论文地址:https://arxiv.org/pdf/2312.13735.pdf
源码地址:https://github.com/xinghaochen/DECO
近年来,Detection Transformer (DETR) 及其变体在准确检测目标方面显示出巨大的潜力。对象查询机制使DETR系列能够直接获得固定数量的目标预测,并简化了检测 pipeline。同时,最近的研究还表明,通过适当的架构设计,ConvNeXt这样的卷积网络(ConvNets)也可以与 transformers等变压器实现竞争性能。为此,在本文中,作者探讨了是否可以使用 ConvNet 而不是复杂的 transformer 架构构建基于查询的端到端目标检测框架。所提出的框架,即检测ConvNet(DECO),由骨干和卷积编码器-解码器架构组成。作者精心设计了DECO编码器,并为DECO解码器提出了一种新颖的机制,通过卷积层在对象查询和图像特征之间执行交互。将 DECO 与具有挑战性的 COCO 基准上的先前检测器进行了比较。尽管简单,但DECO在检测精度和运行速度方面具有竞争力。具体来说,使用 ResNet-50 和 ConvNeXt-Tiny 骨干网,DECO 在 COCO val 上分别获得 38.6% 和 40.8% 的 AP,分别为 35 和 28 FPS,优于 DETR 模型。作者的 DECO+ 集成了先进的多尺度功能模块,以 34 FPS 的速度实现了 47.8% 的 AP。作者希望提出的DECO为设计目标检测框架带来另一个视角。
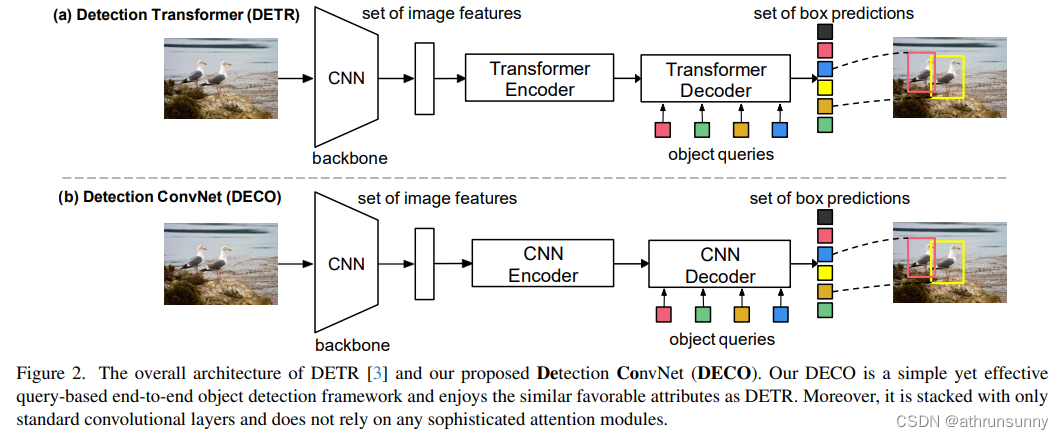
网络架构
DETR的主要特点是利用Transformer Encoder-Decoder的结构,对一张输入图像,利用一组Query跟图像特征进行交互,可以直接输出指定数量的检测框,从而可以摆脱对NMS等后处理操作的依赖。作者提出的DECO总体架构上跟DETR类似,也包括了Backbone来进行图像特征提取,一个Encoder-Decoder的结构跟Query进行交互,最后输出特定数量的检测结果。唯一的不同在于,DECO的Encoder和Decoder是纯卷积的结构,因此DECO是一个由纯卷积构成的Query-Based端对端检测器。
编码器
DETR 的 Encoder 结构替换相对比较直接,我们选择使用4个ConvNeXt Block来构成Encoder结构。具体来说,Encoder的每一层都是通过叠加一个7x7的深度卷积、一个LayerNorm层、一个1x1的卷积、一个GELU激活函数以及另一个1x1卷积来实现的。此外,在DETR中,因为Transformer架构对输入具有排列不变性,所以每层编码器的输入都需要添加位置编码,但是对于卷积组成的Encoder来说,则无需添加任何位置编码。
代码示例:
class DecoEncoder(nn.Module):
'''Define Deco Encoder'''
def __init__(self, enc_dims=[120,240,480], enc_depth=[2,6,2]):
super().__init__()
self._encoder = ConvNeXt(depths=enc_depth, dims=enc_dims)
def forward(self, src):
output = self._encoder(src)
return output # [2, 480, 34, 31]
ConvNeXt部分:
class Block(nn.Module):
r""" ConvNeXt Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # Conv2d(120, 120, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=120) # Conv2d(240, 240, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=240) # Conv2d(480, 480, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), groups=480)
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x # [2, 120, 34, 31] # [2, 240, 34, 31] # [2, 480, 34, 31]
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1)
x = self.norm(x)
x = self.pwconv1(x) # [2, 34, 31, 120] -> [2, 34, 31, 480] # [2, 34, 31, 240] -> [2, 34, 31, 960] # [2, 34, 31, 480] -> [2, 34, 31, 1920]
x = self.act(x)
x = self.pwconv2(x) # [2, 34, 31, 480] -> [2, 34, 31, 120] # [2, 34, 31, 960] -> [2, 34, 31, 240] # [2, 34, 31, 1920] -> [2, 34, 31, 480]
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2)
x = input + self.drop_path(x)
return x # [2, 120, 34, 31] # [2, 240, 34, 31] # [2, 480, 34, 31]
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
depths (tuple(int)): Number of blocks at each stage. Default: [2, 6, 2]
dims (int): Feature dimension at each stage. Default: [120, 240, 480]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self,
depths=[2, 6, 2], dims=[120, 240, 480], drop_path_rate=0.,
layer_scale_init_value=1e-6,
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList()
for i in range(len(depths)-1):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=1),
)
self.downsample_layers.append(downsample_layer) # (0): Sequential((0): LayerNorm() (1): Conv2d(120, 240, kernel_size=(1, 1), stride=(1, 1)))
# (1): Sequential((0): LayerNorm() (1): Conv2d(240, 480, kernel_size=(1, 1), stride=(1, 1)))
self.stages = nn.ModuleList()
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(len(depths)):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6)
self.apply(self._init_weights)
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self, src):
src=self.forward_features(src)
return src
def forward_features(self, src):
for i in range(len(self.depths)-1):
src = self.stages[i](src) # [2, 120, 34, 31]->[2, 120, 34, 31] # [2, 240, 34, 31]->[2, 240, 34, 31]
src = self.downsample_layers[i](src) # [2, 120, 34, 31]->[2, 240, 34, 31] # [2, 240, 34, 31]->[2, 480, 34, 31]
src = self.stages[len(self.depths)-1](src)
return src # [2, 480, 34, 31]
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)解码器
相比而言,Decoder的替换则复杂得多。Decoder的主要作用为对图像特征和Query进行充分的交互,使得Query可以充分感知到图像特征信息,从而对图像中的目标进行坐标和类别的预测。Decoder主要包括两个输入:Encoder的特征输出和一组可学的查询向量(Query)。把Decoder的主要结构分为两个模块:自交互模块(Self-Interaction Module, SIM)和交叉交互模块(Cross-Interaction Module, CIM)。
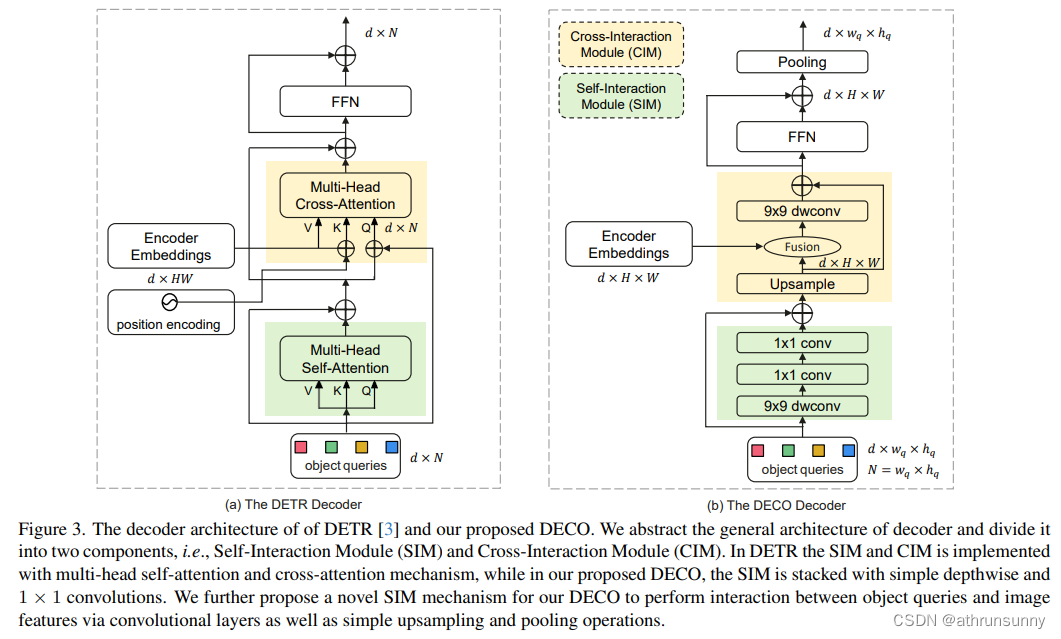
这里,SIM模块主要融合Query和上层Decoder层的输出,这部分的结构,可以利用若干个卷积层来组成,使用9x9 depthwise卷积和1x1卷积分别在空间维度和通道维度进行信息交互,充分获取所需的目标信息以送到后面的CIM模块进行进一步的目标检测特征提取。Query为一组随机初始化的向量,该数量决定了检测器最终输出的检测框数量,其具体的值可以随实际需要进行调节。对DECO来说,因为所有的结构都是由卷积构成的,因此我们把Query变成二维,比如100个Query,则可以变成10x10的维度。
CIM模块的主要作用是让图像特征和Query进行充分的交互,使得Query可以充分感知到图像特征信息,从而对图像中的目标进行坐标和类别的预测。对于Transformer结构来说,利用cross attention机制可以很方便实现这一目的,但对于卷积结构来说,如何让两个特征进行充分交互,则是一个最大的难点。
要把大小不同的SIM输出和encoder输出全局特征进行融合,必须先把两者进行空间对齐然后进行融合,首先我们对SIM的输出进行最近邻上采样:
![]()
使得上采样后的特征与Encoder输出的全局特征有相同的尺寸,然后将上采样后的特征和encoder输出的全局特征进行融合,然后进入深度卷积进行特征交互后加上残差输入:
![]()
最后将交互后的特征通过FNN进行通道信息交互,之后pooling到目标数量大小得到decoder的输出embedding:
![]()
最后将得到的输出embedding送入检测头,以进行后续的分类和回归。
代码示例:
class DecoDecoder(nn.Module):
'''Define Deco Decoder'''
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False, qH=10, qW=10):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
self.qH = qH
self.qW = qW
def forward(self, tgt, memory, bs, d_model, query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output=output.permute(1, 2, 0).view(bs, d_model,self.qH,self.qW)
output = layer(output, memory, query_pos=query_pos)
output=output.flatten(2).permute(2, 0, 1)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
class DecoDecoderLayer(nn.Module):
'''Define a layer for Deco Decoder'''
def __init__(self,d_model, normalize_before=False, qH=10, qW=10,
drop_path=0.,layer_scale_init_value=1e-6):
super().__init__()
self.normalize_before = normalize_before
self.qH = qH
self.qW = qW
# The SIM module
self.dwconv1 = nn.Conv2d(d_model, d_model, kernel_size=9, padding=4, groups=d_model) # Conv2d(480, 480, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4), groups=480)
self.norm1 = LayerNorm(d_model, eps=1e-6)
self.pwconv1_1 = nn.Linear(d_model, 4 * d_model)
self.act1 = nn.GELU()
self.pwconv1_2 = nn.Linear(4 * d_model, d_model)
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones((d_model)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# The CIM module
self.dwconv2 = nn.Conv2d(d_model, d_model, kernel_size=9, padding=4, groups=d_model) # Conv2d(480, 480, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4), groups=480)
self.norm2 = LayerNorm(d_model, eps=1e-6)
self.pwconv2_1 = nn.Linear(d_model, 4 * d_model)
self.act2 = nn.GELU()
self.pwconv2_2 = nn.Linear(4 * d_model, d_model)
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((d_model)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, tgt, memory, query_pos: Optional[Tensor] = None):
# SIM
b, d, h, w = memory.shape # [2, 480, 34, 31]
tgt2 = tgt + query_pos # tgt以及query_pos均由nn.Embedding(100,480)生成,并reshape到[2, 480, 10, 10]
tgt2 = self.dwconv1(tgt2)
tgt2 = tgt2.permute(0, 2, 3, 1) # (b,d,10,10)->(b,10,10,d)
tgt2 = self.norm1(tgt2)
tgt2 = self.pwconv1_1(tgt2) # [2, 10, 10, 480]->[2, 10, 10, 1920]
tgt2 = self.act1(tgt2)
tgt2 = self.pwconv1_2(tgt2) # [2, 10, 10, 1920]->[2, 10, 10, 480]
if self.gamma1 is not None:
tgt2 = self.gamma1 * tgt2
tgt2 = tgt2.permute(0,3,1,2) # (b,10,10,d)->(b,d,10,10)
tgt = tgt + self.drop_path1(tgt2)
# CIM
tgt = F.interpolate(tgt, size=[h,w]) # [2, 480, 10, 10] -> [2, 480, 34, 31]
tgt2 = tgt + memory
tgt2 = self.dwconv2(tgt2)
tgt2 = tgt2+tgt
tgt2 = tgt2.permute(0, 2, 3, 1) # (b,d,h,w)->(b,h,w,d)
tgt2=self.norm2(tgt2)
# FFN
tgt = tgt2
tgt2 = self.pwconv2_1(tgt2) # [2, 34, 31, 480]->[2, 34, 31, 1920]
tgt2 = self.act2(tgt2)
tgt2 = self.pwconv2_2(tgt2) # [2, 34, 31, 1920]->[2, 34, 31, 480]
if self.gamma2 is not None:
tgt2 = self.gamma2 * tgt2
tgt2 = tgt2.permute(0,3,1,2) # (b,h,w,d)->(b,d,h,w)
tgt = tgt.permute(0,3,1,2) # (b,h,w,d)->(b,d,h,w)
tgt = tgt + self.drop_path1(tgt2) # [2, 480, 34, 31]
# pooling
m = nn.AdaptiveMaxPool2d((self.qH, self.qW))
tgt = m(tgt) # [2, 480, 10, 10]
return tgt多尺度特征
跟原始的DETR一样,上述框架得到的DECO有个共同的短板,即缺少多尺度特征,而这对于高精度目标检测来说是影响很大的。Deformable DETR通过使用一个多尺度的可变形注意力模块来整合不同尺度的特征,但这个方法是跟Attention算子强耦合的,因此没法直接用在我们的DECO上。为了让DECO也能处理多尺度特征,我们在Decoder输出的特征之后,采用了RT-DETR提出的一个跨尺度特征融合模块。
实验
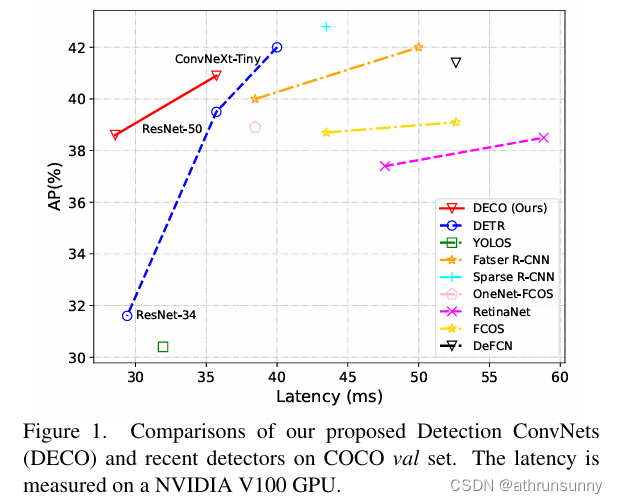
在COCO上进行实验,在保持主要架构不变的情况下将DECO和DETR进行了比较,比如保持Query数量一致,保持Decoder层数不变等,仅将DETR中的Transformer结构按上文所述换成卷积结构。可以看出,DECO取得了比DETR更好的精度和速度的Trade-off。
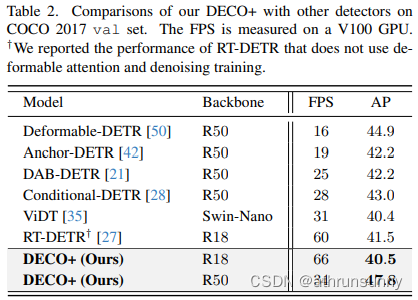
把搭配了多尺度特征后的DECO跟更多目标检测方法进行了对比,其中包括了很多DETR的变体,从下图中可以看到,DECO取得了很不错的效果,比很多以前的检测器都取得了更好的性能。