注:本文仅供学习,未经同意请勿转载
说明:该博客来源于xiaobai_Ry:2020年3月笔记
对应的PDF下载链接在:待上传
目录
常见的评价指标
准确率 (Accuracy)
混淆矩阵 (Confusion Matrix)
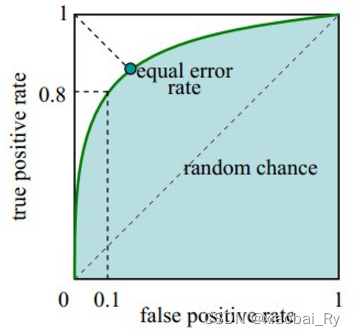
精确率(Precision)与召回率(Recall)
重点:平均精度(Average-Precision,AP)与 mean Average Precision(mAP)
IoU
ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)
PR曲线和ROC曲线比较
NMS%EF%BC%89%C2%A0-toc" style="margin-left:80px;"> 非极大值抑制(NMS)
常见的评价指标
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC + AUC,非极大值抑制(NMS)。
准确率 (Accuracy)
(1)概念:分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
(2)作用:一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
混淆矩阵 (Confusion Matrix)
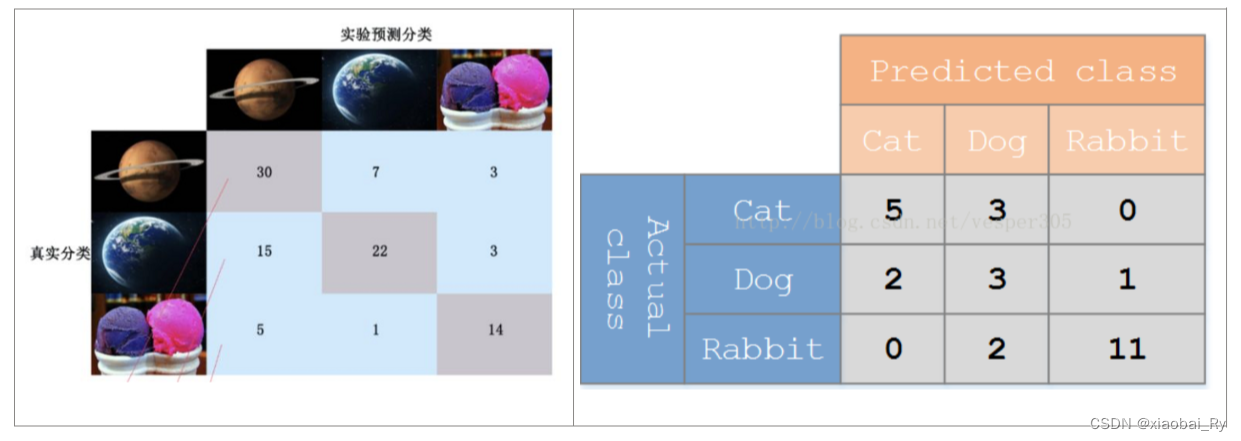
(1)概念:混淆矩阵又被称为错误矩阵, 在每个类别下,模型预测错误的结果数量,以及错误预测的类别和正确预测的数量都在一个矩阵下面显示出来,方便直观的评估模型分类的结果。其中,横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
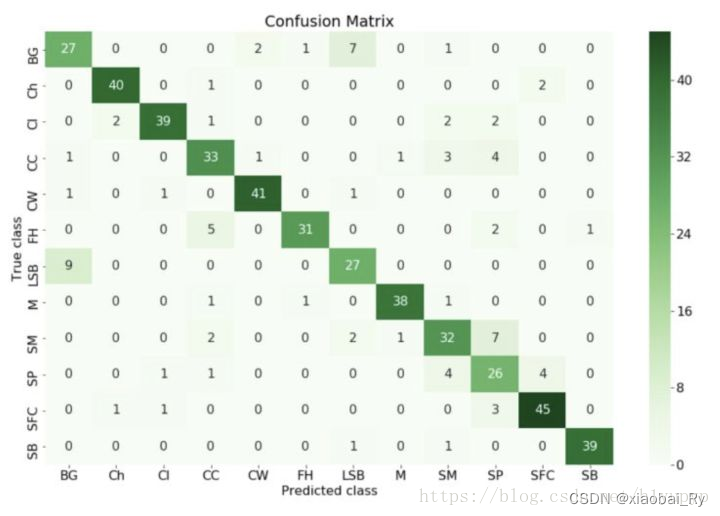
(2)对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
精确率(Precision)与召回率(Recall)
- True positives(TP) : 正样本被正确识别为正样本;预测为positive ground truth为True。
- True negatives: 负样本被正确识别为负样本; 预测为positive 但ground truth 为negative。
- False positives: 假的正样本,即负样本被错误识别为正样本; 预测为positive 但ground truth 为negative
- False negatives: 假的负样本,即正样本被错误识别为负样本;预测为negative ground truth也为False。
- precision查准率: 指预测为positive中,ground truth是positive所占的比例 (TP/(TP+FP)),该值越大越好,1为理想状态
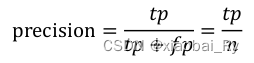
- recall查全率:指测试集中所有正样本样例中,被正确识别为正样本的比例。该值越大越好,1为理想状态。
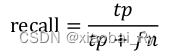
- Precision-recall 曲线:改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线
