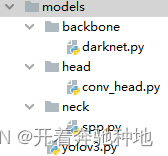
用torch从0简单实现一个的yolov3模型,主要分为Backbone、Neck、Head三部分
目录
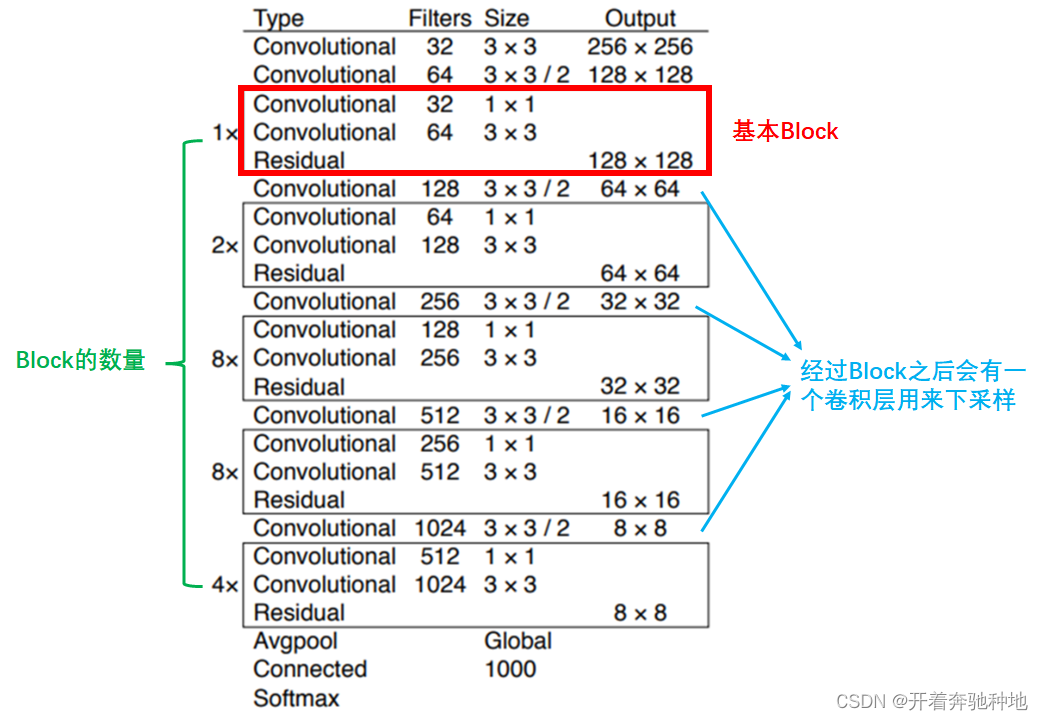
Backbone:DarkNet53
结构简介
- 输入层:接受图像数据作为模型输入,以长宽均为640像素的图像为例:(BatchSize,3,640,640)
- 隐藏层:
- 残差块:每个残差块由多个卷积(Conv)、批归一化(BN)、激活函数(Relu)组成
- 下采样:利用 stride = 2 的卷积层来进行下采样,减小特征图尺寸
- 输出层:保留最后3个尺度的特征图并返回
代码实现
Step1:导入相关库
import torch
import torch.nn as nn
from torchsummary import summary
Step2:搭建基本的Conv-BN-LeakyReLU
- 一层卷积 + 一层B批归一化 + 一层激活函数
def ConvBnRelu(in_channels, out_channels, kernel_size=(3,3), stride=(1,1), padding=1):
"""
一层卷积 + 一层 BatchNorm + 一层激活函数
:param in_channels: 输入维度
:param out_channels: 输出维度(卷积核个数)
:param kernel_size: 卷积核大小
:param stride: 卷积核步长
:param padding: 填充
:return:
"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU())
Step3:组成残差连接块
- 小单元:ConvBNRelu
- 堆叠两个小单元
- 残差连接
class DarkResidualBlock(nn.Module):
"""
DarkNet残差单元
"""
def __init__(self, channels):
super(DarkResidualBlock, self).__init__()
reduced_channels = int(channels // 2)
self.layer1 = ConvBnRelu(channels, reduced_channels, kernel_size=(1,1), padding=0)
self.layer2 = ConvBnRelu(reduced_channels, channels)
def forward(self, x):
residual = x
out = self.layer1(x)
out = self.layer2(out)
out += residual # 残差连接
return out
Step4:搭建DarkNet53
- 根据DarkNet各block的个数搭建网络模型
- conv1用来把输入3维的图片卷积卷成32维
- conv2 ~ conv6 都会用一个stride = 2的卷积层进行下采样
- 每一个residual_block都是带有残差连接的2层ConvBNRelu
- 原始DarkNet是用来做图像分类,作为Backbone只需要提取最后3个尺度特征图就好,不需要最后的池化层和全连接层
class DarkNet53(nn.Module):
"""
Darknet53网络结构
"""
def __init__(self, in_channels = 3, num_classes = 80, backbone = True):
"""
:param in_channels:
:param num_classes:
:param backbone:
