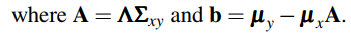UniT: Unified Knowledge Transfer for Any-Shot Object Detection and Segmentation
UniT:任意样本量的目标检测和分割的统一知识转移
论文地址:https://openaccess.thecvf.com/content/CVPR2021/papers/Khandelwal_UniT_Unified_Knowledge_Transfer_for_Any-Shot_Object_Detection_and_Segmentation_CVPR_2021_paper.pdf
代码地址:GitHub - ubc-vision/UniT
摘要
Methods for object detection and segmentation rely on large scale instance-level annotations for training, which are difficult and time-consuming to collect. Efforts to alleviate this look at varying degrees and quality of supervision. Weakly-supervised approaches draw on image-level labels to build detectors/segmentors, while zero/few-shot methods assume abundant instance-level data for a set of base classes, and none to a few examples for novel classes. This taxonomy has largely siloed algorithmic designs. In this work, we aim to bridge this divide by proposing an intuitive and unified semi-supervised model that is applicable to a range of supervision: from zero to a few instance-level samples per novel class. For base classes, our model learns a mapping from weakly-supervised to fully-supervised detectors/segmentors. By learning and leveraging visual and lingual similarities between the novel and base classes, we transfer those mappings to obtain detectors/segmentors for novel classes; refining them with a few novel class instance-level annotated samples, if available. The overall model is end-to-end trainable and highly flexible . Through extensive experiments on MS-COCO [32] and Pascal VOC [14] benchmark datasets we show improved performance in a variety of settings.
目标检测和分割方法依赖于大规模的实例级标注进行训练,这些标注难以收集且耗时。解决这个问题很大程度上取决于监督的质量。弱监督方法利用图像级别的标签来构建检测器/分段器,而零/少样本方法为一组基类假设了丰富的实例级别数据,为新类假设了很少的实例级别数据。这种分类法在很大程度上是孤立的算法设计。在这项工作中,我们的目标是通过提出一个直观、统一的半监督模型来弥合这一分歧,该模型适用于一系列监督:从零到每个新类的几个实例级样本。对于基类,我们的模型学习从弱监督到完全监督检测器/分段器的映射。通过学习和利用新类和基类之间的视觉和语言相似性,我们转移这些映射以获得新类的检测器/分段器;如果可以的话,可以使用几个新的类实例级注释示例来细化它们。整个模型具有端到端的可训练性和高度灵活性。通过对MS-COCO[32]和Pascal VOC[14]基准数据集的大量实验,我们发现在各种设置下性能都有所提高。
1 介绍
Over the past decade CNNs have emerged as the dominant building blocks for various computer vision understanding tasks, including object classification [21, 45, 52], detection [33, 42, 43], and segmentation [8, 20]. Architectures based on Faster R-CNN [43], Mask R-CNN [20] and YOLO [42] have achieved impressive performance on a variety of core vision tasks. However, traditional CNN-based approaches rely on lots of supervised data for which the annotation efforts can be time-consuming and expensive [22, 29]. While image level class labels are easy to obtain, more structured labels such as bounding boxes or segmentations are difficult and expensive. Further, in certain domains (e.g., medical imaging) more detailed labels may require subject expertise. The growing need for efficient learning has motivated development of various approaches and research sub-communities.
在过去十年中,CNN已成为各种计算机视觉理解任务的主要构建块,包括目标分类[21,45,52]、检测[33,42,43]和分割[8,20]。基于Faster R-CNN[43]、Mask R-CNN[20]和YOLO[42]的体系结构在各种核心虚拟任务上取得了令人印象深刻的性能。然而,传统的基于CNN的方法依赖于大量有监督的数据,因此注释工作可能耗时且昂贵[22,29]。虽然图像级别的类标签很容易获得,但更结构化的标签(如边界框或分段)很难获得,而且成本也很高。此外,在某些领域(如医学成像),更详细的标签可能需要专业知识。对高效学习的需求不断增长,推动了各种方法和研究子社区的发展。
On one end of the spectrum, zero-shot learning methods require no visual data and use auxiliary information, such as attributes or class names, to form detectors for unseen classes from related seen category detectors [3, 16, 40, 65]. Weakly-supervised learning methods [2, 5, 12, 29, 34, 61] aim to utilize readily available coarse image-level labels for more granular downstream tasks, such as object detection [3, 40] and segmentation [29, 71]. Most recently, few-shot learning [1, 41, 49, 60] has emerged as a learning-to-learn paradigm which either learns from few labels directly or by simulation of few-shot learning paradigm through meta-learning [15, 47, 57]. An interesting class of semi-supervised methods [17, 22, 26, 56, 58, 68] have emerged which aim to transfer knowledge from abundant base classes to datastarved novel classes, especially for granular instance-level visual understanding tasks. However, to date, there isn’t a single, unified framework that can effectively leverage various forms and amounts of training data (zero-shot to fully supervised).
另一方面,零样本学习方法不需要视觉数据,并使用辅助信息,如属性或类名,从相关的可见类别检测器中形成未知类别的检测器[3,16,40,65]。弱监督学习方法[2,5,12,29,34,61]旨在利用现成的粗图像级别标签来执行更精细的下游任务,如目标检测[3,40]和分割[29,71]。最近,少样本学习[1,41,49,60]已经成为一种学习到学习的范式,它要么直接从少数标签学习,要么通过元学习模拟少样本学习范式[15,47,57]。一类有趣的半监督方法[17,22,26,56,58,68]已经出现,其目的是将知识从丰富的基类转移到数据存储的新类,尤其是对于粒度实例级的视觉理解任务。然而,到目前为止,还没有一个单一的、统一的框架可以有效地利用各种形式和数量的训练数据(从零样本到完全监督)。
We make two fundamental observations that motivate our work. First, image-level supervision is abundant, while instance-level structured labels, such as bounding boxes and segmentation masks, are expensive and scarce. This is reflected in the scales of widely used datasets where classification tasks have > 5K classes [28, 52] while the popular object detection/segmentation datasets, like MSCOCO [32], have annotations for only 80 classes. A similar observation was initially made by Hoffman et al. [22] and other semi-supervised [26, 56, 58] approaches. Second, the assumptionof n o instance-level supervision for target classes (as is the case for semi-supervised [22, 26, 56, 58] and zero-shot methods [3, 16, 40, 65]) is artificial. In practice, it is often easy to collect few instance-level annotations and, in general, a good object detection/segmentation model should be robust and work with any amount of available instance-level supervision. Our motivation is to bridge weakly-supervised, zero- and few-shot learning paradigms to build an expressive, simple, and interpretable model that can operate across types (weak/strong) and amounts of instance-level supervision (from 0 to 90+ instance-level samples per class).
我们有两个基本的观察结果来激励我们的工作。首先,图像级别的监控非常丰富,而实例级别的结构化标签,如边界框和分割遮罩,价格昂贵且稀缺。这反映在广泛使用的数据集的规模上,其中分类任务的类别超过5K[28,52],而流行的目标检测/分割数据集,如MSCOCO[32],只有80个类别的注释。霍夫曼等人[22]和其他半监督[26,56,58]方法最初也进行了类似的观察。其次,对目标类不进行实例级监督的假设(如半监督[22,26,56,58]和零样本方法[3,16,40,65])是人为的。在实践中,通常很容易收集很少的实例级注释,一般来说,一个好的目标检测/分割模型应该是健壮的,并且可以与任何数量的可用实例级监控一起工作。我们的动机是在弱监督、零样本和少样本头学习范式之间架起桥梁,以构建一个表达性、简单且可解释的模型,该模型可以跨类型(弱/强)和实例级超视距(每个类从0到90+实例级样本)进行操作。
We develop a unified semi-supervised framework (UniT) for object detection and segmentation that scales with different levels of instance-level supervision (see Figure1). The data used in training our model is categorized in two ways, (1) image-level classification data for all the object classes, and (2) abundant detection data for a set of base object classes and limited (possibly zero) detection data for a set of novel object classes, with the aim to obtain a model that learns to detect both base and novel objects at test time.
