主动学习研究现状
一. 传统查询策略(Query Strategy)
主动学习介绍和传统查询策略看两篇就够了:
知乎:循环智能的主动学习(Active Learning)技术探索与实践:减少 80% 标注量
知乎:主动学习(ACTIVE LEARNING)
CSDN:主动学习入门篇:如何能够显著地减少标注代价
这里只做简单的罗列:
-
(1)不确定性采样的查询(Uncertainty Sampling):
- 1.置信度最低(Least Confident)
- 2.边缘采样(Margin Sampling)
- 3.熵方法(Entropy)
-
(2)基于委员会的查询(Query-By-Committee):
- 1.投票熵(Vote Entropy):选择这些模型都无法区分的样本数据;
- 2.平均 KL 散度(Average Kullback-Leibler Divergence):选择 KL 散度较大的样本数据。
-
(3)基于模型变化期望的查询(Expected Model Change);
-
(4)基于误差减少的查询(Expected Error Reduction);
-
(5)基于方差减少的查询(Variance Reduction);
-
(6)基于密度权重的查询(Density-Weighted Methods)。
这些方法在Alipy,modAL,libact库里面都有集成:
- Alipy(比较推荐):
- 官网:http://parnec.nuaa.edu.cn/huangsj/alipy/
- github:https://github.com/NUAA-AL/ALiPy
- csdn:https://blog.csdn.net/weixin_44575152/article/details/100783835
- modAL:
- 官网:https://modal-python.readthedocs.io/en/latest/index.html
- github:https://github.com/modAL-python/modAL
- libact:
二. 在图像分类的应用
参考下面的10篇文章,但是遗憾的是作者没有提供源码:
CSDN:主动学习:Active Learning
对于理解怎么将主动学习实践、流程有帮助
三. 在目标检测的研究
3.1.《Localization-Aware Active Learning for Object Detection 》(ACCV, 2018)
论文链接:https://arxiv.org/pdf/1801.05124v1.pdf
论文解读:知乎:【论文】 Active Learning for Object Detection
核心操作:作者提出了两个查询策略,分别为: Localization Tightness (TL) 和 Localization Stability (LS)。
- Localization Tightness (TL) :
这个指标顾名思义就是描述预测的 bounding box 能多大紧密程度框住目标物。对于预测的 bounding box [公式] 的紧密度 [公式] 的定于如下:
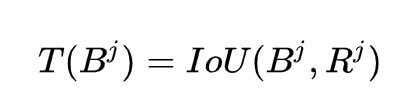
其中, [公式] 为 detector 对应的 region proposal,即当网络预测未经 scale 调整前的推荐 region。

(a) 为置信度很高(即预测得很准 Pmax=1),但紧密程度很低( T(Bj)=0);(b)为置信度很低(即预测得很不准 Pmax=0 ), 但紧密程度很高( T(Bj)=1)。因此,选择策略如下图所示:

- Localization Stability
一个假设为:如果当前模型对噪声是稳定的,这意味着即使输入的未标记图像被噪声破坏,检测结果也不会发生显著变化,则当前模型已经很好地理解了该未标记图像,因此无需对该未标记图像进行注释。
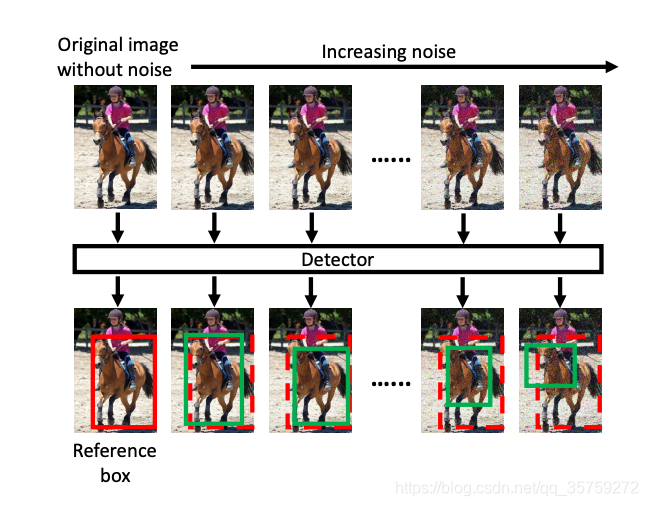
如上图所示,红色框为原图所预测的 bounding box,绿色框为不断增加噪声后模型所预测的bounding box。如果模型能对这张图片学得很好,则红色框和绿色框的变化不会太大;反之,如果模型的预测随噪声的增加发生显著变化,则说明该图片的信息量大需要进行标注。
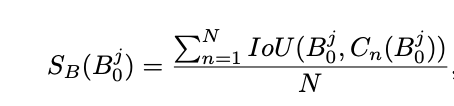

3.2. 《Active Learning for Deep Object Detection via Probabilistic Modeling》
论文链接:https://arxiv.org/abs/2103.16130
论文翻译:CSDN:【论文阅读】Active Learning for Deep Object Detection via Probabilistic Modeling
出发点:不确定性的预测可以拆分为偶然不确定性和认知不确定性两个方面。偶然不确定性是指数据的固有噪音,比如传感器噪音或是图像特征的遮挡或是缺失。认知不确定性是由于模型本身的能力所限并且与训练数据的密度成反比。在主动学习中建模并且区分这两种不确定性是十分重要的。为了计算这两种不确定性,学者们会用基于多模型的方法,比如集成方法或者MC dropout。然后对于基于多模型的方法往往需要较高的计算代价,而对于集成来说,这更增加了网络的参数量。另外,这些方法只依赖于分类的不确定性,完全无视了定位的不确定性。
创新点:本文的方法通过单模型的单次前向传播,通过结合图像中每一个目标的基于定位和分类的不确定性来评估每张图像的信息量得分。
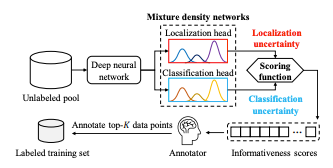
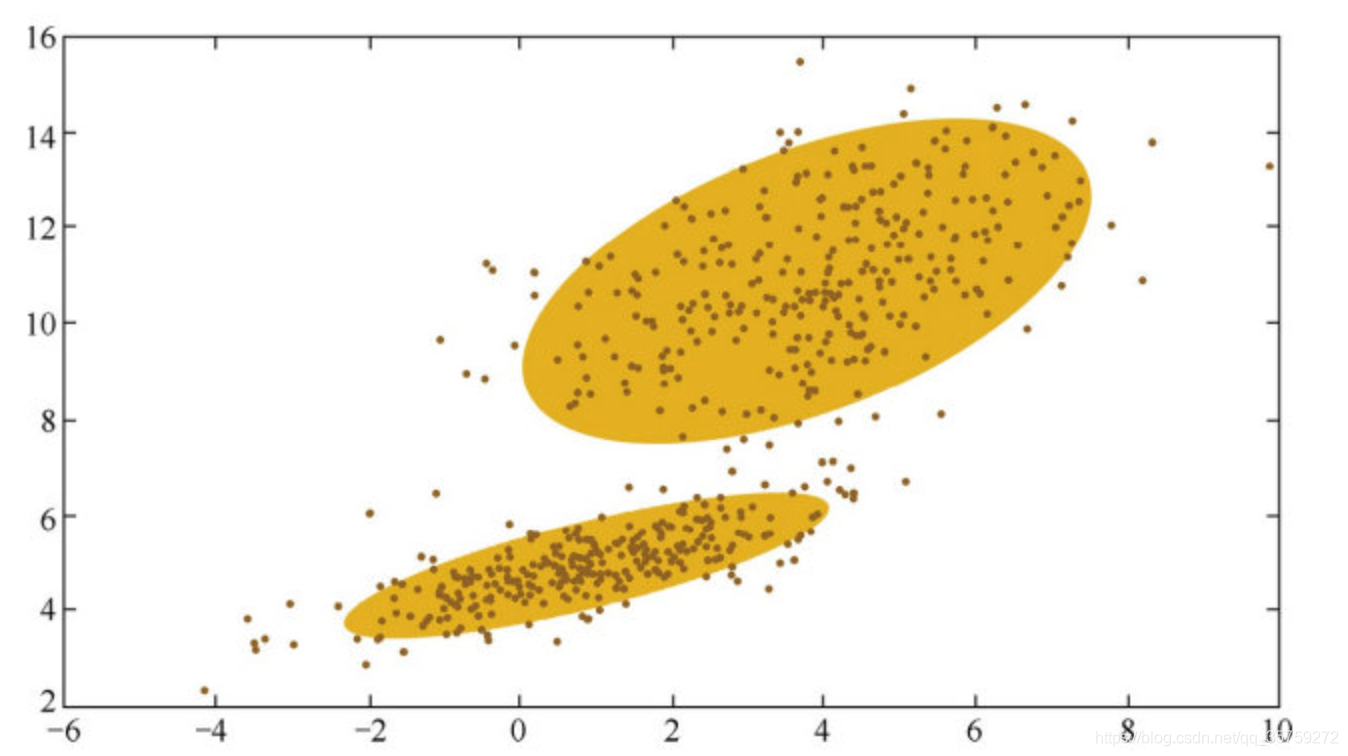
我的理解:对于每个目标Ground True都会有很多个预测框Bounding Box,这些Bounding Box的概率分布即代表了目标的偶然不确定度和认知不确定度,而这些分布可以用GMM来确定(一个分布可以由K个高斯分布来表达,比如下图的分布就可以用2个高斯函数要表达)
据此,作者在文末也展现了消融实验,说明在K=4的时候IOU>0.75的mAP效果最好

不确定性计算公式:其中输出网络由 GMM的参数组成:均值µk、方差 Σ k和第 k 个的混合权重 πk对于GMM 的第k个组成部分。给定这些参数,我们可以估计任意 ual偶然不确定性和uep认知不确定性。
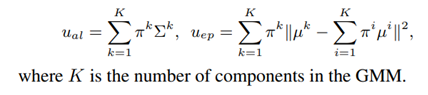
混合模型:我的理解是,GMM是在Locloss和Clsloss后增加的新网络,只用来预测不确定度,用来筛选主动学习的图片,用于下一个batch训练,不参加反向传播;而定位和分类损失是独立于不确定性,单独定义用于反向传播的,用于更新参数后参加(上一个batch+上一个batch参数的模型来预测筛选出下一个batch的其中一部分数据)的下一轮训练

至于定位目标损失等可以自己看看论文
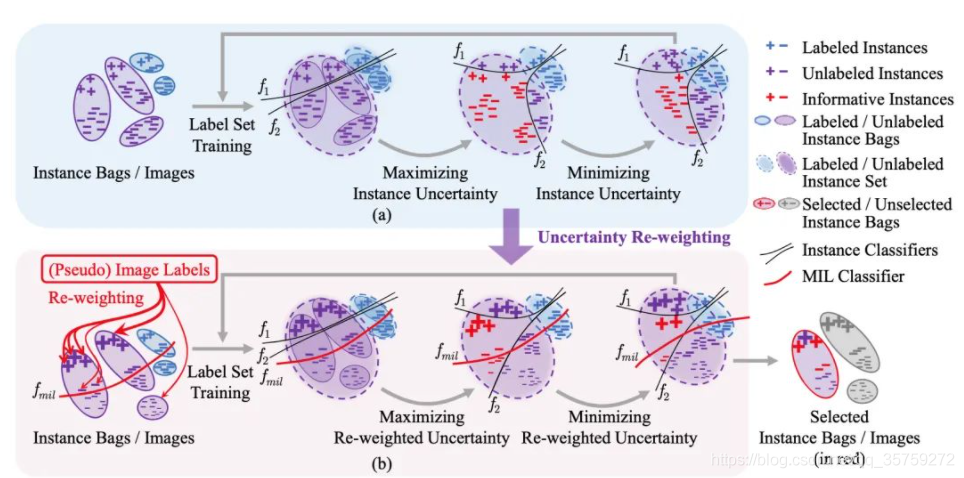
3.3. MI-AOD——《Multiple Instance Active Learning for Object Detection》
- 标题:用于目标检测的多实例主动学习
- 论文:https://arxiv.org/pdf/2104.02324.pdf
- 代码:https://github.com/yuantn/MI-AOD
- 详细解读:知乎:MI-AOD: 少量样本实现高检测性能
出发点:尽管主动学习在图像识别方面取得了长足的进步,但仍然缺乏一种专门适用于目标检测的示例级的主动学习方法。
核心操作:本文提出了多示例主动目标检测(MI-AOD),通过观察示例级的不确定性来选择信息量最大的图像用于检测器的训练。MI-AOD定义了示例不确定性学习模块,该模块利用在已标注集上训练的两个对抗性示例分类器的差异来预测未标注集的示例不确定性。MI-AOD将未标注的图像视为示例包,并将图像中的特征锚视为示例,并通过以多示例学习(MIL)方式对示例重加权的方法来估计图像的不确定性。反复进行示例不确定性的学习和重加权有助于抑制噪声高的示例,来缩小示例不确定性和图像级不确定性之间的差距。实验证明,MI-AOD为示例级的主动学习设置了坚实的基线。在常用的目标检测数据集上,MI-AOD和最新方法相比具有明显的优势,尤其是在已标注集很小的情况下。