1、动作检测 DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
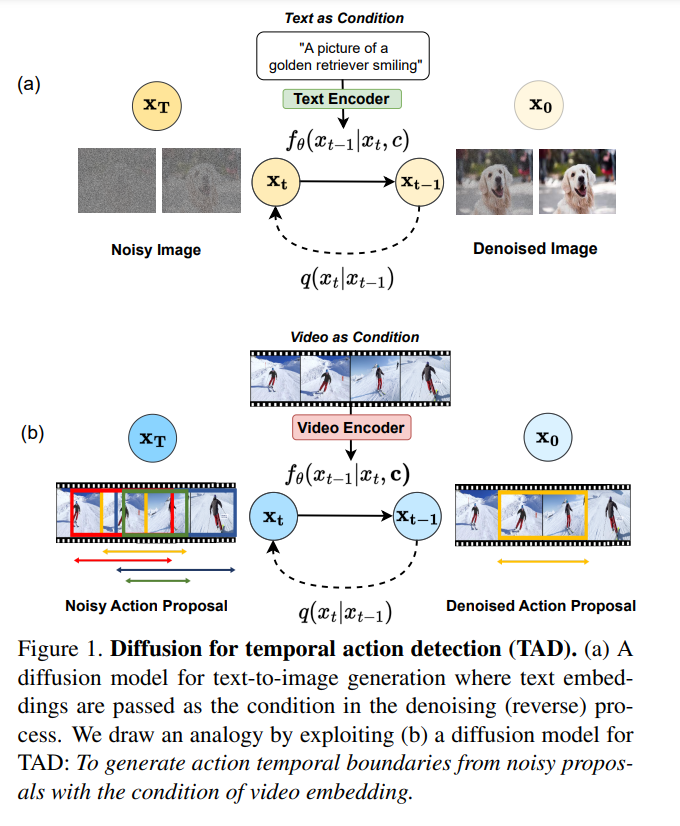
基于扩散方法提出一种新的时序动作检测(TAD)算法,简称DiffTAD。以随机时序proposals作为输入,可以在未修剪的长视频中准确生成动作proposals。从生成建模的视角,与先前的判别学习方法不同。
首先将真实proposals从正向扩散到随机proposals(即前向/噪声过程),然后学习逆转噪声过程(即反向/去噪过程)来实现这种能力。通过在Transformer解码器(如DETR)中引入具有更快收敛性的时间位置查询设计来建立去噪过程。进一步提出一种用于推理加速的交叉步选择条件算法。
在ActivityNet和THUMOS上的大量评估表明,与先前的方法相比,DiffTAD实现了最佳性能。已开源在:https://github.com/sauradip/DiffusionTAD
2、目标检测 DiffusionDet: Diffusion Model for Object Detection
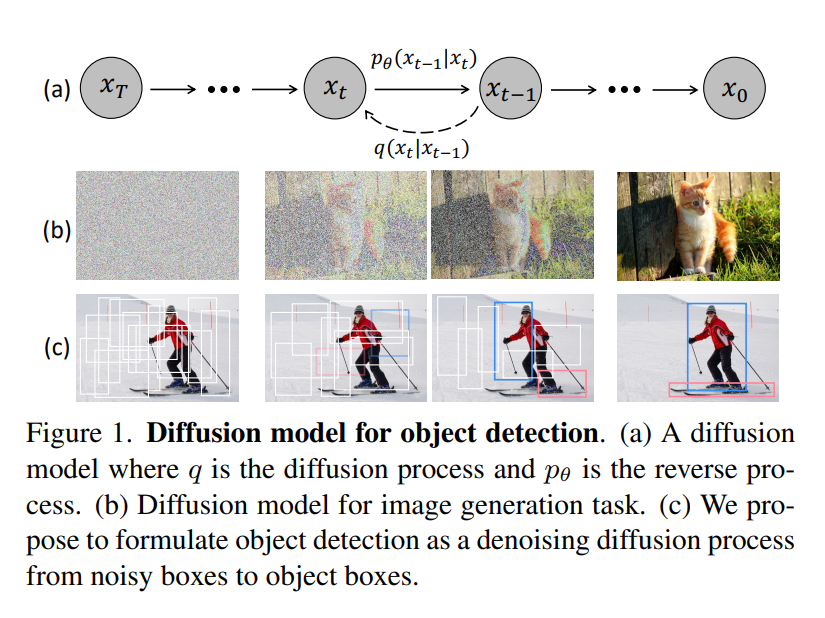
提出DiffusionDet,一种将目标检测作为从噪声框到目标框的去噪扩散过程的新框架。在训练阶段,目标框从真实边界框扩散到随机分布,模型学习逆转这个噪声过程。在推理中,模型以渐进的方式将一组随机生成的边界框优化到输出结果中。
方法具有灵活性的吸引力,可以动态调整边界框的数量和迭代评估。在标准基准测试中进行的广泛实验表明,与先前的成熟检测器相比,DiffusionDet取得了有利的性能。例如,在从COCO到CrowdHuman的零样本迁移设置下,DiffusionDet在较多的边界框和迭代步骤下分别达到了5.3 AP和4.8 AP的增益。已开源在:https://github.com/ShoufaChen/DiffusionDet
3、异常检测 Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
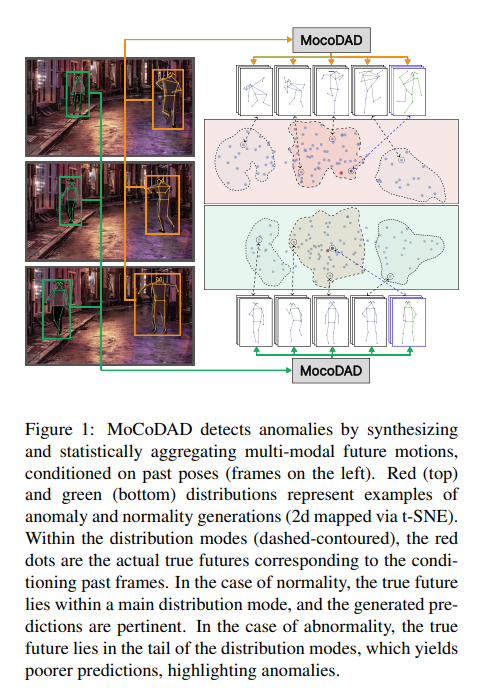
