接上篇,根据脚本可将coco128的128张图片,按照比例划分成训练集、测试集、验证集,同时生成相应的标注的labels文件夹,最近再看实例分离比较火的mask rcnn模型,准备进行调试但由于实验室算力不足,网上自己租的2080ti马,传整个coco2017实在是太慢了,检索了一下没有开源的部分coco2017数据集,于是我想到将coco128的数据转化成json文件,便于新手进行debug,节约时间和算力。

数据集结构准备如上(在我上篇博文的基础上新增classes.txt文件和annotations文件夹)
脚本如下:
import os
import json
import cv2
import random
import time
from PIL import Image
coco_format_save_path='/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/annotations/' #要生成的标准coco格式标签所在文件夹
yolo_format_classes_path='/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/train/classes.txt' #类别文件,一行一个类
yolo_format_annotation_path='/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/train/labels/' #yolo格式标签所在文件夹
img_pathDir='/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/train/images/' #图片所在文件夹
with open(yolo_format_classes_path,'r') as fr: #打开并读取类别文件
lines1=fr.readlines()
# print(lines1)
categories=[] #存储类别的列表
for j,label in enumerate(lines1):
label=label.strip()
categories.append({'id':j+1,'name':label,'supercategory':'None'}) #将类别信息添加到categories中
# print(categories)
write_json_context=dict() #写入.json文件的大字典
write_json_context['info']= {'description': '', 'url': '', 'version': '', 'year': 2024, 'contributor': '纯粹ss', 'date_created': '2024-01-12'}
write_json_context['licenses']=[{'id':1,'name':None,'url':None}]
write_json_context['categories']=categories
write_json_context['images']=[]
write_json_context['annotations']=[]
#接下来的代码主要添加'images'和'annotations'的key值
imageFileList=os.listdir(img_pathDir) #遍历该文件夹下的所有文件,并将所有文件名添加到列表中
for i,imageFile in enumerate(imageFileList):
imagePath = os.path.join(img_pathDir,imageFile) #获取图片的绝对路径
image = Image.open(imagePath) #读取图片,然后获取图片的宽和高
W, H = image.size
img_context={} #使用一个字典存储该图片信息
#img_name=os.path.basename(imagePath) #返回path最后的文件名。如果path以/或\结尾,那么就会返回空值
img_context['file_name']=imageFile
img_context['height']=H
img_context['width']=W
img_context['date_captured']='2024.1.12'
img_context['id']=i #该图片的id
img_context['license']=1
img_context['color_url']=''
img_context['flickr_url']=''
write_json_context['images'].append(img_context) #将该图片信息添加到'image'列表中
txtFile=imageFile[:12]+'.txt' #获取该图片获取的txt文件
with open(os.path.join(yolo_format_annotation_path,txtFile),'r') as fr:
lines=fr.readlines() #读取txt文件的每一行数据,lines2是一个列表,包含了一个图片的所有标注信息
for j,line in enumerate(lines):
bbox_dict = {} #将每一个bounding box信息存储在该字典中
# line = line.strip().split()
# print(line.strip().split(' '))
class_id,x,y,w,h=line.strip().split(' ') #获取每一个标注框的详细信息
class_id,x, y, w, h = int(class_id), float(x), float(y), float(w), float(h) #将字符串类型转为可计算的int和float类型
xmin=(x-w/2)*W #坐标转换
ymin=(y-h/2)*H
xmax=(x+w/2)*W
ymax=(y+h/2)*H
w=w*W
h=h*H
bbox_dict['id']=i*10000+j #bounding box的坐标信息
bbox_dict['image_id']=i
bbox_dict['category_id']=class_id+1 #注意目标类别要加一
bbox_dict['iscrowd']=0
height,width=abs(ymax-ymin),abs(xmax-xmin)
bbox_dict['area']=height*width
bbox_dict['bbox']=[xmin,ymin,w,h]
bbox_dict['segmentation']=[[xmin,ymin,xmax,ymin,xmax,ymax,xmin,ymax]]
write_json_context['annotations'].append(bbox_dict) #将每一个由字典存储的bounding box信息添加到'annotations'列表中
name = os.path.join(coco_format_save_path,"train"+ '.json')
with open(name,'w') as fw: #将字典信息写入.json文件中
json.dump(write_json_context,fw,indent=2)
注意这里要新建classes.txt文件夹,每一行表示一个物体类别,编号与yolo格式的标注txt文件对应,我新建的coco数据集的classes.txt文件夹如下:
person
bicycle
car
motorcycle
airplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
hangbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
couch
potted plant
bed
mirror
dining table
window
desk
toilet
door
tv
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
blender
book
clock
(txt文件发出来是因为查了一下发现网上给出的coco类别与编码都是图片,由于自己手欠还打了两遍,发出来大家可以直接用)
注意脚本运行时候的一些设置:

脚本关于获取图片对应txt文件时,需要名字对应,我是编号为000000000009.txt,因此这里设置的是12,表示前12位,感觉也可以用文件名末尾.jpg替换为.txt来实现。
最后生成的coco格式的json文件如下:
{
"info": {
"description": "",
"url": "",
"version": "",
"year": 2024,
"contributor": "\u7eaf\u7cb9ss",
"date_created": "2024-01-12"
},
"licenses": [
{
"id": 1,
"name": null,
"url": null
}
],
"categories": [
{
"id": 1,
"name": "person",
"supercategory": "None"
},
{
"id": 2,
"name": "bicycle",
"supercategory": "None"
},
.....
