BEV_0">基于BEV的自动驾驶会颠覆现有的自动驾驶架构吗

引言
很多人都有这样的疑问–基于BEV(Birds Eye View)的自动驾驶方案是什么?这个问题,目前学术界还没有统一的定义,但从我的开发经验上,尝试做一个解释:以鸟瞰视角为基础形成的端到端的自动驾驶算法和系统。
感知模块是最为重要的自动驾驶模块之一,也是最为复杂的模块。一般的感知模块包含障碍物目标检测,车道线语义分割,可行驶区域分割等等。在BEV出现之后,整个自动驾驶感知模块趋向形成统一,简洁,高效的端到端结构。不光是感知模块,基于BEV进行的规划决策也是学术界研究的方向。下面将结合几篇顶会论文来看BEV给自动驾驶技术带来的改变。
BEV_10">BEV统一了多模态数据融合的尺度
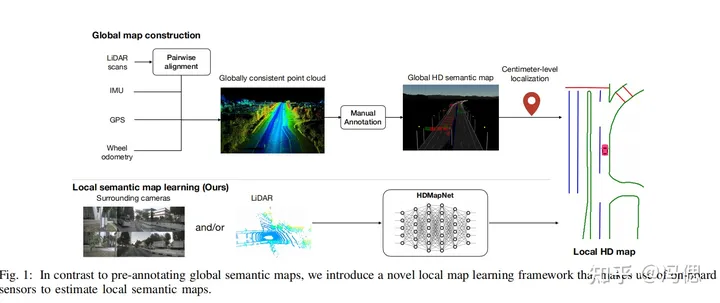
**典型论文:**HDMapNet: A Local Semantic Map Learning and EvaluationFramework
自动驾驶感知模块中对是否要使用激光雷达的问题分成了两派。一种是坚定的纯视觉技术路线,比如特拉斯等。还有一种是国内的多传感器数据融合路线。在没有接触到BEV之前,我是坚定的纯视觉路线的拥护者,但是在研究了一些论文后,我的观点逐步改变。传感器融合路线的机会在前融合或者中融合层面,而目前市面上的多模态数据融合方案多为后融合或者结果层面的融合(补充链接:多模态数据融合的几种方式)。就是在生硬的融合方式下,各个传感器的缺点形成了木桶效应。
BEV的出现给多模态数据提供了一个统一尺度的可能,比如在HDMapNet论文中,主要目的是基于多模态数据采集制作低廉高效的高精地图。作者设计了多传感器的动态可插拔结构。把所有传感器的数据或特征统一到BEV视角下,这样的统一尺度理论上来说天然成立。减少传感器会影响检测的效果,但是不会影响感知系统的可使用性,是1+1>2的正向结果。
BEV_22">BEV带来了简洁高效的感知模块
**典型论文:**FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras
现有的自动驾驶感知模块中,包含了2d/3d目标检测,语义分割,全景分割,多目标跟踪,轨迹预测等。整个感知模块是又臭又长,需要的算法开发/算法维护/模型迭代等人员数量众多。而BEV的出现,让更加简洁高效的感知模块成为可能。
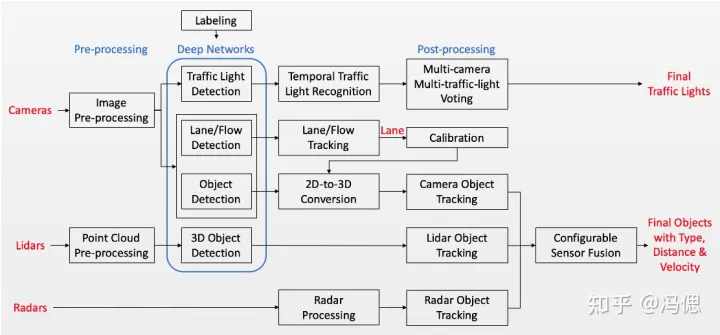
fiery的论文和代码有幸研究了一段时间,结构设计的巧妙和统一任务的架构一下子打开我新世界的大门。这篇文章使用的传感器只有摄像头,也就是纯视觉方案。fiery是在lift论文的基础上进行的改进,这篇论文将多个相机数据通过神经网络进行了基于BEV的投影。在一个算法框架下实现了3d目标检测(无高度h),障碍物实例分割,车道线分割,可行驶区域分割,多目标跟踪,障碍物轨迹预测的功能。维护上述模块可能要大几十的团队,但是现在维护fiery可能十多人就够了(我离失业越来越近了,哈哈)。这篇文章的缺点是耗时太长(8fps),主要是用于未来轨迹预测的GRU网络部分,要3帧一起输入网络。
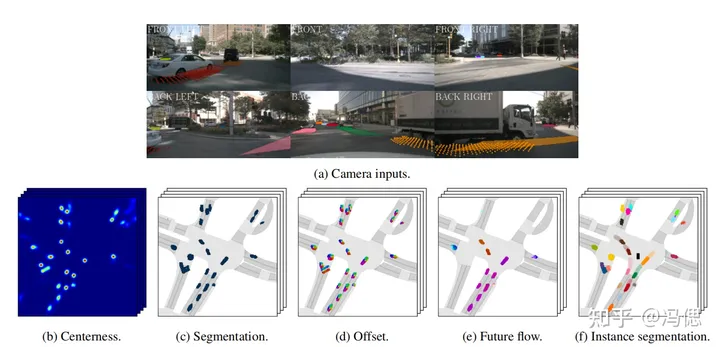
BEV_34">BEV促进端到端的自动驾驶框架发展
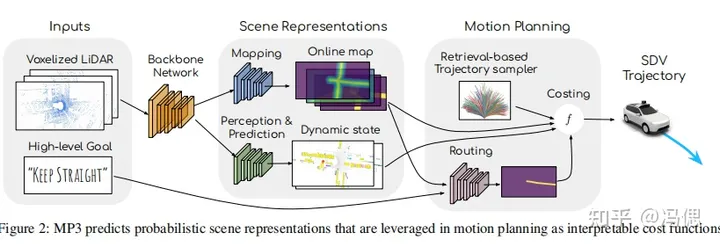
典型论文1:MP3: A Unified Model to Map, Perceive, Predict and Plan
**典型论文2:**SelfD: Self-Learning Large-Scale Driving Policies From the Web
从apollo等开源的自动驾驶框架上看,自动驾驶技术常被分为感知模块,预测模块,规划决策模块,控制模块等。各个模块通过消息机制或者共享内存的方式进行交互,保持相对的独立。此外这样的架构虽顺应了当下的自动驾驶技术发展,但不一定就是合理的,比如强解耦造成的鲁棒性变差等问题。无论是工业界和学术界都在期盼一个端到端的自动驾驶框架的出现。
BEV下的自动驾驶技术发展很可能就是端到端的自动驾驶框架的契机。
SelfD里作者利用BEV视角统一了大量行车视频的数据尺度,并进行了规划和决策模块的模型学习。

MP3中,将地图,感知,预测和规划设计成一个统一模块,形成了一个接近端到端的自动驾驶框架。
BEVViTvision_transform_54">BEV的药引子–ViT(vision transform)
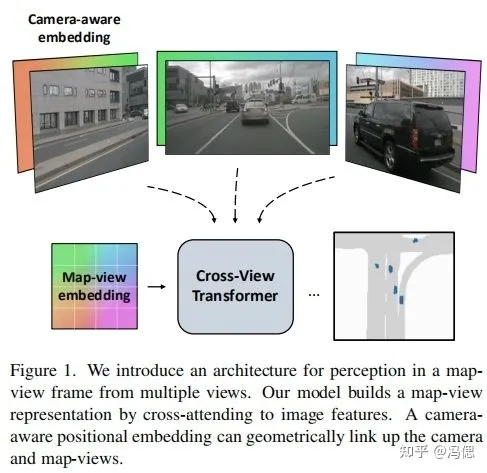
**典型论文:**Cross-view Transformers for real-time Map-view Semantic Segmentation
2022年ViT(vision transform)如何应用在自动驾驶任务上?
经过上面几个层次的分析之后,你是否看到了BEV自动驾驶方案的未来了呢?在我看来BEV技术是形成端到端自动驾驶框架的契机,但是还需要一个药引子——ViT(vision transform)。传统的卷积神经网络在不同尺度/类型的特征的融合上,处理困难(序列特征需要rnn系列,空间特征需要cnn)。但是端到端的自动驾驶框架恰恰就需要融合不同种类的,比如将序列特征和空间特征的融合。来自NLP领域的attention机制提供多类型特征编码融合的统一方法。
cross-view transformers的方法是针对纯视觉多视角下的地图生成和障碍物感知任务,设计一个有效的注意力机制网络。直白点就是用于BEV地图生成和障碍物感知的注意力机制网络。目前代码已经开源,从论文公布的结果看,无论在精度还是速度上都达到SOTA。
总结
据我的了解,目前已经有很多公司启动了基于BEV的自动驾驶框架研发。这两年的顶会论文上看,这个方案下的相关技术会越来越成熟,廉价的自动驾驶技术方案离我们越来越近了。最后,如果真的如预期这样发展,现在的自动驾驶求职热潮可能会带来以后的自动驾驶裁员热潮。
附赠自动驾驶学习资料和量产经验:链接