论文:A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection 【点击下载】
Caffe代码:【Github】
深度学习的根基在于样本,大量的样本决定了深度网络的精确度和收敛性,针对样本的挖掘是深度学习的一个重要研究方向,这里我们先回顾两个概念 Easy Example 和 Hard Example :
Easy Example:
直观上来讲,太易于识别的样本对于训练来讲意义并不太大,有一部分就够了,因为太明显了嘛,傻子都认识;
比较难以区别的样本,比如目标在 变形、遮挡、逆光 等情况下的 Performance,别人不说你都不认识那种。
样本挖掘 通常是找出样本中的 Hard Examples,用来提高网络对于目标的判别能力,讲到这里,可能大多数人都会 Refer 到经典的 OHEM -online hard example mining 。
论文:Training Region-based Object Detectors with Online Hard Example Mining【点击下载】
Caffe代码:【Github】
二. OHEM
传统机器学习中训练 SVM 的时候,通过初始的分类器进行分类(检测)测试,得到的误报即称为 Hard Example,将其加入到训练样本中,重新训练分类器,这种方法称为 Bootstrap(自举)。
OHEM 就是 BootStrap 方法在深度卷积网络中的应用。
先来看网络架构图:
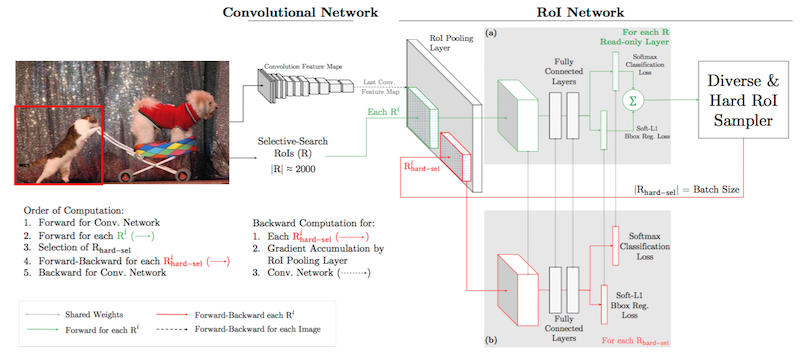
这是基于 Fast RCNN 的结构进行改造的,卷积网络的上半部分是 Fast RCNN 的网络。修改加工的地方在于:
1)添加了一个 Hard ROI Sampler,用于挖掘 Loss 比较大的 Proposal;
2)为了加快速度,复制了一个 ROINet,两个子网络-图中 (a)和(b)共享参数;
(a) 只做正向传播 forward,标注为 Read-only;
(b) 根据 Sampler 传回的结果(hard examples),同时进行正反向传播 - 红色部分。
与原网络的差异在于 通过 Sampler 对 Loss 结果进行排序,将Loss最大的 k个作为 Hard Examples,进行误差回传,这样做的意义在于充分利用了 Hard Examples,增加了网络的辨识度。
三. 对抗网络引入
当下生成式对抗网络(GAN)大热,而 GAN 的最核心的作用就是造假,造的假的越来越接近真的,逼迫 “Detector” 不断突破自我来进行判别。
GAN在最后生成的这些 Example 就可以称为 Hard Example。
将对抗学习和Fast R-CNN结合,来增加遮挡和姿态变化的物体的数量,这种做法可行性在于:
1)实际样本中可能这种情况比较少;
2)现实搜集的样本仅包含部分场景,很难 cover 多数的遮挡和变形情况;
作者提到一个长尾效应,20%的场景在80%的情况下不会出现,来看下图:

因此,通过自动生成的方式来获得这些样本将变得很有意义,可以通过这些样本来 Teach 网络什么是“遮挡”和“变形”,区别于传统的直接生成样本图片的方法,作者采用的是在特征图上进行“某些”变换:
a)通过添加 Mask来实现实现特征的部分遮挡;
b)通过操纵特征响应来实现特征的部分变形;
> Adversarial Spatial Dropout Network
处理遮挡的对抗网络,通过 Mask(Dropout)来实现,网络结构:
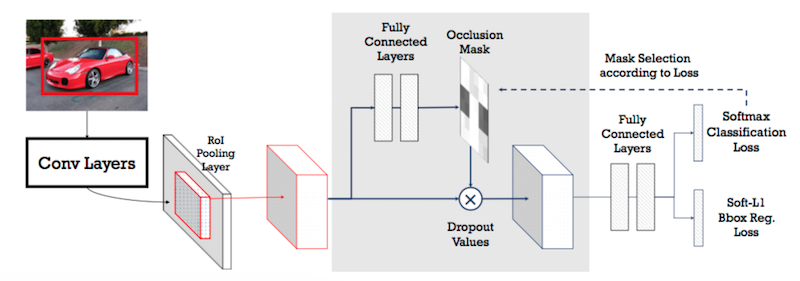
网络结构基础是 Fast RCNN 网络,在阴影部分做了一些处理:
1)添加了一个 Mask层,作为遮挡掩码,并通过前面两个FC层来生成 Mask,共同构成对抗网络部分;
2)根据 Loss 选择 Mask;
Occlusion Mask 是二值掩码(值为0或1),大小与传入的 Feature 一致,假设ASDN的输入特征图是d×d×c(AlexNet中,d=6,c=256),对应 Mask 尺寸也是 d×d。对应像素 Mij 值为1时,drop 所有特征通道对应的特征。
训练过程:
1)模型预训练:首先屏蔽掉 ASDN 部分,单独训练 Fast RCNN 网络 10k 次;
2)ASDN 网络初始化:
通过 d/3×d/3 的滑动窗口(原特征图的1/9)进行遮挡测试,每个特征图会得到10种不同的遮挡情况(包括完全不遮挡,如下图),生成的新特征图通过 Fast RCNN 判别,选择损失值最高的那个为最优(因为它最能骗过分类器)。
将选择的 Grid 最优的样本和对应 Mask组成训练样本{(X1,M1), (X2,M2), ……,(Xn, Mn)},Loss 函数描述为:
其中 Aij 表示对应特征图 Xp 在 i,j 位置对应的输出。
ASDN 单独训练 10k 次。
3)阈值采样
通过上面的训练过程,我们得到一个连续的热度图(不再是二维掩码),或者叫灰度图,作者选择其中影响最大的1/3来生成mask(不是固定阈值),这里采用了一个 Trcik,先选择最大的 1/2 ,再从里面选取 2/3 set to 0,这个不重要。
4)联合训练
将 Fast RCNN 与 ASDN 进行联合训练(joint training)。
受强化学习的启发,只采用 hard examples mask 来训练 ASDN。


> Adversarial Spatial Transformer Network
处理形变的对抗网络,通过在特征图上产生形变,让检测器难以判别。
STN回顾:包含三个部分:定位网络(localisation network)、网格生成器(grid generator)和采样器(sampler)。
定位网络 估计形变参数(如旋转、平移距离和缩放因子),网格生成器 和 采样器 会用到这些参数来产生形变后的特征图。
STN 的贡献在于生成的网络是可微的,这样定位网络的参数可以通过分类目标的残差回传得到,具体内容参考论文:Spatial Transformer Networks 。
Aversarial STN:
这里只关注旋转特征,其中定位网络由3个全连接层构成,前两层是由fc6和fc7初始化得到。
与 ASDN 类似,ASTN 和 Fast R-CNN 也需要联合训练,如果ASTN的变换让检测器将前景误判为背景,那么这种空间变换就是最优的。与 ASDN 不同的是,由于 ASTN 是可微的,我们可以直接通过分类误差反向传播,fine-tune 定位网络的参数。
执行细节:
首先旋转角度不能太大(太大了肯定识别不出,没什么意义),文中把旋转角度限制在(-10,10),同时,按照特征图维度将Channels 划分为 4个 parts(对应4种不同的旋转方向),这样可以增加旋转操作的复杂性,避免 Trivial 变形。
对抗网络融合:
ASDN 和 ASTN 提供了两种不同的变化,通过将这两种变形相结合(ASDN 输出作为 ASTN 的输入),检测器可以训练的更加鲁棒。

> 实验结果
在 VOC2017 上的测试结果(可以对比一下单独的 ASDN 和 ASTN 的网络,以及两者都采用的 mAP):
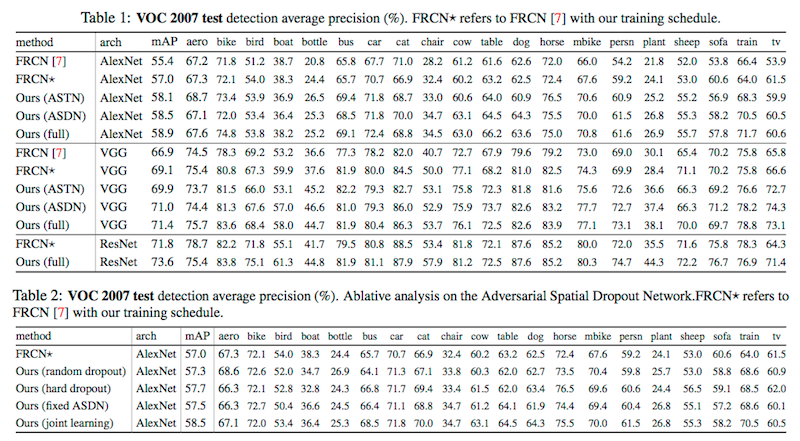
作者分别进行了 遮挡 和 变形方法的对比:
1)Table2 是针对 4种丢弃策略进行对比,得到最好的效果是 ASDN联合训练 的结果;
2)ASTN 和 随机抖动(random jittering)做了对比,发现使用AlexNet,mAP分别是58.1%h和57.3%,使用VGG16,mAP分别是69.9%和68.6%,ASTN 的表现都比比随机抖动效果好。
作者对不同类别进行了分析:

可以看到,有一些种类的 AP 是下降的,有好也有坏,但功大于过。好的原因在于测试样本中可能出现了比较多的遮挡和形变情况;降低的原因在于对于正常目标的特征抽象能力下降。
定性分析:某些遮挡样本 可能会导致错分的情况(这是一把双刃剑啊),也就是说,过尤不及,当你想对目标特征的兼容性太强的时候,走向了另一个极端。

另外,作者给出了在 VOC2012 和 MS COCO 下的测试结果,都较原来有显著提高。
与 OHEM 对比:
本方法和 OHEM(Online Hard Example Mining)有些类似,都属于对 Hard Example 的挖掘,区别在于本方法是创建并不存在的Hard Positive 样本,而 OHEM 则是挖掘利用现有的 所有 Hard 样本,现实意义更高。
测试结果:在VOC 2007数据集上,本文方法略好(71.4% vs. 69.9%),而在VOC 2012数据集上,OHEM更好(69.0% vs. 69.8%)。作者又做了实验,VOC 2012数据集下,our approach+OHEM(71.7%),two OHEM(71.2),two our approach(70.2%),发现两个 OHEM 和 两个 our models 效果都不如混合效果好,说明这两种方法可以有效互补。
Conclusion:
将对抗网络引入目标检测,确实开了先河,估计以后还会有人在此基础上进一步改进。
从改善效果上来讲,并不比 OHEM 有多好的效果,也许是仿造的数据和真实性还存在差距,也许是真实世界的长尾并没有太多的影响,anyway,也许像大家说的一样,“学术意义大于工程意义”,就看接下来的童鞋如何 Follow 和改进了。