我们为目标检测和分割开发了一个统一的半监督框架(UniT),该框架可根据不同级别的实例级监督进行扩展(见图1)。用于训练我们的模型的数据以两种方式分类,(1)所有目标类的图像级分类数据,(2)一组基本目标类的丰富检测数据和一组新目标类的有限(可能为零)检测数据,目的是获得一个模型,该模型在测试时学习检测基本目标和新目标。
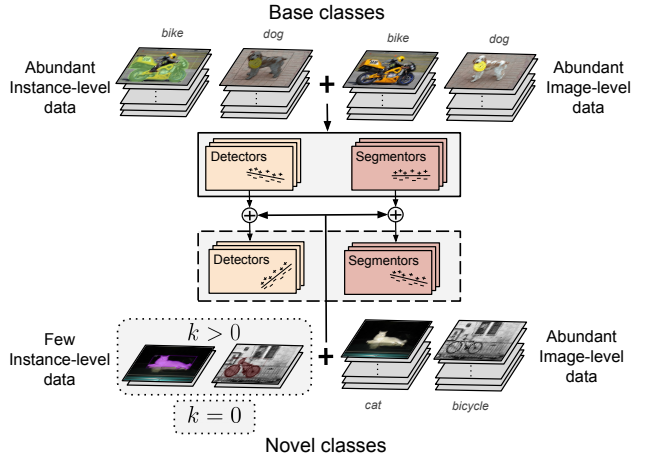
Figure 1: Semi-supervised Any-shot Detection and Segmentation. The data used in our setting is categorized in two ways: (1) image-level classification data for all object classes, and (2) abundant instance data for base object classes and limited (possibly zero) instance data for novel object classes, with the aim to obtain a model that learns to detect/segment both base and novel objects at test time.
图1:any-shot样本半监督检测和分割。我们设置中使用的数据以两种方式分类:(1)所有目标类的图像级分类数据,(2)基本目标类的丰富实例数据和新目标类的有限(可能为零)实例数据,目的是获得一个模型,该模型能够在测试时学习检测/分割基本目标和新目标。
Our algorithm, illustrated in Figure 2, jointly learns weak-detectors for all the object classes, from image-level classification data, and supervised regressors/segmentors on top of those for base classes (based on instance-level annotations in a supervised manner). The classifiers, regressors and segmentors of the novel classes are expressed as aweighted linear combination of its base class counterparts. The weights of the combination are determined by a multimodal similarity measure: lingual and visual. The key insight of our approach is to utilize the multi-modal similarity measure between the novel and base classes to enable effective knowledge transfer and adaptation. The adopted novel classifier/regressors/segmentors can further be refined basedon instance-level s upervision, if any available. We experiment with the widely-used detection/segmentation datasets - Pascal VOC [13] and MSCOCO [32], and compare our method with state-of-the-art few-shot, weakly-supervised,and semi-supervised object detection/segmentation methods.
如图2所示,我们的算法从图像级分类数据中联合学习所有目标类的弱检测器,并在基类的弱检测器之上学习有监督的回归器/分段器(以有监督的方式基于实例级注释)。新类的分类器、回归器和分段器被表示为其基类对应项的加权线性组合。组合的权重由多模态相似性度量确定:语言和视觉。我们的方法的关键是利用新类和基类之间的多模态相似性度量来实现有效的知识转移和适应。所采用的新型分类器/回归器/分段器可以在实例级监督的基础上进一步细化(如果有的话)。我们对广泛使用的检测/分割数据集——Pascal VOC[13]和MSCOCO[32]进行了实验,并将我们的方法与最先进的少样本、弱监督和半监督目标检测/分割方法进行了比较。
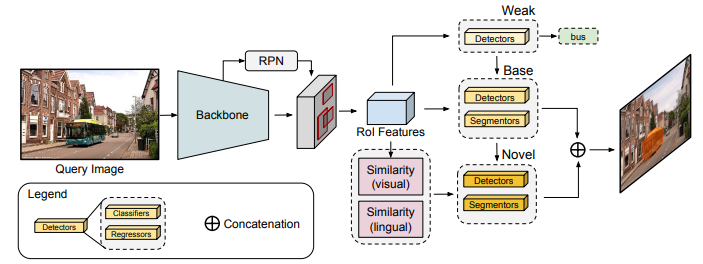
Figure 2: Overall Architecture. We form detectors/segmentors for base classes as a refinement on top of weak detectors. The detectors/segmentors for novel classes utilize a similarity weighed transfer (pink boxes) from the base class refinements.In a k-shot setting, (few) novel class instance annotations are incorporated through direct adaptation of the resulting novel detectors/segmentors through fine-tuning. All detectors are built on top of Faster/Mask RCNN architecture which comprises of classification and regression heads with shared backbone (in cyan) and simultaneously trained region proposal network (RPN).
图2:总体架构。我们为基类构造检测器/分段器,作为弱检测器之上的一种改进。新类的检测器/分割器利用基类细化的相似性加权转移(粉色框)。在k-shot设置中,通过微调直接调整生成的新检测器/分割器,可以合并(很少)新的类实例注释。所有检测器都构建在Faster/Mask RCNN架构之上,该架构由具有共享主干(青色)的分类和回归头以及同时训练的区域建议网络(RPN)组成。
Contributions: Our contributions can be summarized as follows: (1) We study the problem of semi-supervised object detection and segmentation in light of image-level supervision and limited instance-level annotations, ranging from no data (zero-shot) to a few (few-shot); (2) We propose a general, unified, interpretable, and flexible end-to-end framework that, by leveraging a learned multi-modal (lingual + visual) similarity metric, can adopt classifiers/detectors/segmentors for novel classes by expressing them as linear combinations of their base class counterparts. (3) In the context of our model, we contrast the relative importance of weak image-level supervision with strong instance-level supervision, and highlight the importance of the former under a small fixed annotation budget (4) We illustrate the flexibility and effectiveness of our model by applying it to a variety of tasks (object detection and segmentation) and datasets (Pascal VOC [13], MSCOCO [32]); showing state-of-the-art performance. We get up to 23% relative improvement in mAP over the closest semi-supervised methods [17], and up to 16% gain over the best performing few-shot method [62] under a fixed annotation budget. We conduct comprehensive comparisons across settings, tasks, types and levels of supervision.
贡献:我们的贡献可以概括为以下几点:(1)我们研究了基于图像级监控和有限实例级注释的半监督目标检测和分割问题,范围从无数据(零样本)到少量(少量样本);(2) 我们提出了一个通用的、统一的、可解释的、灵活的端到端框架,通过利用学习到的多模态(语言+视觉)相似性度量,可以通过将新类表示为其基类对应项的线性组合来采用新类的分类器/检测器/分段器。(3) 在我们的模型中,我们对比了弱图像级监控与强实例级监控的相对重要性,并强调了前者在较小的固定注释预算下的重要性(4)我们通过将其应用于各种任务(目标检测和分割)和数据集(Pascal VOC[13],MSCOCO[32]),说明了我们模型的灵活性和有效性;展示最先进的表现。在固定的注释预算下,与最接近的半监督方法[17]相比,我们的mAP相对提高了23%,与性能最好的少样本方法[62]相比提高了16%。我们对监督的设置、任务、类型和级别进行全面比较。
2 相关工作
Few-shot object detection: Object detection with limited data was initially explored in a transfer learning setting by Chen et al. [7]. In the context of meta-learning[1, 15, 41, 49, 60], Kang et al. [24] developed a few-shot model where the learning procedure is divided into two phases: first the model is trained on a set of base classes with abundant data using episodic tasks, then, in the second phase, a few examples of novel classes and base classes are used for fine tuning the model. Following this formulation, [63, 67] employed better performing architecture - Faster R-CNN [43], instead of a one-stage YOLOv2 [42]. Yan et al. [67] extended the problem formulation to account for segmentation in addition to detection. In contrast to the above approaches, Wang et al. [62] showed that meta-learning is not a crucial ingredient to Few-shot object detection, and simple fine-tuning produces better detectors. Similar to the above works, we also adopt the two-phase learning procedure. However, we fundamentally differ in assuming that easily attainable extra supervision, in the form of image-level data, over all the classes is available. Unlike [63], we learn a semantic mapping between weakly-supervised detectors and detectors obtained using a large number of examples.
少样本目标检测:Chen等人最初在迁移学习环境中探索了有限数据的物体检测[7]。在元学习[1,15,41,49,60]的背景下,Kang等人[24]开发了一个多样本模型,其中学习过程分为两个阶段:首先使用情景任务在一组具有丰富数据的基类上训练模型,然后在第二阶段,使用一些新类和基类的示例来微调模型。按照这个公式,[63,67]采用了性能更好的架构——Faster R-CNN[43],而不是单级YOLOv2[42]。Yan等人[67]将问题公式扩展到除检测之外的分割。与上述方法相比,Wang等人[62]表明,元学习并不是少样本目标检测的关键因素,简单的微调可以产生更好的检测器。与上述工作类似,我们也采用了两阶段学习过程。然而,我们的基本不同之处在于,我们假设所有类别都可以以图像级数据的形式轻松实现额外监管。与[63]不同,我们学习了弱监督检测器和使用大量示例获得的检测器之间的语义映射。
Weakly-supervised object detection: Weak supervision in object detection takes the form of image-level labels, usually coupled with bounding box proposals [59, 73], thereby representing each image as a bag of instances[2, 5, 9, 12, 18, 34, 44, 50, 54, 55, 61, 70]. Bilen et al. [5] proposed an end-to-end architecture which softly labeled object proposals and uses a detection stream, in addition to classification stream, to classify them. Further extensions followed, Diba et al. [12] incorporated better proposals into a cascaded deep network; Tang et al. [55] proposed an Online Instance Classifier Refinement (OICR) algorithm which iteratively refines predictions. More recently, further improvements were made by combining weakly-supervised learning with strongly-supervised detectors, by treating predicted locations from the weakly-supervised detector as pseudo-labels for a strongly-supervised variant [2, 61]. In this work, we choose to adopt and build on top of single-stage OICR [55], hence enabling end-to-end training. However, our approach is not limited to the choice of weakly-supervised architecture.
弱监督目标检测:目标检测中的弱监督采用图像级标签的形式,通常与边界框方案结合[59,73],从而将每个图像表示为一组实例[2,5,9,12,18,34,44,50,54,55,61,70]。Bilen等人[5]提出了一种端到端架构,该架构对目标建议框进行软标记,并在分类流之外使用检测流对其进行分类。随后,Diba等人[12]将更好的方案整合到级联深度网络中;Tang等人[55]提出了一种在线实例分类器细化(OICR)算法,该算法迭代地细化预测。最近,通过将弱监督学习与强监督检测器相结合,通过将弱监督检测器的预测位置作为强监督变量的伪标签来处理,取得了进一步的改进[2,61]。在这项工作中,我们选择采用并建立在单阶段OICR基础上[55],从而实现端到端训练。然而,我们的方法并不局限于弱监督体系结构的选择。
Semi-supervised object detection: Approaches under semi-supervised setup assume abundant detection data for base classes and no detection data for novel classes, in addition to weak supervision for all the classes. The methods in this category first learn weak classifiers for all classes using abundant weak supervision, then fine-tune base classifiers into detectors using abundant detection data, and finally transfer this transformation to obtain detectors for novel classes using an external (or learned) similarity measure between base and novel classes. LSDA [22], being the first, formed similarity based on L2-normalized weak classifier weights. Tang et al. [56] extended this approach to include semantic and visual similarity explicitly. DOCK [26] expanded the types of similarities to include spatial and attribute cues using external knowledge sources. Other works leverage semantic hierarchies of classes, such as Yang et al. [68] proposes a class split based on granularity of classes, and transfers knowledge from coarse to fine grained classes. Uijlings et al. [58] uses a proposal generator trained on base classes, and transfers the proposals from base to novelclasses by computing their similarity on a tree based on Imagenet semantic hierarchy [45]. Similar to the above methods we also use visual and lingual similarities between base and novel classes, but consider a more general problem setting where we have varying degrees of detection supervision for novel classes ranging from zero to a few k-samples per class.
半监督目标检测:半监督设置下的方法假设基类有丰富的检测数据,而新类没有检测数据,此外所有类的监督都很弱。这类方法首先使用丰富的弱监督学习所有类的弱分类器,然后使用丰富的检测数据将基本分类器微调为检测器,最后使用基本类和新类之间的外部(或学习的)相似性度量将此转换转换为新类的检测器。LSDA[22]是第一个基于L2规范化弱分类器权重形成相似度的算法。Tang等人[56]扩展了这种方法,明确地将语义和视觉相似性包括在内。DOCK[26]扩展了相似性的类型,包括使用外部知识源的空间和属性线索。其他工作利用了类的语义层次结构,如Yang等人[68]提出了基于类粒度的类划分,并将知识从粗粒度的类转移到细粒度的类。Uijlings等人[58]使用一个在基类上训练过的建议生成器,通过计算基于Imagenet语义层次结构的树上的相似性,将建议从基类转移到NovelClass[45]。与上述方法类似,我们也使用基本类和新类之间的视觉和语言相似性,但考虑一个更一般的问题设置,我们对新类有不同程度的检测监督,范围从0到每个类的几个k样本。
Unique, and closest to our setup, is NOTE-RCNN [17]. In [17], few-k detection samples for novel classes are used as seed annotations, based on which training-mining [55, 58] is employed. Specifically, they initialize detectors for novel classes by training them with few seed annotations, and iteratively refine them by retraining with mined bounding boxes for novel classes. They transfer knowledge indirectly in the form of losses that act as regularizers. Our approach, on the other hand, takes on a simpler and more intuitive direction where we first transfer the mappings from base to novel classes, and use few seed annotations (if available) to fine-tune the detectors. Despite being simpler, our approach is more accurate, and works in the k = 0 regime. Further, unlike all the above semi-supervised approaches , we transfer across tasks, including regression and segmentation.
唯一且最接近我们设置的是NOTE-RCNN[17]。在[17]中,新类的少量k检测样本被用作seed标注,在此基础上使用了训练挖掘[55,58]。具体来说,它们通过使用少量seed注释对新类的检测器进行训练来初始化检测器,并通过使用新类的挖掘边界框进行重新训练来迭代地细化检测器。它们以损失的形式间接地传递知识,这些损失起到了调节作用。另一方面,我们的方法采用了更简单、更直观的方向,首先将映射从基类转移到新类,并使用少量seed注释(如果可用)来微调检测器。尽管更简单,但我们的方法更准确,并且在k=0的情况下有效。此外,与上述所有半监督方法不同,我们在任务之间进行转移,包括回归和分割。
Zero-shot object detection: Zero-shot approaches rely on auxiliary semantic information to connect base and novel classes; e.g., text description of object labels or their attributes [3, 16, 40, 65]. A common strategy is to represent all classes as prototypes in the semantic embedding space and to learn a mapping from visual features to this embedding space using base class data; classification is then obtained using nearest distance to novel prototypes. This approach was expended to detection in [10, 27, 30, 46, 69, 72]. Bansal et al. [3], similarly, proposed method to deal with situations where objects from novel/unseen classes are present in the background regions. We too explore the setting where we are not provided with any instance data for novel classes, but in addition assume weak-supervision for novel object classes in the form of readily available [28] image-level annotations.
零样本目标检测:零样本方法依靠辅助语义信息连接基本类和新类;例如,目标标签或其属性的文本描述[3,16,40,65]。一种常见的策略是在语义嵌入空间中将所有类表示为原型,并使用基类数据学习从视觉特征到该嵌入空间的映射;然后使用与新原型的最近距离进行分类。这种方法被扩展到[10,27,30,46,69,72]中的检测。Bansal等人[3]也提出了类似的方法来处理背景区域中存在来自新类/未知类的目标的情况。我们也探索了这样一种环境,即我们没有为新类提供任何实例数据,但另外还假设以现成的[28]图像级注释的形式对新目标类的监督很弱。
3 问题表述
Here we formally introduce the semi-supervised any-shot object detection / segmentation setup. We start by assuming image-level supervision for all the classes denoted by ![]() , where each image xi is annotated with a label
, where each image xi is annotated with a label ![]() , where
, where ![]() if image xi contains at least one j-th object, indicating its presence;
if image xi contains at least one j-th object, indicating its presence; ![]() |being number of object classes.
|being number of object classes.
在这里,我们正式介绍了半监督的任意样本目标检测/分割设置。首先,我们假设对由![]() 表示的所有类进行图像级监控,其中每个图像xi都用标签
表示的所有类进行图像级监控,其中每个图像xi都用标签![]() 注释,如果图像xi包含至少一个第j个目标,则
注释,如果图像xi包含至少一个第j个目标,则![]() ,表示其存在;
,表示其存在;![]() 是目标类的数量。
是目标类的数量。
We further extend the above image-level data with objectinstance annotations by following the few-shot object detection formulation [24, 63, 67]. We split the classes into two disjoint sets: base classes Cbase and novel classes Cnovel; ![]() ;. For base classes, we have abundant instance data Dbase = {(xi, ci, yi)}, where xi is an input image,
;. For base classes, we have abundant instance data Dbase = {(xi, ci, yi)}, where xi is an input image, ![]() are class labels,
are class labels, ![]() or
or ![]() are corresponding bounding boxes and/or masks for each instance j in image i. For novel classes, we have limited instance data
are corresponding bounding boxes and/or masks for each instance j in image i. For novel classes, we have limited instance data ![]() , where data for k-shot detection / segmentation only has k bounding boxes / masks for each novel class in Cnovel. Note, these annotations are assumed only for images in the train data. Also, for semi-supervised zero-shot, k = 0 and Dnovel =
, where data for k-shot detection / segmentation only has k bounding boxes / masks for each novel class in Cnovel. Note, these annotations are assumed only for images in the train data. Also, for semi-supervised zero-shot, k = 0 and Dnovel =![]() ;.
;.
通过遵循少样本目标检测公式[24,63,67],我们进一步扩展了具有目标实例注释的上述图像级数据。我们将这些类划分为两个不相交的集合:基类Cbase和新类Cnovel;![]() 。对于基类,我们有丰富的实例数据Dbase={(xi,ci,yi)},其中xi是一个输入图像,
。对于基类,我们有丰富的实例数据Dbase={(xi,ci,yi)},其中xi是一个输入图像,![]() 是类标签,
是类标签,![]() 或
或![]() 是图像i中每个实例j的相应边界框和/或掩码。对于新类,我们有有限的实例数据
是图像i中每个实例j的相应边界框和/或掩码。对于新类,我们有有限的实例数据![]() 、 其中,对于Cnovel中的每个新类,k-shot检测/分割的数据只有k个边界框/掩码。注意,这些注释仅适用于列车数据中的图像。同样,对于半监督零样本,k=0,Dnovel=
、 其中,对于Cnovel中的每个新类,k-shot检测/分割的数据只有k个边界框/掩码。注意,这些注释仅适用于列车数据中的图像。同样,对于半监督零样本,k=0,Dnovel=![]() 。
。
4 方法
We propose a single unified framework that leverages the weak image-level supervision for object detection / segmentation in any-shot setting. That is, our proposed approach can seamlessly incorporate arbitrary levels of instance-level supervision without the need to alter the architecture.
我们提出了一个单一的统一框架,该框架利用弱图像级监控,在任何样本设置下进行目标检测/分割。也就是说,我们提出的方法可以无缝地结合任意级别的实例级监控,而无需改变体系结构。
Our proposed framework builds upon the Faster R-CNN [43] / Mask R-CNN [20] architecture. Faster R-CNN [43] utilizes a two-stage pipeline in order to perform object detection. The first stage uses a region proposal network (RPN) to generate class-agnostic object region proposals ![]() for image i. The second stage is a detection network (Fast R-CNN [19]) that performs RoI pooling, forming feature vector
for image i. The second stage is a detection network (Fast R-CNN [19]) that performs RoI pooling, forming feature vector![]() for proposal j in image i, and learns to classify this RoI feature vector z (we drop proposal and image indexing for brevity for remainder of the section) into one of the object classes and refine the bounding box proposals using a class-aware regressors. Conceptually, an R-CNN object detector can be thought of as a combination of a classifier and regressor (see Figure 2). Mask R-CNN [20] is a simple extension to the Faster R-CNN framework, wherein an additional head is utilized in the second stage to predict the instance segmentation masks.
for proposal j in image i, and learns to classify this RoI feature vector z (we drop proposal and image indexing for brevity for remainder of the section) into one of the object classes and refine the bounding box proposals using a class-aware regressors. Conceptually, an R-CNN object detector can be thought of as a combination of a classifier and regressor (see Figure 2). Mask R-CNN [20] is a simple extension to the Faster R-CNN framework, wherein an additional head is utilized in the second stage to predict the instance segmentation masks.
我们提出的框架基于Faster R-CNN[43]/Mask R-CNN[20]架构。Faster R-CNN[43]利用两步来执行目标检测。第一阶段使用区域建议网络(RPN)为图像i生成类无关目标区域建议![]() 。第二阶段是检测网络(Fast R-CNN[19]),该网络执行RoI池,形成图像i中建议j的特征向量
。第二阶段是检测网络(Fast R-CNN[19]),该网络执行RoI池,形成图像i中建议j的特征向量![]() ,并学习将该RoI特征向量z(为了简洁起见,我们在本节剩余部分中删除了建议框和图像索引)分类为一个目标类,并使用类感知回归器优化边界框提案。从概念上讲,R-CNN目标检测器可以被认为是分类器和回归器的组合(见图2)。Mask R-CNN[20]是对Faster R-CNN框架的简单扩展,其中在第二阶段使用额外的头部来预测实例分割掩码。
,并学习将该RoI特征向量z(为了简洁起见,我们在本节剩余部分中删除了建议框和图像索引)分类为一个目标类,并使用类感知回归器优化边界框提案。从概念上讲,R-CNN目标检测器可以被认为是分类器和回归器的组合(见图2)。Mask R-CNN[20]是对Faster R-CNN框架的简单扩展,其中在第二阶段使用额外的头部来预测实例分割掩码。
Figure 2 details the proposed architecture. The model consists of two branches: i) the weakly-supervised branch that trains detectors ![]() using image-level supervision Dclass, and ii) a supervised branch that uses detection data Dbase/Dnovel to learn a refinement mapping from the weak detector to category-aware classifiers, regressors, and segmentors
using image-level supervision Dclass, and ii) a supervised branch that uses detection data Dbase/Dnovel to learn a refinement mapping from the weak detector to category-aware classifiers, regressors, and segmentors ![]() , which are used in the second stage of Faster / Mask R-CNN. Note that weak detectors simply output the proposal box of the pooled feature vector as the final location
, which are used in the second stage of Faster / Mask R-CNN. Note that weak detectors simply output the proposal box of the pooled feature vector as the final location![]() ; while refined detectors are able to regress a better box. Here fW(·) is a learned neural network function parametrized by W. We jointly train both branches and the RPN, and learning is divided into two stages: base-training and fine-tuning
; while refined detectors are able to regress a better box. Here fW(·) is a learned neural network function parametrized by W. We jointly train both branches and the RPN, and learning is divided into two stages: base-training and fine-tuning
图2详细描述了提出的体系结构。该模型由两个分支组成:i)使用图像级监控Dclass训练检测器![]() 的弱监督分支,ii)使用检测数据Dbase/Dnovel学习从弱检测器到类别感知分类器、回归器和分段器
的弱监督分支,ii)使用检测数据Dbase/Dnovel学习从弱检测器到类别感知分类器、回归器和分段器![]() 的细化映射的监督分支,用于Faster/Mask R-CNN的第二阶段。注意,弱检测器只是将合并特征向量的建议框作为最终位置
的细化映射的监督分支,用于Faster/Mask R-CNN的第二阶段。注意,弱检测器只是将合并特征向量的建议框作为最终位置![]() 输出;而经过改进的探测器能够回归出更好的边界框。这里fW(·)是一个由W参数化的学习神经网络函数。我们联合训练这两个分支和RPN,学习分为两个阶段:基础训练和微调。
输出;而经过改进的探测器能够回归出更好的边界框。这里fW(·)是一个由W参数化的学习神经网络函数。我们联合训练这两个分支和RPN,学习分为两个阶段:基础训练和微调。
Base-training: During base-training, instances from Dbase are used to obtain a detector / segmentation network for the base classes Cbase. Specifically, for each![]() , category-aware classifiers and regressors for the base classes are formulated as additive refinements to their corresponding weak counterparts. For region classifiers this takes the form of:
, category-aware classifiers and regressors for the base classes are formulated as additive refinements to their corresponding weak counterparts. For region classifiers this takes the form of: ![]() ,where
,where
基础训练:在基础训练期间,使用来自Dbase的实例为基础类Cbase获取检测器/分段网络。具体地说,对于每个![]() ,基类的类别感知分类器和回归器被表示为对其相应的弱对应项的加性细化。对于区域分类器,其形式为:
,基类的类别感知分类器和回归器被表示为对其相应的弱对应项的加性细化。对于区域分类器,其形式为:![]() ,其中
,其中
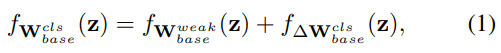
where![]() is a zero-initialized residual to the logits of the weakly supervised detector. The regressed object location is similarly defined as:
is a zero-initialized residual to the logits of the weakly supervised detector. The regressed object location is similarly defined as:
![]() 是弱监督检测器logits的零初始化残差。回归目标位置的定义类似于:
是弱监督检测器logits的零初始化残差。回归目标位置的定义类似于:
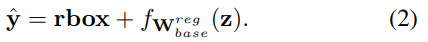
Finally, as there is no estimate for the segmentation masks in the first stage of Mask R-CNN [20], ![]() is aresidual over rbox learned directly from base annotations.
is aresidual over rbox learned directly from base annotations.
最后,由于在mask R-CNN[20]的第一阶段中没有对分割掩码的估计,![]() 是直接从基注释学习的rbox上的个体。
是直接从基注释学习的rbox上的个体。
Novel fine-tuning (k > 0): In the fine-tuning phase, the detectors / segmentors of the base classes are used to transfer information to the classes in Cnovel. The network is also fine-tuned on Dnovel, which, for a value of k, contains k bounding boxes / masks for novel and base classes. Here we consider the case of k > 0; we later address k = 0 case, which does not require fine-tuning. The key insight of our approach is to use additional visual and lingual similarities between the novel and base classes to enable effective transfer of the network onto the novel classes under varying degrees of supervision. Contrary to existing work [22, 56, 26] that only consider information from base category-aware classifiers, our approach additionally learns a mapping from base category-aware regressors and segmentors to obtain more accurate novel counterparts. For a specific proposal rbox with features z, let ![]() denote similarity between base classes and novel classes. The dependenceon z stems from visual component of the similarity and is discussed in Section 4.2. Given this, for each proposal z, the category-aware classifier for the novel classes is obtained as follows:
denote similarity between base classes and novel classes. The dependenceon z stems from visual component of the similarity and is discussed in Section 4.2. Given this, for each proposal z, the category-aware classifier for the novel classes is obtained as follows: ![]() , where
, where ![]() can be written as,
can be written as,
新的微调(k>0):在微调阶段,基类的检测器/分段器用于将信息传输到Cnovel中的类。该网络也在Dnovel上进行了微调,当值为k时,它包含k个用于新类和基类的边界框/掩码。这里我们考虑k>0的情况;我们稍后将讨论k=0的情况,它不需要微调。我们的方法的关键洞察是在新类和基类之间使用额外的视觉和语言相似性,以便在不同程度的监督下将网络有效地转移到新类上。与现有研究[22,56,26]只考虑基本类别感知分类器的信息不同,我们的方法还从基本类别感知回归器和分段器学习映射,以获得更准确的新对应项。对于具有特性z的特定建议框rbox,让![]() 表示基类和新类之间的相似性。依赖项z源于相似性的视觉成分,在第4.2节中讨论。鉴于此,对于每个提议z,新类的类别感知分类器如下所示:
表示基类和新类之间的相似性。依赖项z源于相似性的视觉成分,在第4.2节中讨论。鉴于此,对于每个提议z,新类的类别感知分类器如下所示:![]() 、 其中
、 其中![]() 可以写成:
可以写成:
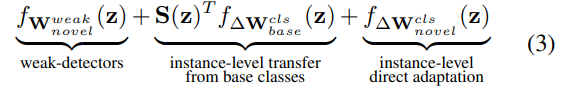
where ![]() which is computed along the columns in S(z), and
which is computed along the columns in S(z), and ![]() denotes broadcast of vector similarity
denotes broadcast of vector similarity ![]() followed by element-wise product with lingual similarity
followed by element-wise product with lingual similarity ![]() . The interpretation of Eq.(3) is actually rather simple – we first refine the weak detectors for novel classes by similarity weighted additive refinements from base classes (e.g.,novel class motorbike may relay on base class bicycle for refinement; illustrations in supp. Sec. H.), denoted by “instance-level transfer from base classes”. We then further directly adapt the resulting detector with few instances of the novel class (last term). Similarly, for each z, the novel class object regressor can be obtained as.
. The interpretation of Eq.(3) is actually rather simple – we first refine the weak detectors for novel classes by similarity weighted additive refinements from base classes (e.g.,novel class motorbike may relay on base class bicycle for refinement; illustrations in supp. Sec. H.), denoted by “instance-level transfer from base classes”. We then further directly adapt the resulting detector with few instances of the novel class (last term). Similarly, for each z, the novel class object regressor can be obtained as.
式中![]() ,沿S(z)中的列计算,
,沿S(z)中的列计算,![]() 表示向量相似性
表示向量相似性![]() 的广播,然后是元素|与语言相似性
的广播,然后是元素|与语言相似性![]() 。公式(3)的解释实际上相当简单——我们首先通过对基类(例如,新类摩托车可能会在基类自行车上进行改进;补充章节H中的插图)的相似加权加法改进,来改进新类的弱检测器,用“从基类的实例级转移”表示。然后,我们进一步直接使用新类(上一部分)的几个实例来调整生成的检测器。类似地,对于每个z,新的类目标回归器可以如下所示:
。公式(3)的解释实际上相当简单——我们首先通过对基类(例如,新类摩托车可能会在基类自行车上进行改进;补充章节H中的插图)的相似加权加法改进,来改进新类的弱检测器,用“从基类的实例级转移”表示。然后,我们进一步直接使用新类(上一部分)的几个实例来调整生成的检测器。类似地,对于每个z,新的类目标回归器可以如下所示:

Finally, the segmentation head ![]() can be obtained as follows (additional details in appendix Section A),
can be obtained as follows (additional details in appendix Section A),
最后,分割头![]() 可如下获得(附录A部分中的附加细节),
可如下获得(附录A部分中的附加细节),
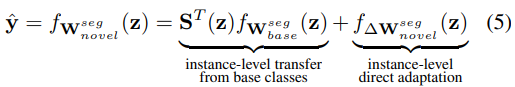
Semi-supervised zero-shot (k = 0): As we mentioned previously, our model is also readily applicable when Cnovel =![]() . This is a special case of the formulation above, where fine-tuning is not necessary or possible, and we only rely on base training and apply novel class evaluation procedure. The predictions for novel classes can be done as in Eq.(3), Eq.(4), and Eq.(5), but omitting the “instance-level direct adaptation” term in all three cases.
. This is a special case of the formulation above, where fine-tuning is not necessary or possible, and we only rely on base training and apply novel class evaluation procedure. The predictions for novel classes can be done as in Eq.(3), Eq.(4), and Eq.(5), but omitting the “instance-level direct adaptation” term in all three cases.
半监督零样本(k=0):正如我们前面提到的,当Cnovel=![]() ,我们的模型也很容易适用。这是上述公式的一个特例,不需要或不可能进行微调,我们只依赖基础训练,并应用新的类别评估程序。对新类的预测可以按照式(3)、式(4)和式(5)进行,但在所有三种情况下都省略了“实例级直接适应”一词。
,我们的模型也很容易适用。这是上述公式的一个特例,不需要或不可能进行微调,我们只依赖基础训练,并应用新的类别评估程序。对新类的预测可以按照式(3)、式(4)和式(5)进行,但在所有三种情况下都省略了“实例级直接适应”一词。
4.1. Weakly-Supervised Detector
As mentioned earlier, our approach leverages detectors trained on image level annotations to learn a mapping to supervised detectors/segmentors. We highlight that our approach is agnostic to the method used to train the weakly-supervised detector, and most of the existing approaches [2, 5, 54, 55] can be integrated into our framework. We, however, use the Online Instance Classifier Refinement (OICR) architecture proposed by Tang et al. [55] due to its simple architecture. OICR has R “refinement” modules![]() that progressively improve the detection quality. These individual “refinement” modules are combined to obtain the final prediction as follows,
that progressively improve the detection quality. These individual “refinement” modules are combined to obtain the final prediction as follows,
如前所述,我们的方法利用在图像级注释上训练的检测器来学习到监督检测器/分段器的映射。我们强调,我们的方法与用于训练弱监督检测器的方法不可知,大多数现有方法[2,5,54,55]都可以集成到我们的框架中。由于其简单的体系结构,我们一直使用Tang等人[55]提出的在线实例分类器优化(OICR)体系结构。OICR具有R“细化”模块![]() ,可逐步提高检测质量。将这些单独的“细化”模块组合起来,以获得如下最终预测:
,可逐步提高检测质量。将这些单独的“细化”模块组合起来,以获得如下最终预测:

We use the same loss formulation![]() described in [55], which compares predicted (aˆ) and ground truth (a) class labels, to train the OICR module (see Sect. 4.3). For additional details, we refer the reader to [55]
described in [55], which compares predicted (aˆ) and ground truth (a) class labels, to train the OICR module (see Sect. 4.3). For additional details, we refer the reader to [55]
我们使用[55]中所述的相同损失公式![]() ,比较预测(aˆ)和基本真相(a)类别标签,以训练OICR模块(见第4.3节)。有关更多详细信息,请参阅[55]
,比较预测(aˆ)和基本真相(a)类别标签,以训练OICR模块(见第4.3节)。有关更多详细信息,请参阅[55]
4.2. Similarity Matrices相似矩阵
As described in Eq.(3), (4), (5), the key contribution of our approach is the ability to semantically decompose the classifiers, detectors and segmentors of novel classes into their base classes’ counterparts. To this end, we define a proposal-aware similarity ![]() , where each element captures the semantic similarity of novel class n to base class b. We assume S(z) can be decomposed into two components: lingual
, where each element captures the semantic similarity of novel class n to base class b. We assume S(z) can be decomposed into two components: lingual ![]() and visual
and visual ![]() similarity.
similarity.
如等式(3)、(4)、(5)所述,我们的方法的关键贡献是能够在语义上将新类的分类器、检测器和分段器分解为它们的基类对应项。为此,我们定义了一个方案感知相似性![]() ,其中每个元素捕捉新类别n与基本类别b的语义相似性。我们假设S(z)可以分解为两个组成部分:语言
,其中每个元素捕捉新类别n与基本类别b的语义相似性。我们假设S(z)可以分解为两个组成部分:语言![]() 和视觉
和视觉![]() 相似性。
相似性。
Lingual Similarity: This term captures linguistic similarity between novel and base class labels. The intuition lies in the observation that semantically similar classes often have correlated occurrences in textual data. For a novel class n and a base class b, ![]() ; gn and gb are 300-dimensiona lGloVe [38] vector embeddings for n and b respectively
; gn and gb are 300-dimensiona lGloVe [38] vector embeddings for n and b respectively
语言相似性:这个术语描述了小说和基类标签之间的语言相似性。直觉在于观察到语义相似的类在文本数据中经常有相关的出现。对于一个新类n和一个基类b,![]() ;gn和gb分别是n和b的300维a lGloVe[38]向量嵌入
;gn和gb分别是n和b的300维a lGloVe[38]向量嵌入
Visual Similarity: Complementary to the lingual component, this proposal-aware similarity models the visual likeness of a proposal z to base class objects. For each z, we use the normalized predictions aˆ of the weak detector fWweak (z) (Eq. (6)) as a proxy for the likelihood of z belonging to a base class b. Specifically, let aˆb be the score corresponding to the base class b. For a novel class n and a base class b, the visual similarity![]() is then defined as,
is then defined as,
视觉相似性:作为对语言部分的补充,该建议感知相似性对建议z与基类目标的视觉相似性进行建模。对于每个z,我们使用弱检测器![]() (等式(6))的归一化预测aˆ作为z属于基类b的可能性的代理。具体地说,让aˆb是对应于基类b的分数。对于新的类n和基类b,视觉相似性
(等式(6))的归一化预测aˆ作为z属于基类b的可能性的代理。具体地说,让aˆb是对应于基类b的分数。对于新的类n和基类b,视觉相似性![]() 定义为,
定义为,

Note, computing this visual similarity does not require learning additional parameters. Rather, it is just a convenient by-product of training our model. As a result, this similarity can be efficiently computed. Our visual similarity formulation,in its essence, is similar to the one used in [56]. However,[56] use image-level scores aggregated over a validation set, lacking ability to adapt to a specific proposal. Additionally, our framework is extremely flexible and can easily utilize any additional information, akin to [26], to obtain a more accurate semantic decomposition S(z). However, as computing these might require additional datasets and pre-trained models, we refrain from incorporating them into our model.
注意,计算这种视觉相似性不需要学习其他参数。相反,这只是方便训练我们模型的一个副产品。因此,可以有效地计算这种相似性。我们的视觉相似性公式本质上与[56]中使用的相似。然而,[56]使用在验证集上聚合的图像级分数,缺乏适应特定提案的能力。此外,我们的框架非常灵活,可以轻松地利用类似于[26]的任何附加信息来获得更准确的语义分解S(z)。然而,由于计算这些数据可能需要额外的数据集和预先训练的模型,我们避免将它们合并到我们的模型中。
4.3. Training
We now describe the optimization objective used to train our proposed approach in an end-to-end fashion. During base training, the objective can be written as,
现在,我们以端到端的方式描述用于训练我们提出的方法的优化目标。在基础训练期间,目标可以写为:
![]()
where Lrcnn is the Faster/Mask R-CNN [20, 43] objective, and Lweak is the OICR [55] objective; α = 1 is the weighting hyperparameter. In fine-tuning, we refine the model only using Lrcnn. Note, our approach affords the flexibility to either use pretrained proposals or jointly train a RPN during the base-training phase using instance-level base class annotations. Fine-tuning only effects last term of Eq.(3), (4), and (5), while everything else is optimized using base training objective. Further details are in suppl. Sec. B.
其中,Lrcnn是Faster/Mask R-CNN[20,43]目标,Lweak是OICR[55]目标;α=1是加权超参数。在微调过程中,我们仅使用Lrcnn来优化模型。注意,我们的方法提供了灵活性,可以使用预先训练的方案,也可以在基础训练阶段使用实例级基类注释联合训练RPN。微调只会影响等式(3)、(4)和(5)的最后一项,而其他一切都会使用基本训练目标进行优化。更多详情请参阅补充资料B部分
5 实验
We evaluate our approach against related methods in the semi-supervised and few-shot domain. Comparison against work in the weakly-supervised literature is provided in supplementary Sec. E. Note, for base classes, across all experiments, the same images are used for both image and instance level annotations. This does not induce any additional cost as instance-level labels implicitly give image-level labels.
我们在半监督和少样本领域对我们的方法与相关方法进行了评估。补充章节E提供了与弱监督文献中工作的比较。注意,对于基类,在所有实验中,相同的图像用于图像和实例级注释。这不会导致任何额外的成本,因为实例级别的标签隐式地给出了图像级别的标签。
5.1. Semi-supervised Object Detection
Datasets. We evaluate the performance of our framework on MSCOCO [32] 2015 and 2017 datasets. Similar to [17, 26], we divide the 80 object categories into 20 base and 60 novel classes, where the base classes are identical to the 20 VOC [14] categories. For our model and the baselines, we assume image-level supervision for all 80 classes, whereas instance-level supervision is only available for 20 base classes. For few-shot experiments (k > 0) we additionally assume k instance-level annotations for the novel classes.
数据集。我们在MSCOCO[32]2015和2017年的数据集上评估了我们框架的性能。与[17,26]类似,我们将80个目标类别分为20个基本类和60个新类,其中基本类与20个VOC[14]类别相同。对于我们的模型和基线,我们假设所有80个类都有映像级别的监控,而实例级别的监控只适用于20个基类。对于少样本实验(k>0),我们还假设新类有k个实例级注释。
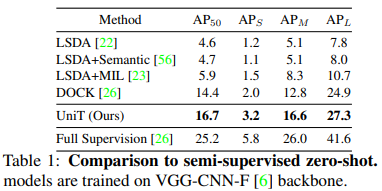
Semi-supervised zero-shot (k = 0). Table 1 compares the performance of our proposed approach against the most relevant semi-supervised zero-shot (k = 0) methods [22, 23,26, 56] on novel classes. As an upper-bound, we also show the performance of a fully-supervised model. To ensure fair comparison, we follow the experimental setting in the strongest baseline DOCK [26], and borrow performance for [22, 23, 56] from their paper. All models are trained using the same backbone: VGG-CNN-F [6] which is pretrained on the ImageNet dataset [11]. Similar to [26], we use the MCG [39] proposals instead of training the RPN. The models are evaluated using mAP at IoU threshold 0.5 denoted as AP50.
半监督零样本(k=0)。表1比较了我们提出的方法与最相关的半监督零样本(k=0)方法[22,23,26,56]在新类上的性能。作为上界,我们还展示了完全监督模型的性能。为了确保公平比较,我们在最强的基线平台[26]中遵循实验设置,并从他们的论文中借用[22,23,56]的性能。所有模型都使用相同的主干网进行训练:VGG-CNN-F[6],该主干网在ImageNet数据集[11]上进行了预训练。与[26]类似,我们使用MCG[39]建议,而不是培训RPN。使用IoU阈值为0.5(表示为AP50)的mAP对模型进行评估。
Semi-supervised few-shot (k > 0). Table 2 compares the performance of our method with NOTE-RCNN [17], which is the only relevant baseline under this setting, on novel classes. We follow the experimental setting described in [17], and our model is trained using the same backbone as NOTE-RCNN: Inception-Resnet-V2 [53] pretrained on the ImageNet classification dataset [11], where the RPN is learned from the instance-level base data. Similar to [17], we assume k instance-level annotations for the novel classes, where k ∈ {12, 33, 55, 76, 96}. To ensure fair comparison, the performance of NOTE-RCNN [17] is taken from their published work . We report mAP on novel classes averaged over IoU thresholds in [0.5:0.05 : 0.95]
半监督少样本(k>0)。表2比较了我们的方法与NOTE-RCNN[17]在新类上的性能,NOTE-RCNN是该设置下唯一相关的基线。我们遵循[17]中描述的实验设置,并使用与NOTE-RCNN相同的主干对我们的模型进行训练:Inception-Resnet-V2[53]在ImageNet分类数据集[11]上预训练,其中RPN从实例级基础数据中学习。与[17]类似,我们假设新类有k个实例级注释,其中k∈{12,33,55,76,96}。为了确保公平比较,NOTE-RCNN[17]的性能取自他们发表的工作。我们在[0.5:0.05:0.95]中报告了平均超过IoU阈值的新类的mAP
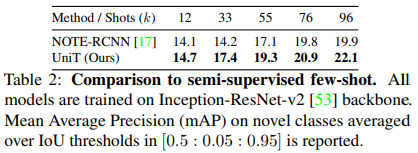
UniT outperforms NOTE-RCNN [17] on all values of k, providing an improvement of up to ~23%. Contrary to NOTE-RCNN that only trains novel regressors on the k shots, UniT benefits from effectively mapping information from base regressors to novel regressors. In addition, UniT also has the advantage of allowing end-to-end training while simultaneously being simple and interpretable. NOTE-RCNN, on the other hand, employs a complex multi-step bounding box mining framework that takes longer to train on novel classes. Note that, in principle, one could incorporate the box mining mechanism into our framework as well.
