Paper:R-FCN: Object Detection via Region-based Fully Convolutional Networks

Visual Computing Group / Microsoft Research Asia
1 提出框架
首先说一说为什么提出了RFCN。作者分析此前的各种分类和检测框架,发现了一个问题:很多网络应用在分类问题的时候都能取得相当好的结果,准确率非常高,但是在应用到检测问题上的时候结果似乎就没那么理想了,这是为啥呢?除去分类和检测问题本身的复杂性,作者思考了一下这些框架的特点。
我们知道,在做分类问题的时候,从早期的AlexNet、VGGNet到之后的GoogleNet、ResNet使用的模式都是“卷积网络提取特征+全连接层/GAP层做分类”,于是在处理检测问题的时候,这种模式就被自然而然的迁移过来,比如我们之前说过的RCNN系列、SSD等等,也都是采取卷积网络提取特征(加入ROI提取)+RoI Pooling的模式来做检测。
于是作者就此分析了解决分类/检测两种问题的关键:
(1) 分类问题: 其本身要求具有平移不变性。也就是说当目标的位置发生变化时,分类网络能够自动适应位置的变化。
(2) 检测问题: 对目标进行定位的需求要求其具有平移敏感性。由于检测问题需要在图像中对目标进行精确的定位,因此要求整个网络对目标的位置变化更为敏感。
通过先前的学习我们了解到,分类问题中深度卷积网络使得整个模型具有很好的平移不变性,而检测问题中引入的RoI Pooling的操作引入了位置信息。但是作者认为这种做法大大牺牲了训练和测试的效率。
于是作者就此提出了一个新的操作:叫做位敏得分特征图(position-sensitive score maps)。基于这个玩意做出了新的检测框架:Region-based Fully Convolutional Network (R-FCN)。
2 R-FCN框架和细节
2.1 R-FCN整体的网络结构
咱们先来看看整个R-FCN网络的结构:
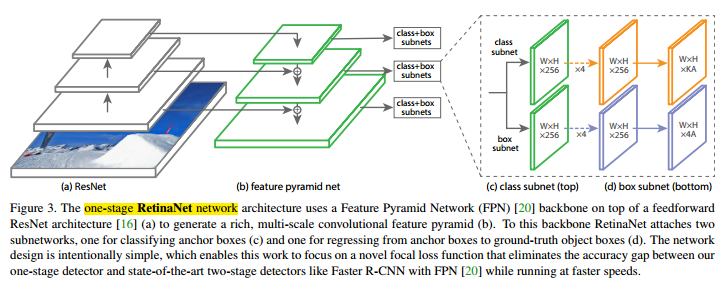
整个网络沿用了Faster-RCNN(可以会看我们的博客Faster RCNN)的框架:卷积网络提取特征,由RPN生成候选框,RPN和特征提取共享卷积网络。
(1) 特征提取部分采用ResNet-101的结构,去掉了最后的GAP层和fc层,并添加了一个1024维的1*1卷积用来降维(原输出是2048维),总共101个卷积层。
(2) RPN部分与Faster-RCNN相同,基本没有变化。
(3) 位敏得分特征图(Position-sensitive score maps) 生成和位敏RoI Pooling(Position-sensitive RoI pooling, PSRoIPooling)部分。(划重点!)
2.2 Position-sensitive score maps(位敏得分特征图,PSSM)
顾名思义,位敏得分特征图就是一个对位移敏感的特征图(废话,,为啥对位移敏感等会儿会说)。这一步的操作是在特征提取部分网络输出的feature map(1024个 w ∗ h w*h w∗h的feature map)后接一个 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)维的 1 ∗ 1 1*1 1∗1卷积层得到 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)个大小为 w ∗ h w*h w∗h的Position-sensitive score maps,这个 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)个score maps代表啥呢?看下图:
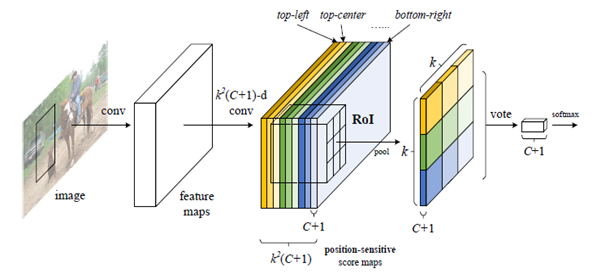
假设将由RPN提取的ROI划分为 k ∗ k k*k k∗k个bin,使用上述的 1 ∗ 1 1*1 1∗1卷积分别获得针对每个bin的激活图(feature map),那么针对其中某一个类别就将获得 k ∗ k k*k k∗k个激活图(feature map),总共有C个类别,加上一个背景类,就将获得 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)个激活图,也就是我们说的Position-sensitive score maps。
【举个栗子】 假设针对“人”这个类别,如下图所示,划分为 k ∗ k k*k k∗k个bin(此处假设k=3),那么每个bin的激活特征是不一样的,得到的Position-sensitive score map当然也是不一样的,比如top-left的bin激活的是人的一侧肩和头的部分,bottom-right的bin激活的是人的一条腿的部分。那么对于一张输入图片将得到 3 ∗ 3 = 9 3*3=9 3∗3=9个bin对应的部分的激活特征图(9张),也就是对应“人”这个类别的Position-sensitive score maps 。


上面的示例中,针对“人”这一个类别生成了 k 2 ( k = 3 ) k^2(k=3) k2(k=3)张位敏特征图,那么扩展到具有C个类别(再加一个背景类)的数据集,就会生成 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)张位敏特征图(Position-sensitive score maps),把每一个类的相同位置的bin对应的特征图放在一起就会是下图所示的样子啦(比如说所有类的左上角的bin对应的激活图都放在一起就得到了下图中深黄色的 ( C + 1 ) (C+1) (C+1) 张Position-sensitive score maps):
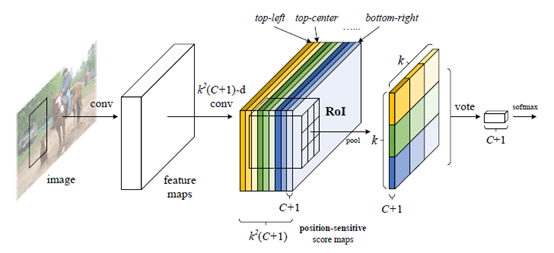
2.3 Position-sensitive RoI pooling(PSROIPooling)
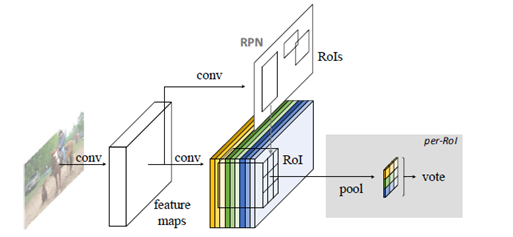
说完了得到Position-sensitive score maps的过程,咱们继续来看看Position-sensitive RoI pooling。根据上面所说的过程,我们得到了 k 2 ( C + 1 ) k^2 (C+1) k2(C+1)张位敏特征得分图,还通过RPN得到了一系列ROI,很自然的想到,接下来做的就是把这些ROI映射到这一堆Position-sensitive score maps上,根据前面所说我们知道每一张 Position-sensitive score map对应着某一个类别的某一个bin,而Position-sensitive RoI pooling所做的就是把对应着相同类别的Position-sensitive score map在ROI映射区域中的相应的bin提取出来,重新拼成一个完整ROI的激活图(说白了就是在每个位敏特征图上提取ROI区域中对应位置bin然后做个重新排列)。这个部分好像说的有点抽象,咱们可以对应论文中的一个示例图来做理解:

接着前面所说的例子,对于一张输入图片的“人”这一类,我们将得到9张不同位置bin在feature map上的激活图(位敏特征图),把提取的ROI映射到这9张位敏特征图上,然后分别提取对应位置bin在ROI中相应的那一块,这样一来就分别从9张图中“抠”出了9个小块,然后把这9个小块分别作average pooling后按照对应位置重新拼成一个 3 ∗ 3 ( k ∗ k ) 3*3(k*k) 3∗3(k∗k)的输出。那么拓展到一个具有C个类别的数据集,结果将得到 ( C + 1 ) (C+1) (C+1)个 k ∗ k k*k k∗k的输出。
2.4 PSSM(位敏得分特征图)和PSROIPooling后的操作
那么问题来了,得到了这个
k
∗
k
k*k
k∗k的输出后该怎么用于分类和定位呢?
首先对于分类: 最后这个输出的每一个类的
k
∗
k
(
3
∗
3
)
k*k(3*3)
k∗k(3∗3)的输出直接进行voting得到最后的得分,文中说明的voting操作是将
k
∗
k
k*k
k∗k个值进行相加。那么对于每一个ROI的
(
C
+
1
)
(C+1)
(C+1)个
k
∗
k
k*k
k∗k输出,我们最后将得到一个
(
C
+
1
)
(C+1)
(C+1)维的输出向量,再使用softmax进行分类。
对于包围框回归: 相似的,对于特征提取卷积层输出的feature map加上一个
4
k
2
4k^2
4k2维的卷积层,得到
4
k
2
4k^2
4k2个用于包围框回归的位敏特征得分图(类似于前面说的
k
2
(
C
+
1
)
k^2 (C+1)
k2(C+1)个用于分类的位敏得分图)。然后采用同样的PSROIPooling操作并进行voting,最后每个ROI得到一个4维的输出用于包围框回归(这4个维度分别对应包围框的
(
t
x
,
t
y
,
t
w
,
t
h
)
(t_x,t_y,t_w,t_h )
(tx,ty,tw,th))。
说到这里我们就可以解释一下为什么这个又奇怪又抽象的操作可以引入位移敏感性了。如图所示,我们得到的这9张位敏特征图都分别真实还原了某一目标的某一部位在原图中的激活位置,如果ROI的位置有偏差,那么分别从9张位敏特征图中抠出来的每一个小块相对真实位置就都是有偏差的,也就是说最后重新拼接起来的3*3的输出中的每一块都是有偏差的,再经过最后的voting操作,这些偏差的累加自然就使得最终的结果对位移具有更高的敏感性了。

3 训练和测试细节
3.1 训练
要说训练,当然先看损失函数啦:
L
(
s
,
t
x
,
y
,
w
,
h
)
=
L
c
l
s
(
s
c
∗
)
+
λ
[
c
∗
>
0
]
L
r
e
g
(
t
,
t
∗
)
L_(s,t_{x,y,w,h}) = L_{cls}(s_{c^*}) + \lambda [c^*>0] L_{reg}(t,{t^*})
L(s,tx,y,w,h)=Lcls(sc∗)+λ[c∗>0]Lreg(t,t∗)
其中
L
c
l
s
(
s
c
∗
)
=
−
l
o
g
(
s
c
∗
)
L_{cls(s_{c^*})}= -log(s_{c^*})
Lcls(sc∗)=−log(sc∗)是分类部分的交叉熵损失,
L
r
e
g
L_{reg}
Lreg是包围框回归部分的损失,采用L1 Smooth。定义 :当对应ground truth的标签为非背景类时
[
c
∗
>
0
]
=
1
[c^*>0]=1
[c∗>0]=1,当标签指示为背景类时
[
c
∗
>
0
]
=
0
[c^*>0]=0
[c∗>0]=0 。RPN产生的区域建议当ROI与ground truth的IOU大于0.5时样本标为正例。
有意思的是,这篇文章里边再一次提到了难例挖掘(hard example mining,OHEM)。原文的描述是:假设对一张输入图像提取得到了N个proposals,经过前向运算计算所有N个proposals的损失,然后按损失将所有ROIs排序,选出损失最高的B个ROIs进行反向传播。
【一些训练小细节】
(1) 使用了0.0005的权重衰减系数和0.9的动量;
(2) 使用单一尺寸图像进行训练,把输入图像resize为短边为600像素的统一尺寸;使用非极大值抑制,IOU阈值设置为0.3;
(3) 本文还用了一个有意思的小tip:“Hole algorithm”. 作者试图通过减小某些卷积层的步长来提升输出的feature map的分辨率,按文中介绍:保持ResNet101的conv4以前(包括conv4)的步长(32)不变,把conv5中的第一个卷积(conv5_1)步长改为1,而conv5中之后的其他卷积将使用Hole算法用来弥补。本文中作者把这叫做 “à trous trick”
Hole 算法是个啥?
我们知道,将某个卷积层的步长减小会导致感受野的减小,如何来弥补这一点呢?在论文 “Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFS” 中作者为了解决这一问题提出了Hole算法,当缩小了步长后,通过“skip”连接来保持感受野不变,如下图所示:
(参考论文:Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFS.
参考博客:https://blog.csdn.net/tangwei2014/article/details/50453334)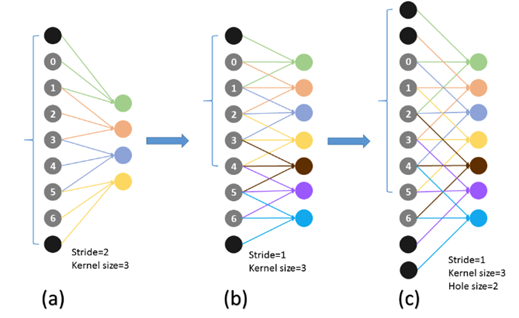
作者也对比了减小/不减小步长、使用/不使用Hole算法对结果的影响,结果如下表所示:

4 实验结果
4.1 使用PASCAL VOC数据集
作者对比了当前几种全卷积(或接近全卷积)检测算法在PASCAL VOC数据集上的表现,结果如下表所示:
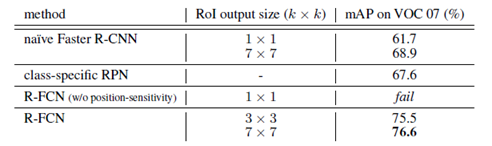
其中移除位移敏感特性的RFCN是通过设置k=1来实现的。表中所列的几种框架都使用了à trous trick。
RFCN和Faster-RCNN的比较:
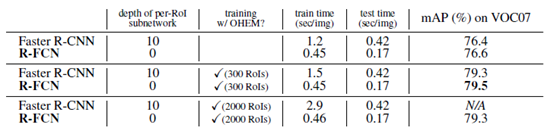
进一步的比较:
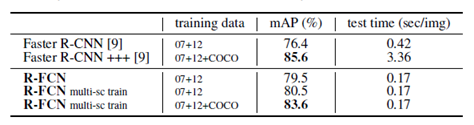
此处尝试使用多尺度图像训练RFCN,包括{400,500,600,700,800}五种尺寸。
进一步使用VOC2007+VOC2012的训练集训练结果:
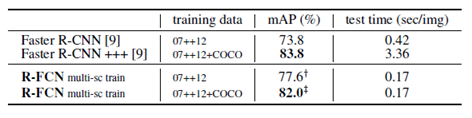
继续尝试使用不同深度的ResNet做对比实验:

尝试使用不同的候选框生成算法作对比试验:

4.2 使用 MS COCO数据集
各种对比大合集:
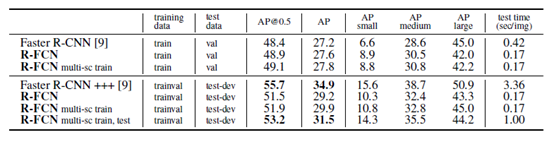
5 总结(重点!!!)
从实验结果来看RFCN还是一个非常优秀的算法的,总结一下:
(1) 提出相同网络在检测问题中的应用效果远不如在分类问题中的效果,是因为检测问题要求算法在一定程度上有较好的位移敏感性。
(2) 提出了位敏得分特征图(Position-sensitive score maps)和对应的Position-sensitive ROI Pooling,有效的编码了目标的位置信息,增强了位移敏感性。
(3) 还使用了à trous trick,引入了Hole算法(不是创新点,算是一个小tips吧)
(4) 从最后的结果展示来看,为了全方位的展示RFCN的优秀,作者做的对比实验可以说是非常多了,而且对比实验的设置覆盖面也相当广,这是一个值得学习的点,多做实验还是很有必要的。