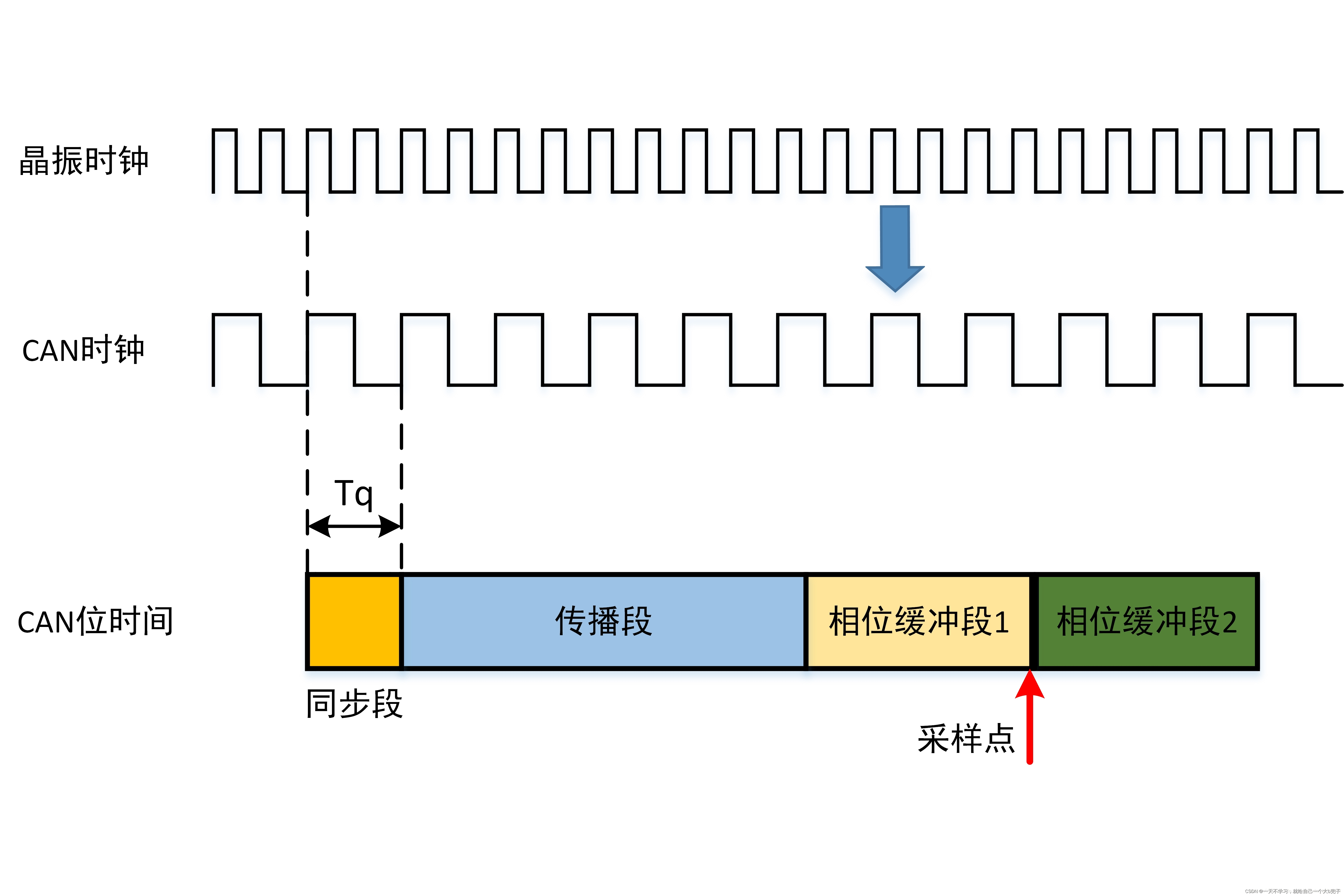
1、准备和环境
首先需要将yolov5模型训练好的最佳权重文件转化为.onnx格式以备使用。不会的小伙伴可以参考yolov5的官方文档,使用yolov5官方的 export.py 脚本进行转换,或者参考一些博客链接,这里不做详细解析。
基本环境配置,相比于yolov5模型源码部署,使用onnx的方式部署会省下不少配置环境的问题,只需要几个关键的第三方库即可完成。
numpy>=1.22.3
onnxruntime>=1.13.1
Pillow>=9.3.0
python-multipart>=0.0.5
fastapi>=0.88.0
python-multipart>=0.0.5
uvicorn[standard]
2、部署代码
2.1、main.py
主文件主要调用
python">from PIL import Image,ImageDraw,ImageFont
from utils.operation import YOLO
from utils.Colors import colors
import numpy as np
from matplotlib import pyplot as plt
def draw_anchor(img,det_obj):
img = Image.open(img)
draw = ImageDraw.Draw(img)
font = ImageFont.truetype('arial.ttf', 30)
imgw,imgh = img.size
colors_dt = dict()
for i in range(len(det_obj)):
if colors_dt.get(det_obj[i]['classes']) is None:
colors_dt[det_obj[i]['classes']] = colors(i,True)
draw.rectangle(det_obj[i]['crop'],width=3,outline=colors_dt[det_obj[i]['classes']])
x1, y1, x2, y2 = tuple(det_obj[i]['crop'])
draw.text((x1,y1-35),det_obj[i]['classes'],fill=colors_dt[det_obj[i]['classes']],font=font)
imgarr = np.array(img)
plt.imshow(imgarr)
plt.show()
img.show()
def detect(onnx_path='ReqFile/yolov5s.onnx',img=r'ReqFile/bus.jpg',show=True):
'''
检测目标,返回目标所在坐标如:
{'crop': [57, 390, 207, 882], 'classes': 'person'},...]
