之——物体检测和数据集
目录
之——物体检测和数据集
杂谈
正文
1.目标检测
2.目标检测数据集
3.目标检测和边界框
4.目标检测数据集示例
杂谈
目标检测是计算机视觉中应用最为广泛的,之前所研究的图片分类等都需要基于目标检测完成。
在图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。 然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)。
以下是一些主流的目标检测算法。请注意,领域中的进展可能导致新的算法和方法的出现,因此建议查阅最新的文献和研究以获取最新信息。
Faster R-CNN (Region-based Convolutional Neural Network): Faster R-CNN是一种经典的目标检测框架,它引入了区域提议网络(Region Proposal Network,RPN)来生成候选区域,然后使用分类器和回归器来完成目标检测。
YOLO (You Only Look Once): YOLO是一种实时目标检测算法,通过将图像划分为网格并在每个网格上预测边界框和类别,实现了高效的目标检测。YOLO的多个版本,如YOLOv2、YOLOv3、YOLOv4,都在改进性能和精度方面进行了优化。
SSD (Single Shot Multibox Detector): SSD是一种单阶段的目标检测算法,它直接在图像中预测多个边界框和类别,具有高效性能和较好的准确度。
Mask R-CNN: Mask R-CNN是在Faster R-CNN的基础上扩展而来,不仅可以进行目标检测,还可以生成目标的精确分割掩码。这使得它在实例分割任务中表现优异。
RetinaNet: RetinaNet引入了一种名为Focal Loss的损失函数,用于解决目标检测中类别不平衡的问题。这个框架在同时保持高召回率的情况下提高了检测框的精度。
EfficientDet: EfficientDet是一种基于EfficientNet的轻量级目标检测算法,通过优化模型结构和参数,实现了高效的目标检测性能。
CenterNet: CenterNet通过预测目标的中心点,然后通过回归得到目标的边界框,具有简单而强大的设计,适用于多种场景。
Cascade R-CNN: Cascade R-CNN通过级联使用多个检测器,每个检测器都在前一个阶段的基础上进行细化,从而提高了检测性能。
这些算法都在不同的任务和场景中取得了良好的效果,选择最适合特定应用的算法通常取决于实际需求、计算资源和准确度要求。请注意,领域中的研究和发展一直在进行,因此可能有新的算法和技术已经问世。
正文
1.目标检测
图片分类和目标检测:
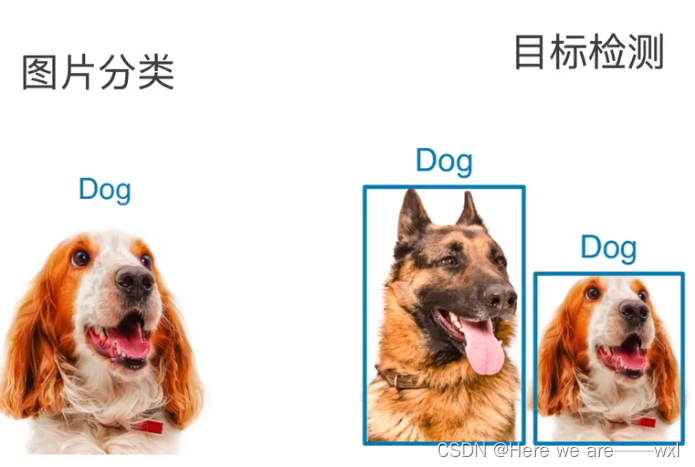
无人车的实时目标识别应用:

边缘框:
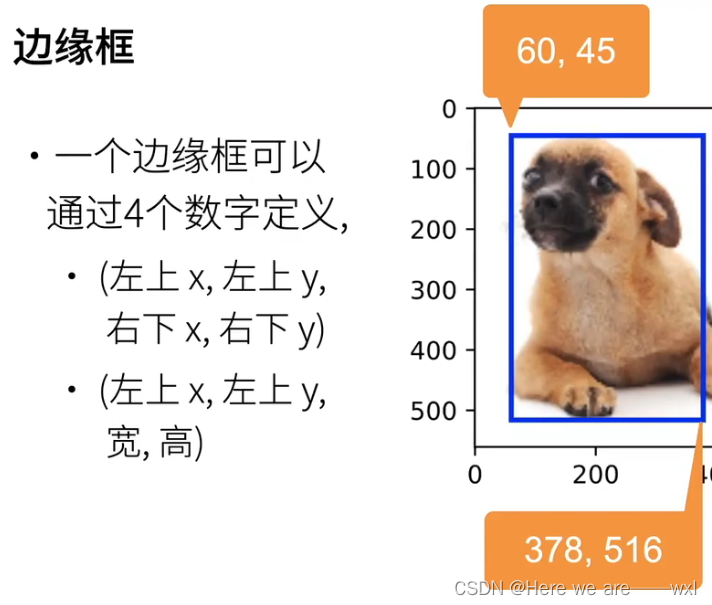
在目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置。 边界框是矩形的,由矩形左上角的以及右角的x和y坐标决定。 另一种常用的边界框表示方法是边界框中心的(x,y)轴坐标以及框的宽度和高度。
2.目标检测数据集
经典的目标检测数据集,就是已经框好的:

COO(Common Objects in Context)数据集是一个用于计算机视觉任务的大规模图像数据集,由微软研究院创建和维护。COCO数据集的目的是为目标检测、分割、图像标注等计算机视觉任务提供丰富多样的图像数据和标注信息。
以下是COCO数据集的一些关键特点:
图像数量: COCO数据集包含33w张图像,每张图像包括多个物体,总共有150w个物体,这些图像来自于不同的场景和情境。
对象类别: 数据集涵盖了80多个不同的对象类别,包括人、动物、交通工具、家具等,多为人造物体。这种多样性使得COCO数据集适用于亲民的目标检测和分类任务。
图像标注: 每张图像都有详细的标注信息,包括对象的边界框和对象的语义分割标签。这使得COCO数据集成为训练和评估目标检测、分割等模型的理想选择。
场景复杂性: 数据集中的图像通常具有复杂的场景,包括多个对象的重叠和各种遮挡。这使得模型在处理真实世界场景时更具挑战性。
用途广泛: COCO数据集被广泛用于评估计算机视觉模型的性能,特别是在目标检测、分割和图像生成等任务上。很多研究论文和竞赛中都使用了COCO数据集。
年度挑战赛: COCO每年都举办一个挑战赛,邀请研究人员提交他们在该数据集上训练的模型,并评估这些模型在不同任务上的性能。
COCO数据集的贡献在于为计算机视觉社区提供了一个丰富而具有挑战性的数据集,推动了目标检测、分割和其他相关任务的研究和发展。
3.目标检测和边界框
定义两种框的表示方法:
#左上右下表示法与中间高宽表示法的转换
#boxes是传入的多个框tenser
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
#%%
boxes = torch.tensor((dog_bbox, cat_bbox))
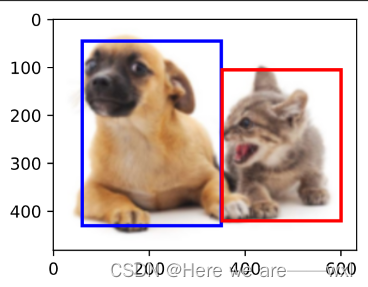
print(box_center_to_corner(box_corner_to_center(boxes)) == boxes)画边界框:
#画边界框
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));显示结果:
4.目标检测数据集示例
目前没有特别小的目标检测数据集用于示例,大的数据集跑起来都太慢了,感谢d2l团队搞了个香蕉数据集用于学习:
拍摄了一组香蕉的照片,并生成了1000张不同角度和大小的香蕉图像。 然后,我们在一些背景图片的随机位置上放一张香蕉的图像。 最后,我们在图片上为这些香蕉标记了边界框。
下载数据集:
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
#%%
#读取香蕉检测数据集。
# 该数据集包括一个的CSV文件,内含目标类别标签和位于左上角和右下角的真实边界框坐标
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256自定义dataset,读取:
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
#%%
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
#0是feature,批量大小,RGB通道,图片大小;1是label,批量大小,物体数,标号+四个坐标
print(batch[0].shape, batch[1].shape)展示:
#演示
#拿出前十个图像,换下维度
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
#每个框
for ax, label in zip(axes, batch[1][0:10]):
#因为之前归一化到了0~1,所以要乘回来
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])满天飞的香蕉: