我是训练的行人目标检测。
首先下载YOLOFastestv2:https://github.com/dog-qiuqiu/FastestDet
yolofastestv2需要这样的数据集:
python">.
├── category.names # .names category label file
├── train # train dataset
│ ├── 000001.jpg
│ ├── 000001.txt
│ ├── 000002.jpg
│ ├── 000002.txt
│ ├── 000003.jpg
│ └── 000003.txt
├── train.txt # train dataset path .txt file
├── val # val dataset
│ ├── 000043.jpg
│ ├── 000043.txt
│ ├── 000057.jpg
│ ├── 000057.txt
│ ├── 000070.jpg
│ └── 000070.txt
└── val.txt # val dataset path .txt file
一般我们的数据集是voc样式的数据集即文件夹中只有这两个文件:
train和val文件夹内的0001.txt为yolo数据集的格式,其内容如下:
python">0 0.344192634561 0.611 0.416430594901 0.262
1 0.509915014164 0.51 0.974504249292 0.972
首先我们将xml转成这个格式的,在Annotations和JPEGImages的同级路径下创建一个py文件:
python"># 作者:李富贵
# 公众号:猛男技术控
# 输入:xml的文件夹路径
# 输出:在txt路径下创建对应的txt文件
import xml.etree.ElementTree as ET
import os
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(xml_file, txt_path, filename):
in_file = open('{}/{}.xml'.format(xml_file, filename), encoding='UTF-8')
out_file = open('{}/{}.txt'.format(txt_path, filename), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
if obj.find('difficult'):
difficult = obj.find('difficult').text
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 改成自己的类别
classes = ["person"]
# 改成自己xml文件夹和要保存的txt文件夹的路径
xml_path = 'Annotations'
txt_path = 'txt'
if not os.path.exists(txt_path):
os.makedirs(txt_path)
xml_files = os.listdir(xml_path)
for xml_file in xml_files:
print(xml_path + '/' + xml_file)
convert_annotation(xml_path, txt_path, xml_file[:-4])
然后得到一个txt文件,里面就是存放所有已转换的txt
第二步就是将文件分成train和test
python">import os
import shutil
import random
all_txt = os.listdir('txt')
random.shuffle(all_txt)
trainf = all_txt[:1316]
vlaf = all_txt[1317:]
i = 1
for trainimg in trainf:
try:
shutil.copy(os.path.join('JPEGImages',trainimg[:-3]+'png'),'train')
shutil.copy(os.path.join('txt', trainimg), 'train')
print(i)
i += 1
except:
print('no such file ',os.path.join('JPEGImages',trainimg[:-3]+'jpg'))
j = 1
for valimg in vlaf:
try:
shutil.copy(os.path.join('JPEGImages',valimg[:-3]+'png'),'v')
shutil.copy(os.path.join('txt', valimg), 'v')
print(j)
j += 1
except:
print('no such file ',os.path.join('JPEGImages',valimg))
注意自己创建号train和val文件夹,修改train和val文件的个数。
这样就生成了下面这样的文件
python">├── train
│ ├── 000001.jpg
│ ├── 000001.txt
│ ├── 000002.jpg
│ ├── 000002.txt
│ ├── 000003.jpg
│ └── 000003.txt
└── val
├── 000043.jpg
├── 000043.txt
├── 000057.jpg
├── 000057.txt
├── 000070.jpg
└── 000070.txt
然后将所有文件读入txt中:
python">import os
traintxt = open('train.txt','a')
val = open('val.txt','a')
for img in os.listdir('train'):
if "png" in img:
traintxt.write(os.path.join('INRIAPerson-823/train',img)+'\n')
print(img)
else:
print(img,'error')
for img in os.listdir('val'):
if "png" in img:
valtxt.write(os.path.join('INRIAPerson-823/val',img)+'\n')
print(img)
else:
print(img,'error')
valtxt.close()
traintxt.close()
然后修改data下的.data文件
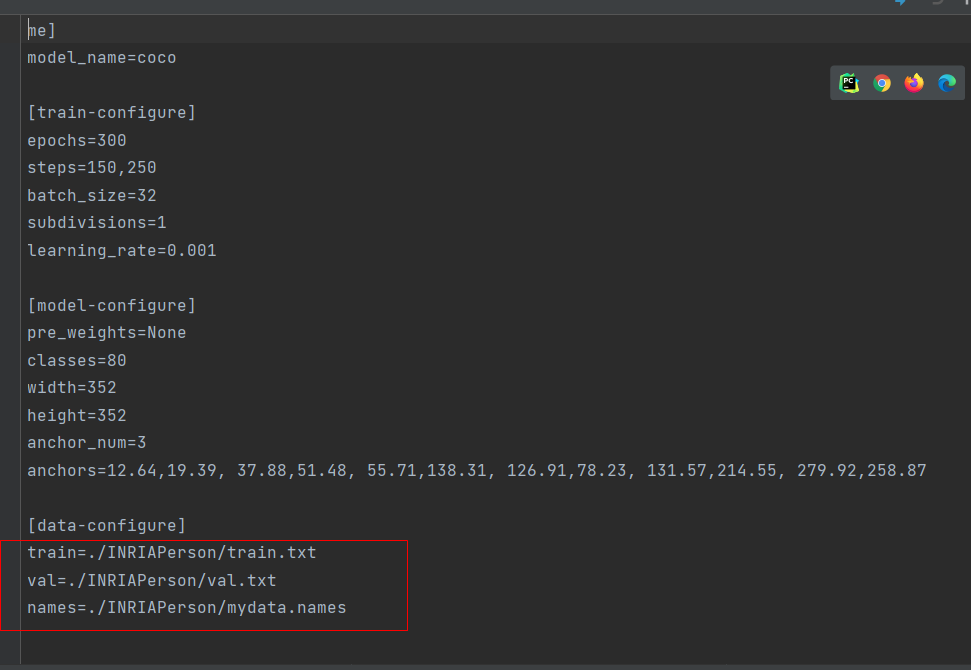
对应的路径自己修改
然后就是训练了:
先跑下这个:
python">python3 genanchors.py --traintxt ./train.txt
然后
python">python3 train.py --data data/coco.data
下不了的关注我公众号:猛男技术控,回复yolofastest 可以提供代码、数据、以及我训练的权重。