开学第二周小结
- 本周进展
- 对抗神经网络模型(Generative Adversarial Networks)
- GAN网络模型主要架构
- GAN对抗网络中的损失函数
- GAN网络中的训练问题和缺点
- DCGAN的改进之处
- 图像修复与可学习的双向注意力图
- 论文研究背景
- 论文介绍
- 论文相关工作
- 网络结构
- 实验
- 创新点
- 1.网络模型上的修改
- 2.掩码卷积上的修改
- 本周小结
本周进展
这周时间可能不够,先记着一半,后半看周六日能不能看完
对抗神经网络模型(Generative Adversarial Networks)
GAN网络又叫做生成式对抗网络,是近年来在无监督学习领域中最具有发展前景的神经网络模型。GAN网络如其名字一般,是由两个互相对抗的神经网络组成的,一个叫做生成器网络,另一个叫做鉴别器网络。但是,在原始的GAN理论中,G和D不一定需要是神经网络,只要是能够实现相似生成和判别的函数即可。
GAN网络模型主要架构
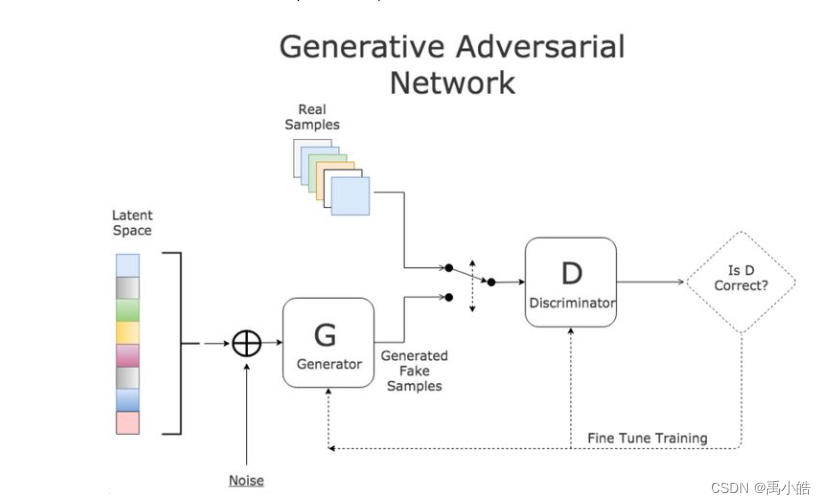
GAN网络模型的架构如图所示,首先原始数据集中的数据叫做真图片,由生成器网络学习生成的图片叫做假图片。鉴别器网络的目的即通过输入原始数据集的数据和生成的假图片数据,经过模型训练能够精准的识别出来哪些是真图片哪些是假图片。而生成器网络的目的是根据鉴别器网络的识别结果,生成更类似于真图片的假图片,从而使得鉴别器无法识别出来。由此形成一种对抗的形式,鉴别器要不断的训练能够以更高性能识别假图片,而生成器同样根据不断的训练对模型不断优化,从而实现生成出的假图片可以欺骗过生成器。
GAN对抗网络中的损失函数
在上文中,已经简要介绍了对抗生成网络的主要架构,接下来围绕网络的损失函数进行分析,由上文的解释可以看到,无论是生成器还是鉴别器,最核心的是通过鉴别器的结果来对两个模型进行调优的。简要来说,鉴别器需要根据鉴别器的结果进行模型的优化,而生成器同样是看模型是否欺骗过鉴别器而进行优化。因此损失函数主要集中在对鉴别器上进行设计。如下图所示。
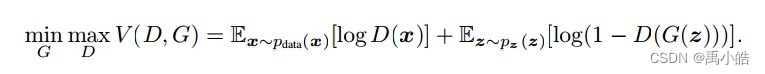
这就是GAN网络的损失函数,看起来很复杂,其实按照上面所讲的,主要的核心在于鉴别器网络的结果,那么将这个公式拆解为两个部分进行分析。
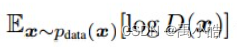
第一个部分为公式的前半部分,x`pdata代表了原始数据集中的图片,也是所谓的真图片,公式的意思的将原始图片经过鉴别器得到的结果log化后计算其熵值。作为鉴别器的损失函数,自然希望熵值越大,则能说明模型的性能越好。所以损失函数要尽量使这个值尽可能的大。
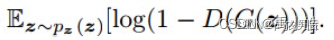
公式的后半部分G(z)则代表了生成器生成的假图片经过鉴别器的结果,作为生成器的损失函数,则希望D(G(z))的结果为1也就是鉴别器将假图片鉴定为了真图片。因此则自然希望这部分公式的值越小越好。通过这两部分,也正对应了一开始公式中所写的minG和maxD。
GAN网络中的训练问题和缺点
训练GAN网络时在两个阶段时,当训练生成器时需要冻结鉴别器。训练鉴别器时需要冻结生成器。
生成器的损失值是鉴别器的值来计算的,而鉴别器的输出是一个概率值,所以需要使用交叉熵来计算。
DCGAN的改进之处
- DCGAN的鉴别器和生成器舍弃了池化层,而生成器中的所有卷积结构换成反卷积,鉴别器中则保持CNN的整体结构
- 在鉴别器和生成器中都加入BN层来加速模型的计算,但是在鉴别器输入层和生成器的输出层不能加BN层,如果加了会导致样本震荡以及模型不稳定
- 生成器网络中使用tahn函数加Relu函数作为激活函数,鉴定器中把LeakyReLU作为激活函数。
图像修复与可学习的双向注意力图
论文研究背景
现存的大部分CNN卷积神经网络模型在处理不规则的孔洞时的效果不好,后续出现的部分卷积(Pconv)出现能解决这个问题,但是部分卷积只考虑前向掩码更新。在本文中,设计了一种改进U-net的网络模型,通过重新设计掩码规则和激活函数,使得出现反向注意图,从而得到一种双向的注意力图模型,这样的设计使得U-net模型更加专注于对不规则的缺失部分的填补。
论文介绍
此节介绍了图像修复从传统的范例方法一直改进到本文提出方法中的差别。
1.传统范例方法在产生细节纹理方面有优势,但是在获得高级语义方面仍然有限,并且可能无法生成复杂和非重复的结构。
2.利用对抗神经网络来实现图像修复,但是对不规则孔洞的处理仍然存在差距,而且在经过一些处理后还是无法解决。
3.基于传统范例的方法和对抗神经网络结合的方法,会大大增加计算成本,但是在矩形孔洞的处理上效果比较不错,但是在不规则孔洞上的处理仍存在差距。
4.在传统方法和普通CNN对抗神经网络解决不了不规则孔洞的问题时,PCONV部分卷积通过使用一种叫做掩码卷积的模块,使得每次只输出未被掩盖的卷积以及加入特征重归一化进行缩放,并且提出了一种掩码更新规则来更新下一层的掩码。在效果上有较大的提升
在本文的方法中,在u-net模型的基础上加入了反向注意力图的机制,使得形成双向注意力图机制,可以引入对抗性损失来提高结果。并且重新设计了一种可学习的注意力映射模块,作用是对特征重新归一化以及更改掩码更新规则。
论文相关工作
基于范例的修复方法原理,简单来说就是从已知区域搜索粘贴,从外部到内部来逐渐填补孔洞,先修复主体结构后填充缺失区域。为了提高填补的效果,引入了补丁优先级测度,有时间再去研究这个。

