文章目录
- 1. RCNN
- 2. Fast-RCNN
- 3. Faster-RCNN
1. RCNN
论文:Rich feature hierarchies for accurate object detection and semantic segmentation
地址:https://arxiv.org/abs/1311.2524
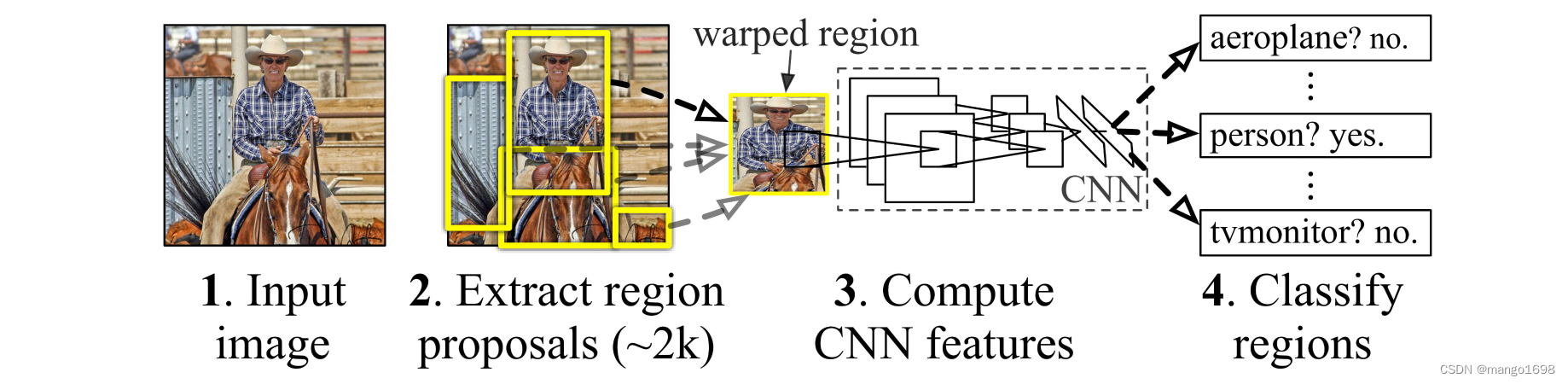
分为两个阶段:
- 目标候选框
Object Proposals - Proposals缩放后放入CNN网络
目标候选框的实现:区域提案方法(Extract region proposals):使用选择性搜索selective search提取2000个候选区域,经过得到的(x',y',w',h')与现实标注(x,y,w,h)以欧式距离损失做回归
对候选框bounding box进行评分和整合。
selective search
使用一种过分隔方法,将图片分隔成比较小的区域
计算所有临近区域之间的相似性,包括颜色、纹理、尺度等
将相似度比较高的区域合并到一起
计算合并区域和临近区域到相似度
迭代合并,知道整个图片变成一个区域。

在选取候选框的时候,除了选择性搜索,还可以使用边缘框edge boxes的方法。

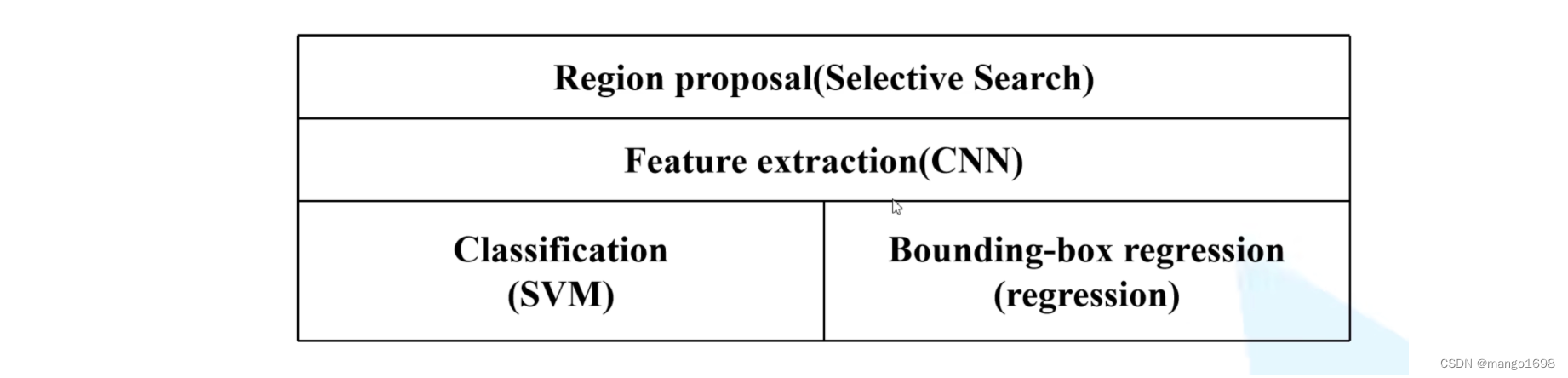
RCNN过程
- 一张图像生成1000到2000个候选区域(使用selective search方法)
- 对每个候选区域,使用深度网络提取特征(卷积池化)
- 特征送入每一类SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
