行人检测计数系统是一种重要的智能交通监控系统,它能够通过图像处理技术对行人进行实时检测、跟踪和计数,为城市交通规划、人流控制和安全管理提供重要数据支持。本系统基于先进的YOLOv8目标检测算法和PyQt5图形界面框架开发,具有高效、准确、易用等特点。
系统特点
- 基于YOLOv8的目标检测算法:YOLOv8是一种高效的目标检测算法,它能够在保证检测速度的同时,提高检测精度。本系统采用YOLOv8算法对行人进行检测,能够快速准确地识别出行人的位置,并进行计数。
- PyQt5图形界面框架:PyQt5是一种功能强大的图形界面开发框架,它支持跨平台开发,具有良好的可移植性。本系统采用PyQt5框架开发,界面简洁明了,易于操作。
- 支持多种检测方式:本系统支持对单张图片、视频文件和摄像头实时流进行检测。用户可以根据需要选择不同的检测方式,满足不同的应用场景。
- GPU加速功能:本系统支持GPU加速功能,可以将预测计算任务分配到GPU上进行处理,提高系统的实时检测性能。相比在CPU上进行处理,GPU加速可以大幅度降低延时,提升用户体验。
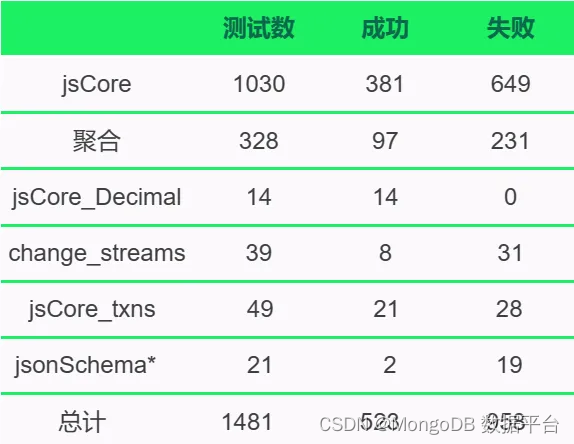
本文介绍了基于深度学习yolov8的行人检测计数系统,包括训练过程和数据准备过程,同时提供了推理的代码和GUI。对准备计算机视觉相关的毕业设计的同学有着一定的帮助。
模型在线体验:https://o554w00336.goho.co/
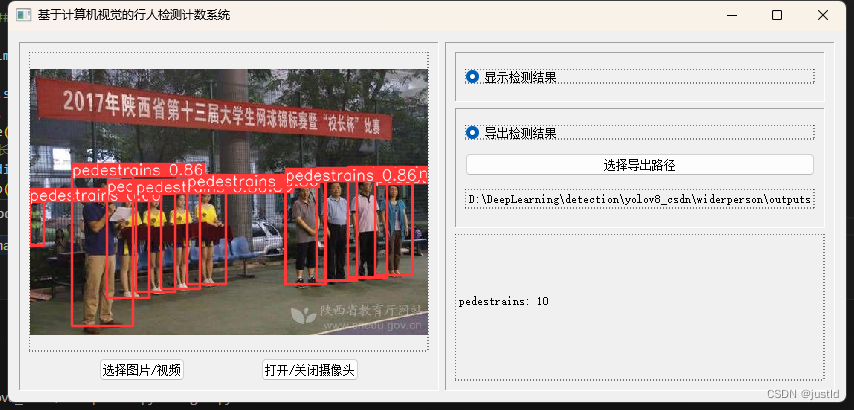
检测结果如下图:


一、安装YoloV8
yolov8官方文档:主页 - Ultralytics YOLOv8 文档
安装部分参考:官方安装教程
1、安装pytorch
根据本机是否有GPU,安装适合自己的pytorch,如果需要训练自己的模型,建议使用GPU版本。
①GPU版本的pytorch安装
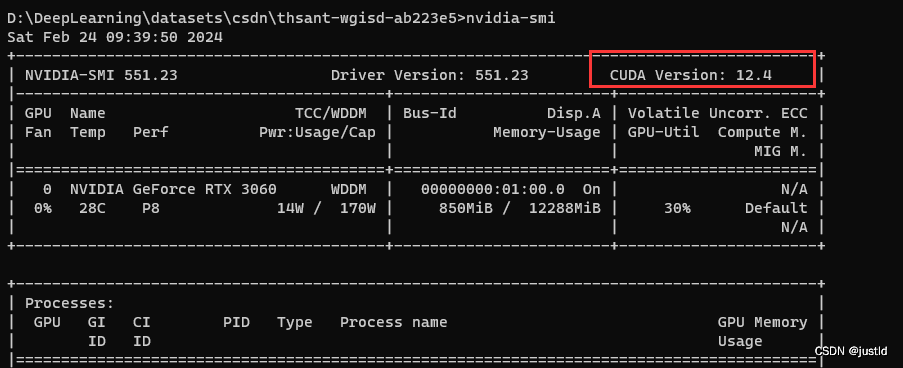
对于GPU用户,安装GPU版本的pytorch,首先在cmd命令行输入nvidia-smi,查看本机的cuda版本,如下图,我的cuda版本是12.4(如果版本过低,建议升级nvidia驱动):
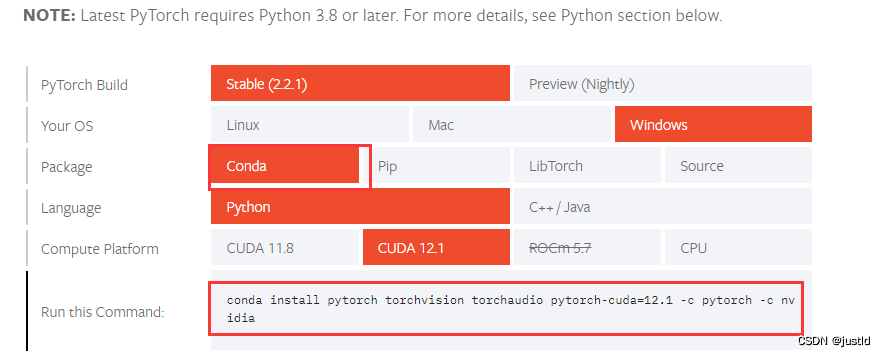
打开pytorch官网,选择合适的版本安装pytorch,如下图,建议使用conda安装防止cuda版本问题出现报错:
②CPU版本pytorch安装
打开pytorch官网,选择CPU版本安装pytorch,如下图:

2、安装yolov8
在命令行使用如下命令安装:
pip install ultralytics二、数据集准备
本文数据集来自http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/
该数据集包含8000个训练数据,1000个验证数据,4382个测试数据,数据如下图:


为了使用yolov8算法进行训练,需要将该数据转换为yolov8格式,本文提供转换好的数据集下载连接:widerperson(密集行人检测)yolov8格式数据集,该数据集8000个训练数据,1000个验证数据,4382个测试数据
三、模型配置及训练
1、数据集配置文件
创建数据集配置文件rsna_pneumonia.yaml,内容如下(将path路径替换为自己的数据集路径):
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: yolo train data=coco.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:\DeepLearning\datasets\csdn\widerperson\widerperson_yolov8 # 替换为自己的数据集路径
train: images/train
val: images/val
test: images/val
# Classes
names:
# 0: normal
0: pedestrains2、训练模型
使用如下命令训练模型,数据配置文件路径更改为自己的路径,model根据自己的需要使用yolov8n/s/l/x版本,其他参数根据自己的需要进行设置:
yolo detect train project=widerperson name=train exist_ok data=widerperson/widerperson.yaml model=yolov8n.yaml epochs=100 imgsz=480
3、验证模型
使用如下命令验证模型,相关路径根据需要修改:
yolo detect val project=widerperson name=val imgsz=480 model=widerperson/train/weights/best.pt data=widerperson/widerperson.yaml
精度如下:
# Ultralytics YOLOv8.1.20 🚀 Python-3.9.18 torch-2.2.0 CUDA:0 (NVIDIA GeForce RTX 3060, 12288MiB)
# YOLOv8n summary (fused): 168 layers, 3005843 parameters, 0 gradients, 8.1 GFLOPs
# val: Scanning D:\DeepLearning\datasets\csdn\widerperson\widerperson_yolov8\labels\val.cache... 1000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 1000/1000 [00:00<?, ?it/s]
# Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:08<00:00, 7.15it/s]
# all 1000 27353 0.813 0.606 0.722 0.452
# Speed: 0.1ms preprocess, 2.6ms inference, 0.0ms loss, 1.3ms postprocess per image
# Results saved to widerperson\val
# 💡 Learn more at https://docs.ultralytics.com/modes/val四、推理
训练好了模型,可以使用如下代码实现推理,权重路径修改为自己的路径:
from PIL import Image
from ultralytics import YOLO
# 加载预训练的YOLOv8n模型
model = YOLO('best.pt')
image_path = 'test.jpg'
results = model(image_path) # 结果列表
# 展示结果
for r in results:
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像
im.show() # 显示图像
im.save('results.jpg') # 保存图像五、界面开发
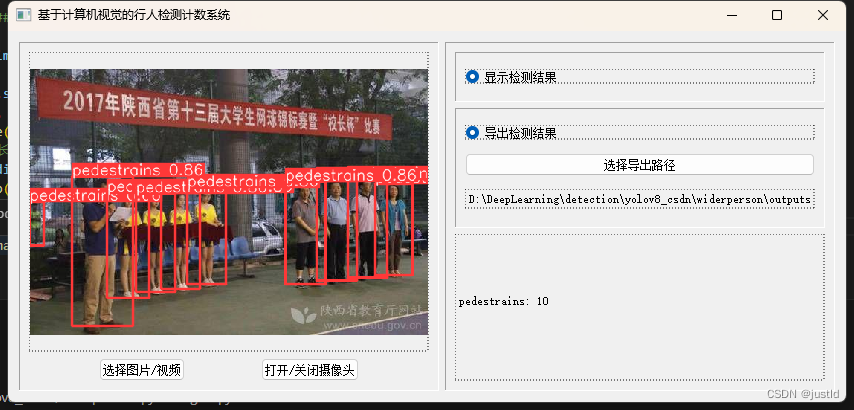
使用pyqt5开发gui界面,支持图片、视频、摄像头输入,支持导出到指定路径,其GUI如下图(完整GUI代码可在下方链接下载):
代码下载连接:基于yolov8的行人检测系统,包含训练好的权重和推理代码,GUI界面,支持图片、视频、摄像头输入,支持检测结果导出