介绍了深度卷积神经网络在图像修复上的发展历程

网络结构
由于原有的掩码激活函数不具有可微性,于是对其进行改进,如下图所示。



通过对激活函数的改进后,网络的结构也发生了变化,如下图所示

模型的输出函数也发生了变化,由原来的单向变成了双向传播的


本文中采用了四种损失函数,分别是像素重建损失、感知损失、风格损失和对抗性损失。(暂时不懂)
实验
最后各种对比实验,本文的LBAM模型和全局、PM、CA、Pconv等模型比较以及自身未学习、前向传播、sigmod、LRelu、Relu、w/o等不同状态下的效果比较。

创新点
只能说不愧是ICCV上的顶会论文,这篇文章给我带来的感受和上周看的两篇完全不一样,本文以U-net模型为基础,对其网络结构层次上进行修改使其能够更加适用于本文的图像修复中。
1.网络模型上的修改
传统U-net模型的结构如下图所示,其实比我想象中的简单一点,如图中的结构一样,前面一半是卷积层加上池化层的结合。为什么选择大小为3的卷积,是因为大小为1的卷积不会带来感受野的变化,而大小为2的卷积会使得在进行SAME卷积后无法通过反卷积的形式将图片还原为原始尺寸。池化层的作用是为了因为卷积通道增多而带来的大量参数,使用尺寸大小为2的核可以使得每次的参数量减半。
在U-net过了前半后,一部分再经过3个卷积层变成(28,28,1024)大小的,经过一次反卷积对其进行大小进行还原,什么是反卷积呢,其实也很简单,通过将图片补足够的padding值将其进行扩大之后,再进行一次卷积操作就得到了比原图片更大的卷积图片,反卷积就等于full卷积,关于反卷积中的步长则不再指的是卷积的移动步长,而是指插入padding值的步长。在经过一次反卷积后,图片的大小变成(56,56,512)这个时候将之前正向卷积时候大小为(56,56,512)的图片进行拼接从而得到了下图中的白色方块。这样做的目的是为了弥补在卷积和反卷积中图像丢失了太多的特征,随后将拼接后的图片经过反卷积的卷积的操作逐步得到输出图片。

