3D Object Detection for Autonomous Driving: A Review and New Outlooks
https://arxiv.org/pdf/2206.09474.pdf
目录
0.background编辑
1.1表示形式
1.2感知输入
1.3数据集
1.4评估指标
1. LiDAR-based 3D Object Detection
2.数据表征
2.1 point-based
2.1.1 point cloud sampling
Furthest Point Sampling (FPS):最远点 采样
其他采样方式
2.1.2 point cloud feature learning
集合抽象set abstraction
图论 graph
transformer
2.2 grid-based(voxel&pillars&BEV)
2.2.1 Grid-based representations.
voxel(voxelnet)
1711.06396.pdf (arxiv.org)
pillars(PointPillars)
1812.05784.pdf (arxiv.org)
BEV
2.2.2 Grid-based neural networks
2.3 point-voxel based
2.4 Range-based 3D object detection
3.检测方法
3.1 Anchor-based 3D object detection
检测流程
Anchor生成:根据预设的规则(如不同的尺寸、宽高比和朝向),在整个场景或特定的体素/点云区域生成大量的anchor boxes作为候选框。
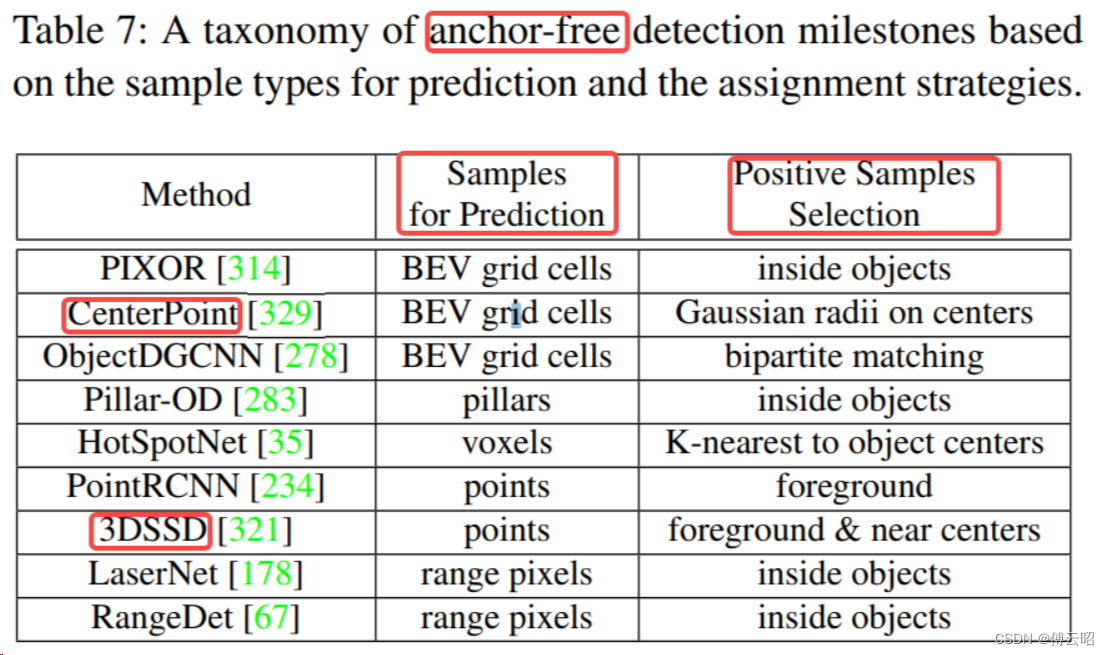
3.2 Anchor-free 3D object detection
关键概念
检测流程
技术特点
区别:
联系:
3.3 3D object detection with auxiliary tasks
4.Camera-based 3D Object Detection编辑编辑编辑编辑5.网络对比
0.background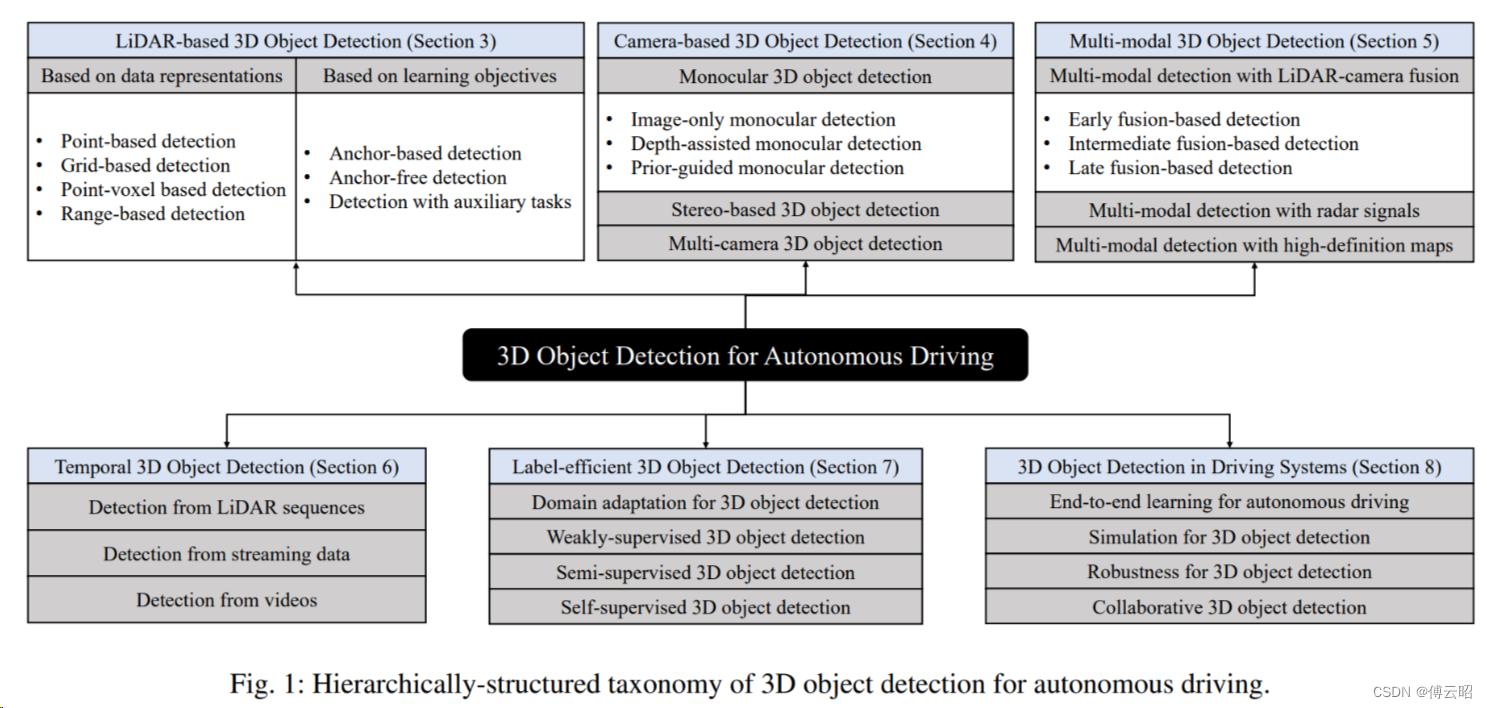
表征方式:point-based,grid-based,point-voxel based,range-based
学习目标:anchor-based,anchor free,辅助任务
1.1表示形式
-
中心点&长宽高&角度&类别
-
4角坐标鸟瞰图BEV

1.2感知输入
-
相机:间接的3D信息,便宜但depth精度低,受天气光照影响,RGB-D,计算深度&立体匹配。机使用光学传感器来捕捉环境中的可见光,并将其转化为数字图像。它基于颜色和纹理等视觉特征来识别和分析目标。相机可以提供丰富的视觉信息,对于目标的形状、纹理和外观具有较高的分辨率。相机对光照条件和环境变化较为敏感,例如强烈的光照、阴影和反射等情况可能会影响图像质量和目标检测性能。
-
雷达:range image是原始图像,可以进一步转化为点云(通过球面坐标转化为笛卡尔坐标)
表示方式:x,y,z,反射intensity,是直接的3D信息。雷达利用电磁波的反射和回波时间来测量目标的位置和距离。它发送脉冲信号,并检测接收到的反射信号,从而获取目标的距离、速度和角度信息。雷达通过测量目标的距离和速度来进行目标检测,对于识别运动和距离较远的目标有优势。它在目标跟踪和环境感知中具有较好的鲁棒性,但对于目标的细节和形状信息有限。雷达在大多数环境条件下都能稳定工作,对于光照变化不敏感,并且可以穿透一些障碍物如雨雪、烟雾等。
