM "tb_real_time_car" where pay_status = null
如何这样做,就会导致引擎放弃使用索引而进行全表扫描
应该这样去设置(也就是在没有值时,我们在存数据库时自动默认给个o值,而不是什么都不写):
SELECT * FROM "tb_real_time_car" where pay_status = 0
2.2 应尽量避免在 where 子句中使用!=或<>操作符
SELECT * FROM "tb_real_time_car" where pay_status != null ;
//或者
SELECT * FROM "tb_real_time_car" where pay_status <> null ;
这样写将导致引擎放弃使用索引而进行全表扫描。
2.3 应尽量避免在 where 子句中使用 or 来连接条件
SELECT * FROM "tb_real_time_car" where pay_status != null or enter_time = null;
这样将导致引擎放弃使用索引而进行全表扫描
可以这样操作:
SELECT * FROM "tb_real_time_car" where pay_status != null union all
SELECT * FROM "tb_real_time_car" where enter_time = null;
2.4 in 和 not in 也要慎用
SELECT * FROM "tb_real_time_car" where rowed in [1,2,3,4];
//或者
SELECT * FROM "tb_real_time_car" where rowed not in [1,2,3,4];
这样操作,也会导致全表扫描
可以这样来写:
SELECT * FROM "tb_real_time_car" where rowed between 1 and 5;
2.5 少使用模糊匹配 like
SELECT * FROM "tb_real_time_car" where enter_time like '%2016-09-01%'
2.6 应尽量避免在 where 子句中对字段进行表达式操作
SELECT * FROM "tb_real_time_car" where rowid/4 =100;
这样写,将导致引擎放弃使用索引而进行全表扫描
应该写成:
SELECT * FROM "tb_real_time_car" where rowid =4*100;
2.7 任何地方都不要使用*通配符去查询所有
SELECT * FROM "tb_real_time_car" where rowid/4 =100;
以通配符*去查询所有数据,这样做也是非常耗时的,我们应该需要什么字段就查询什么字段.
应该这样做:
SELECT leave_time FROM "tb_real_time_car" where rowid/4 =100;
3、不要在条件判断时进行 算数运算
SELECT * FROM "tb_real_time_car" where rowid/4 =100;
所以不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,这样系统将可能无法正确使用索引
应该这样做:
SELECT * FROM "tb_real_time_car" where rowed =400;
4、很多时候用 exists 代替 in 是一个好的选择
SELECT * FROM "tb_real_time_car" where rowed (select rowed from "tb_real");
应该这样来写:
SELECT * FROM "tb_real_time_car" where exists (select rowed from "tb_real" where rowed = tb_real.rowid);
5 论索引技巧
5.1 并不是所有索引对查询都有效
SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用
5.2 索引并不是越多越好
索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
5.3 应尽可能的避免更新 clustered 索引数据列
因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
5.4 尽量使用数字型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
6 创建数据库时应该注意地方
6.1. 尽可能的使用 varchar/nvarchar 代替 char/nchar
因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
6.2 用表变量来代替临时表。
如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
6.3 避免频繁创建和删除临时表,以减少系统表资源的消耗。
6.4 尽量避免使用游标
因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
7 数据放回时注意什么
7.1 尽量避免大事务操作,提高系统并发能力。
这样可以有效提高系统的并发能力
7.2 尽量避免向客户端返回大数据量
若数据量过大,应该考虑相应需求是否合理。
8.总结
1.尽量避免where中包含子查询;
2.where条件中,过滤量最大的条件放在where子句最后;
3.采用绑定变量有助于提高效率;
4.在索引列上使用计算、改变索引列的类型、在索引列上使用!=将放弃索引;
5.运算符效率:exists高于in高于or,(not exists高于not in);
(这里指出:in和or都是效率较低的运算,但是in的效率:O(logn)仍然比or的效率:O(n)高的多,尤其当运算列不是索引的时候尤为明显)
6.避免在索引列上使用is null和is not null;
7.使用索引的第一个列;
8.用union-all替代union;
9.like ‘text%’使用索引,但like ‘%text’不使用索引;
--END--1、MySQL中,当update修改数据与原数据相同时会再次执行吗?
2、SQL 性能优化梳理,干掉慢SQL!
3、SQL语句大全,所有的SQL都在这里,赶紧收藏!
4、MyBatis动态SQL(认真看 ,以后写SQL就爽多了)
5、在Redis中设置了过期时间的Key,需要注意哪些问题?
关注公众号,查看更多优质文章

关注公众号并回复 222 领取100本架构师相关的电子书,程序员都用得着,不要再浪费时间去网站上找或者花钱买了。点个[在看],支持一下哦~