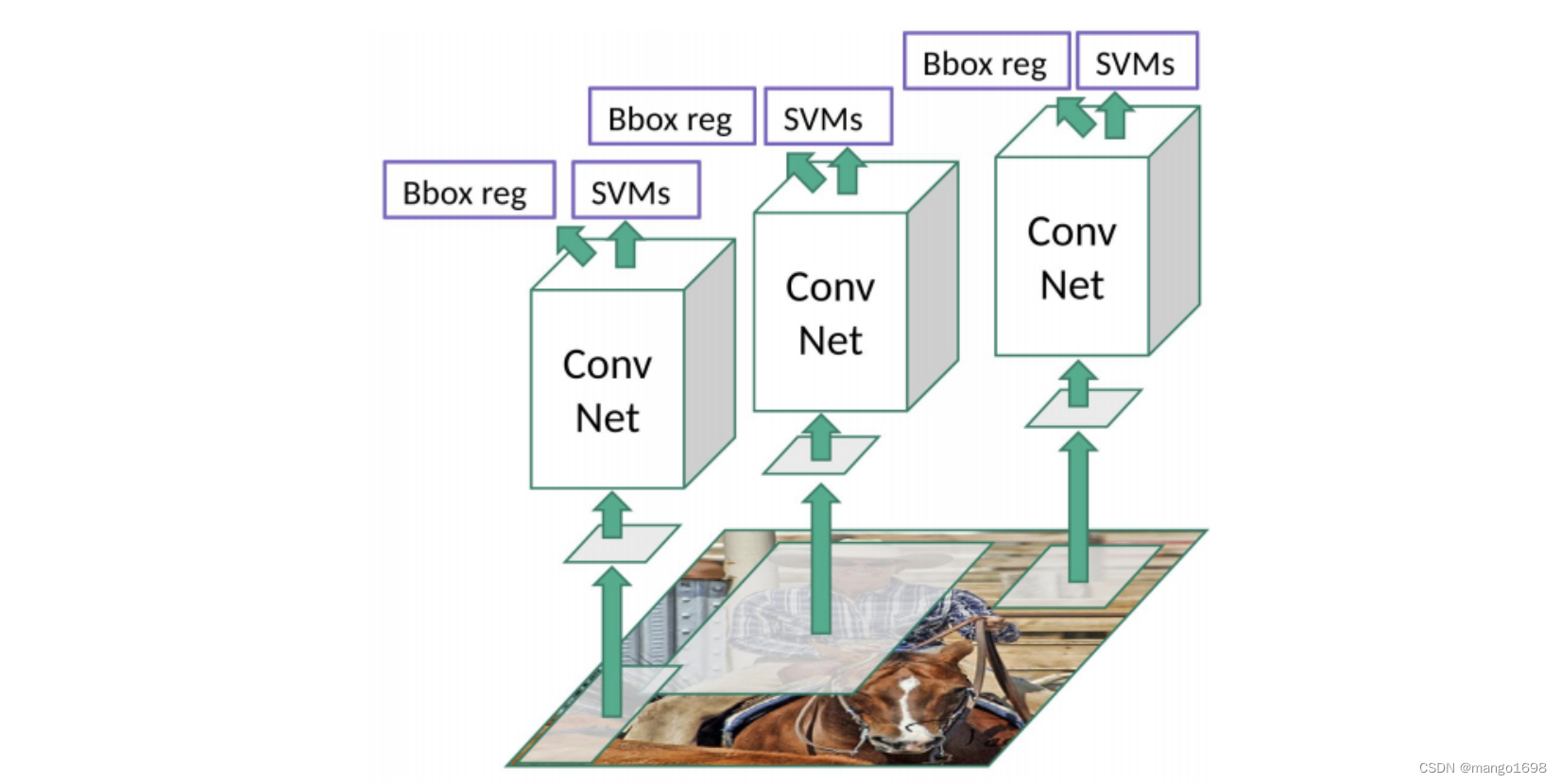
不是一个端到端的结构,整体结构比较松散。
-
候选区域的生成
利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
-
对每个候选区域,使用深度网络提取特征
将2000个候选区域缩放到 277 × 277 p i x e l 277\times 277 pixel 277×277pixel,接着将候选区域输入事先训练好的AlexNet CNN网络中,获取4096维到特征,得到 2000 × 4096 2000\times 4096 2000×4096维矩阵。
-
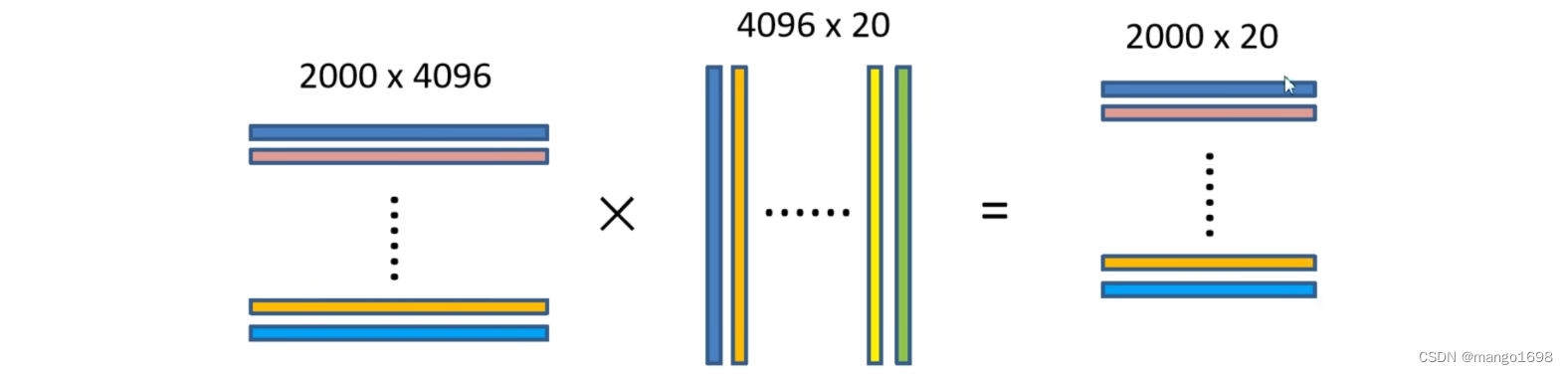
特征送入每一类的SVM分类器,判定类别
将 2000 × 4096 2000\times4096 2000×4096维特征与20个SVM组成的权值矩阵 4096 × 20 4096\times20 4096×20相乘,获得 2000 × 20 2000\times20 2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述 2000 × 20 2000\times20 2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
-
使用回归器精细修正候选框位置 - 依然是针对CNN输出的特征向量进行预测
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
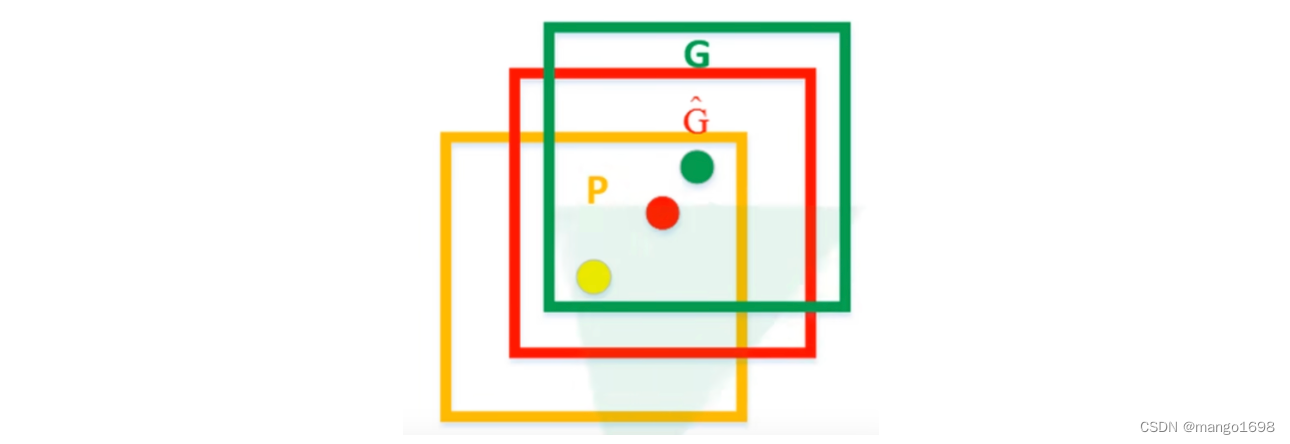