UniT在k的所有值上都优于NOTE-RCNN[17],提高了约23%。NOTE-RCNN只在k-shot点上训练新的回归器,与此相反,UniT受益于从基础回归器到新回归器的有效映射信息。此外,该UniT还具有允许端到端训练,同时简单易懂的优点。另一方面,NOTE-RCNN采用了一个复杂的多步骤包围盒挖掘框架,在新类上进行训练需要更长时间。请注意,原则上,我们也可以将box挖掘机制合并到我们的框架中。
5.2. Few-shot Object Detection and Segmentation
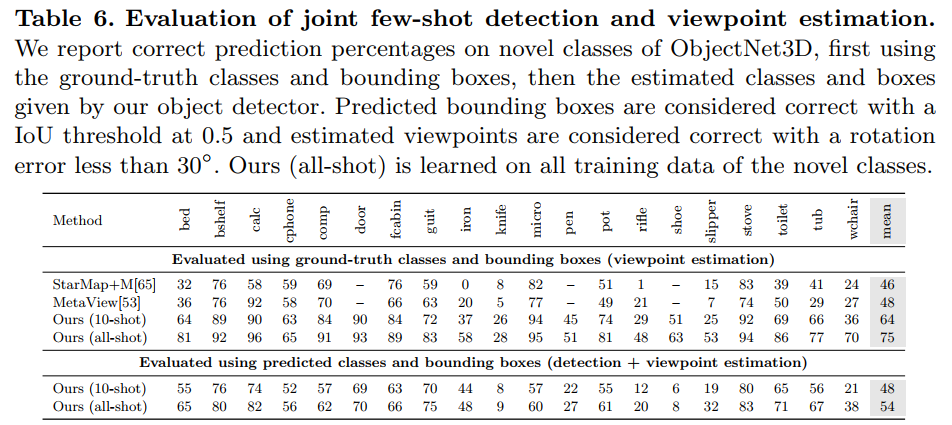
Datasets. We evaluate our models on VOC 2007 [14], VOC 2012 [13], and MSCOCO [32], as used in previous few-shot object detection and segmentation works [24, 62, 63, 67]. For both detection and segmentation, we consistently follow the data splits introduced and used in [24, 67]. In case of VOC, we use VOC 07 test set (5k images) for evaluation and VOC 07+12 trainval sets (16.5k images) for training. The 20 object classes are divided into 3 different class split sets, each with 15 base and 5 novel classes. For novel classes, images provided by Kang et al. [24] are used for k-shot fine-tuning.We report mean Average Precision (mAP) on novel classes and use a standard IoU threshold of 0.5 [14]. For MSCOCO [32], consistent with [24], we use 5k images from the validation set for evaluation and the remaining 115k trainval images for training. We assign 20 object classes from VOC as the novel classes and remaining 60 as the base classes. We report the standard evaluation metric on COCO [43]. In line with the baselines, for both VOC and MSCOCO, the RPN is trained jointly using base class annotations.
数据集。我们在VOC 2007[14]、VOC 2012[13]和MSCOCO[32]上评估了我们的模型,正如之前事业部目标检测和分割工作[24、62、63、67]中使用的那样。对于检测和分割,我们始终遵循[24,67]中介绍和使用的数据分割。对于VOC,我们使用VOC 07测试集(5k图像)进行评估,使用VOC 07+12训练集(16.5k图像)进行训练。20个目标类被分为3个不同的类拆分集,每个类有15个基本类和5个新类。对于新类,Kang等人[24]提供的图像用于k-shot微调。我们报告了新类别的平均精度(mAP),并使用标准IoU阈值0.5[14]。对于MSCOCO[32],与[24]一致,我们使用来自验证集的5k图像进行评估,并使用剩余的115k 训练图像进行训练。我们从VOC中指定20个目标类作为新类,剩余60个作为基类。我们报告了COCO的标准评估指标[43]。根据基线,对于VOC和MSCOCO,使用基类注释联合训练RPN。
PASCAL VOC Detection. Table 3 summarizes the results on VOC for three different novel class splits with different k-shot settings. Following [62, 67], UniT assumes Faster R-CNN [43] with an ImageNet [45] pretrained ResNet-101[21] backbone. UniT outperforms the related state-of-the-art methods on all values of k, including the scenario with no novel class instance-level supervision (k = 0), showing the effectiveness of transfer from base to novel classes. As UniT uses additional weak image-level data for novel classes, this is not an equivalent comparison (see Sec. 5.3 for comparisons under similar annotation budget). However, we highlight that such data is readily available, cheaper to obtain [4], and provides significant performance improvements.
PASCAL VOC 检测。表3总结了三种具有不同 k-shot设置的新类拆分的VOC结果。在[62,67]之后,该UniT采用了Faster R-CNN[43],带有ImageNet[45]预训练的ResNet-101[21]主干网。UniT在k的所有值上都优于相关的最新方法,包括没有新类实例级监控(k=0)的场景,显示了从基类到新类的转换的有效性。由于该UniT对新类别使用了额外的弱图像级数据,因此这不是等效的比较(类似注释预算下的比较见第5.3节)。然而,我们强调,此类数据随时可用,获取成本更低[4],并提供了显著的性能改进。

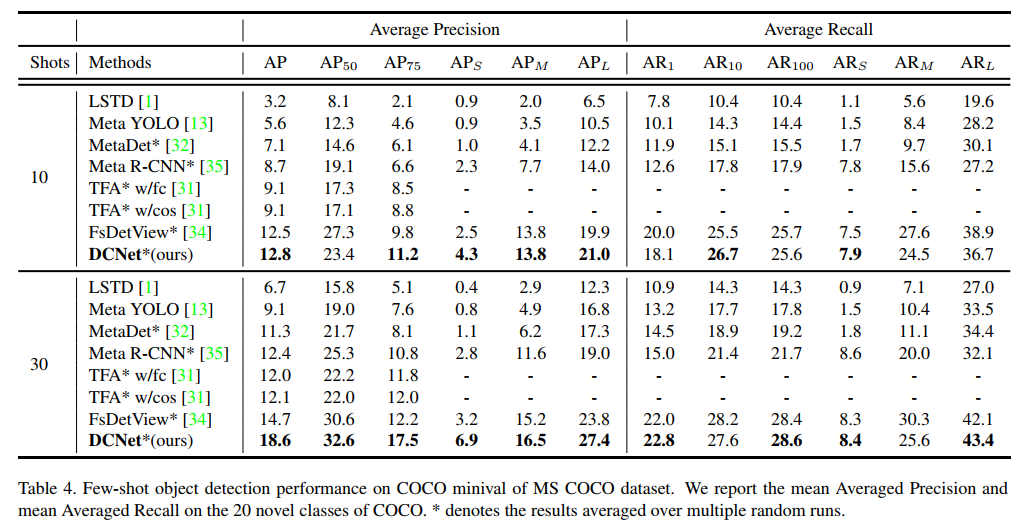
MS-COCO Detection. Table 4 describes the results on COCO dataset. Similar to [67, 62], we use ImageNet [11] pretrained ResNet-50 [21] as the backbone. We observe similar trends as above. In addition, our performance consistently increases with the value of k even on larger datasets, showing that UniT is effective and can easily scale to different amounts of instance-level supervision. The full table is in suppl. Sec. C. Figure 3 shows qualitative results, indicating our method is able to correctly detect novel classes.
MS-COCO检测。表4描述了COCO数据集的结果。与[67,62]类似,我们使用ImageNet[11]预训练的ResNet-50[21]作为主干。我们观察到与上述类似的趋势。此外,即使在更大的数据集上,我们的性能也会随着k值的增加而不断提高,这表明UniT是有效的,并且可以轻松地扩展到不同数量的实例级监控。Sec. C图3显示了定性结果,表明我们的方法能够正确检测新类。

Figure 3: Qualitative Visualizations. Semi-supervised zero-shot (k = 0) detection (top) and instance segmentation (bottom) performance on novel classes in MS-COCO (color = category). See suppl. Section J for more examples.
图3:定性可视化。MS-COCO(颜色=类别)中新类的半监督零样本(k=0)检测(顶部)和实例分割(底部)性能。更多示例请参见补充J节。
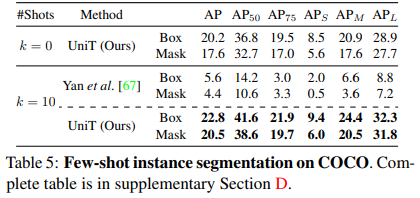
MS-COCO Segmentation. Table 5 summarizes the results. Similar to [67], we choose an ImageNet[11] pretrained ResNet-50 [21] backbone. UniT consistently improves over[67], demonstrating that our approach is not limited to bounding boxes, and is able to generalize over the type of downstream structured label by effectively transferring information from base segmentations to novel segmentations. The full table is provided in supplementary Section D. Figure 3 shows some qualitative results on k = 0 for novel classes.