:param onnx_path:onnx模型路径
:param img:检测用的图片
:param show:是否展示
'''
#加载yolo
yolo = YOLO(onnx_path=onnx_path) # 加载yolo类
#检测
det_obj = yolo.decect(img,conf_thres=0.5, iou_thres=0.25) # 检测
#画锚框
draw_anchor(img,det_obj)
if __name__ == '__main__':
detect()
pass
2.2、operation.py
python">from io import BytesIO
import onnxruntime
import numpy as np
from PIL import Image
from utils.orientation import non_max_suppression, tag_images
class ONNXModel(object):
def __init__(self, onnx_path):
"""
:param onnx_path:
"""
self.onnx_session = onnxruntime.InferenceSession(onnx_path)
self.input_name = self.get_input_name(self.onnx_session)
self.output_name = self.get_output_name(self.onnx_session)
def get_output_name(self, onnx_session):
"""
output_name = onnx_session.get_outputs()[0].name
:param onnx_session:
:return:
"""
output_name = []
for node in onnx_session.get_outputs():
output_name.append(node.name)
return output_name
def get_input_name(self, onnx_session):
"""
input_name = onnx_session.get_inputs()[0].name
:param onnx_session:
:return:
"""
input_name = []
for node in onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_input_feed(self, input_name, image_numpy):
"""
input_feed={self.input_name: image_numpy}
:param input_name:
:param image_numpy:
:return:
"""
input_feed = {}
for name in input_name:
input_feed[name] = image_numpy
return input_feed
def to_numpy(self, file, shape, gray=False):
if isinstance(file, np.ndarray):
img = Image.fromarray(file)
elif isinstance(file, bytes):
img = Image.open(BytesIO(file))
pass
else:
img = Image.open(file)
widht, hight = shape
# 改变大小 并保证其不失真
img = img.convert('RGB')
if gray:
img = img.convert('L')
img = img.resize((widht, hight), Image.ANTIALIAS)
# 转换成矩阵
image_numpy = np.array(img) # (widht, hight, 3)
if gray:
image_numpy = np.expand_dims(image_numpy,0)
image_numpy = image_numpy.transpose(0, 1, 2)
else:
image_numpy = image_numpy.transpose(2,0,1) # 转置 (3, widht, hight)
image_numpy = np.expand_dims(image_numpy,0)
# 数据归一化
image_numpy = image_numpy.astype(np.float32) / 255.0
return image_numpy
class YOLO(ONNXModel):
def __init__(self, onnx_path="ReqFile/yolov5n-7-k5.onnx"):
super(YOLO, self).__init__(onnx_path)
# 训练所采用的输入图片大小
self.img_size = 640
self.img_size_h = self.img_size_w = self.img_size
self.batch_size = 1
#数量
self.num_classes = 2
#标签
self.classes = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush']
def to_numpy(self, file, shape, gray=False):
def letterbox_image(image, size):
iw, ih = image.size
w, h = size
scale = min(w / iw, h / ih)
nw = int(iw * scale)
nh = int(ih * scale)
image = image.resize((nw, nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128, 128, 128))
new_image.paste(image, ((w - nw) // 2, (h - nh) // 2))
return new_image
if isinstance(file, np.ndarray):
img = Image.fromarray(file)
elif isinstance(file, bytes):
img = Image.open(BytesIO(file))
else:
img = Image.open(file)
resized = letterbox_image(img, (self.img_size_w, self.img_size_h))
img_in = np.transpose(resized, (2, 0, 1)).astype(np.float32) # HWC -> CHW
img_in = np.expand_dims(img_in, axis=0)
img_in /= 255.0
return img_in
def decect(self, file,conf_thres=0.25, iou_thres=0.45):
# 图片转换为矩阵
image_numpy = self.to_numpy(file, shape=(self.img_size, self.img_size))
input_feed = self.get_input_feed(self.input_name, image_numpy)
outputs = self.onnx_session.run(self.output_name, input_feed=input_feed)
pred = non_max_suppression(outputs[0],conf_thres, iou_thres)
if pred:
res = tag_images(np.array(Image.open(file)), pred, self.img_size, self.classes)
else:
res = []
return res
2.3、orientation.py
python">import time
import numpy as np
#用于控制Python中小数的显示精度
np.set_printoptions(precision=4)
def rescale_boxes(boxes, current_dim, original_shape):