如图,黄色框口P表示建议框Region Proposal,绿色窗口G表示世纪框Ground Truth,红色窗口 G ^ \hat G G^表示Region Proposal进行回归后的预测窗口,可以用最小二乘法解决的线性回归问题。
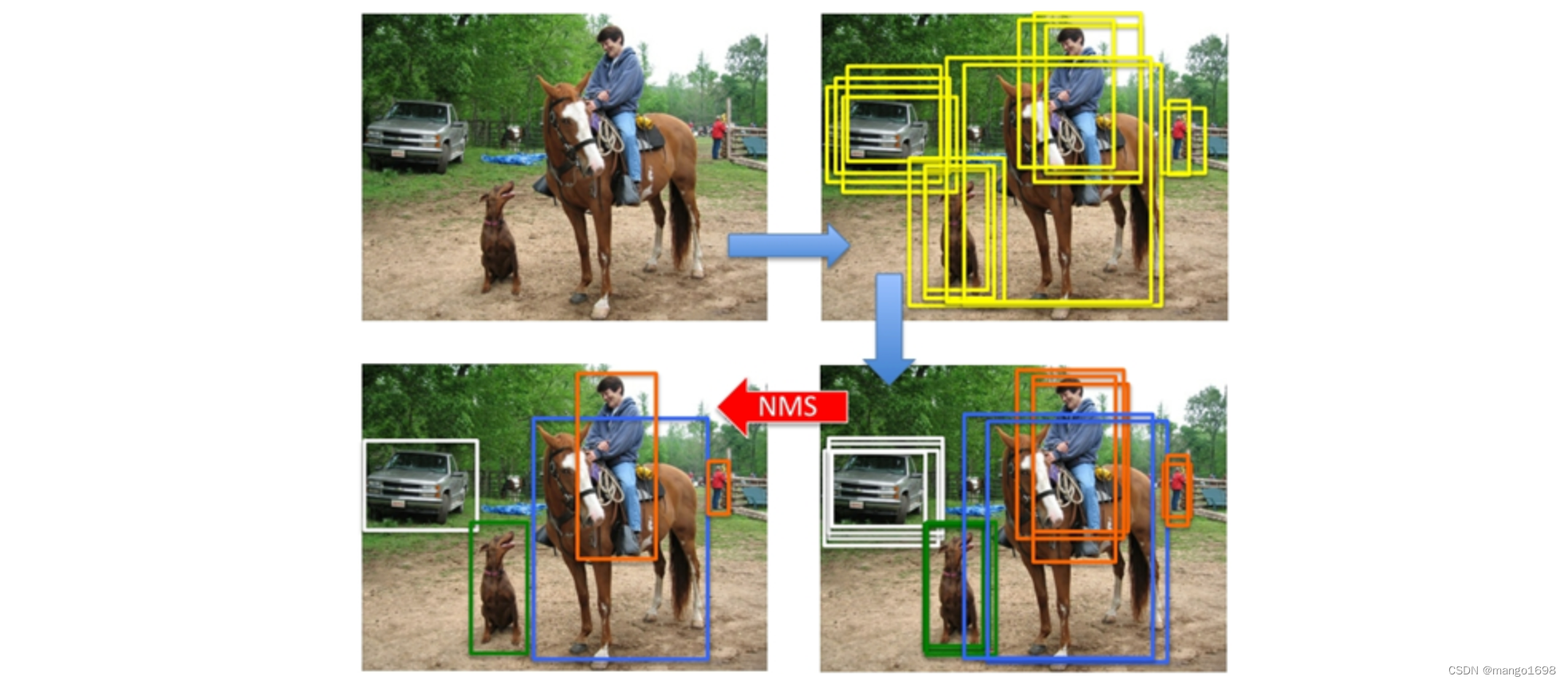
非极大值抑制(NMS)
非极大值抑制,为了去除冗余的检测框。
在对conv5后的特征图,接入SVM进行打分,打好分后做非极大值抑制。
非极大值抑制过程:
- 假设有3个框,根据SVM的打分顺序:概率从大到小为A、B、C
- 判断B、C与A的重复率
IoU是否大于阀值,如果大于阀值,则丢弃。如果小于阀值,则保留。 - 保留下来的框,根据打分排序,重复上诉过程。
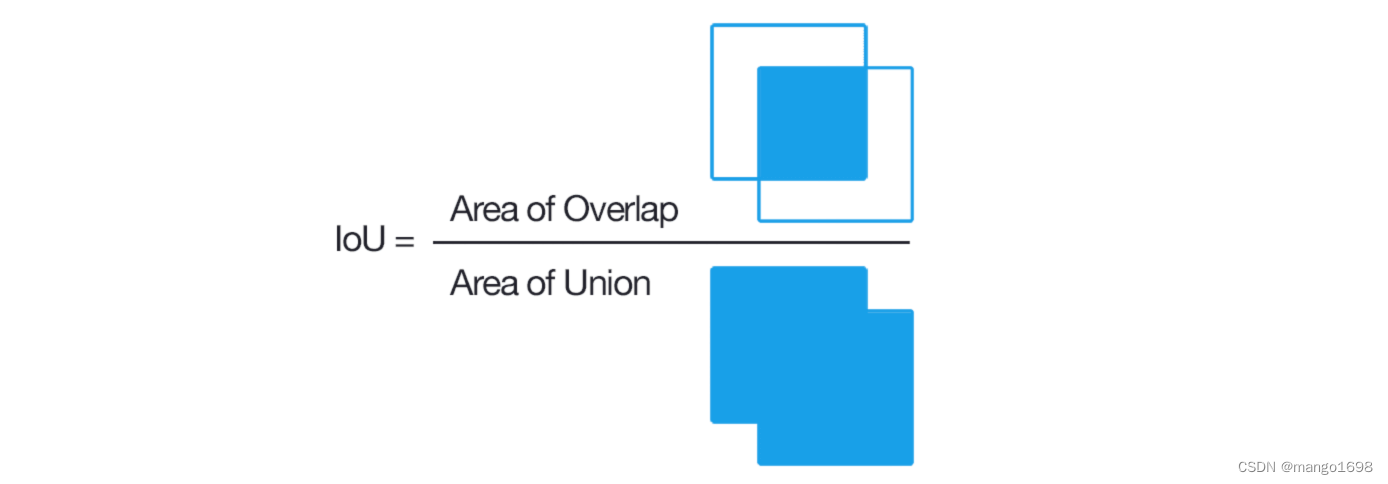
IoU 交并比
Bounding-box regression是用来微调窗口的。
(x,y,w,h):x,y为平移,w,h为尺度缩放。
RCNN框架
2. Fast-RCNN
论文:Fast R-CNN
地址:https://arxiv.org/abs/1504.08083
Fast R-CNN是继R-CNN之后的又一力作。同样使用VGG16作为网络的backbone,与R-CNN相比,训练时间快6倍,测试推理时间快213倍,准确率从62%提升至66%(在Pascal VOC数据集上)。
Fast RCNN算法流程
- 一张图像生成1000到2000个候选区域(使用Selective Search方法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI Pooling层缩放到 7 × 7 7\times 7 7×7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
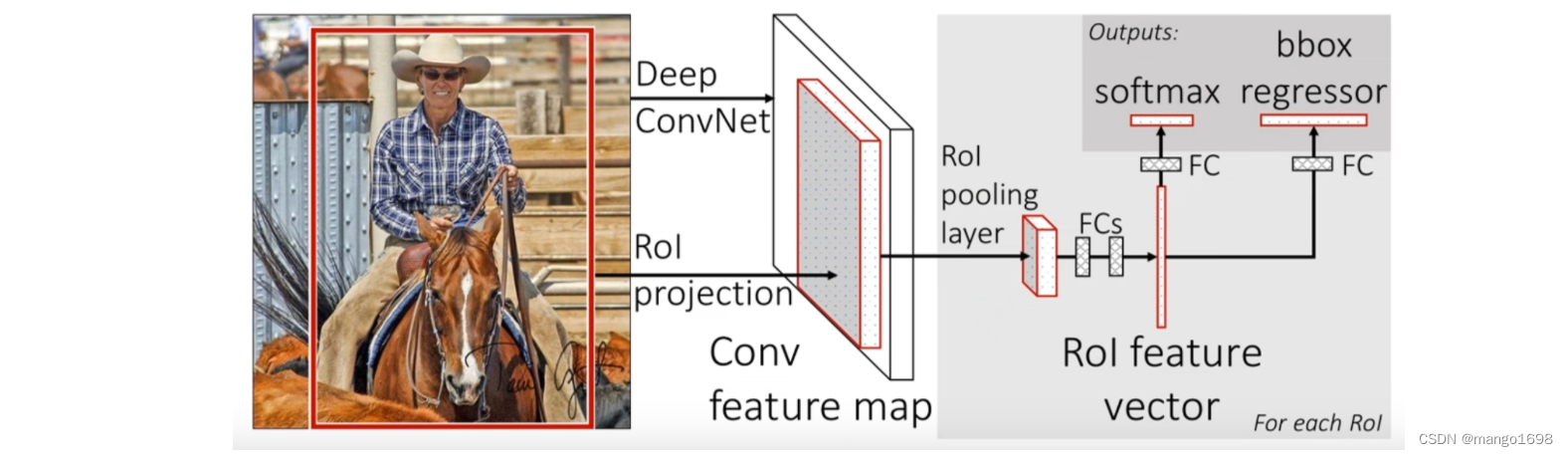
一次性计算整张图像特征。不限制输入图像的尺寸。Fast-RCNN将整张图像送入网络,紧接着从特征图上提取相应的候选区域。这些候选区域的特征不需要再重复计算。而对于R-CNN,是一次将候选框区域输入卷积神经网络得到特征。
分类器,输出N+1个类别的概率(N为检测目标的种类,1为背景),用N+1个节点。
边界框回归器,输出对应N+1个类别的候选边界框回归参数 ( d x , d y , d w , d h ) (d_x,d_y,d_w,d_h) (dx,dy,dw,dh),共 ( N + 1 ) × 4 (N+1)\times4 (N+1)×4个节点。

Fast RCNN损失函数

分类损失: L c l s ( p , u ) = − l o g p u L_{cls}(p,u) = -logp_u Lcls(p,u)=−logpu
边界框回归损失:
L
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
u
−
v
i
)
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
i
f
∣
x
∣
<
1
∣
x
∣
−
0.5
o
t
h
e
r
w
i
s
e
L_{loc}(t^u,v) = \sum_{i\in\{x,y,w,h\}}smooth_{L_1}(t^u_i-v_i) \\ smooth_{L_1}(x) = \begin{cases} 0.5x^2 \ \ \ if |x|<1 \\ |x|-0.5 \ \ \ otherwise \end{cases}
Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi)smoothL1(x)={0.5x2 if∣x∣<1∣x∣−0.5 otherwise
补充:Cross Entropy Loss交叉熵损失
-
针对多分类问题(softmax输出,所有输出概率和为1)
H = − ∑ i o i ∗ l o g ( o i ) H = -\sum_io^*_ilog(o_i) H=−i∑oi∗log(oi) -
针对二分类问题(sigmoid输出,每个输出节点之间互不干预)
H = − 1 N ∑ i = 1 N [ o i ∗ l o g o i + ( 1 − o i ∗ ) l o g ( 1 − o i ) ] H = -\frac{1}{N}\sum^N\limits_{i=1}[o^*_ilogo_i+(1-o^*_i)log(1-o_i)] H=−N1i=1∑N[oi∗logoi+(1−oi∗)log(1−oi)]
其中 o i ∗ o^*_i oi∗为真实标签值, o i o_i oi为预测值,默认 l o g log log以 e e e为底等于 l n ln ln
Fast RCNN框架

3. Faster-RCNN
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
网址:https://arxiv.org/abs/1506.01497
Faster RCNN是继Fast RCNN后的又一力作。同样适用VGG16作为网络的backbone。
RNP+Fast R-CNN
Faster RCNN算法流程
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI Pooling层缩放到 7 × 7 7\times 7 7×7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
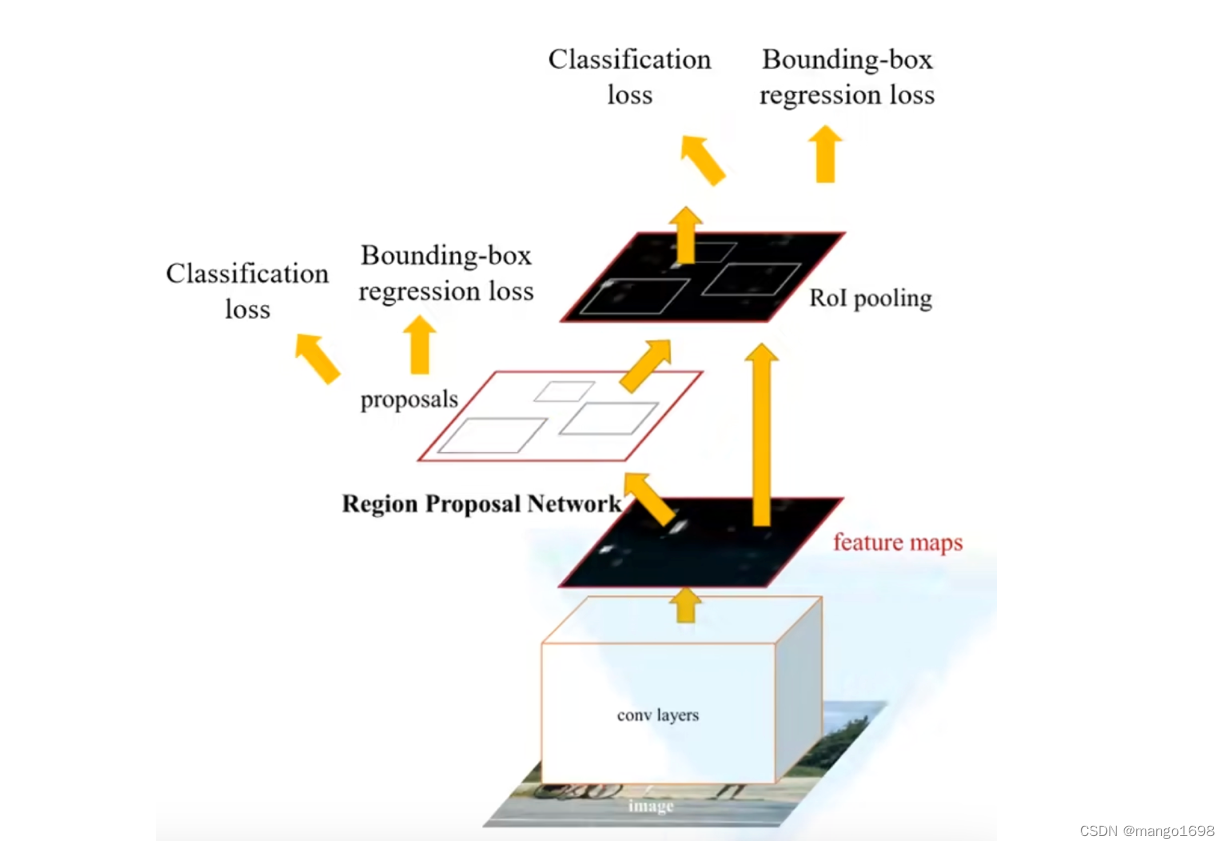
RPN网络
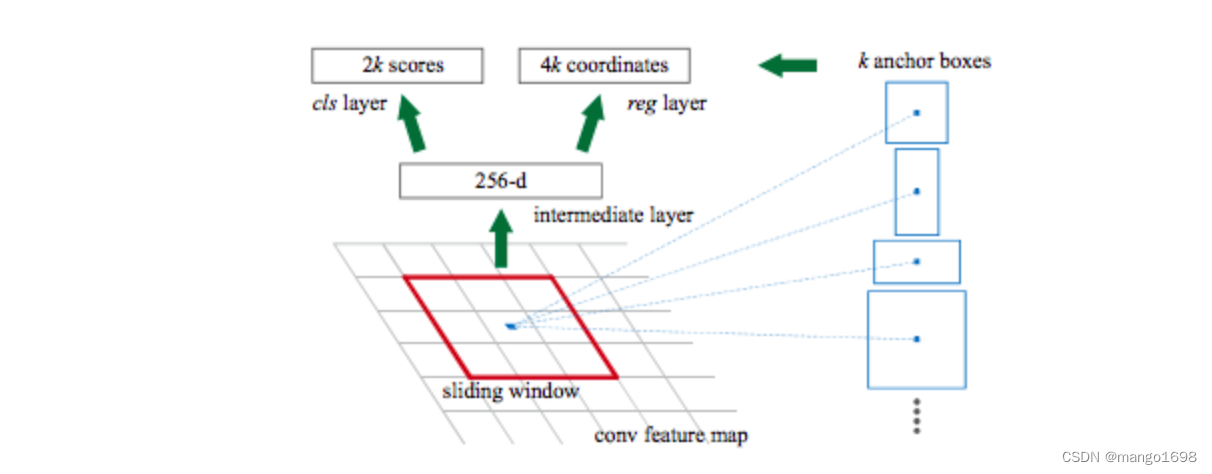
对于特征图上的每个 3 × 3 3\times 3 3×3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出k个anchor boxes(注意和proposal的差异)
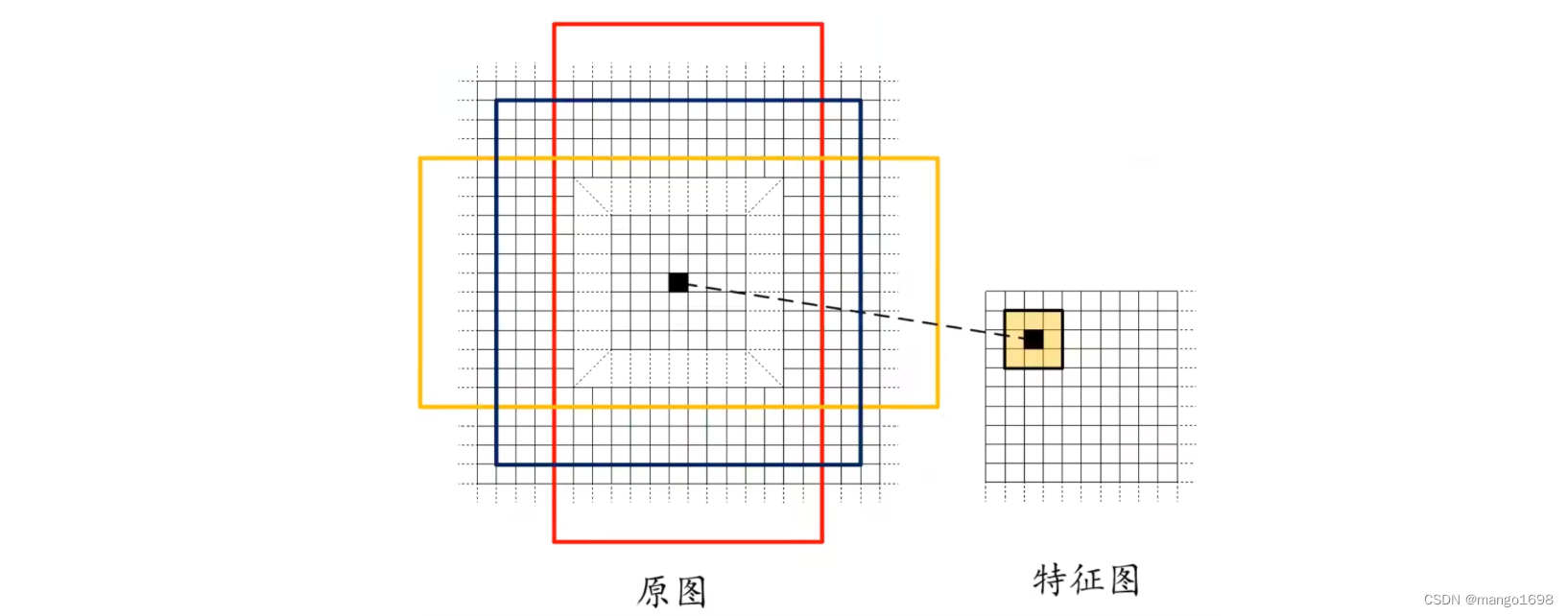
需要提前设定好k个不同尺寸比例的anchor。在faster rcnn中给了三个尺度和三个比例。
三种尺度(面积): 12 8 2 , 25 6 2 , 51 2 2 128^2,256^2,512^2 1282,2562,5122,(面积具体数字,论文中说是根据经验所得)
三种比例: 1 : 1 , 1 : 2 , 2 : 1 1:1,1:2,2:1 1:1,1:2,2:1
意思就是,在 12 8 2 128^2 1282这个尺度上,有 1 : 1 , 1 : 2 , 2 : 1 1:1,1:2,2:1 1:1,1:2,2:1三个anchor,在 25 6 2 256^2 2562这个尺度上,有 1 : 1 , 1 : 2 , 2 : 1 1:1,1:2,2:1 1:1,1:2,2:1三个anchor,在 51 2 2 512^2 5122这个尺度上,有 1 : 1 , 1 : 2 , 2 : 1 1:1,1:2,2:1 1:1,1:2,2:1三个anchor。分别来负责检测不同大小的物体。
每个位置(每个滑动窗口)在原图上都对应有 3 × 3 = 9 3\times 3=9 3×3=9个anchor。
但是存在一个问题,VGG的感受野为228,那怎么去预测一个比它大的目标的边界框呢?如去预测 25 6 2 , 51 2 2 256^2,512^2 2562,5122尺度上的物体。论文中说,通过一个小的感受野去预测一个比它大的目标的边界框是有可能的,根据经验,我们看到一个物体的一部分,可以猜出这个物体的位置区域。
对于一张 1000 × 600 × 3 1000\times 600\times 3 1000×600×3的图像,大约有 60 × 40 × 9 ( 20 k ) 60\times 40\times 9(20k) 60×40×9(20k)个anchor,忽略跨越边界的anchor以后,剩下约 6 k 6k 6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的 c l s cls cls得分,采用非极大值抑制, I o U IoU IoU设置为0.7,这样每张图片只剩2k个候选框。
在原论文中k=9
利用RPN生成的边界框回归参数将anchor调整到我们所需要的候选框。
对于每张图片,上万个anchor中,采样256个anchor,由正样本和负样本两部分组成,比例大概为1:1。如果正样本个数不足128,则用负样本进行填充。
定义为正样本的方式:
- 只要anchor与ground-truth box的IoU大于0.7,则这个anchor为正样本。
- anchor与某个ground-truth box拥有最大的IoU,则也认为它为正样本。