异常情况很少见,因此异常检测通常作为单分类(OCC)来构造,即仅在正常情况下进行训练。提出了一种新的视频异常检测(VAD)生成模型,假设正常和异常都是多模态的。考虑骨骼表示,并利用最先进的扩散概率模型生成多模态的未来人体姿势。对人的过去动作进行了新的条件化,并利用扩散过程的改进模式覆盖能力生成不同但可靠的未来运动。
通过对未来模态进行统计聚合,当生成的一组运动与实际未来不相关时,检测到异常。在四个已建立的基准测试:UBnormal,HR-UBnormal,HR-STC和HR-Avenue上验证模型,并进行广泛实验,结果超过现有技术水平。已开源在:https://github.com/aleflabo/MoCoDAD
4、异常检测 DIFFGUARD: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
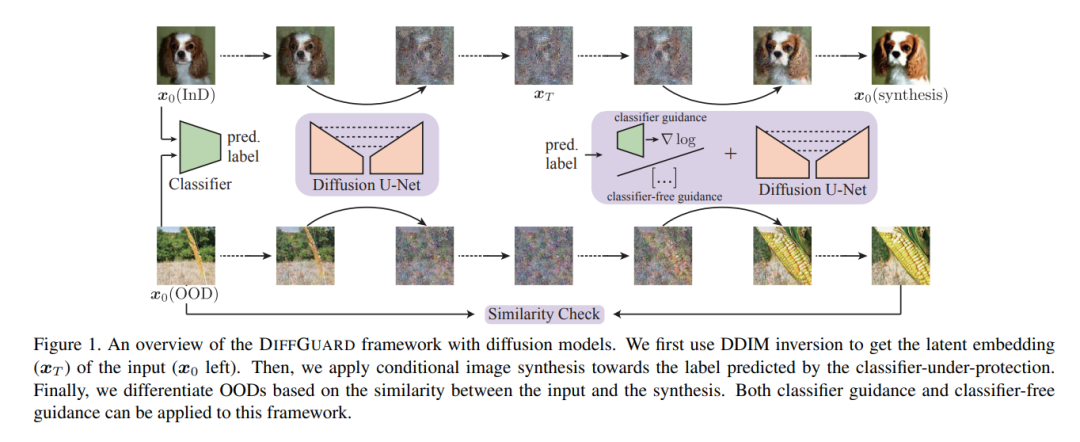
给定一个分类器,语义上的Out-of-Distribution(OOD)样本的固有属性是其内容与所有合法类别在语义上有所不同,即语义不匹配。最近工作将其直接应用于OOD检测,该方法采用条件生成对抗网络(cGAN)来扩大图像空间中的语义不匹配。尽管在小型数据集上取得一些效果,但对于IMAGENET规模的数据集来说,由于训练同时具备输入图像和标签作为条件的cGAN的困难,该方法不适用。
鉴于扩散模型比cGANs更易于训练和适用于各种条件,本研究提出一种名为DIFFGUARD的方法,直接利用预训练扩散模型进行语义不匹配引导的OOD检测。具体而言,给定一个OOD输入图像和分类器的预测标签,扩大在这些条件下重建的OOD图像与原始输入图像之间的语义差异。还提出一些测试时的技术来进一步增强这种差异。
实验证明,DIFFGUARD对于CIFAR-10和大规模IMAGENET的复杂案例都很有效,并且可以与现有的OOD检测技术轻松结合,达到最先进的OOD检测结果。已开源在:https://github.com/cure-lab/DiffGuard
5、异常检测 Feature Prediction Diffusion Model for Video Anomaly Detection