在介绍完传统的U-net模型后,介绍本文中基于U-net模型改进后的LBAM模型。文本的模型分为正向和反向两个过程,首先介绍正向方面,正向方向的话结构和U-net模型差不多,但是在模型中会根据mask图片去得到正向的注意力图,并且在前向传播的每层中都会加上正向注意力图一起进行传播。这点和上面介绍的网络结构模型差不多,正向理解起来比较简单。
到了中间大小图片的通道数为512时,在传统U-net模型中这里会将正向传播的得到特征图进行拼接从而对在卷积中缺失的特征进行弥补,而本文从则是将其与注意力图进行拼接。
反向注意力图的过程首先是根据mask矩阵的特性对其像素点进行取反的操作,形成了如下图右下角的1-M图片。然后根据取反后的mask图片进行卷积操作,在进行6层的卷积后,将最后得到图像与正向拼接经过反卷积后的特征图再次进行拼接,并且对每次在之后的每次反卷积中都将其与相应的反向注意力图进行拼接。将拼接后的图片进行一步步的反卷积得到最后的结果。这也是解释为什么本文叫做双向注意力图模型,不仅是从正向进行拼接,同时对缺失区域进行像素取反后进行反向的拼接。这样也使得本文的模型更加专注于修复图片中那些缺失的不规则的区域。

2.掩码卷积上的修改
这部分可能理解的不是很透彻,掩码卷积又称Pconv,和传统卷积的不同是掩码卷积采用了剪枝的操作来进行优化,分为模式化剪枝和联通性剪枝,模式化卷积是针对每个卷积的内部,对其进行部分权重进行清零,如下图红色部分所示。==而连通性剪枝我的感觉和dropout层的效果一样,对部分卷积核进行删除,而且我不明白如果这样进行是不是会导致模型的通道数每次进行改变,这个以后可以自己再研究下。==经过清华大学以及一起合作的学者一起研究后,将剪枝化转化为了对神经网络模型权重中加入了一层二进制膜,通过这些膜和卷积权重进行相乘后就得到了卷积的稀疏性。

然后就引出了本文的创新点,上面模型结构图时可以看到在注意力图的正向传播和与特征图进行拼接时都存在着激活函数,一部分是注意力图的激活函数,一部分是掩码更新的激活函数。传统的激活函数如下图所示,其中掩码更新激活函数就很类似上面提到的掩码卷积的二进制膜形式,但是根据本文描述的,这样的掩码卷积激活函数由于没有可微性,会导致模型在端到端训练的过程中这些激活函数不会进行更新,因此本文对这部分进行了进一步的修改。

修改过后的函数如下图所示。至于为什么这么修改我看不懂了,掩码的激活函数可以看懂是当a=0时其等于上述没有修改的,当a不为0时,会根据模型在训练的过程中学习参数。
本周小结
第一次学习图像修复领域,收货还算挺多的,第一篇论文是本科生的,我就没写啥阅读体会,主要是好跑代码上手,第一个主要就用了非常传统的DCGAN模型。由此也是我第一次学习到什么叫做对抗性神经网络,通过两个模型不断互相比较从而优化自身性能的想法确实厉害。这篇论文虽然是本科生毕业论文,但是对我而言都是新领域,收货还是不少。
在阅读完上面那个之后,找了一篇2019年ICCV上的图像修复的论文并且复现了下代码,这篇论文给我带来的感受就更多了,首先论文从介绍以及相关工作方面介绍了深度学习在图像修复这个领域是怎么进行的。从最初的基于范例的方法,引入补丁优先级的优化策略,从图片缺口的外部进行填补,主要一步步从外部填补到内部。到基于深度神经网络以及带来改变的掩码卷积方法,现在经常使用的对抗性神经网络,更是让我看到了多少代人不断的努力带来技术的更新,如果以后有机会要去多读读相关的论文。最后到本文所创新的方法,上周看的两篇论文主要是围绕对模型的部分模块进行优化改进,简单来说可以理解为一种通用的方法,但是本文只能说不愧是顶会论文,从模型的部分函数到模型网络整体的结构都进行了针对与修复图片不规则缺失部分修复这个问题进行的大改,使得模型更够更加专注于这一个问题,这个部分确实让我看出来了顶会和普通论文之间存在的差距。




