论文:Rich feature hierarchies for accurate object detection and semantic segmentation【用于精确物体定位和语义分割的丰富特征层次结构】
论文链接:https://arxiv.org/pdf/1311.2524v3.pdf
论文翻译:https://blog.csdn.net/v1_vivian/article/details/78599229
题外话
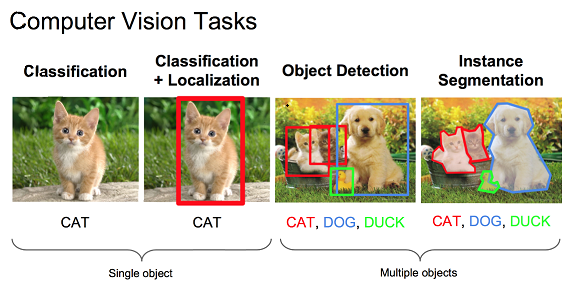
图像分类,检测及分割是计算机视觉领域的三大任务。目标检测,具体指识别并定位一张图片中的多个物体,返回与图内物体对应的预测框及其分类。任务要求复杂于分类,弱于分割,是一个中粒度的任务。
解决这一问题,核心思路有两种:
(1) two-stage法,将问题分为两个阶段,首先产生候选区域,再对区域分类和精修,典型代表为R-CNN家族(rcnn, fast-rcnn, faster-rcnn)。更准但偏慢。
(2) one-stage法直接产生物体的类别概率和位置坐标值,比较典型的算法如YOLO家族和SSD。快速但准确度稍逊。
RCNN这篇论文是二阶法的开山之作,虽然其技术手段上并没有提出新东西,但RCNN是首先将深度模型应用到检测任务的成功案例,RCNN也终结了检测任务上传统方法的统治地位。虽然其本身仍有蛮多缺陷,但其地位,亦足可以称作一个milestone了。
不建议在本篇论文花过多时间, 后续之作(faster-rcnn)很多地方进行了改进, so, that’s a waste of time.
先放上RCNN的摘要,也是重点!!!
数据集: Pascal VOC (目标检测领域很经典的一个数据集,不过现已经被COCO取代)
本文两大核心difference:
(1). 成功将CNN应用到检测任务上,并取得了巨大的表现提升。(mAP达到了当时的state of art 53.3%,比传统方法提高近30%)
(2). VOC 数据集很小,故本实验使用了迁移学习+网络微调的方式。
架构设计
整体流程为:SS + CNN + SVM分类器
使用Selective Search 方法,提取出2000余个候选框
将提取到的全部候选框输入到CNN网络(AlexNet, VGG)中,本步骤旨在提取特征,最终得到定长的特征向量(4096维)
再将提取到的特征向量输入到SVM分类器中,获得候选框的分类(predict label of bboxes)
【补:Selective Search 是一篇讲述合并,生成候选框的论文。速度太慢,瓶颈严重,在rcnn家族中被后来的RPN网络方法取代,故十分不建议阅读。】
简介如下:
首先使用F.M的论文的方法(一种分割领域的贪心聚类算法)生成诸多小块区域,此后,论文从多种角度(颜色空间,纹理,域尺寸,匹配程度等)提出思考,定义了多种相似度,线性加权得到整体域相似度,再根据整体相似度进行区域合并。计算纹理相似度基于SIFT算法,因此计算耗时过大,最后此方法被弃用,故不建议阅读。
Related Blog:(Selective Search相关)
https://blog.csdn.net/Tomxiaodai/article/details/81412354
https://blog.csdn.net/c20081052/article/details/80020200
注: 在后续的fast-rcnn中,SVM分类器这一部分被弃用,Softmax分类器取代了它。

训练细节
预训练
在 数据集 ILSVRC2012 (ImageNet)上进行预训练。框架是Caffe,论文最初使用的是AlexNet架构。(这只是一个单纯分类任务,训练网络提取特征的能力)
问: 为什么要进行预训练?
答: CNN训练需要大量样本,VOC数据集太小了,根本顶不住(overfitting)
建议框提取
bbox = bounding box, 亦可称之为 proposal region 或 ROI(Region of Interest),指所要提取的边界框
不妨将选择性搜索看做一个黑盒模型,输入原始图像,返回bounding box的左上角点位置及bbox的shape(宽,高)。由是,我们得到了两千余个,形状各异的矩形建议框。
问: 提取到的bbox下一步要输入到CNN网络中,AlexNet固定网络输入(224×224 px),如何解决这一问题?
答:warp image。 本文将每个提取到的bbox,均padding了16px(填值为每个bbox的灰度均值),接下来进行暴力扭曲,将图片resize到固定尺寸。显然,这破坏了图像的结构,造成了失真。(在后续研究中,这种方法弃用,找到了更聪明的方法)
网络微调
问: 不进行调优,直接用预训练模型行么?
答: 可行,经过微调,mAP提高了8%
数据集:VOC, SS后得到bbox, warp,输入网络进行训练。
CNN基本架构不变,变更的是网络输出。ImageNet 输出1000个分类,而VOC数据集上,仅21维输出(20类物体+背景类)。此处是一个单纯分类任务,输入bbox扭曲后的定长图像,输出该图像的分类。
问: 如何label 建议框的分类?
答: VOC数据集中,包含图像原图+图内若干个物体框标注信息。以单张图片为例,该图内的所有物体框设置为ground truth(如图0第3幅中的猫,狗,鸭子)。那接下来,如何给bbox打label呢?
下面,由我引入IOU (Intersection over Union)
简而言之,就是两个框,boxA && boxB。
IOU = (boxA ∩ boxB) / (boxA ∪ boxB)