在视频中进行异常检测,是一个重要的研究领域和实际应用中的挑战性任务。由于缺乏大规模标注的异常事件样本,大多数现有的视频异常检测(VAD)方法侧重于学习正常样本的分布,以检测明显偏离的异常样本。为学习正常运动和外观的分布,许多辅助网络被用于提取前景对象或动作信息。这些高级语义特征可以有效地过滤背景噪声,减少其对检测模型的影响。然而,这些额外的语义模型的能力严重影响了VAD方法的性能。
受扩散模型(DM)启发,本研究引入一种基于DM的新方法来预测用于异常检测的视频帧特征。目标是在不涉及任何额外高级语义特征提取模型的情况下学习正常样本的分布。为此,构建两个去噪扩散隐式模块来预测和改善特征。第一个模块专注于特征运动学习,最后一个模块专注于特征外观学习。
这是第一个基于DM的VAD帧特征预测方法。扩散模型的强大能力使方法能比非DM的特征预测VAD方法更准确地预测正常特征。实验证明,方法在具有挑战性的MVTec数据集上实现了最先进的性能,特别是在定位精度上。
6、异常检测 Unsupervised Surface Anomaly Detection with Diffusion Probabilistic Model
无监督表面异常检测,仅用无异常的训练样本来发现和定位异常模式。基于重建的模型是最受欢迎和成功的方法之一,其依赖于异常区域更难重建的假设。然而,这种方法在实际应用中面临三个主要挑战:1)需要进一步改进重建质量,因为它对最终结果有很大影响,特别是对于具有结构变化的图像;2)观察到对于许多神经网络,异常样本也可以很好地重建,这严重违反了基本假设;3)由于重建是一个病态问题,一个测试实例可能对应多个正常模式,但大多数当前的基于重建的方法忽略了这个关键事实。
本文提出DiffAD,一种基于潜在扩散模型的无监督异常检测方法,受到其生成高质量和多样化图像的能力的启发。进一步提出噪声条件嵌入和插值通道来解决常规重建流程中所面临的挑战。广泛实验证明,方法在具有挑战性的MVTec数据集上实现最先进的性能,特别是在定位准确性方面。
7、图像检测deepfake相关 DIRE for Diffusion-Generated Image Detection
