论文地址:https://arxiv.org/abs/2304.08069
代码地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
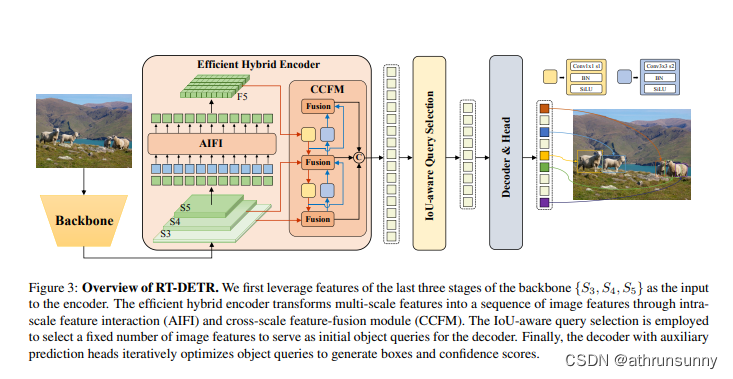
基于Transformer的端到端检测器(DETR)已经取得了显著的性能。然而,DETR的高计算成本问题尚未得到有效解决,这限制了它们的实际应用,并使它们无法充分利用无后处理的好处,如非最大值抑制(NMS)。本文首先分析了现代实时目标检测器中NMS对推理速度的影响,并建立了端到端的速度基准。为了避免NMS引起的推理延迟,作者提出了一种实时检测Transformer(RT-DETR),这是第一个实时端到端目标检测器。具体而言,设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来高效处理多尺度特征,并提出了IoU感知的查询选择,以提高目标查询的初始化。
代码以yolov8的代码为准(非原文中paddle的代码)
代码的配置文件rtdetr-l.yaml:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[21, 24, 27], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
BACKBONE
按代码顺序,首先是HGStem,主要起到升维和降采样的作用,因为是第一层,参数固定,直接用显式数字表示
class HGStem(nn.Module):
"""
StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2):
"""Initialize the SPP layer with input/output channels and specified kernel sizes for max pooling."""
super().__init__()
self.stem1 = Conv(c1, cm, 3, 2, act=nn.ReLU())
self.stem2a = Conv(cm, cm // 2, 2, 1, 0, act=nn.ReLU())
self.stem2b = Conv(cm // 2, cm, 2, 1, 0, act=nn.ReLU())
self.stem3 = Conv(cm * 2, cm, 3, 2, act=nn.ReLU())
self.stem4 = Conv(cm, c2, 1, 1, act=nn.ReLU())
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
x = self.stem1(x) # [N 3 640 640] 下采样 [N 32 320 320]
x = F.pad(x, [0, 1, 0, 1]) # 在图像右侧和下侧pad 1 [N 32 321 321]
x2 = self.stem2a(x) # 2*2的卷积 [N 16 320 320]
x2 = F.pad(x2, [0, 1, 0, 1]) # 在图像右侧和下侧pad 1 [N 16 321 321]
x2 = self.stem2b(x2) # 2*2的卷积 [N 32 320 320]
x1 = self.pool(x) # [N 32 321 321]->[N 32 320 320]
x = torch.cat([x1, x2], dim=1)
x = self.stem3(x) # [N 64 320 320] 下采样 [N 32 160 160]
x = self.stem4(x) # [N 32 160 160] 升维 [N 48 160 160]
return x之后是 HGBlock
class HGBlock(nn.Module):
"""
HG_Block of PPHGNetV2 with 2 convolutions and LightConv.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=nn.ReLU()):
"""Initializes a CSP Bottleneck with 1 convolution using specified input and output channels."""
super().__init__()
block = LightConv if lightconv else Conv
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # squeeze conv
self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # excitation conv
self.add = shortcut and c1 == c2
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
y = [x] # [[N C H W]]
y.extend(m(y[-1]) for m in self.m) # [x]分别经过六次CONV 其中lightconv为True时为DWConv
y = self.ec(self.sc(torch.cat(y, 1))) # sc和ec都是1*1的卷积
return y + x if self.add else y # 是否使用shortcut这两部分都是比较简单的卷积结构,假设使用默认的640*640的输入,那么经过最后一个HGBlock之后输出的特征图维度为[N 2048 20 20],经过一个1*1卷积对其channel降维->[N 256 20 20],将其输入AIFI模块。
其实该模块就是一个位置编码加一个Multi Head Self Attention(即encoder)
class AIFI(TransformerEncoderLayer):
"""Defines the AIFI transformer layer."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""Initialize the AIFI instance with specified parameters."""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
"""Forward pass for the AIFI transformer layer.""" #就是一个位置编码加一个encoder结构
c, h, w = x.shape[1:] # 256 20 20
pos_embed = self.build_2d_sincos_position_embedding(w, h, c) # 对特征图每个像素位置编码 [1 400 256]
# Flatten [B, C, H, W] to [B, HxW, C]
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype)) # [N 400 256]
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous() # [N 256 20 20]
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""Builds 2D sine-cosine position embedding."""
grid_w = torch.arange(int(w), dtype=torch.float32)
grid_h = torch.arange(int(h), dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h)
assert embed_dim % 4 == 0, \
'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 4 # 64
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1. / (temperature ** omega)
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]
# transformer就是非常标准的多头自注意力
class TransformerEncoderLayer(nn.Module):
"""Defines a single layer of the transformer encoder."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""Initialize the TransformerEncoderLayer with specified parameters."""
super().__init__()
from ...utils.torch_utils import TORCH_1_9
if not TORCH_1_9:
raise ModuleNotFoundError(
'TransformerEncoderLayer() requires torch>=1.9 to use nn.MultiheadAttention(batch_first=True).')
self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True)
# Implementation of Feedforward model
self.fc1 = nn.Linear(c1, cm)
self.fc2 = nn.Linear(cm, c1)
self.norm1 = nn.LayerNorm(c1)
self.norm2 = nn.LayerNorm(c1)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.act = act
self.normalize_before = normalize_before
@staticmethod
def with_pos_embed(tensor, pos=None):
"""Add position embeddings to the tensor if provided."""
return tensor if pos is None else tensor + pos
def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with post-normalization."""
q = k = self.with_pos_embed(src, pos) # q k加上位置编码信息
src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
src = src + self.dropout2(src2)
return self.norm2(src)
def forward_pre(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with pre-normalization."""
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src2))))
return src + self.dropout2(src2)
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Forward propagates the input through the encoder module."""
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
论文中提到的CCFM就是相当于一个PAN结构,这个看yolo的网络结构就比较直观,就是最后一层特征图经过上采样与下采样卷积,和网络中特征大小相同的层进行cat再卷积,这里最后一层特征图经过AIFI的处理。配置文件中的neck部分就能清楚地看到。
这里只是经过一个encoder,对encoder进行了简化,经过CCFM将backbone倒数三层的特征图按HW展开再进行合并,之后作为Deformable transformer decoder的输入,输入维度为[N 8400 256]。
DN_group
这里decoder和DN Deformable DETR一样,动态构造了num_group个去噪组,num_group=100//max_nums(一个batch中类别数的最大值)。只是代码实现上有点不同,基本思想一致
def get_cdn_group(batch,
num_classes,
num_queries,
class_embed,
num_dn=100,
cls_noise_ratio=0.5,
box_noise_scale=1.0,
training=False):
"""
Get contrastive denoising training group. This function creates a contrastive denoising training group with positive
and negative samples from the ground truths (gt). It applies noise to the class labels and bounding box coordinates,
and returns the modified labels, bounding boxes, attention mask and meta information.
Args:
batch (dict): A dict that includes 'gt_cls' (torch.Tensor with shape [num_gts, ]), 'gt_bboxes'
(torch.Tensor with shape [num_gts, 4]), 'gt_groups' (List(int)) which is a list of batch size length
indicating the number of gts of each image.
num_classes (int): Number of classes.
num_queries (int): Number of queries.
class_embed (torch.Tensor): Embedding weights to map class labels to embedding space.
num_dn (int, optional): Number of denoising. Defaults to 100.
cls_noise_ratio (float, optional): Noise ratio for class labels. Defaults to 0.5.
box_noise_scale (float, optional): Noise scale for bounding box coordinates. Defaults to 1.0.
training (bool, optional): If it's in training mode. Defaults to False.
Returns:
(Tuple[Optional[Tensor], Optional[Tensor], Optional[Tensor], Optional[Dict]]): The modified class embeddings,
bounding boxes, attention mask and meta information for denoising. If not in training mode or 'num_dn'
is less than or equal to 0, the function returns None for all elements in the tuple.
"""
if (not training) or num_dn <= 0:
return None, None, None, None
gt_groups = batch['gt_groups']
total_num = sum(gt_groups)
max_nums = max(gt_groups)
if max_nums == 0:
return None, None, None, None
num_group = num_dn // max_nums
num_group = 1 if num_group == 0 else num_group
# Pad gt to max_num of a batch
bs = len(gt_groups)
gt_cls = batch['cls'] # (bs*num, )
gt_bbox = batch['bboxes'] # bs*num, 4
b_idx = batch['batch_idx']
# Each group has positive and negative queries. bs*num->total_num
dn_cls = gt_cls.repeat(2 * num_group) # (2*num_group*bs*num, )
dn_bbox = gt_bbox.repeat(2 * num_group, 1) # 2*num_group*bs*num, 4
dn_b_idx = b_idx.repeat(2 * num_group).view(-1) # (2*num_group*bs*num, )
# Positive and negative mask
# (bs*num*num_group, ), the second total_num*num_group part as negative samples
neg_idx = torch.arange(total_num * num_group, dtype=torch.long, device=gt_bbox.device) + num_group * total_num
if cls_noise_ratio > 0:
# Half of bbox prob
mask = torch.rand(dn_cls.shape) < (cls_noise_ratio * 0.5)
idx = torch.nonzero(mask).squeeze(-1)
# Randomly put a new one here
new_label = torch.randint_like(idx, 0, num_classes, dtype=dn_cls.dtype, device=dn_cls.device)
dn_cls[idx] = new_label # 已经在GT中加入了噪声label
if box_noise_scale > 0:
known_bbox = xywh2xyxy(dn_bbox)
diff = (dn_bbox[..., 2:] * 0.5).repeat(1, 2) * box_noise_scale # 由GT bbox的w和h生成的四维张量 # 2*num_group*bs*num, 4
rand_sign = torch.randint_like(dn_bbox, 0, 2) * 2.0 - 1.0 # 由GT bbox形状随机生成的[-1,1]的标识符
rand_part = torch.rand_like(dn_bbox) # 由GT bbox形状随机生成的随机数
rand_part[neg_idx] += 1.0 # 对随机数索引后半部分的值加1
rand_part *= rand_sign # 随机数乘随机数标识符
known_bbox += rand_part * diff # 加入噪声的GT bbox
known_bbox.clip_(min=0.0, max=1.0) # 将加入噪声的GT bbox限制在[0,1]
dn_bbox = xyxy2xywh(known_bbox)
dn_bbox = torch.logit(dn_bbox, eps=1e-6) # inverse sigmoid
num_dn = int(max_nums * 2 * num_group) # total denoising queries
# class_embed = torch.cat([class_embed, torch.zeros([1, class_embed.shape[-1]], device=class_embed.device)])
dn_cls_embed = class_embed[dn_cls] # bs*num * 2 * num_group, 256
padding_cls = torch.zeros(bs, num_dn, dn_cls_embed.shape[-1], device=gt_cls.device) # [2 num_dn 256]
padding_bbox = torch.zeros(bs, num_dn, 4, device=gt_bbox.device) # [2 num_dn 4]
map_indices = torch.cat([torch.tensor(range(num), dtype=torch.long) for num in gt_groups])
pos_idx = torch.stack([map_indices + max_nums * i for i in range(num_group)], dim=0) # 用于记录存在目标的索引
map_indices = torch.cat([map_indices + max_nums * i for i in range(2 * num_group)])
padding_cls[(dn_b_idx, map_indices)] = dn_cls_embed # BATCH中的目标数量不一样,用0补齐,以max_nums为一个周期
padding_bbox[(dn_b_idx, map_indices)] = dn_bbox
tgt_size = num_dn + num_queries
attn_mask = torch.zeros([tgt_size, tgt_size], dtype=torch.bool)
# Match query cannot see the reconstruct
attn_mask[num_dn:, :num_dn] = True
# Reconstruct cannot see each other
for i in range(num_group):
if i == 0:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
if i == num_group - 1:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * i * 2] = True
else:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * 2 * i] = True
dn_meta = {
'dn_pos_idx': [p.reshape(-1) for p in pos_idx.cpu().split(list(gt_groups), dim=1)],
'dn_num_group': num_group,
'dn_num_split': [num_dn, num_queries]}
return padding_cls.to(class_embed.device), padding_bbox.to(class_embed.device), attn_mask.to(
class_embed.device), dn_meta加入噪声后,还需要注意的一点便是信息之间的是否可见问题,噪声 queries 是会和匈牙利匹配任务的 queries 拼接起来一起送入 transformer中的。在 transformer 中,它们会经过 attention 交互,这势必会得知一些信息,这是作弊行为,是绝对不允许的
一、首先,如上所述,匈牙利匹配任务的 queries 肯定不能看到 DN 任务的 queries。
二、其次,不同 dn group 的 queries 也不能相互看到。因为综合所有组来看,gt -> query 是 one-to-many 的,每个 gt 在
每组都会有 1 个 query 拥有自己的信息。于是,对于每个 query 来说,在其它各组中都势必存在 1 个 query 拥有自己负责预测的那个 gt 的信息。
三、接着,同一个 dn group 的 queries 是可以相互看的 。因为在每组内,gt -> query 是 one-to-one 的关系,对于每个 query 来说,其它 queries 都不会有自己 gt 的信息。
四、最后,DN 任务的 queries 可以去看匈牙利匹配任务的 queries ,因为只有前者才拥有 gt 信息,而后者是“凭空构造”的(主要是先验,需要自己去学习)。
总的来说,attention mask 的设计归纳为:
1、匈牙利匹配任务的 queries 不能看到 DN任务的 queries;
2、DN 任务中,不同组的 queries 不能相互看到;
3、其它情况均可见
其中attn_mask:
tgt_size = num_dn + num_queries
attn_mask = torch.zeros([tgt_size, tgt_size], dtype=torch.bool)
# Match query cannot see the reconstruct
attn_mask[num_dn:, :num_dn] = True
# Reconstruct cannot see each other
for i in range(num_group):
if i == 0:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
if i == num_group - 1:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * i * 2] = True
else:
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), max_nums * 2 * (i + 1):num_dn] = True
attn_mask[max_nums * 2 * i:max_nums * 2 * (i + 1), :max_nums * 2 * i] = True
该max_nums表示在该batch中包含的最大的label个数。
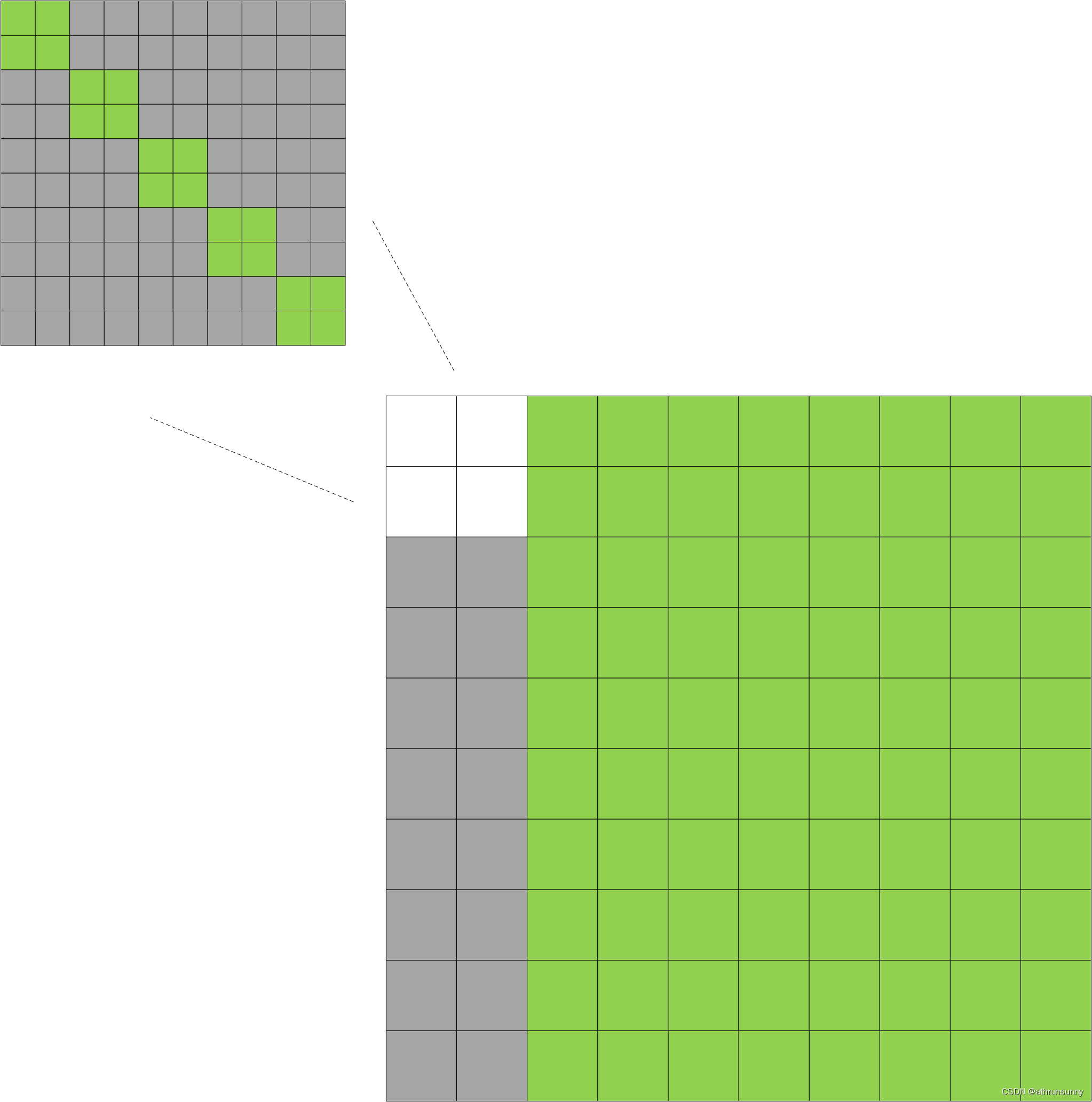
其中绿色部分表示为False,灰色部分表示为True。有那么点最初的transformer的味道。上图是个示意图,右下角的大图为:
300+(num_group * 2*max_nums)*300+(num_group * 2*max_nums),
左上的小图(num_group * 2*max_nums)*(num_group * 2*max_nums)
这里还用到了DINO中的Mixed Query Selection策略,也就是从最后一个编码器层中选择前K个编码器特征作为先验,以增强解码器查询。
def _get_decoder_input(self, feats, shapes, dn_embed=None, dn_bbox=None):
"""Generates and prepares the input required for the decoder from the provided features and shapes."""
bs = len(feats)
# Prepare input for decoder
anchors, valid_mask = self._generate_anchors(shapes, dtype=feats.dtype, device=feats.device)
features = self.enc_output(valid_mask * feats) # bs, h*w, 256 # 有效区域的特征经过Linear(256,256)
enc_outputs_scores = self.enc_score_head(features) # (bs, h*w, nc) # 有效区域的特征经过Linear(256,80)得到各类别分类得分
# Query selection
# (bs, num_queries) # 在enc_outputs_scores最后一维中取得分最大的值,并用topk取排在前300的值的索引
topk_ind = torch.topk(enc_outputs_scores.max(-1).values, self.num_queries, dim=1).indices.view(-1)
# (bs, num_queries)
batch_ind = torch.arange(end=bs, dtype=topk_ind.dtype).unsqueeze(-1).repeat(1, self.num_queries).view(-1)
# (bs, num_queries, 256) # 根据batch和topk的索引在有效features中得到top_k_features
top_k_features = features[batch_ind, topk_ind].view(bs, self.num_queries, -1)
# (bs, num_queries, 4) #根据topk的索引在有效anchors中得到top_k_anchors
top_k_anchors = anchors[:, topk_ind].view(bs, self.num_queries, -1)
# Dynamic anchors + static content # 前300的特征经过3个Linear [N 300 256]—>[N 300 4]再加上top_k_anchors得到refer_bbox
refer_bbox = self.enc_bbox_head(top_k_features) + top_k_anchors
enc_bboxes = refer_bbox.sigmoid()
if dn_bbox is not None:
refer_bbox = torch.cat([dn_bbox, refer_bbox], 1) # 带有噪声的去噪组bbox和refer_bbox cat在一起
enc_scores = enc_outputs_scores[batch_ind, topk_ind].view(bs, self.num_queries, -1)# 根据batch和topk的索引在enc_outputs_scores中得到enc_scores
# 默认embeddings=top_k_features
embeddings = self.tgt_embed.weight.unsqueeze(0).repeat(bs, 1, 1) if self.learnt_init_query else top_k_features
if self.training:
refer_bbox = refer_bbox.detach()
if not self.learnt_init_query:
embeddings = embeddings.detach()
if dn_embed is not None:
embeddings = torch.cat([dn_embed, embeddings], 1) # 带有噪声的去噪组dn_embed和embeddings cat在一起
# embeddings:[N num_queries+dn_dim 256] 有效区域内选出的top300的特征和去噪组的特征合并
# refer_bbox:[N num_queries+dn_dim 4] 有效区域内选出的top300的特征经过Linear得到的bbox + top_k_anchors 与去噪组的bbox合并
# enc_bboxes:[N num_queries 4] 有效区域内选出的top300的特征经过Linear得到的bbox + top_k_anchors 再进行sigmoid
# enc_scores:[N num_queries 80] 根据batch和topk的索引在enc_outputs_scores中得到enc_scores
return embeddings, refer_bbox, enc_bboxes, enc_scores其中_generate_anchors根据特征图的大小,以特征图大小的网格中心生成归一化后的中心点坐标(grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH),anchor的wh则根据(wh = torch.ones_like(grid_xy) * grid_size * (2.0 ** i))其中i表示层号(0-2)grid_size=0.05
def _generate_anchors(self, shapes, grid_size=0.05, dtype=torch.float32, device='cpu', eps=1e-2):
"""Generates anchor bounding boxes for given shapes with specific grid size and validates them."""
# 在给定shapes的情况下,_generate_anchors函数用于生成锚框(anchor bounding boxes)
# 并对其进行验证。其中,valid_mask是一个布尔掩码,用于标记哪些锚框是有效的
anchors = []
for i, (h, w) in enumerate(shapes):
sy = torch.arange(end=h, dtype=dtype, device=device)
sx = torch.arange(end=w, dtype=dtype, device=device)
grid_y, grid_x = torch.meshgrid(sy, sx, indexing='ij') if TORCH_1_10 else torch.meshgrid(sy, sx)
grid_xy = torch.stack([grid_x, grid_y], -1) # (h, w, 2)
valid_WH = torch.tensor([h, w], dtype=dtype, device=device)
grid_xy = (grid_xy.unsqueeze(0) + 0.5) / valid_WH # (1, h, w, 2)
wh = torch.ones_like(grid_xy, dtype=dtype, device=device) * grid_size * (2.0 ** i)
anchors.append(torch.cat([grid_xy, wh], -1).view(-1, h * w, 4)) # (1, h*w, 4)
anchors = torch.cat(anchors, 1) # (1, h*w*nl, 4)
# 限制每个anchor内的值都在[0.01-0.99]之间,在这个区间之外的值设为无效,后面通过masked_fill设为'inf'
valid_mask = ((anchors > eps) * (anchors < 1 - eps)).all(-1, keepdim=True) # 1, h*w*nl, 1
# 这里,将锚框的坐标值进行对数变换,并使用masked_fill函数将无效的锚框的值设置为正无穷(float('inf'))。
# 这样做是为了在后续处理中过滤掉无效的锚框。
anchors = torch.log(anchors / (1 - anchors))
anchors = anchors.masked_fill(~valid_mask, float('inf'))
return anchors, valid_maskDECODER
decoder则是标准的Deformable transformer,对Deformable transformer和DINO不了解的可以参看这两博文:Deformable-DETR代码学习笔记_athrunsunny的博客-CSDN博客
和 DINO代码学习笔记(一)_athrunsunny的博客-CSDN博客
DINO代码学习笔记(二)_athrunsunny的博客-CSDN博客
DINO代码学习笔记(三)-CSDN博客
DINO代码学习笔记(四)-CSDN博客
class MSDeformAttn(nn.Module):
"""
Multi-Scale Deformable Attention Module based on Deformable-DETR and PaddleDetection implementations.
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/modules/ms_deform_attn.py
"""
def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
"""Initialize MSDeformAttn with the given parameters."""
super().__init__()
if d_model % n_heads != 0:
raise ValueError(f'd_model must be divisible by n_heads, but got {d_model} and {n_heads}')
_d_per_head = d_model // n_heads
# Better to set _d_per_head to a power of 2 which is more efficient in a CUDA implementation
assert _d_per_head * n_heads == d_model, '`d_model` must be divisible by `n_heads`'
self.im2col_step = 64
self.d_model = d_model
self.n_levels = n_levels
self.n_heads = n_heads
self.n_points = n_points
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
self.value_proj = nn.Linear(d_model, d_model)
self.output_proj = nn.Linear(d_model, d_model)
self._reset_parameters()
def _reset_parameters(self):
"""Reset module parameters."""
constant_(self.sampling_offsets.weight.data, 0.)
thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(
1, self.n_levels, self.n_points, 1)
for i in range(self.n_points):
grid_init[:, :, i, :] *= i + 1
with torch.no_grad():
self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
constant_(self.attention_weights.weight.data, 0.)
constant_(self.attention_weights.bias.data, 0.)
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.)
def forward(self, query, refer_bbox, value, value_shapes, value_mask=None):
"""
Perform forward pass for multiscale deformable attention.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
Args:
query (torch.Tensor): [bs, query_length, C]
refer_bbox (torch.Tensor): [bs, query_length, n_levels, 2], range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area
value (torch.Tensor): [bs, value_length, C]
value_shapes (List): [n_levels, 2], [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
value_mask (Tensor): [bs, value_length], True for non-padding elements, False for padding elements
Returns:
output (Tensor): [bs, Length_{query}, C]
"""
bs, len_q = query.shape[:2]
len_v = value.shape[1]
assert sum(s[0] * s[1] for s in value_shapes) == len_v
value = self.value_proj(value)
if value_mask is not None:
value = value.masked_fill(value_mask[..., None], float(0))
value = value.view(bs, len_v, self.n_heads, self.d_model // self.n_heads)
sampling_offsets = self.sampling_offsets(query).view(bs, len_q, self.n_heads, self.n_levels, self.n_points, 2)
attention_weights = self.attention_weights(query).view(bs, len_q, self.n_heads, self.n_levels * self.n_points)
attention_weights = F.softmax(attention_weights, -1).view(bs, len_q, self.n_heads, self.n_levels, self.n_points)
# N, Len_q, n_heads, n_levels, n_points, 2
num_points = refer_bbox.shape[-1]
if num_points == 2:
offset_normalizer = torch.as_tensor(value_shapes, dtype=query.dtype, device=query.device).flip(-1)
add = sampling_offsets / offset_normalizer[None, None, None, :, None, :]
sampling_locations = refer_bbox[:, :, None, :, None, :] + add
elif num_points == 4:
add = sampling_offsets / self.n_points * refer_bbox[:, :, None, :, None, 2:] * 0.5
sampling_locations = refer_bbox[:, :, None, :, None, :2] + add
else:
raise ValueError(f'Last dim of reference_points must be 2 or 4, but got {num_points}.')
