【Paper】Focal Loss for Dense Object Detection
1. Background of object detection
首先我们回顾单阶段目标检测(One-Stage)是如何实现的:

上图是YOLO的框架针对一张图片featuremap的变化,可以看到,网络输出的结果是对所有预设集合的分类与回归。
总损失函数如下:
(1)
L
(
p
i
,
t
i
)
=
1
N
c
l
s
∑
i
(
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
(
p
i
∗
)
L
r
e
g
(
t
i
,
t
i
∗
)
L({p_i},{t_i})=\frac{1}{N_{cls}}\sum_i(L_{cls}(p_i,p_i^*) +\lambda\frac{1}{N_{reg}}\sum_i(p_i^*)L_{reg}(t_i,t_i^*)\tag1
L(pi,ti)=Ncls1i∑(Lcls(pi,pi∗)+λNreg1i∑(pi∗)Lreg(ti,ti∗)(1)
上式为损失函数计算的方式,
p
i
p_i
pi为某个ROI的分类结果,
t
i
t_i
ti为回归结果;
我们可以推算出整个前向后向传播的流程:首先我们以滑窗的方式在图片每个固定的区域生成一些假设框,并在通过将图片像素矩阵经过网络之后对每一个假设框进行分类,其中很重要的一个因素就是背景类。得到分类结果之后,对这些每一个分类结果和其gt相比较,求得每一个预设框结果的损失加和之后对按照数量N求均值得到本次bacth的loss,并回传给网络进行后向传播。
由上述程序得知,每一个batch的损失是由所有图片上的所有预设框的结果来共同求出的,通过优化函数就可以减小loss。
观察分类损失函数如下:
(2)
C
E
(
p
,
y
)
=
{
−
log
(
p
)
,
i
f
y
=
1
−
log
(
1
−
p
)
,
o
t
h
e
r
w
i
s
e
CE(p,y)=\begin{cases} -\log(p),if\quad y=1\\ -\log(1-p), otherwise\end{cases}\tag2
CE(p,y)={−log(p),ify=1−log(1−p),otherwise(2)
上式为交叉熵损失函数,对于每个预测结果而言,只利用预测的结果在该类别的概率即可得到回传的总损失。上式损失函数的图象如下:
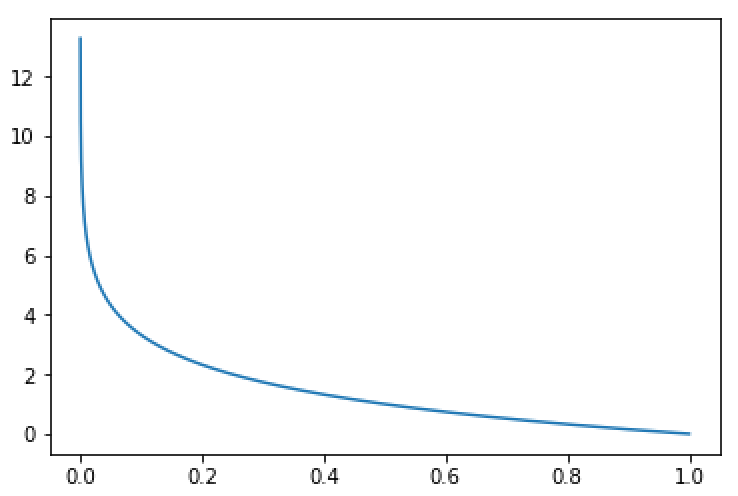
图1:cross-entropy for binary classification
横轴为概率值,纵轴为计算的损失,可以看到,对于某个预测框,gt类别的预测结果概率越大,回传损失越小。【这也是解释了为什么交叉熵函数可以作为损失函数】
2. the main problem of single detector
单阶段的检测器效果一直赶不上双阶段的,直接原因与模型复杂度有关,但随着网络的加深和模型越来越复杂,这个原因的影响应当越来越小,那么应该是其他原因造成。将单阶段与双阶段的检测器结构比较来看,双阶段检测器多了在前向和后向传播过程中挑选样本的步骤,可以将预设框中的大量背景样本去掉,只保留固定比例的正例和负例。那么保持固定正负样本比例有什么意义呢?
