论文:R-FCN: Object Detection via Region-based Fully Convolutional Networks
作者:Jifeng Dai, Yi Li, Kaiming He and Jian Sun
链接:https://arxiv.org/pdf/1605.06409v2.pdf
代码:https://github.com/daijifeng001/r-fcn
1、算法概述
之前基于区域的目标检测方法,像Fast/Faster R-CNN虽然在提取区域特征这部分做了共享,但基于子区域的分类和回归部分,还没有达到计算共享,几百个候选框,依然需要做几百次分类和回归操作,这大大消耗了推理时间。本文所提基于区域的检测器是全部采用卷积操作,几乎所有的计算都是在整个图像上共享的,为了实现所有操作共享这一目的,作者提出了位置敏感的分数图来解决图像分类中的平移不变性(translation-invariance)和目标检测中的平移敏感(translation-variance)之间的矛盾。作者以ResNet101作为主干,在VOC 2007测试集上能达到 83.6%的mAP。推理时间为每张图片170ms,是Faster R-CNN的2.5到20倍。
2、R-FCN细节
先说之前的基于区域候选框的目标检测算法,它们可看作以RoI pooling层为切入点将整个网络分为两个子网络(subnetworks),前部分子网络为RoI Pooling之前的共享计算的全卷积子网络,后一部分为RoI-wise的子网络(全连接层),它们不共享计算。这主要是由于前期采用的经典分类网络就是卷积+全连接这样的设计结构造成的。现在例如ResNets和GoogLeNets都被设计成了全卷积网络,类比到目标检测网络,是不是也可以将后部分的RoI-wise子网络层替换成全卷积网络?
要想分类得比较准,那就要网络学习到平移不变性,即目标从图像左边平移到右边,该目标的类别还是一样,即对位置不敏感;但对于回归任务,又要网络学习到平移可变性,让网络对位置敏感,这样才能保证网络对于目标从图像左边平移到右边后能正确预测到平移后目标的位置。要同时满足这两点,Faster RCNN通过插入RoI Pooling层实现了,但RoI Pooling带有位置截断属性,经过RoI截取后,RoI对目标的感受野也被截断了,相同的目标经过RoI Pooling层后可能得到不同的类别。结合网络越深能提取到越高层特征的特性,若RoI pooling越靠近网络前部,则会导致分类不准确,若RoI Pooling约靠近网络后部,则会导致回归不准确。