"images": [
{
"file_name": "000000000030.jpg",
"height": 428,
"width": 640,
"date_captured": "2024.1.12",
"id": 0,
"license": 1,
"color_url": "",
"flickr_url": ""
},
.......
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 59,
"iscrowd": 0,
"area": 82611.7361856,
"bbox": [
204.86016,
31.019727999999994,
254.88,
324.12012
],
"segmentation": [
[
204.86016,
31.019727999999994,
459.74016,
31.019727999999994,
459.74016,
355.13984800000003,
204.86016,
355.13984800000003
]
]
},
{
"id": 1,
"image_id": 0,
"category_id": 76,
"iscrowd": 0,
"area": 32489.62928639999,
"bbox": [
237.56032,
155.80997600000003,
166.4,
195.25017599999998
],
"segmentation": [
[
237.56032,
155.80997600000003,
403.96031999999997,
155.80997600000003,
403.96031999999997,
351.060152,
237.56032,
351.060152
]
]
},
{
生成json文件后可以用脚本来测试,这里借用博主太阳花的小绿豆的脚本:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/annotations/train.json"
img_path = "/root/autodl-tmp/deep-learning-for-image-processing-master/pytorch_object_detection/mask_rcnn/data/train/images"
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:20]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# draw box to image
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1), coco_classes[target["category_id"]])
# show image
plt.imshow(img)
plt.show()
可以可视化数据集图片的标注结果:
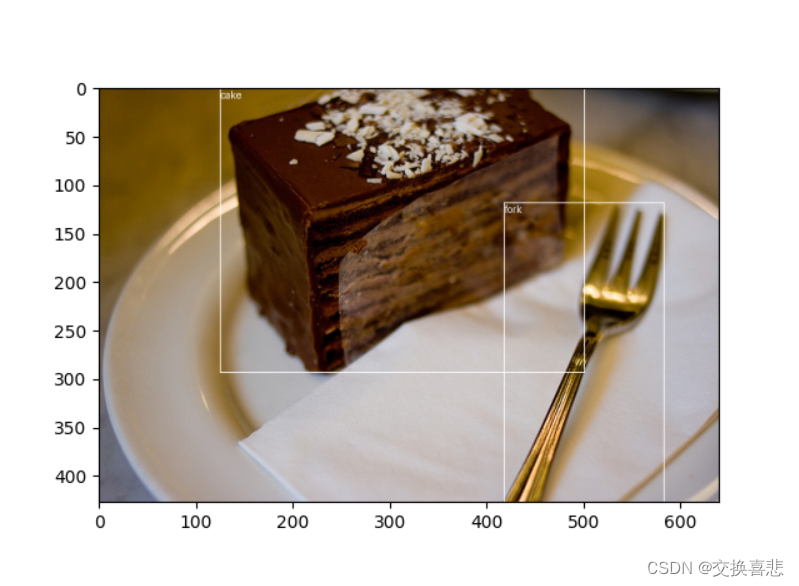
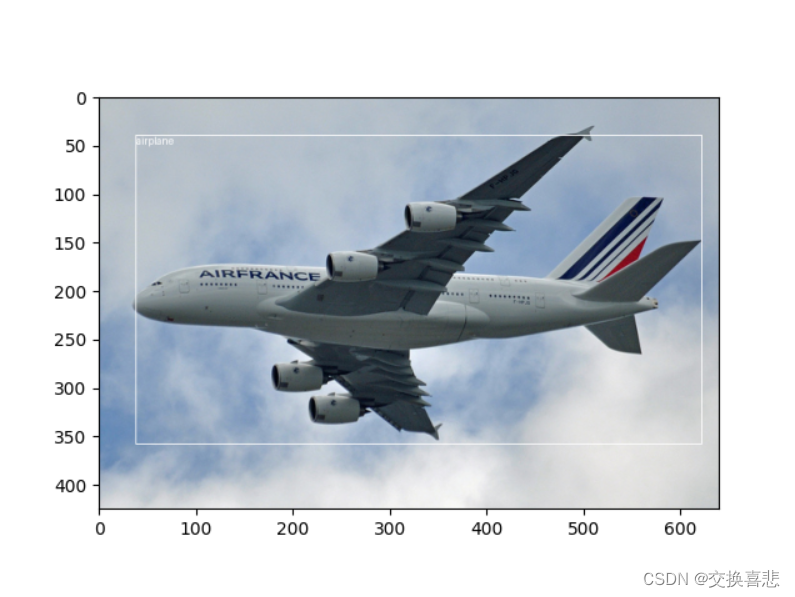
 目标检测框都可以正确生成" />
目标检测框都可以正确生成" />
说明我们生成的json文件是正确的