""" Rescales bounding boxes to the original shape """
orig_h, orig_w = original_shape
# The amount of padding that was added
pad_x = max(orig_h - orig_w, 0) * (current_dim / max(original_shape))
pad_y = max(orig_w - orig_h, 0) * (current_dim / max(original_shape))
# Image height and width after padding is removed
unpad_h = current_dim - pad_y
unpad_w = current_dim - pad_x
# Rescale bounding boxes to dimension of original image
boxes[:, 0] = ((boxes[:, 0] - pad_x // 2) / unpad_w) * orig_w
boxes[:, 1] = ((boxes[:, 1] - pad_y // 2) / unpad_h) * orig_h
boxes[:, 2] = ((boxes[:, 2] - pad_x // 2) / unpad_w) * orig_w
boxes[:, 3] = ((boxes[:, 3] - pad_y // 2) / unpad_h) * orig_h
return boxes
def tag_images(imgs, img_detections, img_size, classes):
imgs = [imgs]
results = []
for img_i, (img, detections) in enumerate(zip(imgs, img_detections)):
# Create plot
if detections is not None:
# Rescale boxes to original image
detections = rescale_boxes(detections, img_size, img.shape[:2])
for x1, y1, x2, y2, conf, cls_pred in detections:
results.append(
{
"crop": [int(i) for i in (x1, y1, x2, y2)],
"classes": classes[int(cls_pred)]
}
)
else:
print("识别失败")
return results
# 识别结果解析
def xywh2xyxy(x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2]
# where xy1=top-left, xy2=bottom-right
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def nms(dets, scores, thresh):
"""Pure Python NMS baseline."""
# x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0] # xmin
y1 = dets[:, 1] # ymin
x2 = dets[:, 2] # xmax
y2 = dets[:, 3] # ymax
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# argsort()返回数组值从小到大的索引值
order = scores.argsort()[::-1]
keep = []
while order.size > 0: # 还有数据
i = order[0]
keep.append(i)
if order.size == 1: break
# 计算当前概率最大矩形框与其他矩形框的相交框的坐标
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
# 计算相交框的面积
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 计算重叠度IOU:重叠面积/(面积1+面积2-重叠面积)
IOU = inter / (areas[i] + areas[order[1:]] - inter)
left_index = (np.where(IOU <= thresh))[0]
# 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要把这个1加回来
order = order[left_index + 1]
return np.array(keep)
def non_max_suppression(prediction, conf_thres, iou_thres, classes=None, agnostic=False, multi_label=False,
labels=()):
"""Runs Non-Maximum Suppression (NMS) on inference results
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
nc = prediction.shape[2] - 5
xc = prediction[..., 4] > conf_thres # candidates
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms()
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
t = time.time()
output = [np.zeros((0, 6))] * prediction.shape[0]
for xi, x in enumerate(prediction):
x = x[xc[xi]] # confidence
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = np.zeros((len(l), nc + 5))
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = np.concatenate((x, v), 0)
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero()
x = np.concatenate((box[i], x[i, j + 5, None], j[:, None]), 1)
else: # best class only
conf = x[:, 5:].max(1, keepdims=True)
j = x[:, 5:].argmax(1)
j = np.expand_dims(j, 0).T
x = np.concatenate((box, conf, j), 1)[conf.reshape(1, -1)[0] > conf_thres]
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == np.array(classes)).any(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes
continue
elif n > max_nms: # excess boxes
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = nms(boxes, scores, iou_thres) # NMS
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
output[xi] = x[i]
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output
3、测试

完整文件请参考:
https://pan.baidu.com/s/1X1DiywM8yJtBzysKfzqbcA
提取码:6666

![安网AC智能路由系统actpt_5g.data敏感信息泄露漏洞复现 [附POC]](https://img-blog.csdnimg.cn/direct/3e23cff5a0a24ee2aec3cb6b020bf351.png)