-
1.3数据集
 最出名的就是kitti数据集。The KITTI Vision Benchmark Suite (cvlibs.net)
最出名的就是kitti数据集。The KITTI Vision Benchmark Suite (cvlibs.net)
KITTI数据集是一个广泛用于自动驾驶和计算机视觉研究的公开数据集。它由德国卡尔斯鲁厄理工学院(Karlsruhe Institute of Technology)和丰田美国技术研究院(Toyota Technological Institute at Chicago)联合创建。
KITTI数据集提供了丰富的场景数据,包括彩色图像、激光雷达数据、相机投影数据、深度地图、标定参数和车辆运动轨迹等。这些数据涵盖了城市街道环境下的多个方面,如车辆检测、目标跟踪、立体视觉、语义分割、道路检测等任务。
KITTI数据集的主要特点包括:
-
彩色图像:包含从车载摄像头拍摄的图像序列,用于目标检测、语义分割等任务。
-
激光雷达数据:提供了高分辨率的三维点云数据,用于障碍物检测、立体视觉等任务。
-
相机投影数据:将激光雷达数据投影到图像平面上,用于将2D和3D信息进行对齐和融合。
-
深度地图:提供了场景中每个像素的深度信息,用于立体匹配和三维重建。
-
标定参数:包括相机和激光雷达之间的标定参数,用于数据对齐和几何转换。
-
车辆运动轨迹:提供车辆的姿态和运动轨迹信息,用于目标跟踪和运动估计。
1.4评估指标
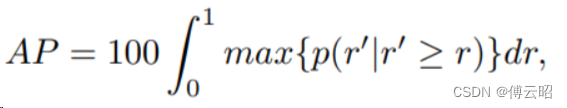

3D IoU (Intersection over Union) 是一种常用的指标,用于评估两个三维(3D)边界框或感兴趣区域(ROI)之间的重叠程度。它通常用于目标检测、实例分割和三维重建等任务中。
3D IoU 的计算需要两个边界框或区域的坐标信息。假设有两个3D边界框,分别为框A和框B。计算3D IoU的步骤如下:
-
计算两个边界框的交集(Intersection):找到两个边界框在三维空间中的重叠部分。
-
计算两个边界框的并集(Union):找到两个边界框在三维空间中的总覆盖区域。
-
计算3D IoU:将交集的体积除以并集的体积,得到IoU的值。公式如下:
3D IoU = 交集体积 / 并集体积
3D IoU 的取值范围在0到1之间,其中0表示两个边界框完全不重叠,1表示两个边界框完全重叠。较高的3D IoU 值通常表示检测结果与真实目标的匹配程度较高。
1. LiDAR-based 3D Object Detection
LiDAR-based 3D object detection是基于激光雷达数据进行三维目标检测的方法。它在自动驾驶、机器人感知和环境理解等领域中被广泛应用。LiDAR(Light Detection and Ranging)利用雷达技术测量光的反射时间来获取目标的距离、位置和形状等信息。
LiDAR-based 3D object detection的主要步骤包括:
-
点云获取:使用激光雷达设备发射激光束,测量激光束与目标表面的反射时间,从而获取点云数据。每个点的坐标表示了目标在三维空间中的位置。
-
点云预处理:对点云数据进行预处理,包括去噪、滤波和降采样等操作,以减少噪声和数据量,并提高后续处理的效率。