MS-COCO细分。表5总结了结果。与[67]类似,我们选择了ImageNet[11]预训练的ResNet-50[21]主干网。UniT在[67]上不断改进,表明我们的方法不仅限于边界框,而且能够通过有效地将信息从基本分段转移到新分段,从而概括下游结构化标签的类型。补充部分D中提供了完整的表格。图3显示了新类k=0的一些定性结果。
Ablation. A complete ablation study on MSCOCO [32] is provided in supplementary Section G. We report performance on the novel split used by [67], starting with only weak detectors and progressively adding the terms in Eq.(1), (3), (4), and (5). Weighting with visual and lingual similarity results in +1.4 AP50 improvement (Eq. (3)), transfer from base regressors (Eq. (4)) provides an additional +7 AP50 imrovement. Finally, transfer from base class segmentations (Eq. (5)) leads to an added gain of +7.5 on mask AP50.
消融。补充章节G中提供了MSCOCO[32]的完整消融研究。我们报告了[67]使用的新型分裂的性能,从弱探测器开始,逐步增加等式(1)、(3)、(4)和(5)中的术语。视觉和语言相似性加权导致+1.4 AP50改善(等式(3)),从基础回归(等式(4))转移提供额外+7 AP50改善。最后,从基类分段(等式(5))的转移导致在掩模AP50上增加+7.5的增益。
5.3. Limited Annotation Budget
Compared to approaches in the few-shot detection (and segmentation) domain like [24, 62, 63, 67], UniT assumes additional image-level annotations for novel classes. We argue this is a reasonable assumption considering that such annotations are readily available in abundance for thousands of object classes (⇠22K in ImageNet [11] and ⇠20K in Open Image v4 dataset [28]). Experiments in Section 5.2 further highlight the performance improvements possible by using such inexpensive data. However, this raises an interesting question as to what form of supervision is more valuable, if one is to collect it. To experiment with this, we conceptually impose an annotation budget that limits the number of novel class image-level annotations our approach can use. For object detection on VOC [13], we assume 7 image-level annotations can be generated in the same timeas 1 instance-level annotation. This conversion factor of 7 is motivated by the timings reported in [4] and is a conservative estimate (details in suppl. Sec. F). For each value of k in a few-shot setup, we train a variant of UniT, referred to as UniTbudget=k, that only assumes 7 * k image-level annotations for novel classes. We then compare the zero-shot performance of UniTbudget=k against the corresponding k-shot object detection benchmarks reported in [62]. Note, UniTbudget=k assumes abundant image-level annotations for base classes. However, as the same images are used for both instance and image level annotations, this does not impose any additional annotation cost when compared to baselines. This setting enables apples-to-apples comparisons with the baselines, while simultaneously contrasting the relative importance of image-level and instance-level annotations.
与[24,62,63,67]等少样本检测(和分割)领域中的方法相比,UniT为新类提供了额外的图像级注释。我们认为这是一个合理的假设,考虑到这样的注释在数千个目标类中都很容易获得(ImageNet[11]中的22K和开放式图像v4数据集中的20K[28])。第5.2节中的实验进一步强调了使用这些廉价数据可能带来的性能改进。然而,这就提出了一个有趣的问题:如果要收集信息,哪种形式的监督更有价值。为了进行实验,我们在概念上施加了一个注释预算,以限制我们的方法可以使用的新颖类图像级注释的数量。对于VOC[13]上的目标检测,我们假设7个图像级注释可以与1个实例级注释同时生成。7的换算系数是由[4]中报告的时间决定的,是一个保守估计值(详情见附录F)。对于少样本设置中的每个k值,我们训练一个单位变量,称为![]() ,它只假设7*k新类的图像级注释。然后,我们将
,它只假设7*k新类的图像级注释。然后,我们将![]() 的零拍性能与[62]中报告的相应k拍目标检测基准进行比较。注意,
的零拍性能与[62]中报告的相应k拍目标检测基准进行比较。注意,![]() 假设基类有大量的图像级注释。然而,由于相同的图像同时用于实例级和图像级注释,与基线相比,这不会带来任何额外的注释成本。此设置允许与基线进行苹果对苹果的比较,同时对比图像级和实例级注释的相对重要性。
假设基类有大量的图像级注释。然而,由于相同的图像同时用于实例级和图像级注释,与基线相比,这不会带来任何额外的注释成本。此设置允许与基线进行苹果对苹果的比较,同时对比图像级和实例级注释的相对重要性。
Please refer to Section 5.2 for details on the dataset and setup. Table 6 summarizes the results on VOC for three novel class splits assuming different k-shot settings. Following [62], all models use ResNet-101 [21] as the backbone. For each split and k-shot, 10 repeated runs of ![]() are averaged, each trained by selecting a different set of 7*k weakly-labelled novel class images. For a fixed budget, equivalent to 10 instance-level annotations, we further analyze the relative importance of the two types of annotations by varying the proportions of image and instance-level annotations used. This is summarized in Table 7 for the first novel split. Even under equal budget constraints,
are averaged, each trained by selecting a different set of 7*k weakly-labelled novel class images. For a fixed budget, equivalent to 10 instance-level annotations, we further analyze the relative importance of the two types of annotations by varying the proportions of image and instance-level annotations used. This is summarized in Table 7 for the first novel split. Even under equal budget constraints, ![]() outperforms the state-of-the-art [62] on multiple splits. This highlights three key observations: i) image-level supervision,which is cheaper to obtain [4], provides a greater ‘bang-for-the-buck’ compared to instance-level supervision, ii) our structured transfer from base classes is effective even under limited novel class supervision, and iii) from Table 7, in a low-shot and fixed budget setting, it is more beneficial to just use weak supervision, instead of some combination of both. Furthermore, as our approach is agnostic to the type of weak detector used, employing better weak detectors like [54, 2] could further improve the performance of
outperforms the state-of-the-art [62] on multiple splits. This highlights three key observations: i) image-level supervision,which is cheaper to obtain [4], provides a greater ‘bang-for-the-buck’ compared to instance-level supervision, ii) our structured transfer from base classes is effective even under limited novel class supervision, and iii) from Table 7, in a low-shot and fixed budget setting, it is more beneficial to just use weak supervision, instead of some combination of both. Furthermore, as our approach is agnostic to the type of weak detector used, employing better weak detectors like [54, 2] could further improve the performance of ![]() .
.
有关数据集和设置的详细信息,请参阅第5.2节。表6总结了假设不同k-shot设置的三个新类拆分的VOC结果。[62]之后,所有型号都使用ResNet-101[21]作为主干。对于每个分割和k-shot,平均10次重复运行![]() ,每次通过选择一组不同的7*k弱标记新类图像进行训练。对于固定预算,相当于10个实例级注释,我们通过改变使用的图像和实例级注释的比例,进一步分析了这两种注释的相对重要性。表7总结了第一个新的拆分。即使在相同的预算约束下,
,每次通过选择一组不同的7*k弱标记新类图像进行训练。对于固定预算,相当于10个实例级注释,我们通过改变使用的图像和实例级注释的比例,进一步分析了这两种注释的相对重要性。表7总结了第一个新的拆分。即使在相同的预算约束下,![]() 在多次拆分方面也优于最先进的[62]。这突出了三个关键观察结果:i)与实例级监控相比,图像级监控更便宜[4],提供了更大的“成本效益”,ii)我们从基类的结构化转移即使在有限的新类监控下也是有效的,以及iii)从表7中可以看出,在低成本和固定预算设置下,仅使用弱监控更有利,而不是两者的结合。此外,由于我们的方法不知道所使用的弱检测器的类型,因此使用更好的弱检测器(如[54,2])可以进一步提高
在多次拆分方面也优于最先进的[62]。这突出了三个关键观察结果:i)与实例级监控相比,图像级监控更便宜[4],提供了更大的“成本效益”,ii)我们从基类的结构化转移即使在有限的新类监控下也是有效的,以及iii)从表7中可以看出,在低成本和固定预算设置下,仅使用弱监控更有利,而不是两者的结合。此外,由于我们的方法不知道所使用的弱检测器的类型,因此使用更好的弱检测器(如[54,2])可以进一步提高![]() 的性能。
的性能。

6 讨论与总结
We propose an intuitive semi-supervised model that is applicable to a wide range of supervision: from zero to a few instance-level samples per novel class. For base classes, our model learns a mapping from weakly-supervised to fully-supervised detectors/segmentors. By leveraging similarities between the novel and base classes, we transfer those mappings to obtain detectors/segmentors for novel classes; refining them with a few novel class instance-level annotated samples, if available. This versatile paradigm works significantly better than traditional semi-supervised and few-shot detection and segmentation methods
我们提出了一个直观的半监督模型,适用于广泛的监督:从零到每个新类的几个实例级样本。对于基类,我们的模型学习从弱监督到完全监督检测器/分段器的映射。通过利用新类和基类之间的相似性,我们将这些映射转换为新类的检测器/分段器;如果可以的话,可以使用几个新的类实例级注释示例来细化它们。与传统的半监督和少样本检测和分割方法相比,这种多功能的模式工作得更好。