扩散模型在视觉生成方面取得成功,但也引发了可能滥用于恶意目的的担忧。本文旨在构建一个检测器,用于区分真实图像和扩散生成的图像。发现现有的检测器很难检测到由扩散模型生成的图像,即使在它们的训练数据中包括了来自特定扩散模型生成的图像。
为解决这个问题,提出一种新的图像表示方法,称为扩散重构误差(DIRE),它通过预训练的扩散模型来衡量输入图像及其重构对应物之间的误差。观察到,扩散生成的图像可以通过扩散模型进行近似重构,而真实图像则不能。这提供了一个线索,表明DIRE可以作为区分生成图像和真实图像的桥梁。DIRE为检测大多数扩散模型生成的图像提供了一种有效的方法,并且适用于检测来自未知扩散模型的生成图像,并且能够抵抗各种扰动。
此外,建立一个扩散生成基准,包括由各种扩散模型生成的图像,以评估扩散生成的图像检测器的性能。在收集的基准上进行了大量实验证明,DIRE优于先前的生成图像检测器。已开源在:https://github.com/ZhendongWang6/DIRE

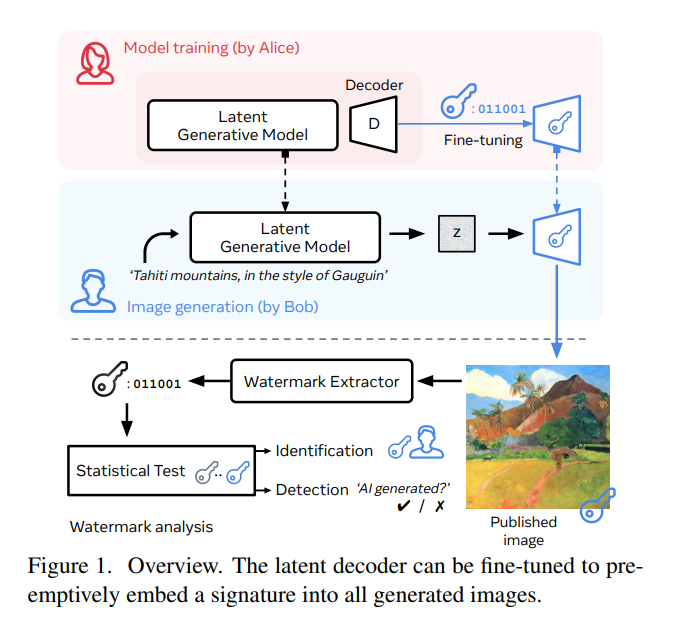
8、图像检测deepfake相关 The Stable Signature: Rooting Watermarks in Latent Diffusion Models
生成图像可实现广泛应用,但也引发了关于负责、伦理关注。引入一种结合图像水印和潜在扩散模型的主动内容追踪方法。其目标是使所有生成的图像都隐藏了一个不可见的水印,以便未来进行检测和/或识别。
该方法通过对二进制签名进行条件化,快速调整图像生成器的潜在解码器。一个预训练的水印提取器从任何生成的图像中恢复出隐藏的签名,然后经过统计检验确定其是否来自生成模型。评估了水印在各种生成任务上的隐形性和稳健性,并显示出稳定签名对图像修改具有较高的鲁棒性。例如,它可以检测到从文本提示生成的图像的来源,然后截取其中10%的内容,以90+%的准确率在误报率低于10^(-6)时进行检测。https://github.com/facebookresearch/stable_signature
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!