接上篇 【目标检测】1. 目标检测概述_目标检测包括预测目标的位置吗?-CSDN博客
一、前言
CVPR201 4经典paper:《 Rich feature hierarchies for accurate object detection and semantic segmentation》,https://arxiv.org/abs/1311.2524, 这篇论文的算法思想被称为R- CNN(Regions with Convolutional Neural Network Features),该算法思想更改了物体检测的总思路,现在很多物体检测算法均基于该算法。简单来讲: R-CNN是一种基于Region Proposal的CNN网络结构。
R-CNN算法中采用和传统目标检测类似的执行过程,主要包含以下几个步骤:
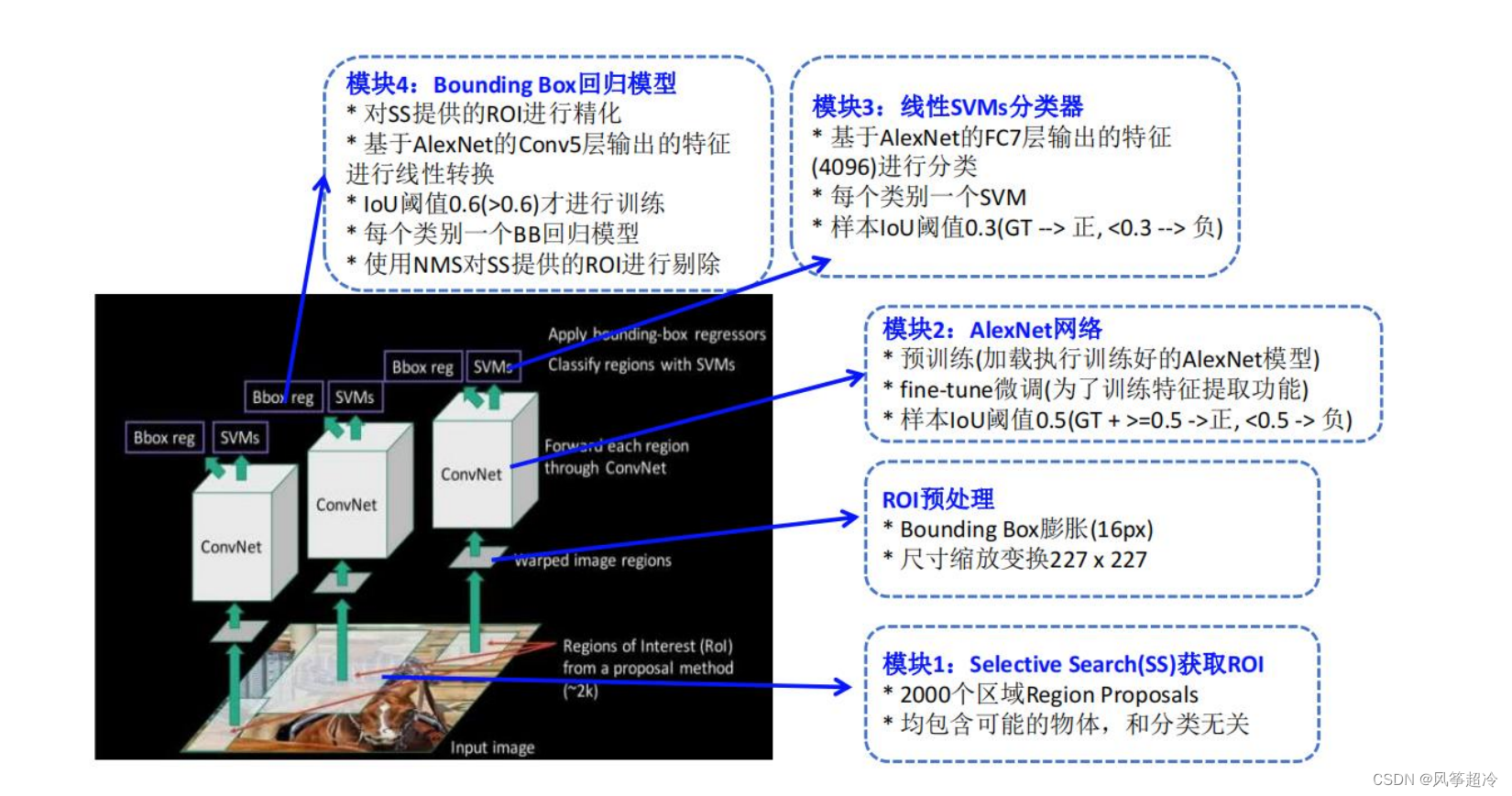
1.区域提名(Region Proposal): 通过区域提名的方法从原始图片中提取2000个左右的区域候选框,一般选择Selective Search(SS);
2.区域大小归一化:将所有候选框大小缩放固定大小(eg:227*227);
3.特征提取: 通过CNN网络,对每个候选区域框提取高阶特征;
4.分类与回归:在高阶特征的基础上添加两个全连接层,再使用SVM分类器来进行识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归器。
二、目标检测中的 one stage 和 two stage:
目标检测是计算机视觉领域中的一项关键任务,它的目标是识别出图像中所有感兴趣的目标的类别和位置。目标检测算法大体上可以分为两大类:单阶段(one stage)和双阶段(two stage)。
Two-Stage目标检测
双阶段目标检测算法,如R-CNN系列(包括Fast R-CNN, Faster R-CNN等),通常由两个主要步骤组成:
-
区域提议(Region Proposal): 第一阶段是生成区域提议,这些提议是可能包含目标的图像区域。在Faster R-CNN中,这个步骤由区域提议网络(Region Proposal Network, RPN)完成,它会对整个图像进行扫描,找出可能包含目标的区域。
-
目标检测(Detection): 第二阶段是在每个提议的区域上运行分类器来确定区域的类别,并调整区域的边界框(bounding box),以准确地框住目标。这一步骤通常涉及特征抽取、分类和边界框回归。
双阶段方法通常准确度较高,因为它们在细致的区域上进行了分类和回归,但这也导致了较慢的推理速度。
One-Stage目标检测
单阶段目标检测算法,如YOLO(You Only Look Once)和SSD(Single Shot Multibox Detector),旨在简化检测流程,通过单个网络直接进行目标的分类和边界框预测。
-
直接检测: 单阶段方法没有区域提议这个步骤,而是直接在图像的各个位置上预测目标类别和边界框。这通常通过在图像上滑动窗口,一次性预测多个区域的方法实现。
-