"""
super(DarkNet53, self).__init__()
self.backbone = backbone
self.num_classes = num_classes
# blocks : [1,2,8,8,4]
self.conv1 = ConvBnRelu(in_channels,32)
self.conv2 = ConvBnRelu(32,64,stride=2)
self.residual_block1 = self.make_layer(DarkResidualBlock, in_channels=64, num_blocks=1)
self.conv3 = ConvBnRelu(64,128,stride=2)
self.residual_block2 = self.make_layer(DarkResidualBlock, in_channels=128, num_blocks=2)
self.conv4 = ConvBnRelu(128,256,stride=2)
self.residual_block3 = self.make_layer(DarkResidualBlock, in_channels=256, num_blocks=8)
self.conv5 = ConvBnRelu(256,512,stride=2)
self.residual_block4 = self.make_layer(DarkResidualBlock, in_channels=512, num_blocks=8)
self.conv6 = ConvBnRelu(512,1024,stride=2)
self.residual_block5 = self.make_layer(DarkResidualBlock, in_channels=1024, num_blocks=4)
self.global_avg_pooling = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(1024, self.num_classes)
def make_layer(self, block, in_channels, num_blocks):
"""
构建 num_blocks 个 conv_bn_relu, 组成residual_block
:param block: 待堆叠的 block : DarkResidualBlock
:param in_channels: 输入维度
:param num_blocks: block个数
:return:
"""
layers = []
for i in range(num_blocks):
layers.append(block(in_channels))
# print(*layers)
return nn.Sequential(*layers)
def forward(self, x):
features = []
out = self.conv1(x) # 3 -> 32
out = self.conv2(out) # 下采样
out = self.residual_block1(out)
out = self.conv3(out) # 下采样
out = self.residual_block2(out)
out = self.conv4(out) # 下采样
out = self.residual_block3(out) # fea1 : 8倍下采样
fea1 = out
out = self.conv5(out) # 下采样
out = self.residual_block4(out) # fea2 : 16倍下采样
fea2 = out
out = self.conv6(out) # 下采样
out = self.residual_block5(out) # fea3 : 32倍下采样
fea3 = out
out = self.global_avg_pooling(out)
out = out.view(-1, 1024)
out = self.fc(out)
if self.backbone: # 返回最后3个尺度特征图
features = [fea1, fea2, fea3]
return features
return out
Step5: 测试
if __name__ == '__main__':
x = torch.randn(size=(4,3,640,640))
model = DarkNet53(backbone=True)
out = model(x)
print(summary(model, (3,640,640), device='cpu'))
for x in out:
print(x.shape)

通过以上Backbone后提取到输入图片的3个尺度特征图,640*640的图片分别经过8倍、16倍、32倍下采样得到80×80,40×40,20×20的特征图,随着尺度的增加,通道维度也随之增加
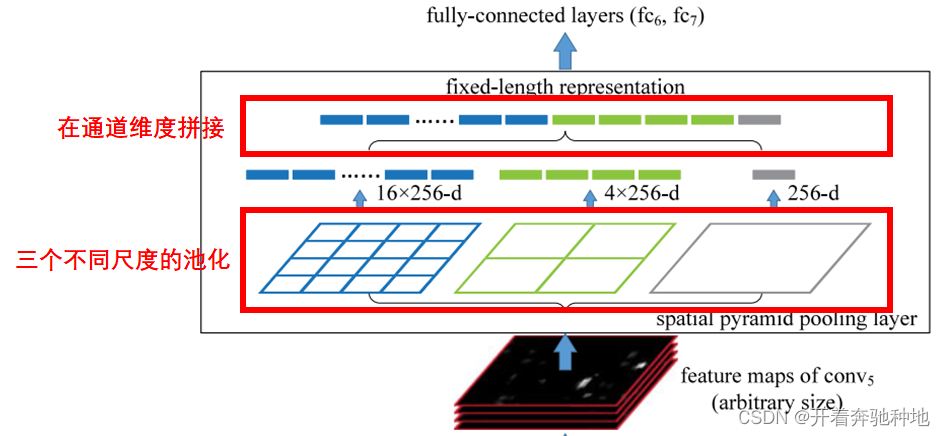
Neck:Spatial Pyramid Pooling(SPP)
结构简介
采用空间金字塔池化层,用于处理不同尺度的特征信息
- 输入层:DarkNet53出来的特征图
- 隐藏层:
- 空间金字塔池化(Spatial Pyramid Pooling):一种多尺度池化的策略,允许网络在处理不同尺寸的目标时更加灵活。通过使用不同大小的池化核或步幅,该模块将输入特征图划分为多个不同大小的网格,然后对每个网格进行池化操作。这些池化操作的结果被连接在一起,形成一个具有多尺度信息的特征向量。
- 连接全局平均池化:除了空间金字塔池化,全局平均池化也通常被添加到模块的最后一层。这有助于捕捉整个特征图的全局上下文信息。全局平均池化将整个特征图降维为一个固定大小的特征向量。
- 通道扩展:为了进一步提高语义信息的表达能力,通常会添加适量的卷积操作,增加特征图的通道数。
- 输出层:输出特征图,保持与输入特征尺寸和维度一致
代码实现
Step1 导入相关库
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
Step2 搭建SPPLayer
主要两个模块:
- 池化层:根据pool_size进行多尺度池化
- 卷积层:变换拼接后的特征图维度,保证前后特征图大小一致
class SPPLayer(nn.Module):
def __init__(self, channels, pool_sizes = [1,2,4]):
super(SPPLayer, self).__init__()
self.pool_sizes = pool_sizes
self.num_pools = len(pool_sizes)
# num_pools个池化层
self.pools = nn.ModuleList()
for pool_size in pool_sizes:
self.pools.append(nn.AdaptiveAvgPool2d(pool_size))
# 卷积层 1*1
self.conv = nn.Conv2d(channels * (1 + self.num_pools), channels, kernel_size=(1,1), stride=(1,1),padding=0)
def forward(self, x):
# 保存 h,w
input_size = x.size()[2:]
# 池化 + 插值
# 池化后插值回原始特征图大小
pool_outs = [F.interpolate(pool(x), size=input_size, mode='bilinear')for pool in self.pools]
# 拼接
spp_out = torch.cat([x] + pool_outs, dim = 1) # 通道维度拼接
# conv
spp_out = self.conv(spp_out)
return spp_out
Step3 测试
if __name__ == '__main__':
x = torch.randn(size=(4,256,80,80)) # 取backbone出来的第一个尺度特征图
model = SPPLayer(channels = 256, pool_sizes = [1,2,4,8]) # 4个不同尺度的池化层
out = model(x)
print('SppLayer output shape: ', out.shape) # (4,256,80,80)

Head:Conv
结构简介
head部分采用最简单的两层卷积结构,将每一个尺度的特征图维度变换为 (4 + 1 + num_classes) * num_anchors
- 4:每个框有4个坐标值(xyxy或xywh),这四个值表示锚框的偏移量
- 1:每个锚框包含目标的概率
- num_classes:检测类别数量
- num_anchors:锚框数量
代码实现
Step1 模型搭建
import torch
import torch.nn as nn
class BaseHead(nn.Module):
def __init__(self,in_channels, num_anchors, num_classes):
super(BaseHead, self).__init__()
# 没有算上背景类
self.predict = nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=(1, 1), stride=(1, 1), padding=0),
nn.Conv2d(in_channels, num_anchors * (4 + 1 + num_classes), kernel_size=(1, 1), stride=(1, 1), padding=0)
)
def forward(self, x):
x = self.predict(x)
return x
Step2 测试
if __name__ == '__main__':
# 示例:创建一个具有3个锚框和80个类别的检测头
detection_head = BaseHead(in_channels=256, num_anchors=3, num_classes=80)
# Neck部分出来的特征图(256通道,80*80的特征图)
example_input = torch.randn((4, 256, 80, 80))
# 前向传播
output = detection_head(example_input)
# 打印输出形状
print('head out shape',output.shape)

255 = (4 + 1 + 80) * 3 <==> num_anchors * (4 + 1 + num_classes)
YOLOV3_291">YOLOV3
模型简介
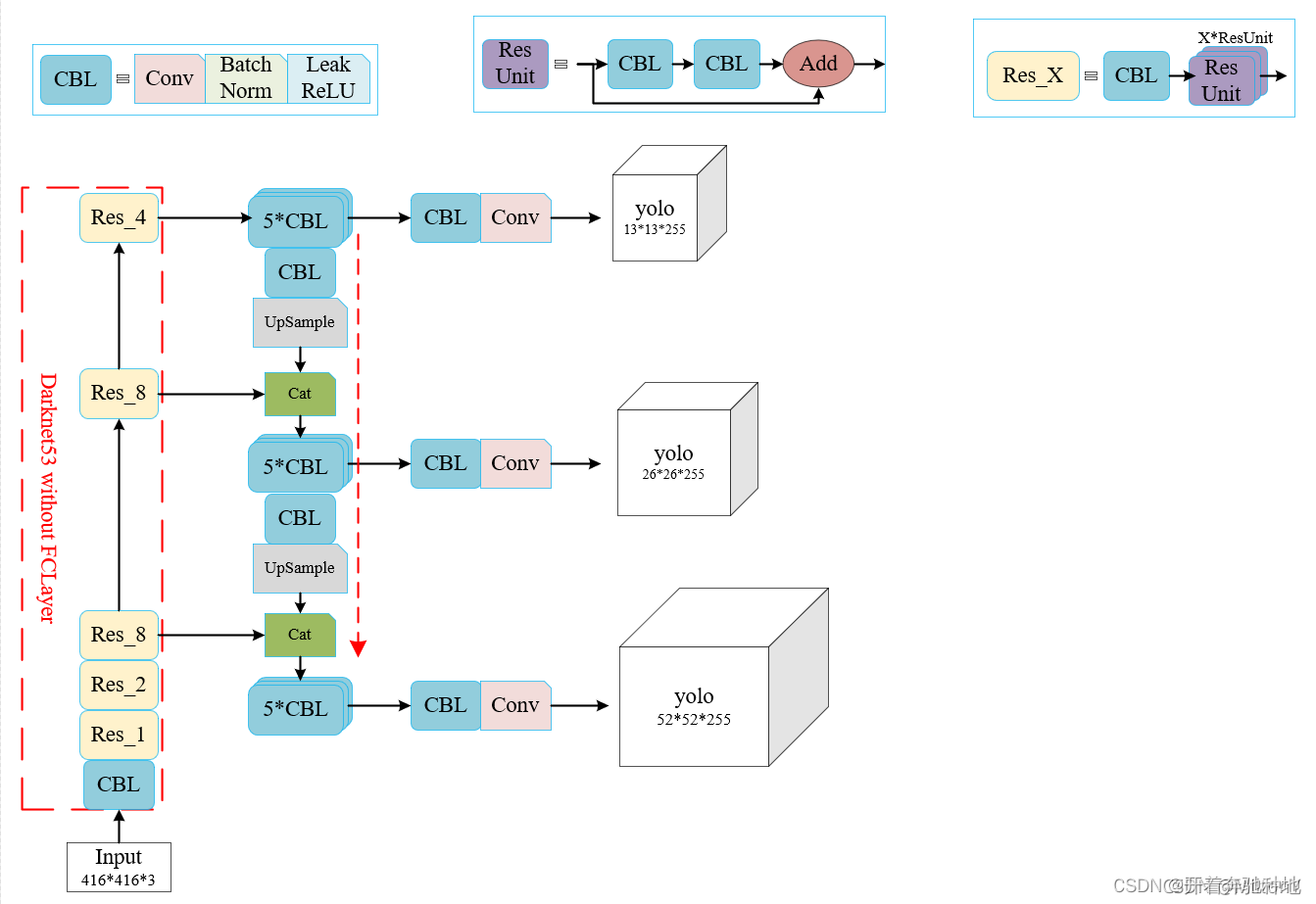
在搭建好backbone、neck、head后,拼成YOLOv3,注意3个尺度特征图分别检测。图片摘自此处
代码实现
Step1 导入上述三个模块和相关库
import torch
import torch.nn as nn
from models.backbone.darknet import DarkNet53
from models.head.conv_head import BaseHead
from models.neck.spp import SPPLayer
YOLOV3_309">Step2 搭建YOLOV3模型
class YOLOv3(nn.Module):
def __init__(self, in_channels, num_anchors, num_classes=80):
super(YOLOv3, self).__init__()
self.in_channels = in_channels
self.num_anchors = num_anchors
self.backbone = DarkNet53(in_channels=in_channels, backbone=True)
# 单尺度
self.neck = SPPLayer(channels=256)
self.head = BaseHead(in_channels=256, num_anchors=num_anchors, num_classes=num_classes)
# #多尺度
self.neck1 = SPPLayer(channels=256)
self.neck2 = SPPLayer(channels=512)
self.neck3 = SPPLayer(channels=1024)
# Detection heads for three scales
self.head1 = BaseHead(in_channels=256, num_anchors=num_anchors, num_classes=num_classes)
self.head2 = BaseHead(in_channels=512, num_anchors=num_anchors, num_classes=num_classes)
self.head3 = BaseHead(in_channels=1024, num_anchors=num_anchors, num_classes=num_classes)
def forward(self, x):
output = []
x = self.backbone(x) # DarkNet53提取3个尺度的特征:list
# 单尺度
# x = self.neck(x[0])
# out = self.neck(x)
# output.append(out)
# return output
# 多尺度
## neck
x[0] = self.neck1(x[0])
x[1] = self.neck2(x[1])
x[2] = self.neck3(x[2])
## head
x[0] = self.head1(x[0])
x[1] = self.head2(x[1])
x[2] = self.head3(x[2])
for xi in x:
output.append(xi)
return output
Step3 测试
if __name__ == '__main__':
yolov3_model = YOLOv3(in_channels=3, num_classes=80, num_anchors=3)
x = torch.randn(size=(4,3,640,640))
# 3 * (5 + num_classes)
out = yolov3_model(x)
for i, o in enumerate(out):
print(f"output {i} shape: ", o.shape)

得到三个尺度的特征图,每个特征图对应着255维(head部分有介绍),后续通过通过解码得到锚框的位置和类别计算得到相应的loss和map等评价指标。