定义为负样本的方式:
- 与所有ground-truth box的IoU小于0.3的anchor,则定义为负样本
对于正样本与负样本之外的所有anchor,则丢弃掉。
RPN损失函数

- p i p_i pi表示第 i i i个anchor存在目标的概率
- p i ∗ p^*_i pi∗当为正样本时为1,当为负样本时为0
- t i t_i ti表示预测第 i i i个anchor的边界框回归参数
- t i ∗ t^*_i ti∗表示第 i i i个anchor对应的GT Box
- N c l s N_{cls} Ncls表示第一个mini-batch中的所有样本数量256
- N r e g N_{reg} Nreg表示anchor位置的个数(不是anchor个数)约2400
分类损失:二值交叉熵损失
回归损失:
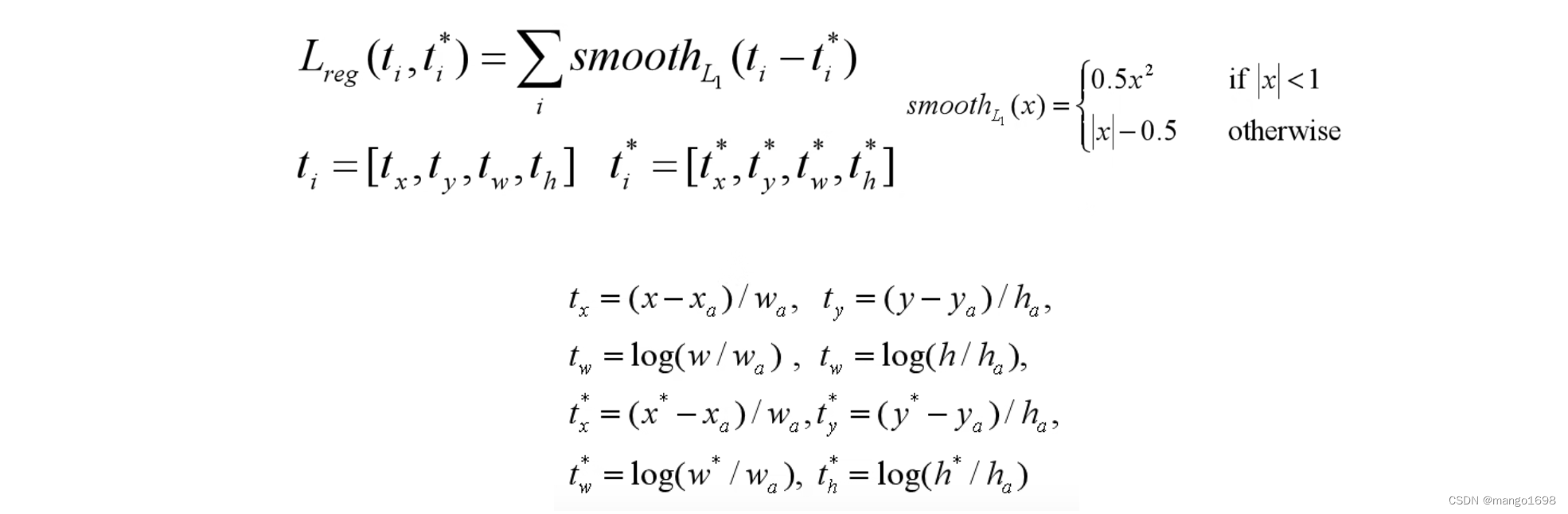
Faster R-CNN训练
直接采用RPN Loss + Fast R-CNN Loss的联合训练方法
原论文中采用分别训练RPN以及Fast R-CNN的方法:
- 利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络参数。
- 固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数。
- 固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层以及全连接层参数。
- 同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
Faster-RCNN框架