output = multi_scale_deformable_attn_pytorch(value, value_shapes, sampling_locations, attention_weights)
return self.output_proj(output)
class DeformableTransformerDecoderLayer(nn.Module):
"""
Deformable Transformer Decoder Layer inspired by PaddleDetection and Deformable-DETR implementations.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/deformable_transformer.py
"""
def __init__(self, d_model=256, n_heads=8, d_ffn=1024, dropout=0., act=nn.ReLU(), n_levels=4, n_points=4):
"""Initialize the DeformableTransformerDecoderLayer with the given parameters."""
super().__init__()
# Self attention
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# Cross attention
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout2 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
# FFN
self.linear1 = nn.Linear(d_model, d_ffn)
self.act = act
self.dropout3 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout4 = nn.Dropout(dropout)
self.norm3 = nn.LayerNorm(d_model)
@staticmethod
def with_pos_embed(tensor, pos):
"""Add positional embeddings to the input tensor, if provided."""
return tensor if pos is None else tensor + pos
def forward_ffn(self, tgt):
"""Perform forward pass through the Feed-Forward Network part of the layer."""
tgt2 = self.linear2(self.dropout3(self.act(self.linear1(tgt))))
tgt = tgt + self.dropout4(tgt2)
return self.norm3(tgt)
def forward(self, embed, refer_bbox, feats, shapes, padding_mask=None, attn_mask=None, query_pos=None):
"""Perform the forward pass through the entire decoder layer."""
# Self attention
q = k = self.with_pos_embed(embed, query_pos)
tgt = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), embed.transpose(0, 1),
attn_mask=attn_mask)[0].transpose(0, 1)
embed = embed + self.dropout1(tgt)
embed = self.norm1(embed)
# Cross attention
tgt = self.cross_attn(self.with_pos_embed(embed, query_pos), refer_bbox.unsqueeze(2), feats, shapes,
padding_mask)
embed = embed + self.dropout2(tgt)
embed = self.norm2(embed)
# FFN
return self.forward_ffn(embed)
class DeformableTransformerDecoder(nn.Module):
"""
Implementation of Deformable Transformer Decoder based on PaddleDetection.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/deformable_transformer.py
"""
def __init__(self, hidden_dim, decoder_layer, num_layers, eval_idx=-1):
"""Initialize the DeformableTransformerDecoder with the given parameters."""
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.hidden_dim = hidden_dim
self.eval_idx = eval_idx if eval_idx >= 0 else num_layers + eval_idx
def forward(
self,
embed, # decoder embeddings
refer_bbox, # anchor
feats, # image features
shapes, # feature shapes
bbox_head,
score_head,
pos_mlp,
attn_mask=None,
padding_mask=None):
"""Perform the forward pass through the entire decoder."""
output = embed
dec_bboxes = []
dec_cls = []
last_refined_bbox = None
refer_bbox = refer_bbox.sigmoid()
for i, layer in enumerate(self.layers):
output = layer(output, refer_bbox, feats, shapes, padding_mask, attn_mask, pos_mlp(refer_bbox))
bbox = bbox_head[i](output)
refined_bbox = torch.sigmoid(bbox + inverse_sigmoid(refer_bbox))
if self.training:
dec_cls.append(score_head[i](output))
if i == 0:
dec_bboxes.append(refined_bbox)
else:
dec_bboxes.append(torch.sigmoid(bbox + inverse_sigmoid(last_refined_bbox)))
elif i == self.eval_idx:
dec_cls.append(score_head[i](output))
dec_bboxes.append(refined_bbox)
break
last_refined_bbox = refined_bbox
refer_bbox = refined_bbox.detach() if self.training else refined_bbox
return torch.stack(dec_bboxes), torch.stack(dec_cls)这里就不对上述代码多做解释了
单层decoder的图解:
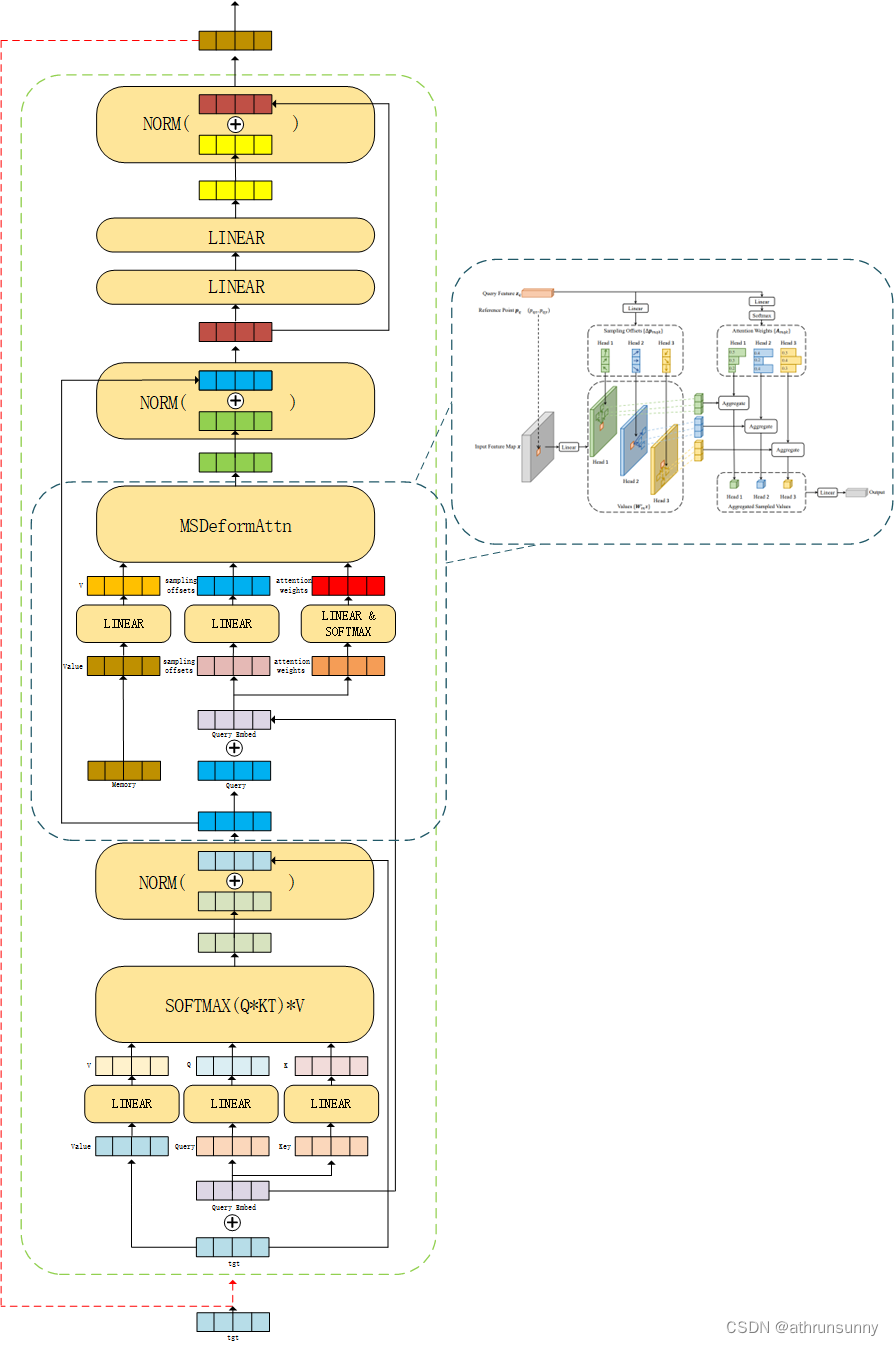
在yolov8的代码中增加了multi scale deformable attention的pytorch的实现,而在Deformable-DETR中是走的cuda底层代码
def multi_scale_deformable_attn_pytorch(value: torch.Tensor, value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor) -> torch.Tensor:
"""
Multi-scale deformable attention.
https://github.com/IDEA-Research/detrex/blob/main/detrex/layers/multi_scale_deform_attn.py
"""
bs, _, num_heads, embed_dims = value.shape
_, num_queries, num_heads, num_levels, num_points, _ = sampling_locations.shape
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
value_l_ = (value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_))
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
sampling_grid_l_ = sampling_grids[:, :, :, level].transpose(1, 2).flatten(0, 1)
# bs*num_heads, embed_dims, num_queries, num_points
sampling_value_l_ = F.grid_sample(value_l_,
sampling_grid_l_,
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
attention_weights = attention_weights.transpose(1, 2).reshape(bs * num_heads, 1, num_queries,
num_levels * num_points)
output = ((torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(
bs, num_heads * embed_dims, num_queries))
return output.transpose(1, 2).contiguous()Deformable-DETR论文中的示意图:
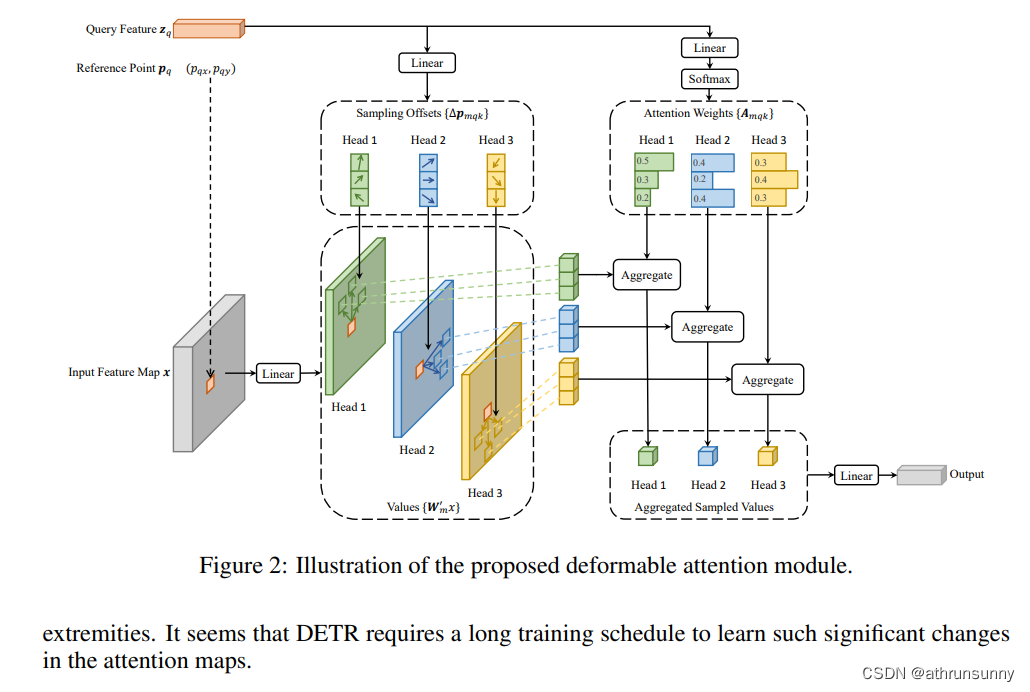
对应的公式
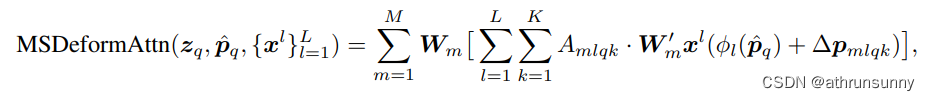
LOSS
loss这里也是和DINO差不多,在非去噪组中用匈牙利匹配得到一对一的匹配索引值,再根据索引值在GT和preds中取得对应的target和pred(包括bbox和cls),之后再分别计算类别损失和bbox损失,不仅对decoder的每个中间层的输出计算loss同时还将单个encoder输出加进loss的计算(共7个输出),除去decoder最后一层的输出,其余中间层的输出作为辅助loss
class DETRLoss(nn.Module):
"""
DETR (DEtection TRansformer) Loss class. This class calculates and returns the different loss components for the
DETR object detection model. It computes classification loss, bounding box loss, GIoU loss, and optionally auxiliary
losses.
Attributes:
nc (int): The number of classes.
loss_gain (dict): Coefficients for different loss components.
aux_loss (bool): Whether to compute auxiliary losses.
use_fl (bool): Use FocalLoss or not.
use_vfl (bool): Use VarifocalLoss or not.
use_uni_match (bool): Whether to use a fixed layer to assign labels for the auxiliary branch.
uni_match_ind (int): The fixed indices of a layer to use if `use_uni_match` is True.
matcher (HungarianMatcher): Object to compute matching cost and indices.
fl (FocalLoss or None): Focal Loss object if `use_fl` is True, otherwise None.
vfl (VarifocalLoss or None): Varifocal Loss object if `use_vfl` is True, otherwise None.
device (torch.device): Device on which tensors are stored.
"""
def __init__(self,
nc=80,
loss_gain=None,
aux_loss=True,
use_fl=True,
use_vfl=False,
use_uni_match=False,
uni_match_ind=0):
"""
DETR loss function.
Args:
nc (int): The number of classes.
loss_gain (dict): The coefficient of loss.
aux_loss (bool): If 'aux_loss = True', loss at each decoder layer are to be used.
use_vfl (bool): Use VarifocalLoss or not.
use_uni_match (bool): Whether to use a fixed layer to assign labels for auxiliary branch.
uni_match_ind (int): The fixed indices of a layer.
"""
super().__init__()
if loss_gain is None:
loss_gain = {'class': 1, 'bbox': 5, 'giou': 2, 'no_object': 0.1, 'mask': 1, 'dice': 1}
self.nc = nc
self.matcher = HungarianMatcher(cost_gain={'class': 2, 'bbox': 5, 'giou': 2})
self.loss_gain = loss_gain
self.aux_loss = aux_loss
self.fl = FocalLoss() if use_fl else None
self.vfl = VarifocalLoss() if use_vfl else None
self.use_uni_match = use_uni_match
self.uni_match_ind = uni_match_ind
self.device = None
def _get_loss_class(self, pred_scores, targets, gt_scores, num_gts, postfix=''):
"""Computes the classification loss based on predictions, target values, and ground truth scores."""
# Logits: [b, query, num_classes], gt_class: list[[n, 1]]
name_class = f'loss_class{postfix}'
bs, nq = pred_scores.shape[:2]
# one_hot = F.one_hot(targets, self.nc + 1)[..., :-1] # (bs, num_queries, num_classes)
one_hot = torch.zeros((bs, nq, self.nc + 1), dtype=torch.int64, device=targets.device)
one_hot.scatter_(2, targets.unsqueeze(-1), 1) # 对target进行onehot编码
one_hot = one_hot[..., :-1]
gt_scores = gt_scores.view(bs, nq, 1) * one_hot # gt_scores [N 300]->[N 300 80](broadcast)
if self.fl:
if num_gts and self.vfl:
loss_cls = self.vfl(pred_scores, gt_scores, one_hot)
else:
loss_cls = self.fl(pred_scores, one_hot.float())
loss_cls /= max(num_gts, 1) / nq
else:
loss_cls = nn.BCEWithLogitsLoss(reduction='none')(pred_scores, gt_scores).mean(1).sum() # YOLO CLS loss
return {name_class: loss_cls.squeeze() * self.loss_gain['class']}
def _get_loss_bbox(self, pred_bboxes, gt_bboxes, postfix=''):
"""Calculates and returns the bounding box loss and GIoU loss for the predicted and ground truth bounding
boxes.
"""
# Boxes: [b, query, 4], gt_bbox: list[[n, 4]]
name_bbox = f'loss_bbox{postfix}'
name_giou = f'loss_giou{postfix}'
loss = {}
if len(gt_bboxes) == 0:
loss[name_bbox] = torch.tensor(0., device=self.device)
loss[name_giou] = torch.tensor(0., device=self.device)
return loss
loss[name_bbox] = self.loss_gain['bbox'] * F.l1_loss(pred_bboxes, gt_bboxes, reduction='sum') / len(gt_bboxes)
loss[name_giou] = 1.0 - bbox_iou(pred_bboxes, gt_bboxes, xywh=True, GIoU=True)
loss[name_giou] = loss[name_giou].sum() / len(gt_bboxes)
loss[name_giou] = self.loss_gain['giou'] * loss[name_giou]
return {k: v.squeeze() for k, v in loss.items()}其中类别损失的计算:
class VarifocalLoss(nn.Module):
"""
Varifocal loss by Zhang et al.
https://arxiv.org/abs/2008.13367.
"""
def __init__(self):
"""Initialize the VarifocalLoss class."""
super().__init__()
@staticmethod
def forward(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
"""Computes varfocal loss."""
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(), reduction='none') *
weight).mean(1).sum()
return loss其中bbox是用L1损失,iou采用GIOU
对于去噪组,不同的是,去噪组仅在decoder中计算,所以输出6个,即计算6次loss,同时在构建去噪组时将pos_idx保存在了dn_meta中,所以不需要做匈牙利匹配,直接计算cls,bbox和iou loss,loss的计算函数与非去噪组一致。