结合式子(1),回传的损失和整个batch的所有预测框的结果有关,当负例的样本远大于正例的样本(1000:1),由于任务的和网络结构的复杂性导致很难找到完全的所有的正例负例分开,那么模型学至将所有的正例全部学为负例的话,由于最后会根据所有的预选框的数量求均值,当正负样本比例足够小,那么尽管单个正样本会得到很高的损失,总的损失却会降低。
其次,由于负样本数量过多,尽管每个负样本的损失较少,但所有负样本加和之后还是要远大于正样本的损失,因此在损失中实际上负样本带来的损失要占主要方面,模型的预测也会倾向于负例。
【因此优化器所带来损失的下降,不一定代表模型分类能力的上升,也可以理解为正负样本的类别不平衡】
3. Focal loss for imbalance
根据上述描述,提出单阶段检测器的主要问题是回传损失中正样本所占比例过小,模型学习任务从分类转为了对负样本的回归。
解决的直接思路自然就是提高每个batch中正样本的损失比例,hard negtive mining是一种方式,给不同种类的样本加不同的权重也是一种方式,focal loss属于后者。
首先对(2)式进行变化,得到
p
t
=
{
p
,
i
f
y
=
1
1
−
p
,
o
t
h
e
r
w
i
s
e
p_t=\begin{cases} p,if\quad y=1\\ 1-p, otherwise\end{cases}
pt={p,ify=11−p,otherwise
进而得到: C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p,y)=CE(p_t)=-log(p_t) CE(p,y)=CE(pt)=−log(pt)

相对于调整整个回传损失中正负样本的数量比例,Focal loss选择调整单个样本在损失器中的回传损失。根据上述假设,模型经过学习学习到了倾向于将所有样本学为数量较多的负例,那么在图1中,正样例的概率在0-0.5之间,负样本的概率在0.5-1之间。
Focal loss:
F
L
(
p
t
)
=
−
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
FL(p_t)=-(1-p_t)^{\gamma}log(p_t)
FL(pt)=−(1−pt)γlog(pt)
相对于原式,增加了一个根据概率值发生改变的权重:
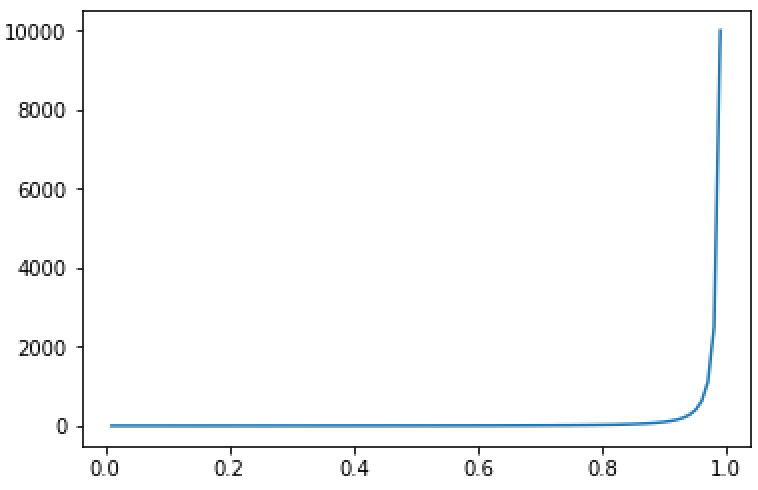
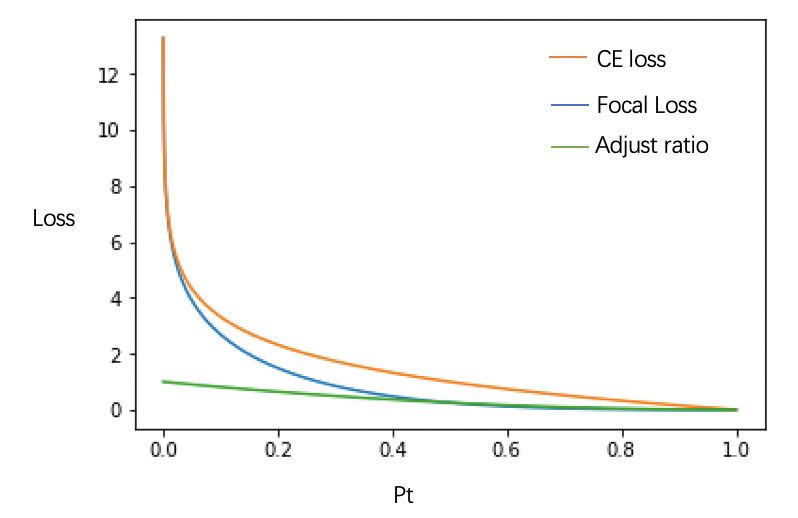
图3:概率值改变的权重曲线