【Ref: (IOU相关 上图源自知乎胡孟)】
https://zhuanlan.zhihu.com/p/47189358
而给bbox定label,实际上就是算bbox和ground truth(gt)的IOU。在微调训练中, gt-bbox和ss后得到的pred-bbox 计算IOU。如果IOU>0.5,就label成正例样本(针对其对应的gt类), 而如果p-bbox和所有gt-bbox的IOU均小于0.5,就设定为背景样本。0.5是一个宽松的阈值,主要原因是数据过少。
SGD大法,初始learning_rate为0.001。
batch-size = 128, 正样本:负样本 = 1:3(96个背景框,32个正例框)
SVM训练
IOU<0.3视为负类,ground-truth作为正类(存疑,是指bbox完全包含ground-truth某个物体,还是直接拿ground-truth作为正类)
而IOU>0.3的其他bbox直接丢弃,不参与SVM训练。
阈值0.3,这个值是网格搜索而来。0~0.5,步长为0.1搜索,最终发现0.3这个阈值的最终表现最好。(如此Label显然比微调更为严格,因为SVM本身适用于小数据集)
SVM是二分类分类器。因此实际上,针对每个类共训练了21个SVM分类器。
测试流程
SS(候选框获取) + CNN(特征提取) + SVM
由SVM确定分类后,将bbox归类成21类,接下来进行NMS非最大值抑制。
NMS过后,进行边界框回归
Ref:
https://blog.csdn.net/weixin_39732260/article/details/81304462
https://blog.csdn.net/weixin_41923961/article/details/80246244(本篇blog里叙述十分详尽,建议阅读)
https://blog.csdn.net/v1_vivian/article/details/80292569(边界回归)
消融实验

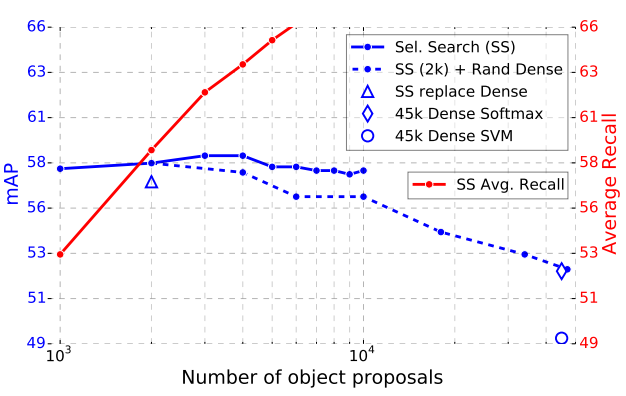
为检测性能,作者进行了消融实验,即丢弃某些层,再观察经丢弃部分后,新模型的表现。作者发现,丢弃全连接层,对结果表现影响较小。或许你还在疑问为什么大动干戈要用SVM单独训练分类,而不是直接从CNN得出分类结果,上图就给出了答案。丢弃FC6, FC7并没有影响很多,从卷积层最后一层(layer-5)提取出特征向量,输入SVM,能得到更优的表现。
补
R-CNN 一(da)作(lao):Ross Girshick 该作者工作于微软,在发表了引起轰动的本文后,没有放弃研究,继续对自己模型改进,以致于形成RCNN家族,成为二阶法典范,赞!这也太666了吧。说起6,我就想起了六小龄童爷爷,今年下半年…
检测任务的评价指标mAP。
Ref:
https://zhuanlan.zhihu.com/p/55575423
https://zhuanlan.zhihu.com/p/48992451
遗憾的地方是,我没有看懂本论文的可视化部分,没get到作者如何进行可视化的。如有dalao出没,望不吝赐教。
结论
贡献:
(1). CNN应用于检测任务的开山之作,第一个成功恰到螃蟹的人
(2). 迁移学习应用的成功案例
(3). 普遍认为 CNN和SVM是互斥的两个东西,但本文通过丢弃CNN全连接层,实现了SVM与CNN的结合
缺点:
(1). warp图像 失真
(2). 2000个框全部输入CNN 冗余计算
(3). Selective Search提取框,特别慢
(4). 训练多个SVM,麻烦
秉着尊重著作权和不重复造车轮的原则,如NMS,bbox回归等某些细节将直接挂链接,simply cuz I learn from that and I make no difference。
人的本质是什么?复读机啊~~~ 虽然不重复造车轮,但学习了解这些trick本身很重要,推荐阅读。本文配图源于CSDN博客或原论文,非原创(借用也没联系博主)(不过读书人的窃那能叫偷嘛),侵删见谅。图源有挂链接(见底部)。这些博主写的解读十分优秀,因此不想重复造轮子,但推荐大家还是要多了解。再次跪谢文中链接的大佬们,感谢他们为我们学习提供明灯~感恩!
RCNN是一篇目标检测的基础论文,入门有些困难,但是一如检测深似海,慢慢就会习惯啦,基础工作做得好,Fast RCNN和Faster RCNN才会不费力!我们本周还有两篇论文(Fast RCNN和Faster RCNN),感谢小伙伴们一路同行啦,感谢大家~