由于卷积神经网络擅长提取图像特征,但是对特征所处的位置不太敏感,所以作者在网络中增加了位置敏感因素,使得全卷积网络对目标的位置具有敏感特性。R-FCN的整体结构如下:
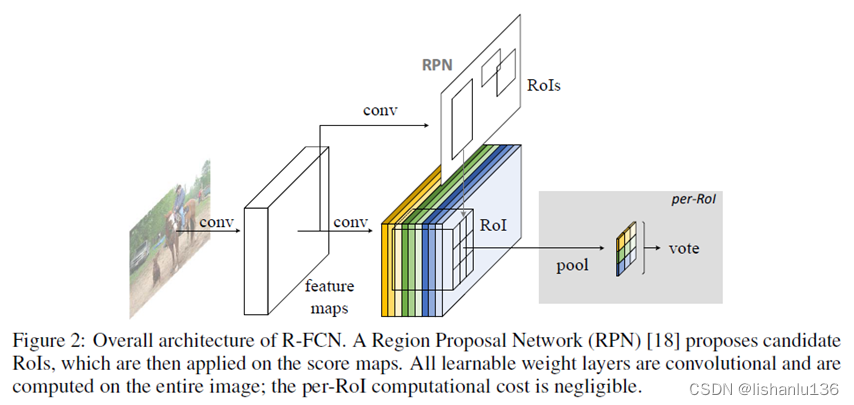
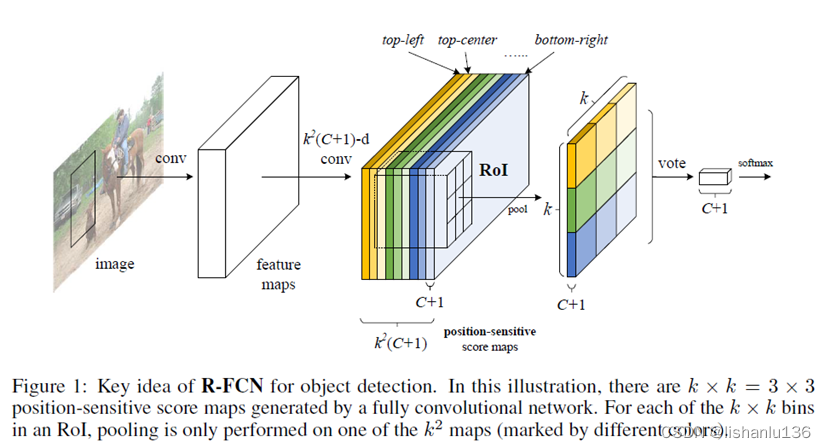
可以看到R-FCN,主体结构还是和Faster R-CNN大体上类似的,只是RoI Pooling这里做了一些变化,另外R-FCN也将Faster R-CNN的RoI-wise部分全部换成了卷积操作,使得基于区域的分类/回归任务都可以共享计算。对比效果如下表:

- Backbone architecture
R-FCN主干网络采用ResNet-101,它包含前面100层的卷积层加global average pooling层和1000类的fc层,作者只用了前面100层卷积层作为提取特征,最后一个卷积层输出是2048维,作者用了一个随机初始化的1024维的1x1卷积层作了降维处理,然后用了k*k(C+1)通道的卷积层用来生成分数图。 - Position-sensitive score maps & Position-sensitive RoI pooling
为了显式地将位置信息编码到每个RoI中,作者通过网格将每个RoI矩形划分为k * k个网络格子。对于w * h的RoI区域,每个网格大小为w/k * h/k。作者通过最后一个卷积层将每个类别映射成k * k个分数图。对第(i,j)个网络(0<=i,j<=k-1),定义一个位置敏感RoI池化操作为:

- 分类
对该RoI每类的所有相对空间位置的分数取平均或者投票得到
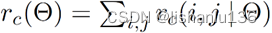
然后通过softmax做分类
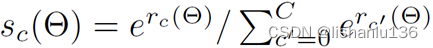
- Bounding-box回归
也是采用类似分类的方法,通过最后一个卷积层使得每个RoI产生4k2维向量,经过投票后,用Fast R-CNN的参数化得到1个4维向量(tx,ty,tw,th)。
3、实验结果
作者在VOC2007,VOC2012上测试结果如下:
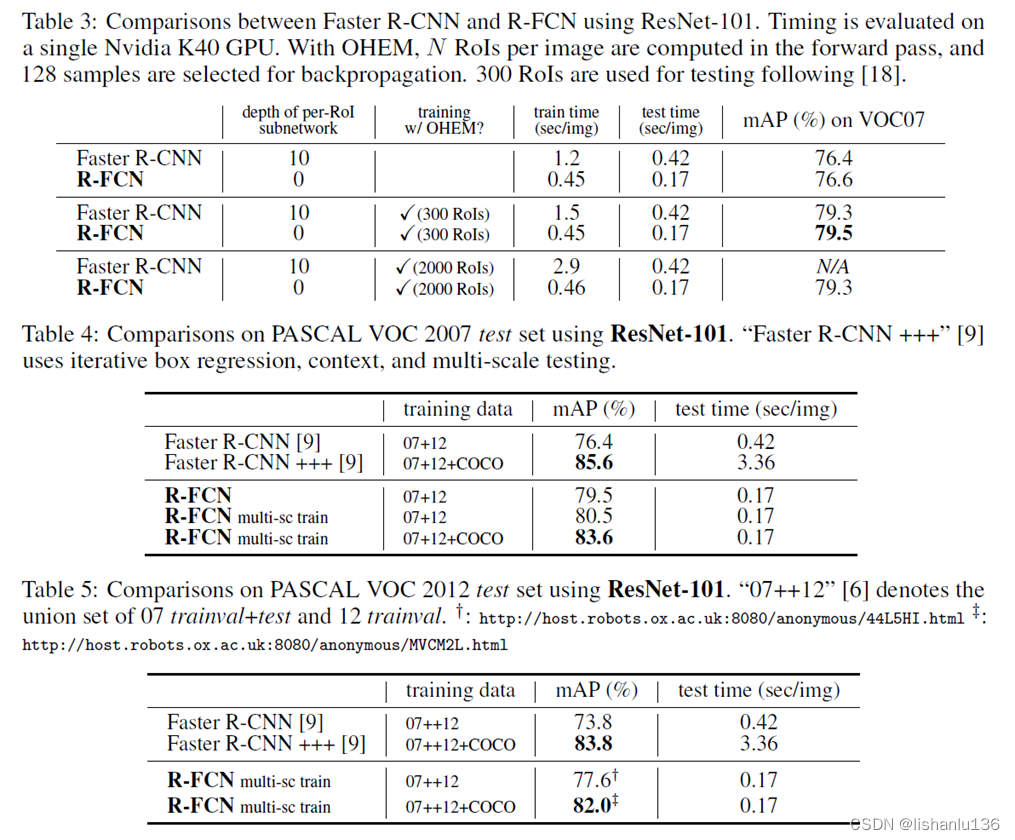
可以看到,在mAP指标上,相对于Faster R-CNN,没有掉点,但是在推理速度上提升很大。