- 如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
- F1-score: 将precision 和recall合成一个指标,越大越好
- accuracy: 所有预测结果与实际结果一样的样本/所有样本
重点:平均精度(Average-Precision,AP)与 mean Average Precision(mAP)
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
在正样本非常少的情况下,PR表现的效果会更好。
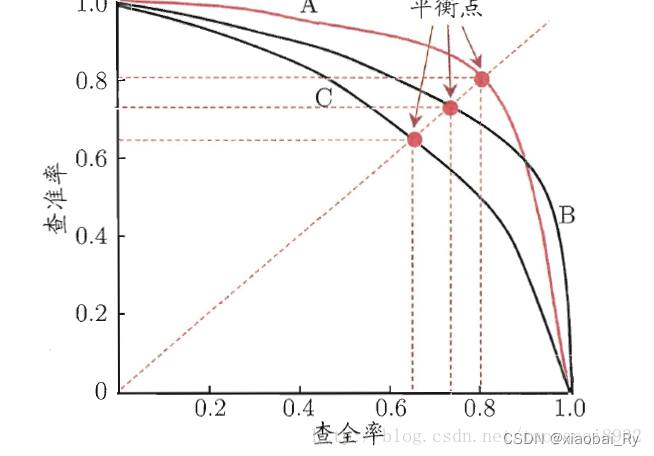
IoU
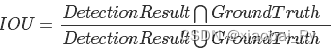
ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)
ROC曲线:
- 横坐标:假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率;
- 纵坐标:真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。
对角线对应于随机猜测模型,而(0,1)对应于所有整理排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。
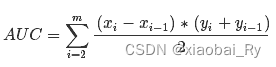
PR曲线和ROC曲线比较
ROC曲线特点:
(1)优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。
在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
(2)缺点:上文提到ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。ROC曲线的横轴采用FPR,根据FPR ,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(当然也可以只分析ROC曲线左边一小段)
PR曲线:
(1)PR曲线使用了Precision,因此PR曲线的两个指标都聚焦于正例。类别不平衡问题中由于主要关心正例,所以在此情况下PR曲线被广泛认为优于ROC曲线。
NMS%EF%BC%89%C2%A0"> 非极大值抑制(NMS)
Non-Maximum Suppression就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的bounding box。对于有重叠在一起的预测框,只保留得分最高的那个。
(1)NMS计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为队列中首个要比较的对象;
(2)计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box,保留小的IoU得预测框;
(3)然后重复上面的过程,直至候选bounding box为空。
最终,检测了bounding box的过程中有两个阈值,一个就是IoU,另一个是在过程之后,从候选的bounding box中剔除score小于阈值的bounding box。需要注意的是:Non-Maximum Suppression一次处理一个类别,如果有N个类别,Non-Maximum Suppression就需要执行N
次。