-
点云分割:将点云数据分割成不同的物体或物体部分。常见的方法包括基于聚类、分割算法(如基于平面、曲面或体素的分割)等。
-
特征提取:对每个点或点云局部区域提取特征。常用的特征包括点的位置、法线、颜色、形状描述符等,用于表示点云的几何和语义信息。
-
目标检测与分类:使用机器学习或深度学习算法对提取的特征进行目标检测和分类。常见的方法包括基于传统机器学习的分类器、基于深度学习的神经网络(如PointNet、VoxelNet、SECOND、PointPillars等)。
-
目标定位与跟踪:确定每个目标的位置、姿态、尺寸和速度等信息。通常使用回归或优化算法对目标进行定位和跟踪。
LiDAR-based 3D object detection的优势在于它能够提供准确的目标位置和距离信息,并在复杂的环境中工作,如低光照、雨雪、烟雾等。相比于基于相机的方法,它对目标的深度感知更为强大,可以获取更丰富的三维几何信息。
然而,LiDAR-based 3D object detection也存在一些挑战。激光雷达设备昂贵且体积较大,对于实时应用和大规模部署可能面临成本和空间限制。此外,点云数据的处理和计算复杂度较高,需要较强的计算资源。
综上所述,LiDAR-based 3D object detection是一种强大的技术,能够提供精确的三维目标检测和定位。随着激光雷达技术的进一步发展和算法的改进,它在自动驾驶和机器人领域的应用前景将会更加广阔。

2.数据表征
2.1 point-based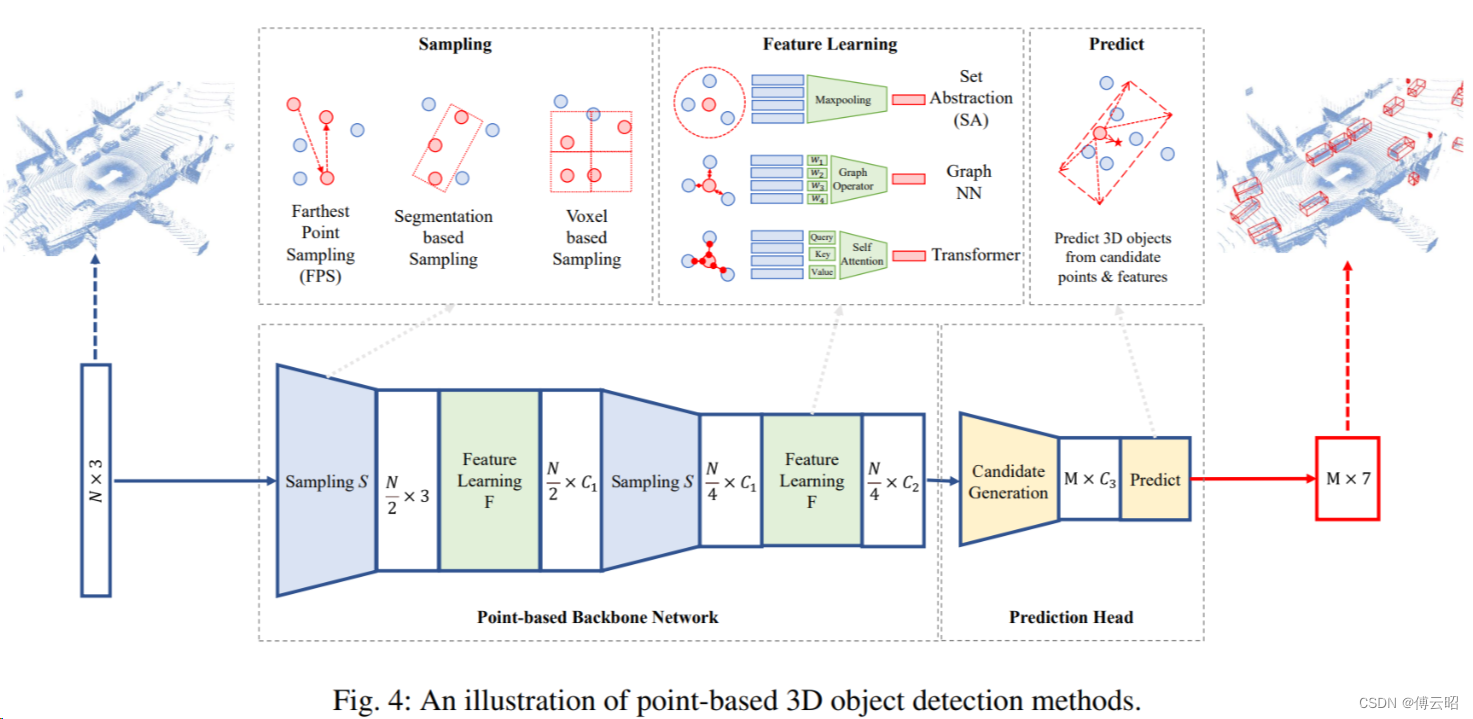
组成=点云采样 + 特征学习 + 预测
2.1.1 point cloud sampling
Furthest Point Sampling (FPS):最远点 采样
最远点采样(Farthest Point Sampling,简称FPS)是一种常用的点云采样方法,用于从大规模点云数据中选择具有代表性的点子集。它通过选择具有最大距离的点来实现。
最远点采样的基本思想是从点云中选择一个起始点,然后逐步选择与已选点集距离最远的点,直到达到所需的采样数量或满足其他停止条件。这样可以确保采样的点在整个点云中分布均匀,同时保留关键的几何特征。
最远点采样的算法流程如下:
-
初始化:从点云中随机选择一个点作为起始点,并将其加入采样点集。
-
距离计算:计算每个未选择点与已选点集中所有点的距离。
-
最远点选择:选择与已选点集距离最远的点作为下一个采样点,并将其加入采样点集。
-
重复:重复步骤2和步骤3,直到达到所需的采样数量或满足其他停止条件。
最远点采样的算法可以通过迭代和贪心策略实现。它具有简单高效的特点,并且可以保证采样点的均匀性和代表性。
其他采样方式
-
随机采样:简单地从点云中随机选择一定数量的点作为采样点。这种方法简单快速,但可能导致采样点分布不均匀。
-
均匀采样:将点云空间划分为网格或体素,然后从每个网格或体素中选择一个点作为采样点。这种方法可以确保采样点在整个点云中均匀分布,但可能无法保留细节信息。
-
点云密度相关采样:根据点云的密度信息进行采样。可以使用密度估计方法(如基于半径的邻域搜索)来计算每个点的密度,然后根据密度进行采样。这样可以在点云中保留更多的细节信息。
-
语义相关采样:根据点云的语义信息进行采样。可以使用语义分割模型对点云进行语义分割,然后根据不同类别的分割结果选择具有特定语义标签的点作为采样点。这种方法可以选择具有特定语义属性的点,用于特定的分割任务。
-
基于聚类的采样:使用聚类算法(如K-means、DBSCAN等)将点云分成不同的簇,然后从每个簇中选择代表性的点作为采样点。这种方法可以提取点云中的主要簇或群集,并保留主要的形状和结构信息。
2.1.2 point cloud feature learning
集合抽象set abstraction
点云特征学习中的集合抽象(Set Abstraction)是一种常用的方法,用于从原始点云数据中提取更高级别的特征表示。它通过将点云分解为一组更紧凑的点集,每个点集代表一个更大范围的区域或物体,以捕捉全局和语义信息。
集合抽象的基本思想是通过层次化的方式对点云进行分割和聚合。通常,这个过程包括以下步骤:
-
区域分割:使用一种分割算法(如基于体素、基于聚类或基于几何特征等)将原始点云分割成多个局部区域或子集。每个子集中的点代表一个局部区域。
-
局部特征提取:对每个局部区域内的点进行特征提取。这可以包括点的位置、法线、颜色、形状描述符等特征。常用的方法包括局部特征描述符(如FPFH、SHOT等)的计算。
-
局部特征聚合:将每个局部区域的特征进行聚合,生成表示整个区域的特征。常用的聚合方法包括简单的平均或最大池化操作,将局部特征合并为一个全局特征向量。
-
递归迭代:对生成的全局特征继续进行集合抽象的过程,即将全局特征作为输入,重复步骤1到步骤3,构建更高级别的特征表示。
集合抽象的优势在于它可以在不同层次上捕捉点云数据的全局信息和语义结构。通过分割和聚合操作,可以减少点云数据的维度,并提取更具代表性的特征,有助于点云分类、分割、检测等任务的准确性和效率。
常见的集合抽象方法包括PointNet(max pooling)、3DSSD,PointNet++和PointCNN等。这些方法通过卷积、池化和聚合等操作,实现了对点云数据的层次化特征提取和学习。
图论 graph
点云特征学习中的图论(Graph)方法是一种有效的方式,用于建模点云数据的几何结构和局部关系。通过构建点云的图结构,并在图上进行图卷积等操作,可以提取丰富的点云特征。
在点云数据中,每个点可以看作是图的节点,而点之间的连接关系可以表示为图的边。基于这种观点,可以使用图论方法来对点云数据进行建模和分析。
图论方法在点云特征学习中的常见步骤如下:
-
图构建:根据点云的几何特征,构建一个图结构。常用的图构建方式包括K最近邻(K-nearest neighbors)和半径最近邻(Radius nearest neighbors)等方法。对于每个点,选择其K个最近邻点或在一定半径范围内的点作为其邻居,并建立连接的边。
-
图特征表示:每个点和其邻居构成了图中的节点和边。可以将每个节点和边赋予特征属性,例如点的位置、法线、颜色等。这些特征属性可以用于节点和边的特征表示。
-
图卷积:在图上进行卷积操作,通过聚合节点邻居的特征来更新节点的特征表示。图卷积操作可以在图上传播和交换特征信息,捕捉局部和全局的关系。常用的图卷积方法包括Graph Convolutional Network (GCN)、GraphSAGE、ChebNet等。
-
图池化:对图进行池化操作,将图的规模降低。图池化可以通过聚合节点特征或减少图的节点和边数来实现。常见的图池化方法有图最大池化(Graph Max Pooling)和图平均池化(Graph Average Pooling)等。
-
图特征学习:通过多次图卷积和图池化的迭代,逐渐提取更高级别的图特征。可以设计深层图卷积网络(如Graph U-Net)来实现更复杂的特征学习。
图论方法在点云特征学习中广泛应用,能够捕捉点云数据的几何和拓扑结构,并提取具有语义和上下文信息的特征表示。这些特征可以用于点云分类、分割、检测等任务,提高算法的性能和鲁棒性。
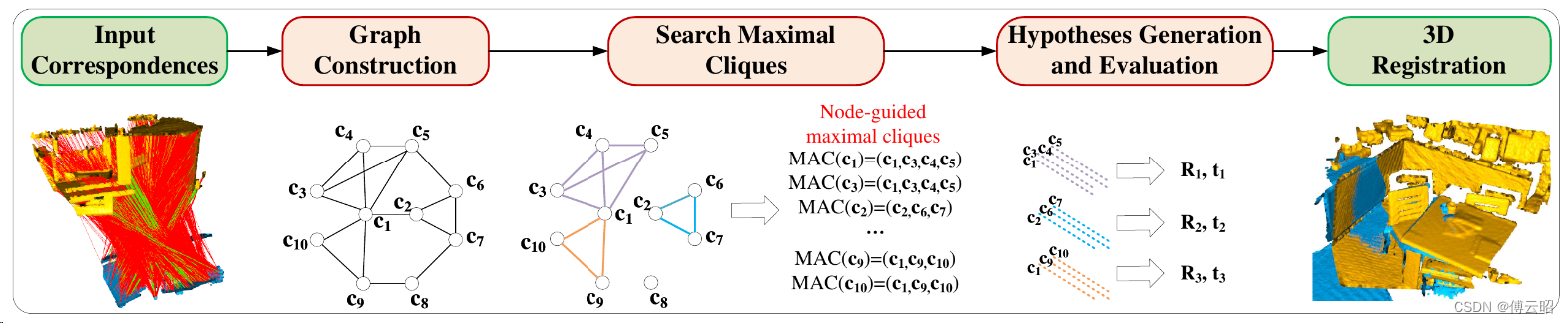
3D-Registration-with-Maximal-Cliques 代表算法,基于图论的匹配算法
transformer
在点云特征学习中,Transformer可以用于对点云数据进行建模和特征提取。以下是使用Transformer进行点云特征学习的一般步骤:
-
点云表示:将点云数据转换为Transformer可以处理的输入表示。可以使用一些方法,如将点的位置、法线、颜色等属性编码为向量表示或矩阵表示。
-
位置编码:为了将点云中的位置信息引入Transformer模型,可以使用位置编码方法将每个点的位置信息嵌入到输入表示中。常用的位置编码方法包括正弦编码和可学习的位置编码。
-
自注意力机制:Transformer的核心是自注意力机制,它能够学习输入序列中不同元素之间的相关性。在点云特征学习中,自注意力机制可以用于学习点之间的关系,并在特征表示中捕捉全局和局部的依赖关系。
-
多层堆叠:为了提取更丰富的特征表示,可以将多个Transformer层堆叠在一起。每个层都包含多头自注意力机制和前馈神经网络,以增加模型的能力。
-
特征聚合:在Transformer的输出中,每个点都具有相应的特征表示。可以通过对特征进行池化或聚合操作,将点云的全局特征提取出来。
-
任务相关模块:根据具体的任务和应用,可以添加任务相关的模块,如分类头、分割头或回归头,以进一步处理提取的点云特征。
使用Transformer进行点云特征学习的优势在于它能够建模点之间的关系,并具有全局感知能力。这使得Transformer在处理点云数据中的长程依赖和语义关系时表现出色。然而,由于点云数据的不规则性和变化性,需要仔细设计输入表示和位置编码方法,以适应Transformer模型的需求。
近年来,一些基于Transformer的点云特征学习方法相继提出,如Point Transformer、PTCN、KPConv等,它们在点云分类、分割和检测等任务上取得了良好的性能。这些方法的发展推动了点云处理领域的研究和应用的进一步发展。
2.2 grid-based(voxel&pillars&BEV)
输入:voxel&pillars&BEV
特征提取:2Dconv & 稀疏3Dconv
输出:3D目标会在BEV gridcell 中探测到
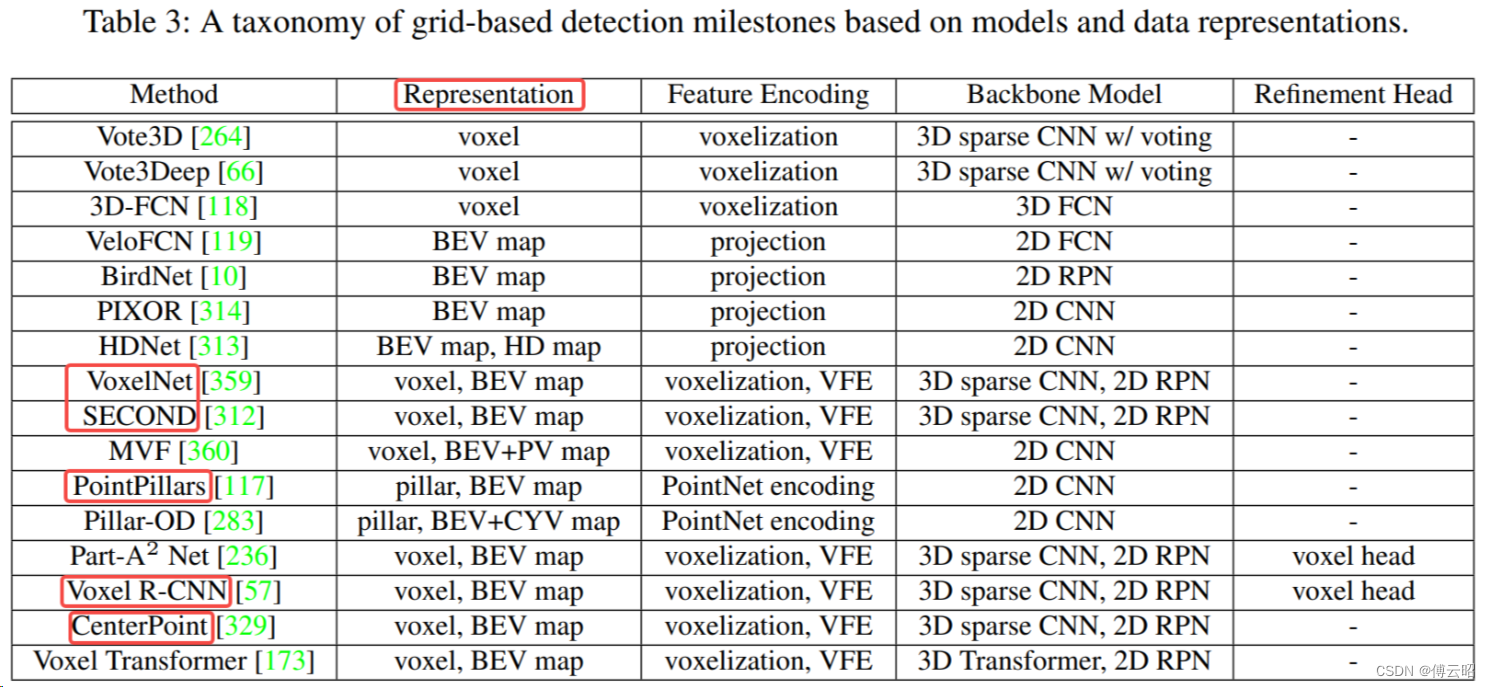
2.2.1 Grid-based representations.
对比2D表征如 BEV & pillar,voxel有更多的3D结构信息,但也计算大
BEV快但是2D,voxel是3D但慢,pillar是两者之间的trade off
问题:gridcell选多大
voxel(voxelnet)
在点云数据处理中,体素(Voxel)是一种常用的点云表征方法。它将三维空间划分为一系列规则的立方体单元,并将每个单元格视为一个体素。每个体素可以表示一个固定大小的空间区域,并且可以用来描述该区域内点云的统计信息或属性。
本质上可以理解为一个3维的魔方。采样方法类似open3d的voxel_down_sample接口。
然后使用3D卷积进行特征提取。
缺点:3D体素占用空间大,且3D卷积计算速度慢

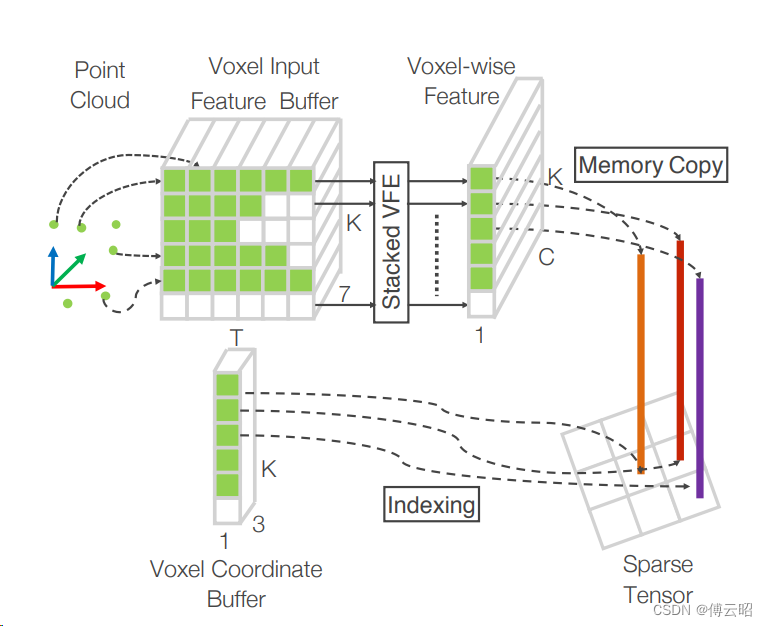 1711.06396.pdf (arxiv.org)
1711.06396.pdf (arxiv.org)
pillars(PointPillars)
Point转化成一个个的Pillar(柱体),从而构成了伪图片的数据。
在基于点云的3D物体检测中,"Pillars"(柱状特征)是一种常用的点云表征方法。它在点云数据的处理中用于提取和表示物体的特征。
"Pillars"的概念最早由PointPillars方法引入,该方法是一种基于深度学习的点云检测算法。它通过将点云数据投影到一个二维空间网格中并构建柱状特征来表示点云数据。
"Pillars"方法的优势在于它能够将点云数据转换为二维平面上的结构化特征表示,使得可以直接应用传统的二维卷积神经网络(CNN)进行处理。这样可以利用CNN在图像处理领域的广泛应用和成熟技术,从而简化了点云数据的处理和特征学习过程。
然而,"Pillars"方法也存在一些限制。首先,柱状特征提取的效果依赖于体素化和投影的参数设定,需要进行仔细选择和调整。其次,柱状特征可能无法捕捉点云数据的细节和形状信息,特别是对于具有复杂几何结构的物体。

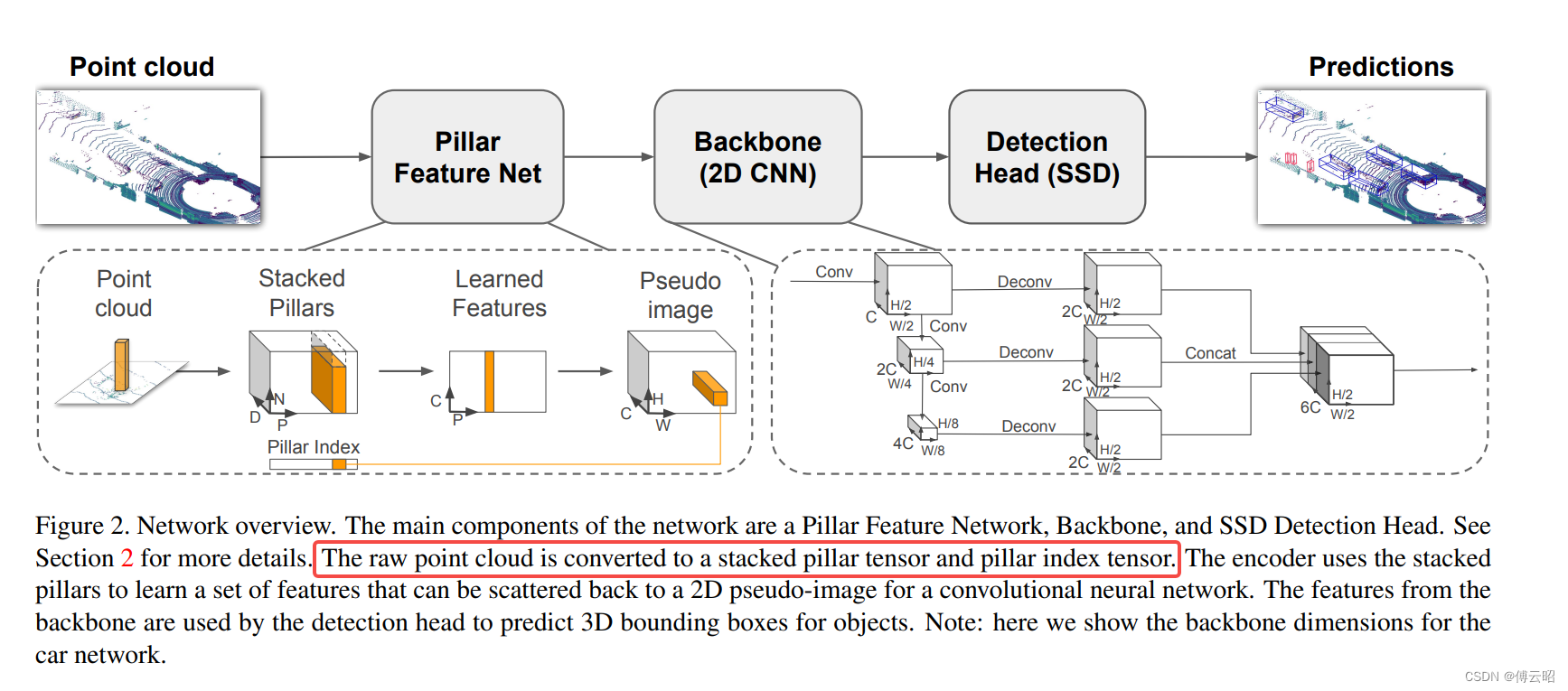 1812.05784.pdf (arxiv.org)
1812.05784.pdf (arxiv.org)
原始点云数据被转换为叠加的柱状张量(stacked pillar tensor)和柱状索引张量(pillar index tensor)。编码器使用叠加的柱状张量学习一组特征,这些特征可以散回到一个二维伪图像(pseudo-image)中,供卷积神经网络使用。
BEV
BEV(Bird's Eye View)算法是一种基于鸟瞰图的三维物体检测算法,常用于自动驾驶和机器人视觉领域。该算法通过将点云数据投影到一个二维平面上,从而将三维空间信息转换为二维图像信息进行处理。
BEV算法的优势在于将三维点云数据转换为二维图像,使得可以直接应用图像处理和计算机视觉领域的成熟技术和方法。计算和存储上节省大量资源。此外,BEV图像中的物体通常以正交视角呈现,有利于物体的定位和形状分析。主要适合自动驾驶,一般假定汽车在水平的马路上运行。
然而,BEV算法也存在一些限制。首先,由于投影过程的信息损失,BEV图像可能无法完全保留点云数据的全部信息。其次,BEV算法对于高度变化明显的场景,如多层建筑或立体交通情况下的物体检测,可能面临挑战。

2.2.2 Grid-based neural networks
2D conv: for BEV & pillars
3D Spare network: for voxelnet, SECOND
two-stage, transformer for voxel_based detection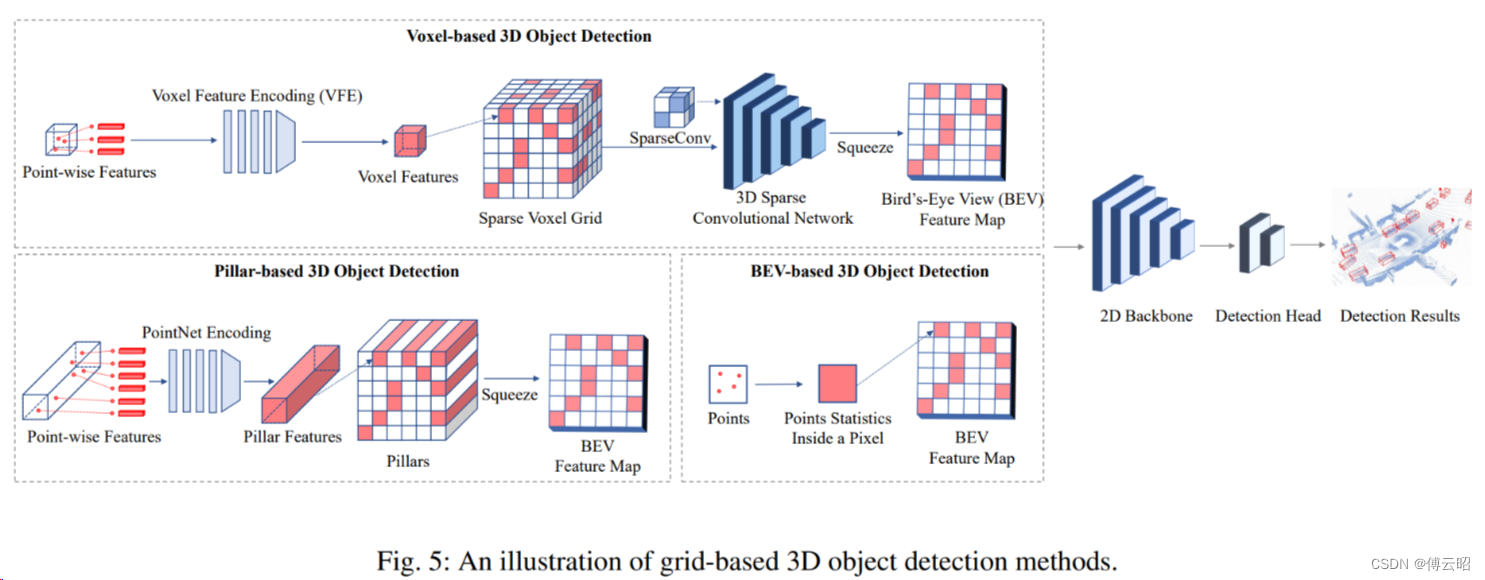
2.3 point-voxel based
思想:point-based包含细粒度的几何信息,voxel-based又结构化,好计算,可以conv
两者结合是一个不错的方向,牺牲速度,提高精度的方法。
基于点-体素(Point-Voxel)的三维物体检测是一种常见的方法,用于从点云数据中检测和定位三维物体。该方法结合了点云的几何信息和体素化表示,以实现高效的物体检测和分割。

2.4 Range-based 3D object detection
Range-based 3D object detection是一种基于距离信息进行三维物体检测的方法。在这种方法中,传感器(通常是激光雷达(LiDAR))收集到的点云数据按照距离(range)信息进行处理,而不是直接在原始的三维空间坐标中操作。
就是2D表示,但每个像素表示的是深度,应该是颜色越亮越远?把RGB-替换为深度
与鸟瞰相比,ranged检测,距离视图的检测容易受到遮挡和比例变化的影响

3.检测方法
3.1 Anchor-based 3D object detection
-
Anchor Boxes:在3D检测中,anchor boxes是预定义的三维边界框,它们具有不同的尺寸、宽高比和方向。这些boxes作为检测的候选区域,遍布在整个三维空间或特定的感兴趣区域。
-
生成机制:与2D图像中的anchor boxes类似,3D anchor boxes可以在不同的尺度、宽高比和朝向上生成,以覆盖可能的目标形状和大小。
-
检测流程
-
Anchor生成:根据预设的规则(如不同的尺寸、宽高比和朝向),在整个场景或特定的体素/点云区域生成大量的anchor boxes作为候选框。
-
特征提取:使用深度学习方法(如3D卷积神经网络)从点云或体素表示中提取特征。
-
分类与回归:对于每个anchor box,网络预测它是否包含目标物体以及物体的类别。同时,对anchor box进行回归调整,以更精确地匹配目标的实际位置和大小。
-
非极大值抑制(NMS):为了去除冗余的检测结果,应用NMS算法来筛选最终的检测框。
-

预测的gt是:物体的中心点xyz,长宽高lwh,还有一个朝向角度。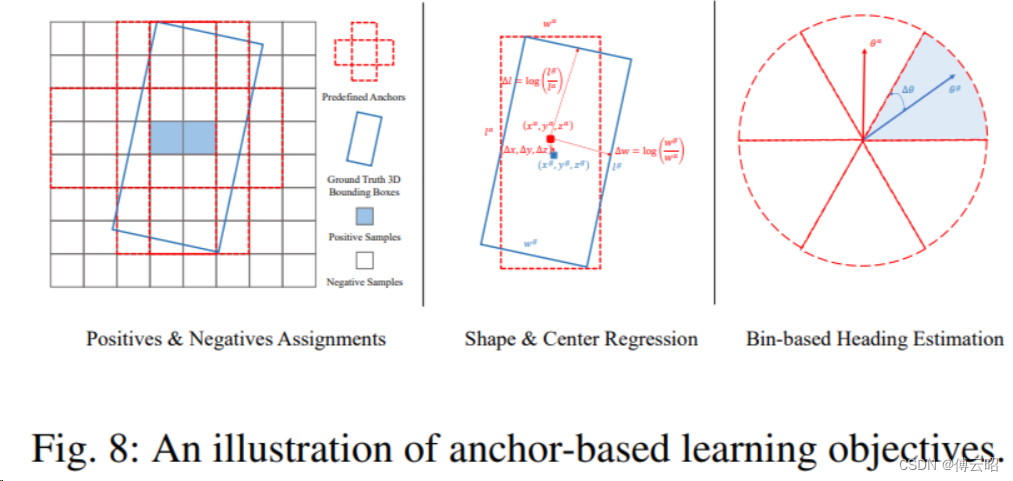
3.2 Anchor-free 3D object detection
Anchor-free 3D object detection是一种相对于anchor-based方法的不同范式。在anchor-free方法中,不需要预定义大量的anchor boxes来作为潜在目标的位置候选,而是直接在原始数据上预测目标的存在和位置。以下是anchor-free 3D物体检测的一些关键点: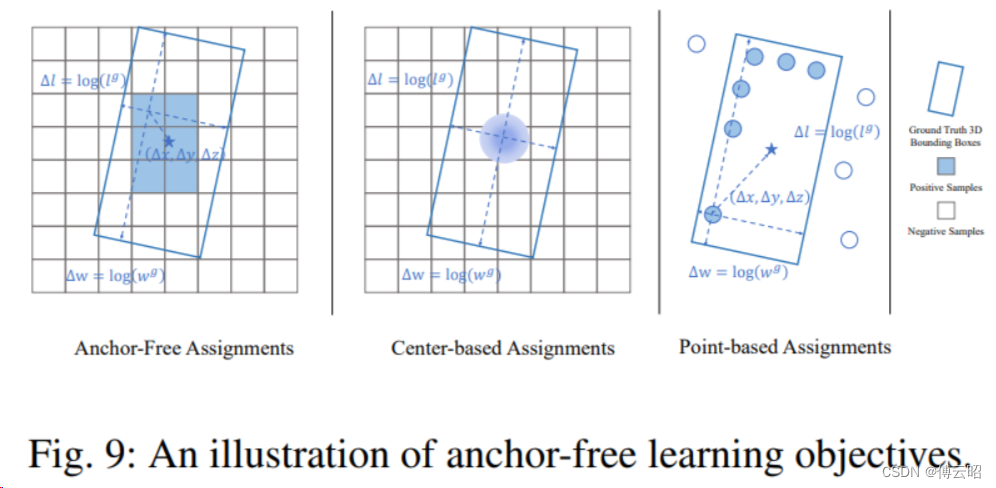
关键概念
-
无锚设计:与anchor-based方法不同,anchor-free方法不依赖于预定义的边界框,而是通过直接在点云或体素化的数据上预测物体的中心点或关键点。
-
端到端学习:anchor-free方法通常采用端到端的网络设计,直接从原始数据中学习物体的特征,减少了手动调参的需求。
检测流程
-
特征学习:使用深度神经网络,如卷积神经网络(CNN)或基于点的网络(如PointNet),从原始点云或体素数据中学习特征。
-
中心点预测:网络直接预测物体的中心点,有时还预测物体的尺寸、方向和其他属性。
-
边界框生成:通过物体的中心点和预测的尺寸等属性,生成物体的三维边界框。
-
置信度评分:网络为每个检测到的物体提供一个置信度评分,用于后续的非极大值抑制(NMS)。
技术特点
-
简化流程:省略了anchor boxes的生成和匹配过程,简化了检测流程。
-
减少计算量:由于不需要处理大量的anchor boxes,anchor-free方法通常具有更低的计算成本。
