接着上一篇文章:目标检测——RCNN系列学习(一)-CSDN博客
主要内容包含:Faster RCNN
废话不多说。
Faster RCNN
[1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)![]() https://arxiv.org/abs/1506.01497
https://arxiv.org/abs/1506.01497
1.Motivation
简要回顾一下之前的检测框架,RCNN和Fast RCNN都是基于Selective Search的,能否让网络自己去学习获取Region proposal的过程呢?
顺着这个思路,Kaiming等人提出了Region Proposal Networks(RPN模块),理解这个网络就成了学习Faster RCNN的关键,其余的操作其实和Fast RCNN是一模一样的。
2.Faster RCNN
(部分内容和图参考:一文读懂Faster RCNN - 知乎 (zhihu.com))

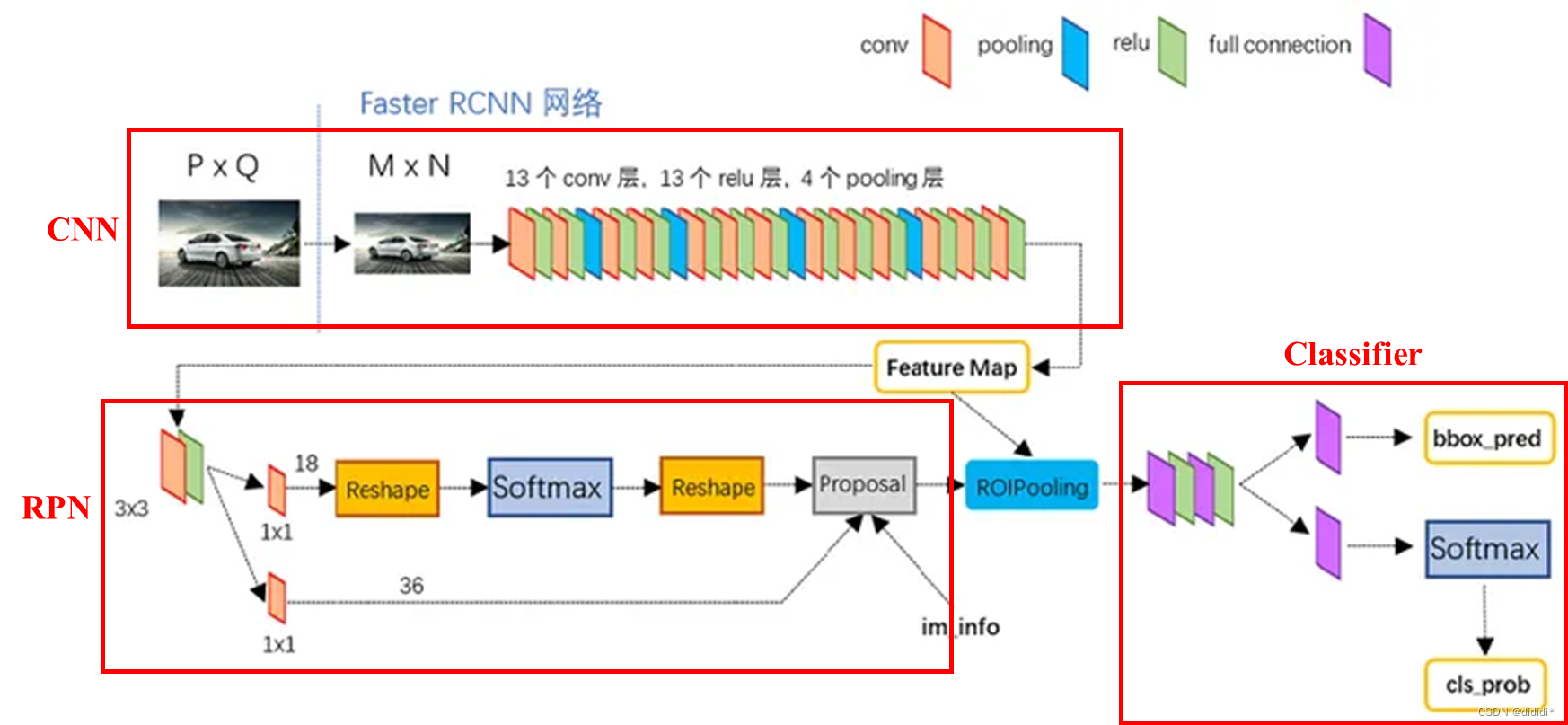
2.1 网络结构
初看:
CNN(特征提取)+ RPN(获取Region Proposal,实现定位)+ ROI Pooling(解决多尺度输入问题)+ Classifier(预测类别与BoundingBox的修正)
细节:
-
CNN
这里的CNN传统采用VGG16为backbone,有一个细节:
- 所有的conv层都是:kernel_size=3,pad=1,stride=1
- 所有的pooling层都是:kernel_size=2,pad=0,stride=2
这涉及到网络前向计算时,特征图的尺寸变换,按照上述形式,假设池化的次数为n,那么最终得到的feature map的尺寸就是原始图像尺寸的1/2^n,4个pooling层就是1/16。
按照上面的尺寸变换,可以保证最终feature map上的点在原始像素空间都有对应点。

此外,还需要注意的一个点,CNN网络的输入图像,全部reshape成了800*600,这是为了便于网络的训练,方便组织成batch。
-
RPN
RPN网络可以说是Faster RCNN的核心,我们下面着重来讲解。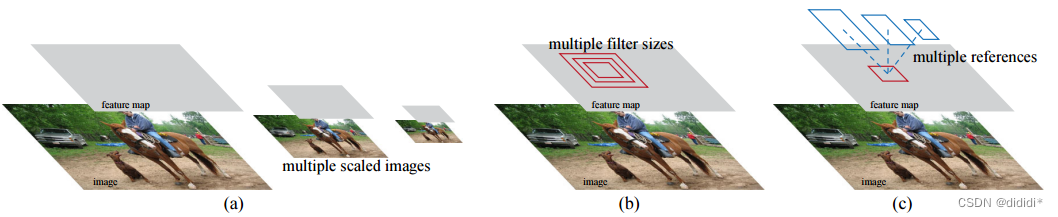
RPN网络的作用从他的名字就可以看出来,为了给出参考的Region proposal。传统的获取候选框的方法如滑动窗口、在原始图像空间进行SS操作,计算量太大,复杂度高,因此RPN的核心想法就是在feature map上获取候选框,做法就是在feature map的每一个点上,设置了一系列的anchor,作为了初始的检测框,虽然这样的初始检测框很不准确,但是后续有两次回归校正的机会。
什么是anchor?
本质上就是一组矩形框,存储时,4个值 (x1,y1,x2,y2) 表示矩形框的左上和右下角点坐标,长宽比为大约为 width:height∈{1:1,1:2,2:1} 三种。
RPN在为feature map上的每个点设置anchor时,除了设置长宽比,还考虑了anchor的尺度(在feature map下的尺度,在原始像素空间的尺度要乘上池化下降的倍率)。
以下图为例:蓝红绿对应了三个尺度,每个颜色下对应了三种长宽比:

上面数据流中RPN的操作对应了作者论文中的图:

RPN的做法:
- 假设Conv Layers最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map中的每个点都是256-dimension
- 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息,同时256-d不变(聚合信息)
- 在conv5 feature map中每个点上有k个anchor(默认k=9,3组长宽比*3组尺度)
- 每个anchor需要区分是否是背景框,对应着上面第一条数据流,其中的18其实就是9个anchor对应positive和negative的概率,9个二分类任务
- 每个anchor需要进行坐标的回归,进行平移和伸缩变换,因此每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4*9=36 个坐标,对应下面这条之路
- 补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练

最终,RPN在feature map上生成了一大堆的anchor框,映射回原始图像的尺度上,也就基本上覆盖了全图。
以上图的尺寸为例子,输入图像尺寸800*600,4个pooling层,则一共有(800/16)*(600/16)*9 = 17100个anchor框。

RPN最后用一个Proposal Layer来整合所有的信息,处理一些特殊的情况,如anchor太多、超出图像边界、某些框尺度太小等问题。
Proposal Layer
输入:anchor修正的坐标信息、anchor属于前景和背景的概率、图像信息(包含图像原始尺度和缩放大小[800,600,16])
- 生成anchors,利用anchor修正的坐标信息对所有的anchors做bbox regression回归(这里是anchor与region proposal的回归,而不是anchor坐标与像素空间下GT的坐标的回归)
- 按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors (选择最有可能是前景的框)
- 限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界
- 剔除尺寸非常小的positive anchors
- 对剩余的positive anchors进行NMS(nonmaximum suppression)
输出:proposal=[x1, y1, x2, y2],注意这里的输出坐标已经被映射回了原始图像尺度。
当proposal的框获取之后,我们的定位功能就已经实现了,接下来只需要进行进一步的坐标修正和图像识别。
RPN网络结构就介绍到这里,总结起来就是:
生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
-
ROI pooling+Classifier
和Fast RCNN一样,不再多说。
2.2 网络训练
(1)待学习参数
整个Faster RCNN网络拆解来看,需要学习的网络参数包括以下四个部分:
CNN(特征提取)+ ROI Pooling(解决多尺度输入问题)+ Classifier(预测类别与BoundingBox的修正)+ RPN(获取Region Proposal,实现定位)
其中前面三个部分可以一起训练,最终的损失和RCNN很相似;而RPN网络单独训练。
(2)RPN部分损失函数:
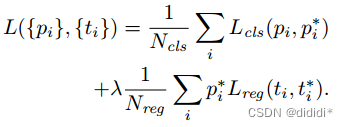
公式中表示anchors index,
表示positive softmax probability,
代表对应的GT predict概率(即当第i个anchor与GT间IoU>0.7,认为是该anchor是positive,
=1;反之IoU<0.3时,认为是该anchor是negative,
=0;至于那些0.3<IoU<0.7的anchor则不参与训练);
代表predict bounding box,
代表对应positive anchor对应的GT box。可以看到,整个Loss分为2部分:
- cls loss,即rpn_cls_loss层计算的softmax loss,用于分类anchors为positive与negative的网络训练
- reg loss,即rpn_loss_bbox层计算的soomth L1 loss,用于bounding box regression网络训练。注意在该loss中乘了
,相当于只关心positive anchors的回归(其实在回归中也完全没必要去关心negative)
(3)四步交替迭代训练方式
Faster RCNN的训练方式可以是交替迭代的训练,也可以是端到端的训练方式,这里只是学习一下论文中提到的交替迭代的方式:
第一步:特征提取的CNN网络参数加载在ImageNet上预训练的模型参数,训练RPN网络,用于生成region proposal;
第二步:固定第一步训练好的RPN参数,拉通训练Fast RCNN网络,即CNN+ROI+两个分类器;
第三步:固定第二步学好的Fast RCNN参数,优化RPN参数;
第四步:固定第三步学好的RPN参数,优化Fast RCNN参数。
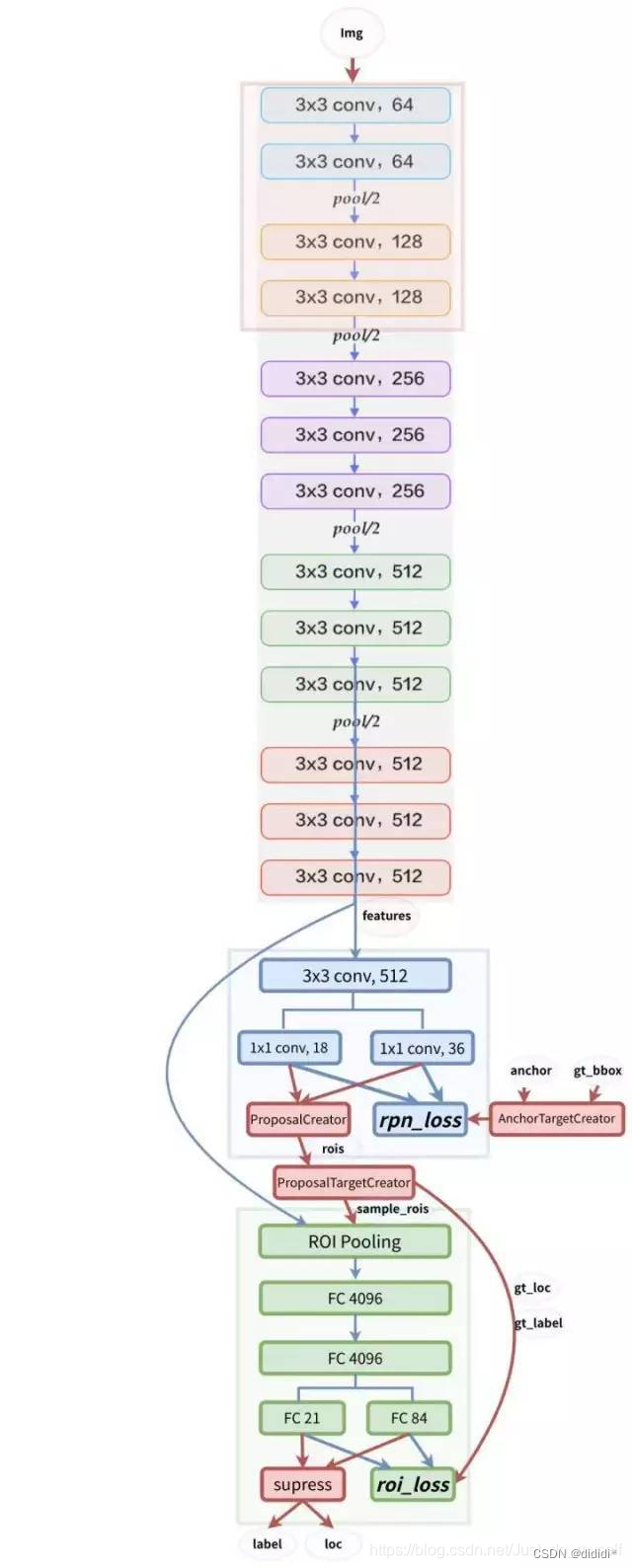
2.3 网络推理
训练好网络过后,我们来看一张图像中,目标是如何被检测出来的:
输入图片——resize到固定尺寸——经过CNN提出特征图feature map——RPN在该feature map上生成anchor对应的类别概率,判断anchor是否是待检测的物体,背景框舍去,同时,对于物体的框进行一系列操作,结合回归修正的坐标,输出在feature map上的region proposal——ROI pooling提取不同尺寸的region proposal的特征,映射成相同的尺度——两个fc层,一个输出识别的类别,一个输出框的进一步修正——最后输出最终的框的坐标,和框内物体的类别。
3.总结
Faster RCNN的核心就在于RPN网络,理解了这个网络,再加上Fast RCNN,就不难学习了。