可以看到,随着概率的增长,相对而言损失减少的比例会逐渐加大。当概率0.9时,损失产生减少了一百倍,0.98时,损失减少了1000倍,后期虽然而概率较小时产生的较大概率却不会影响太多,从而起到了调整单个样本中正负样本产生损失比例,继而调整整个训练batch中的正负样本所占损失比例。
5. RetinaNet
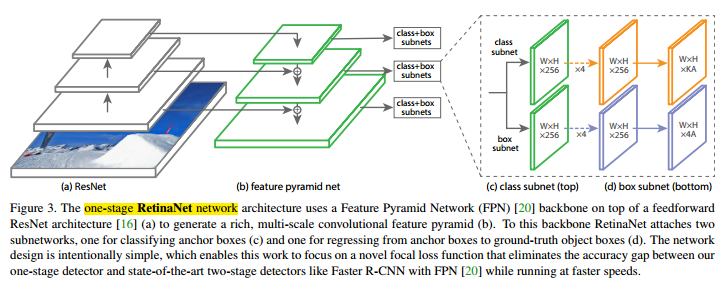
上图所示的是RetinaNet的网络结构,个人理解这是对于之前的优秀的目标检测的一种综合,它用了之前很多非常好的思想,比如说FPN(特征金字塔)等等。具体的请参见论文。
4. Focal Loss总结
其实作者的思路很简单,作者想知道为什么One-stage的目标检测不如Two-stage的目标检测框架效果好,提出了造成这种差异的根本原因是类别不平衡(可以理解为前景类和背景类的不平衡,也可以理解为正负样本的不平衡)。这种类别不平衡在Two-stage中是用RPN来抑制的(因为RPN可以判断Anchor的类别,是前景还是背景,减少了Anchor的数量),而在One-stage中可以用加权的损失函数来解决这一问题,这也是Focal Loss提出的主要思路(给正样本更大的权重,给负样本更小的权重,使正样本在损失函数中贡献更大)。
准确来讲,focal loss是通过检测问题中正负样本数量差距过大的场景来解决分类问题中样本不均衡的问题,类推到其他场景如图像分类以及分割等多分类问题也会有很好的效果,而且整个损失函数的形式也不拘束于论文中的形式,一切可以平滑的按概率对损失进行不同程度的抑制或加强的方法都可以使用,而且论文中依然使用了 α = 0.25 \alpha=0.25 α=0.25这个参数来进一步抑制整体损失,这样可以让损失趋向于0的范围更广,可以根据样本不均衡的程度酌情考虑。
【补充】 有的公司会在面试时问关于Focal Loss的问题,也把这个问题放上来仅供大家参考一下(虽然也不知道是不是标答面试官也没给答案,但是也写一下自己的理解,欢迎各位大佬补充答疑)
【面试官问】 Focal Loss可以解决类别不平衡的问题,还有其他的损失函数可以达到Focal Loss的效果么?
【个人理解】 其实对于这种问题的关键就是Focal Loss的思路是怎么样的,Focal Loss的思路就是将之前普通的交叉熵损失函数变成了平滑加权的交叉熵损失函数,那么重点就是如何变成平滑加权的,Focal Loss选择的是乘以一个 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ的系数,也就是说,我们只要选择任意一个函数(函数必须满足的条件:单调连续增函数,且在趋于0时取较小值,趋于1时取较大值,理想状态是趋于1时变化更快,即函数曲线类似图3)即可。