分类与回归合并: 这些算法通常使用一个单一的卷积网络同时预测边界框和类别概率,这使得推理速度非常快。
单阶段方法的优点是速度快,能够实现实时检测,但可能牺牲一些准确度,尤其是在目标尺寸变化较大的情况下。
两种方法各有优缺点:
- Two-Stage: 更准确,适用于需要高精度检测的场景,但速度较慢。
- One-Stage: 速度快,适用于对实时性要求较高的应用,但在精度上可能稍逊于双阶段方法。
三、迁移学习

上图展示了神经网络模型用于图像分类的过程。网络模型包含多个层次,每个层次完成不同的计算任务。这个过程可分为几个主要部分:
-
卷积和池化(Convolution and Pooling):
- 这些层负责从输入图像中提取特征。卷积层使用一组可学习的滤波器来检测图像中的局部特征,例如边缘、颜色或纹理等。
- 池化层(也称为子采样或下采样)减少数据的维度和复杂性,增加特征检测的不变性。
-
最终的卷积特征图(Final conv feature map):
- 经过多个卷积和池化层后,最终的卷积特征图包含图像的高级特征。这些特征将用于分类任务。
-
全连接层(Fully-connected layers):
- 这些层基于卷积特征图做出决策。全连接层的每个神经元都与前一层的所有神经元相连接。它们将特征图“展平”成一维数组,然后用来学习特征之间的复杂关系。
-
类别得分(Class scores):
- 在最初的设置中,网络模型可能被设计为识别1000个不同的类别(例如,使用ImageNet数据集训练的模型)。这意味着最后一个全连接层将输出一个1000维的向量,其中每个维度代表图像属于特定类别的概率。
-
Softmax损失(Softmax loss):
- Softmax损失函数用于计算网络输出和实际标签之间的差异。训练过程中通过最小化这个损失值来更新网络权重,从而提高模型的分类性能。
图2中重新初始化最后一个全连接层的维度,从原来的1000个类别修改为21个类别,这通常是为了适应一个新的特定任务,以满足只有20个对象类别加上背景类共21个类别的目标检测任务。重新初始化这一层意味着原来的权重将被放弃,新的权重维度将用于新的分类任务。这个过程被称为迁移学习,即利用一个在大型数据集上预训练的模型,并将其适应到一个新的相似任务上。
四、RCNN实现目标检测步骤
- 步骤一:利用Selective Search得到若干候选区域(所有可能是物体的区域);
- 步骤二:对于每个候选区域(2k、缩放变换)分别使用CNN提取高阶特征向量;
- 步骤三:对于每个候选区域提取的高阶特征向量使用SVM进行分类(二分类);
- 步骤四:精准定位(回归器);
- 步骤五:使用非极大值抑制剔除重复框。
4.1 步骤二 对于每个候选区域(2k、缩放变换)
使用padding(真实内容填充、特殊值填充)、缩放等操作,将候选区域转换为227* 227的图像大小。

图7:不同的目标提案转换。 (A) 实际尺度相对于变换的CNN输入的原始目标提案; (B) 带上下文的最紧凑正方形; (C) 不带上下文的最紧凑正方形,使用灰色填充; (D) 变形。在每列和示例提案中,顶行对应于 p = 0 像素的上下文填充,而底行有 p = 16 像素的上下文填充。
“上下文填充”指的是在目标周围额外添加的像素区域,以便提供更多背景信息。在目标检测任务中有助于改善模型对目标物体的理解。
4.2 步骤二 使用CNN提取高阶特征向量
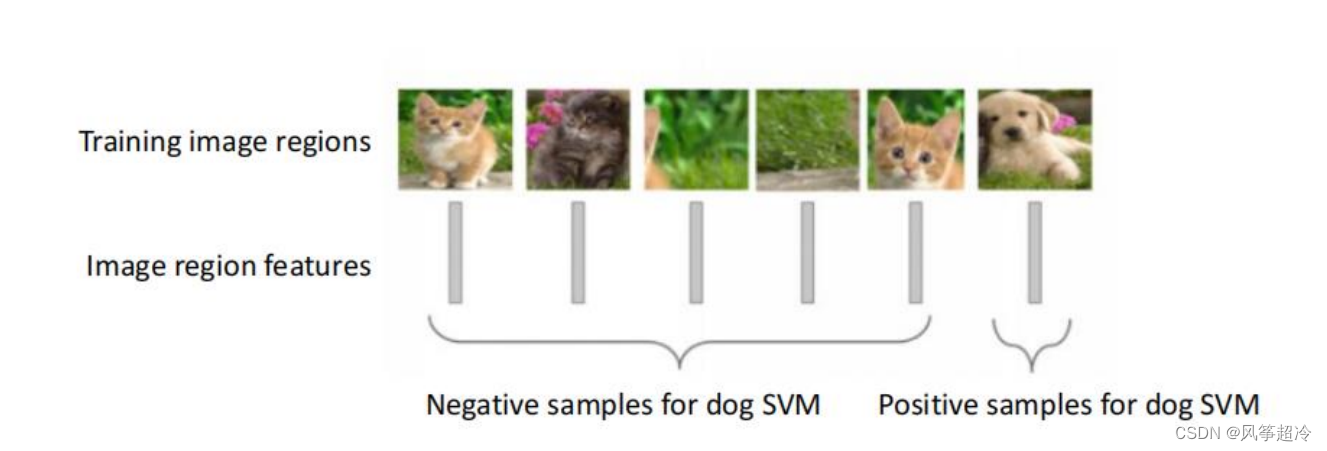
对于进行大小缩放的ROI区域图,使用CNN网络提取出区域图像对应的高阶特征信息(FC7层),然后使用SVM算法将其划分为两个类别:
正样本:包含当前类别的区域图像
负样本:不包含当前类别的区域图像
4.3 步骤三 对每个候选区域提取的高阶特征向量使用SVM进行分类(二分类)
对于进行大小缩放的ROI区域图像,使用CNN网络提取出区域图像对应的高阶特征信息(Conv5层),使用回归器(全连接神经网络)精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
4.4 步骤四 精准定位(回归器)
对于进行大小缩放的ROI区域图像,使用CNN网络提取出区域图像对应的高阶特征信息(Conv5层),使用回归器(全连接神经网络)精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。

为了进一步的提高定位的精确率,引入Bounding Box Regression(BBR)进行定位边框的微调。

如上图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为Selective Search算法得出的建议框,即Region Proposal。即使黄色框中物体,被分类器识别为卡宴车辆,但是由于绿色框和黄色框loU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与Ground Truth更接近,以提高最终的检测精度。
五、深度理解RCNN模型
在RCNN模型训练中,主要有以下几点:
- 直接使用AlexNet(AlexNet是一个影响深远的卷积神经网络(CNN),它在2012年赢得了ImageNet大规模视觉识别挑战赛(ILSVRC)的冠军。)作为前面的特征提取预训练模型;
- 将AlexNet的最后- 层替换成N+ 1个输出神经元的CNN softmax模型,然后使用fine-tuning训练(Fine-tuning,或细调,是一种深度学习技术,通常用于将预训练模型(已经在一个大型和广泛的数据集上训练过的模型)调整到特定任务上。),batch_ size为128,其中32个正样本,96个负样本。最终得到当前任务上的特征提取网络。
- 在SVM训练阶段,假设要检测车辆,Ground Truth的Bounding Box当做正样本,和Ground Truth重叠IOU值低于0.3的bounding box当做负样本。比如提取出2000个候选框,然后高特征维度为4096,也就是可以得到一个2000*4096的特征向量矩阵,那么这个时候只需要训练一个4096*N的权重 系数W就可以完成SVM的训练(N为分类类别数目)。
为什么在CNN softmax模型训练之外, 需要单独训练一个SVM分类器呢?
- 这是因为svm训练和cnn训练过程中的正负样本定义方式不同,导致CNN softmax的输出比采用svm的精度低。在CNN softmax中,将IOU大于等于0. 5的当做正样本,I0U小于0.5的当做负样本;而在SVM中,将Ground Truth当做正样本,I0U小于0.3的当做负样本。
- SVM分类器训练过程中,采用标准的hard negative mining方式进行训练,即:难负例挖掘算法,用途就是解决正负例数量不均衡,而负例分散代表性又不够的问题,hard negative就是每次把那些顽固的棘手的错误的样本,再送回去继续练,练到你的成绩不再提升为止,这一个过程就叫做"hard negative mining"。
- CNN softmax模型的分类识别能力比较强,鲁棒性会更强(泛化能力更强,也就是对于区域中仅包含部分轮廓的情况,也可以产生一个当前类别的预测), 对于精准的定位效果就不会特别的好。
六、RCNN提高定位精度的方式Bounding Box Regression
为了进一步的提高定位的精确率,引入Bounding Box Regression(BBR)进行定位边框的微调。
如上图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为Selective Search算法得出的建议框,即Region Proposal。即使黄色框中物体,被分类器识别为卡宴车辆,但是由于绿色框和黄色框loU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与Ground Truth更接近,以提高最终的检测精度。
如下图,黄色框口P表示建议框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口G^表示Region Proposal进行回归后的预测窗口,现在的目标是找到P到G ^的线性变换。

相较于P, G^的中心坐标和长宽都会发生变换,变换公式及步骤如下:
Region Proposal窗口表示
分别表示中心点坐标横轴值、中心点坐标纵轴值、窗口宽度、窗口高度。
Ground Truth窗表示:
Region Proposal进行回归转换后的窗口表示:
定义四种变换函数,其中中心点通过对x和y进行平移变换得到,宽度w和高度h通过进行缩放变换得到。计算公式如下所示:
结合上述转换函数,我们的目的是要求线性转换之后的边框和实际边框非常接近,那
么也就是目标转换系数为(也就是模型训练值<offset box,位置偏移量> ):
每一个 (*表示x、y、W、h)都是CNN网络的高阶特征提取值(Conv5层)的线性转换函数,即:
这里的w即需要学习的回归参数,损失函数如下:
为了提高样本框回归训练的有效性,对于每类样本中采用与Ground Truth相交loU大于0.6的Region Proposal作为样本对(P,G)进行BBR的训练。之所以选择loU大于0.6的进行回归微调,其主要原因是如果边框间隔太远,那么其转换关系可能就不是线性转换,使用线性转换的方式效果显著。对于每个类别均训练一个BBR线性转换结构。也就是RCNN中最终由N个BBR线性转换。
Bounding Box 回归后性能比较
在迁移学习中BB的性能优势

七、总结
RCNN深度学习应用目标的奠基者:
- R-CNN采用AlexNet;
- R-CNN采用Selective Search技术生成Region Proposal;
- R-CNN在ImageNet_上先进行预训练,然后利用成熟的权重参数在PASCAL VOC数据集上进行fine-tune;
- R-CNN用CNN抽取特征,然后用一系列的的SVM做类别预测;
- R-CNN的bbox位置回归基于DPM的灵感,基于R-CNN提取出来的特征训练了一个线性回归模型;
RCNN缺陷:
R-CNN已经不是最先进的目标检测模型,但是它是深度学习应用目标检测的奠基者,在
RCNN中的很多缺陷问题,也在后续的目标检测网络结构中得以解决,其主要问题如下:
- 重复计算: R-CNN虽然不再是穷举,但依然有两千个左右的候选框,这些候选框都需要进行CNN操作,计算量依然很大,其中有不少其实是重复计算;
- 训练测试分为多步:区域提名、特征提取、分类、回归都是断开的训练的过程,中间数据还需要单独保存;
- 训练的空间和时间代价很高:卷积出来的特征需要先存在硬盘上,这些特征需要几百G的存储空间;
- 执行效率慢: GPU上处理一张图片需要13秒,CPU_上则需要53秒。
欢迎加入,目标检测学习群: