前置知识
包括:非极大值抑制(NMS)、selective search等
RCNN
[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation (arxiv.org)![]() https://arxiv.org/abs/1311.2524
https://arxiv.org/abs/1311.2524
1.网络训练

2.推理流程

3.总结
1.多阶段模型:RCNN框架上看分为三个部分:预测类别的CNN特征提取网络,SVM分类器,BoundingBox回归预测模型,训练起来很麻烦;
2.计算时间长:每个提出的region proposal都需要单独计算一次feature map
3.占用空间大:需要保存所有的region proposal的feature map
SPP-Net
[1406.4729] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (arxiv.org)![]() https://arxiv.org/abs/1406.4729
https://arxiv.org/abs/1406.4729
1.Motivation
RCNN的问题:
- 速度瓶颈:重复为每个region proposal提取特征是极其费时的,Selective Search对于每幅图片产生2K左右个region proposal,也就是意味着一幅图片需要经过2K次的完整的CNN计算得到最终的结果。
- 性能瓶颈:对于所有的region proposal放缩到固定的尺寸会导致我们不期望看到的几何形变,而且由于速度瓶颈的存在,不可能采用多尺度或者是大量的数据增强去训练模型。
问题核心:
CNN网络需要固定的输入尺寸?
进一步剖析,CNN为什么需要固定的输入尺寸?
何恺明团队发现,这是由于网络中的全连接层(fc)所导致的,卷积层是不需要的,而全连接层需要指定输入张量的维度。那么有没有办法解决这一问题呢?
2.SPP-Net

SPP-Net的做法就是在CNN网络的卷积层和全连接层中加入一个新的层,叫做Spatial Pyramid Pooling(空间金字塔池化层),将卷积层的输出转化为了固定的尺度。
其实这个名字里面包含了两个要素:空间金字塔、池化:
1.空间金字塔:多尺度信息的利用
2.池化:信息的聚合,同时降低参数量,加速模型计算
具体的做法如下:

简单的描述一下:
对于卷积层的最后一层输出,尺寸为任意的H*W*C(示例图中channel为256),我们将H和W按统一规则切分,分成16份、4份、1份,每个区域(H/4*W/4*C, H/2*W/2*C, H*W*256)都进行池化操作,最后concat在一起,张量维度变成:(16+4+1)* 256 = 5376维。无论H、W为什么值,全连接的输入都是这个维度。
3.一个实现细节:如何从一个region proposal 映射到feature map的位置?

SPPNet通过 corner point将图像像素映射到feature map上,假设每一层的padding都是p/2,p为卷积核大小。对于feature map的一个像素(x',y'),其实际感受野为:(Sx‘,Sy’),其中S为之前所有层strides的乘积。然后对于region proposal的位置,我们获取左上右下两个点对应的feature map的位置,然后取特征就好了。
左上角映射为:
右下角映射为:
Fast RCNN
[1504.08083] Fast R-CNN (arxiv.org)![]() https://arxiv.org/abs/1504.08083
https://arxiv.org/abs/1504.08083
(部分内容参考:目标检测之Fast RCNN - 知乎 (zhihu.com))
1.Motivation
主要是针对RCNN中的问题:
冗余的特征提取 + 需要固定region proposal的尺度 + SVM和fc需要分开训练,无法端到端
2.推理流程
- 拿到一张图片,使用selective search选取建议框
- 将原始图片输入卷积神经网络之中,获取特征图(最后一次池化前的卷积计算结果)
- 对每个建议框,从特征图中找到对应位置(按照比例寻找即可),截取出特征框(深度保持不变)
- 将每个特征框划分为 H*W个网格(论文中是 7×7 ),在每个网格内进行池化(即每个网格内取最大值),这就是ROI池化。这样每个特征框就被转化为了 7×7×C的矩阵(其中C为深度)
- 对每个矩阵拉长为一个向量,分别作为之后的全连接层的输入
- 全连接层的输出有两个,计算分类得分和bounding box回归(bounding box表示预测时要画的框)。前者是sotfmax的21类分类器(假设有20个类别+背景类),输出属于每一类的概率(所有建议框的输出构成得分矩阵);后者是输出一个 20×4 的矩阵,4表示(x, y, w, h),20表示20个类,这里是对20个类分别计算了框的位置和大小
- 对输出的得分矩阵使用非极大抑制方法选出少数框,对每一个框选择概率最大的类作为标注的类,根据网络结构的第二个输出,选择对应类下的位置和大小对图像进行标注
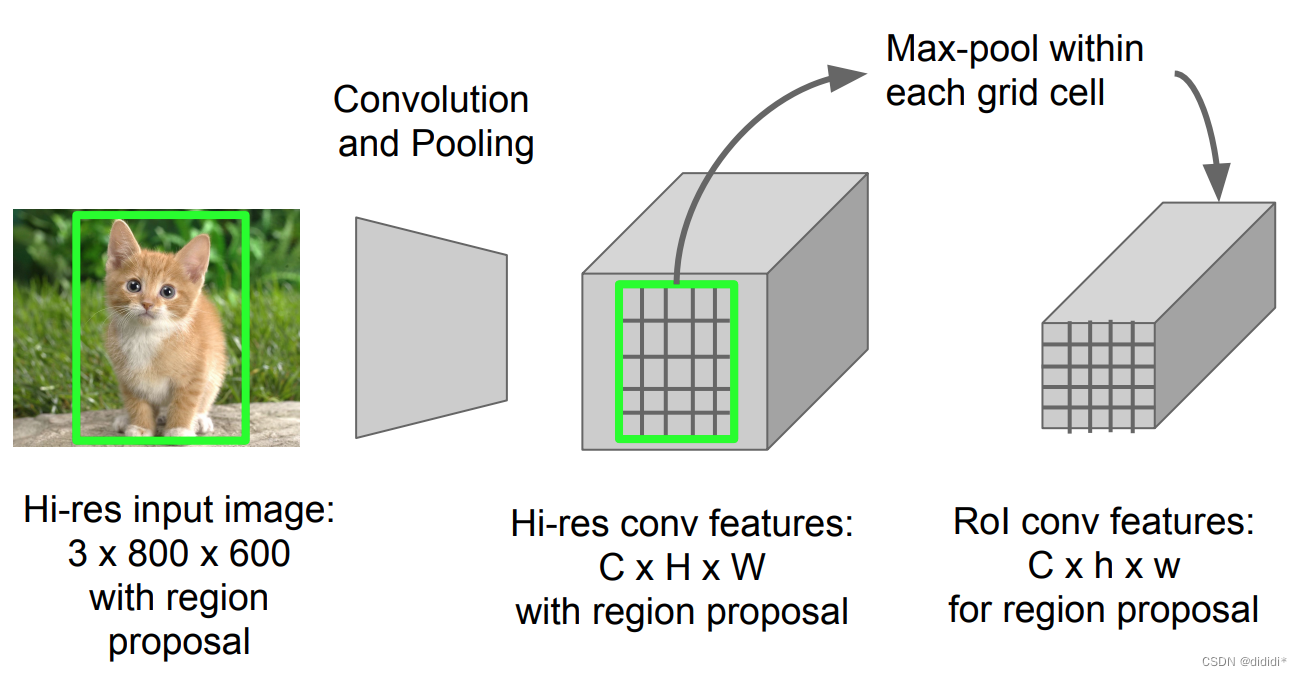
(1)RoI Pooling
在学习了SPP-Net之后,ROI池化就很好理解了,其实可以看成单一尺度的SPP层。
(2)全连接的思考
Q: 为什么第2个fc层要输出一个 20×4 的矩阵,而不是一个4维的向量就行呢?
A: 注意这里的两个全连接层是并行训练的,也就是第一个fc层学习到的类别信息,第二个fc层是无法共享的。因此,如果只学习4维的bounding box框,相当于需要第二个fc隐含的学习类别信息,在没有label作为gt的情况下,训练难度极大,所以学习20*4个框,对类别信息解耦,相当于告诉网络,指定类别去预测框的位置。
3.网络训练
(1)网络结构

初始化为一个预训练的VGG-16网络,改动网络结构:
- 将最后一个最大池化层换成ROI池化层
- 将最后一个全连接层和后面的softmax1000分类器换成两个并行层,一个是全连接层1+21分类器,另一个是全连接层2+表示每个类预测框位置的输出
- 输入的不再只是图片,还有提取到的建议框位置信息
(2)网络训练
训练输入:图像、GT、Region proposal的坐标
为了提高训练速度,采取了小批量梯度下降的方式,每次使用2张图片的128张建议框(每张图片取64个建议框)更新参数。
每次更新参数的训练步骤如下
- 2张图像直接经过前面的卷积层获得特征图
- 根据ground truth标注所有建议框的类别。具体步骤为,对每一个类别的ground truth,与它的iou大于0.5的建议框标记为groud truth的类别,对于与ground truth的iou介于0.1到0.5之间的建议框,标注为背景类别
- 每张图片随机选取64个建议框(要控制背景类的建议框占75%),提取出特征框
- 特征框继续向下计算,进入两个并行层计算损失函数(损失函数具体计算见下面)
- 反向传播更新参数
(3)池化层的反向传播
这里有一个之前一直忽略的操作,这里看到就一起总结了:
常见的池化层如何求反向传播?
池化分为平均池化和最大池化,这两种池化在反向传播的时候会有不同。
- 平均池化:在反向传播的时候将某个元素平均分成n份分配给前一层,保证池化前后的梯度之和保持不变。
- 最大池化:前向传播的时候记录下最大值的位置,反向传播的时候把梯度传给这个位置,其他位置为0。
ROI又如何求反向传播?
这里偷个懒,参考:Fast R-CNN论文详解-CSDN博客

(4)损失函数
简化的版本参考:Object Detection for Dummies Part 3: R-CNN Family | Lil'Log (lilianweng.github.io)
简单一点理解:
分类损失+预测框的回归损失
(1)分类损失预测21个类,1个背景类+20个物体类;而预测框只计算物体类的回归损失(为了避免大量的背景框导致的过拟合)
(2)平滑的L1损失:相比于L2损失函数,其对离群点、异常值不敏感,可控制梯度的量级使训练时不容易跑飞

(5)SVD加速
在全连接层使用SVD分解来减少计算时间,参考:Fast R-CNN论文详解-CSDN博客

4.总结
1.继承了SPP的思想,使用ROI池化,解决了RCNN的一大痛点;
2.并行训练两个fc的输出,实现了端到端的目标检测模型(个人认为相较于SPP-Net最大的提升)