-
灵活性:不需要对anchor boxes进行手动设计,使得该方法对于不同形状和大小的物体具有更好的泛化能力。
Anchor-free和Anchor-based是两种不同的目标检测方法,它们在目标定位的预测方式和实现机制上存在显著差异。以下是它们之间的主要区别和联系:
区别:
- 预测方式:
- Anchor-free:直接预测物体的中心点或关键点,以及可能的尺寸和方向,不需要依赖预定义的边界框。
- Anchor-based:预测物体相对于一组预定义的anchor boxes的位置偏移和类别,这些anchor boxes通常是手工设计的,具有不同的尺寸、宽高比和朝向。
- 计算复杂度:
- Anchor-free:由于不需要处理大量的anchor boxes,通常具有更低的计算复杂度。
- Anchor-based:需要生成和评估大量的anchor boxes,可能导致较高的计算成本。
- 设计复杂性:
- Anchor-free:方法设计相对简单,不需要精心设计anchor boxes的形状和大小。
- Anchor-based:需要精心选择和设计anchor boxes,以适应不同的物体形状和大小。
- 泛化能力:
- Anchor-free:通常对于不同形状和大小的物体具有更好的泛化能力。
- Anchor-based:可能对于某些形状或尺寸的物体需要特定的anchor boxes设计,以获得更好的性能。
- 性能:
- Anchor-free:在某些情况下可能难以达到anchor-based方法的高准确度,特别是在处理小物体或密集场景时。
- Anchor-based:通常能够达到较高的准确度,特别是在经过精细调优的情况下。
联系:
-
目标检测框架:无论是anchor-free还是anchor-based方法,它们都可以采用类似的目标检测框架,包括特征提取、预测和后处理步骤。
-
深度学习技术:两者都依赖于深度学习技术,如卷积神经网络(CNN)或基于点的网络(如PointNet),来从原始数据中提取特征和进行预测。
-
后处理步骤:通常都会使用非极大值抑制(NMS)来去除冗余的检测结果,以及提高最终的检测质量。
-
应用领域:两者都被广泛应用于自动驾驶、机器人导航、安防监控等需要3D物体检测的领域。
总结来说,anchor-free和anchor-based方法在目标检测的不同方面各有优势和局限性。选择哪种方法取决于具体的应用需求、计算资源和期望的性能指标。随着技术的发展,这两种方法也在不断地相互借鉴和融合,以提高检测的准确度和效率。
3.3 3D object detection with auxiliary tasks
4.Camera-based 3D Object Detection
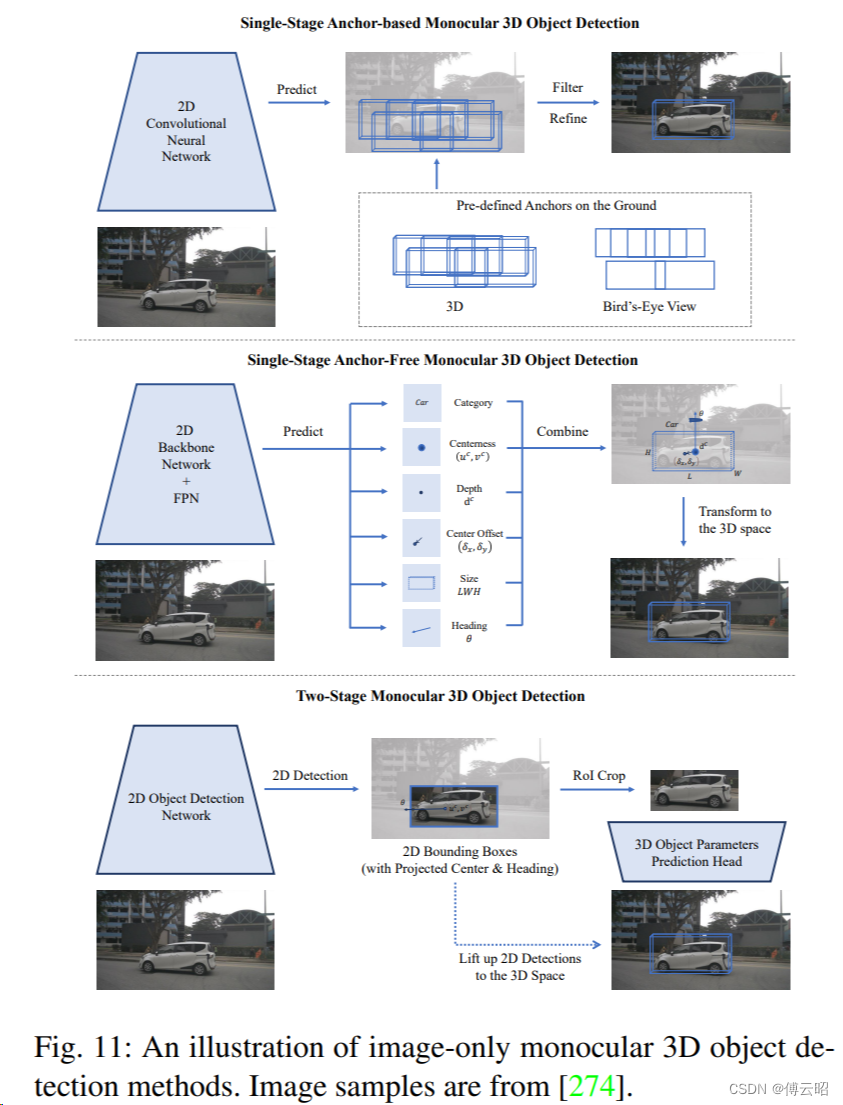
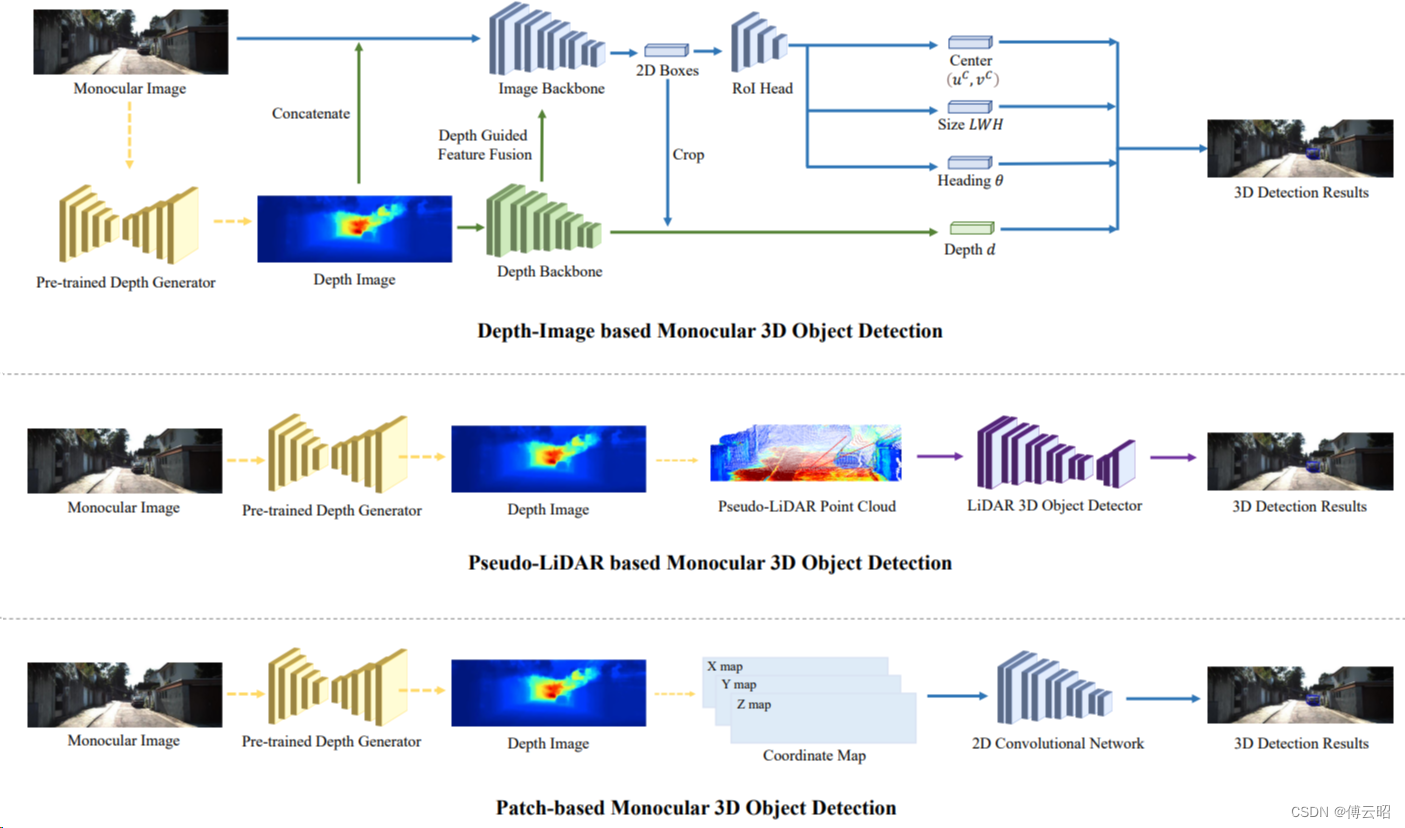
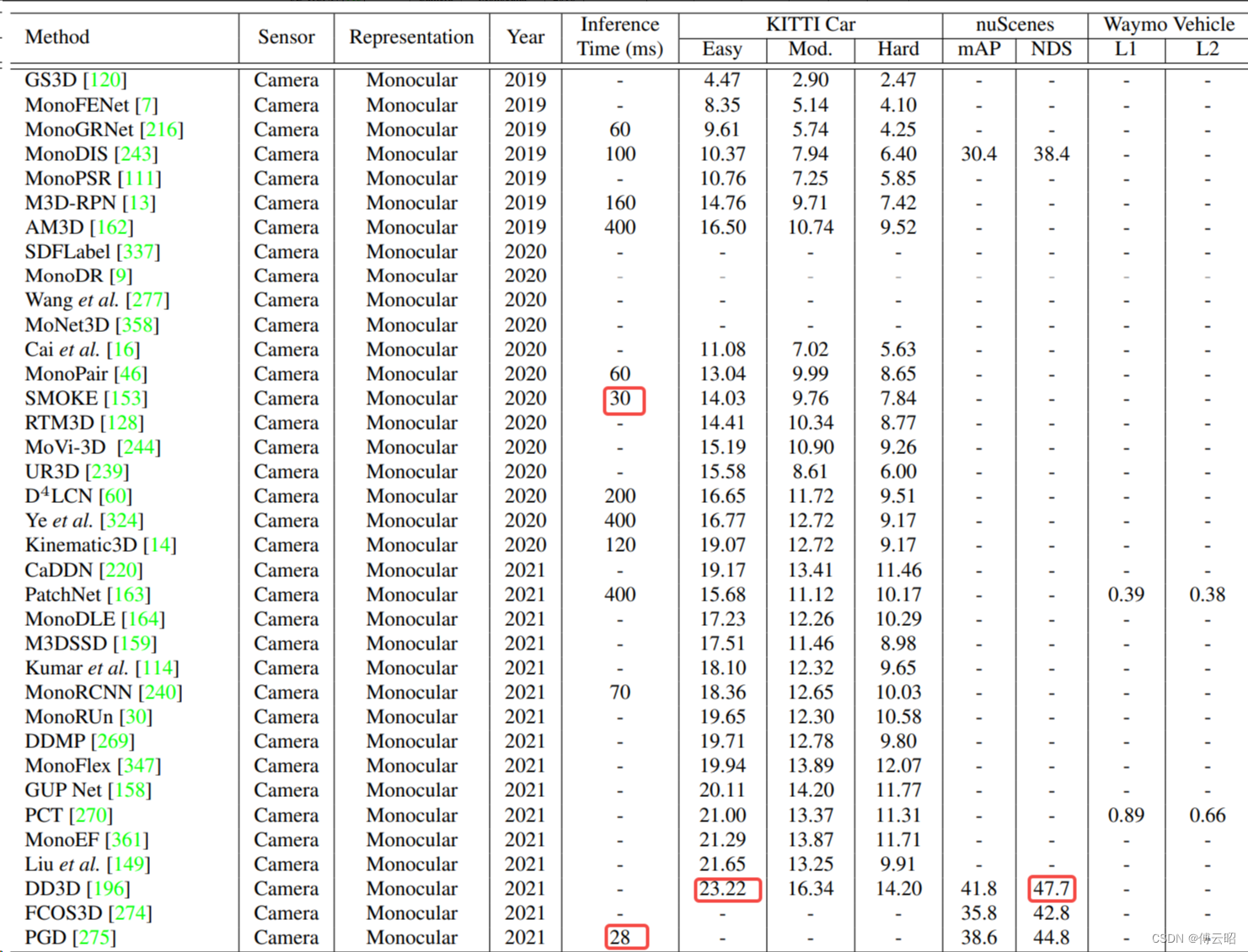
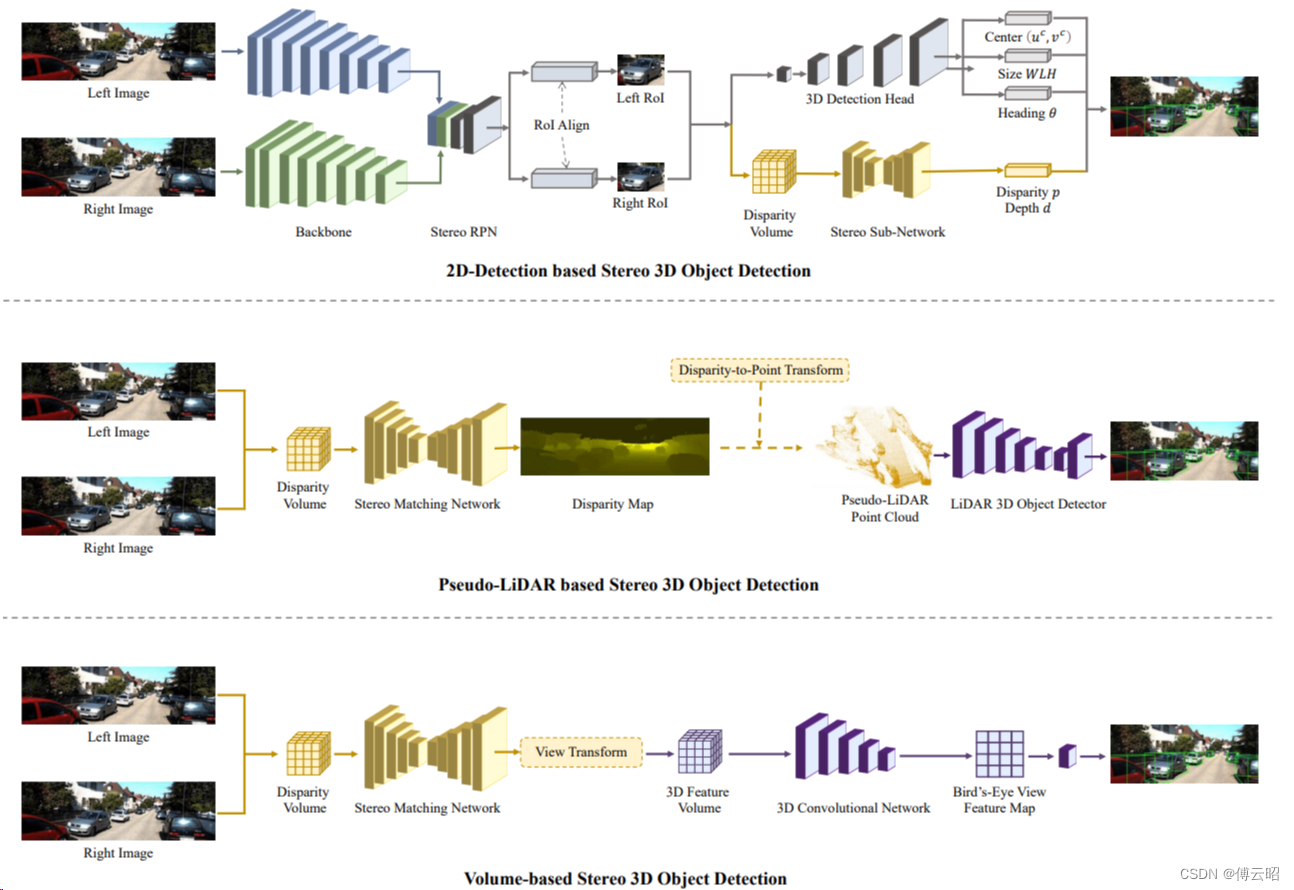 5.网络对比
5.网络对比
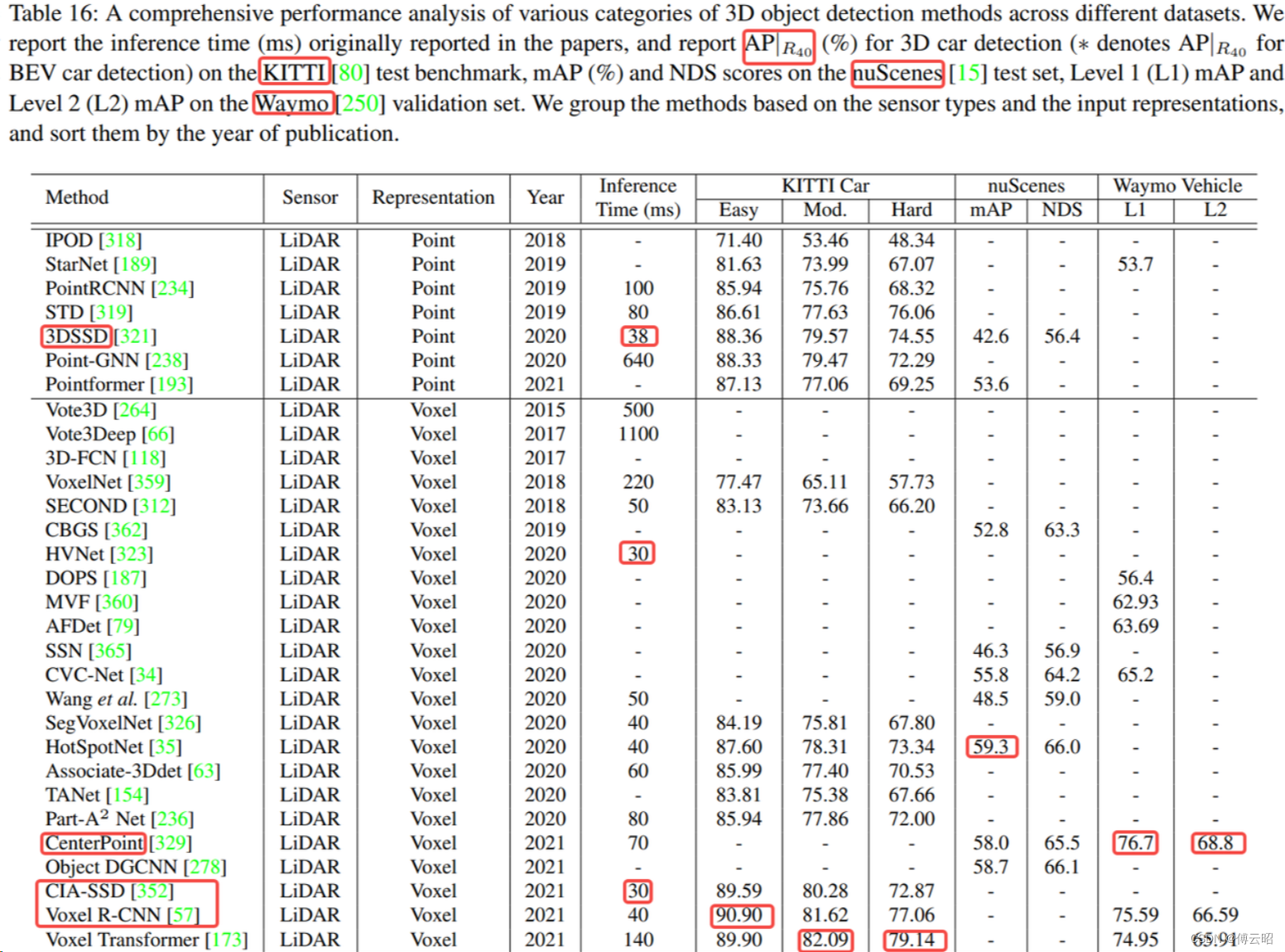
3DSSD,CenterPoint,CIA-SSD,Voxel RCNN, pointpillar,pillarnet,pillar RCNN ,PV-RCNN