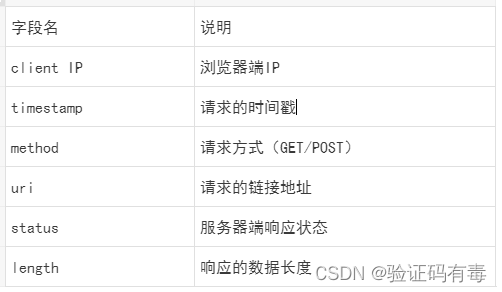
文章目录
- 定位损失 L l o c L_{loc} Lloc
- 偏移值的计算
- smooth L1 loss
- 置信率损失 L c o n f L_{conf} Lconf
最近看看这个古早的目标检测网络,看了好多文章,感觉对损失函数的部分讲得都是不很清楚得样子,所以自己捋一下。
首先,SSD 得损失函数由两部分得加权和,一部分是定位损失 L l o c L_{loc} Lloc,另一部分是分类置信率损失 L c o n f L_{conf} Lconf。公式一般写成: L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x,c,l,g) = \frac{1}{N}\left( L_{conf}(x, c) + \alpha L_{loc}(x, l, g) \right) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))总结来说,定位损失 L l o c L_{loc} Lloc 是使用 smooth L1 loss 来计算的,而分类置信率损失 L c o n f L_{conf} Lconf 是通过 softmax loss 来计算的。
定位损失 L l o c L_{loc} Lloc
接下来就分开讲讲两部分,首先是定位损失 L l o c L_{loc} Lloc, 它的公式可以写成: L l o c ( x , l , g ) = ∑ i ∈ P o s N ∑ m ∈ { c x , c y , w , h } x i j p ⋅ s m o o t h L 1 ( l i m − g ^ j m ) L_{loc}(x, l, g) = \sum_{i \in Pos}^{N} \sum_{m \in \left\{ cx, cy, w, h \right\}} x_{ij}^p \cdot \mathbf{smooth_{L1}}(l_i^m - \hat{g}_j^m) Lloc(x,l,g)=i∈Pos∑Nm∈{cx,cy,w,h}∑xijp⋅smoothL1(lim−g^jm)下昂西介绍一下里面的各种参数的含义:
- i ∈ P o s i \in Pos i∈Pos:第一个求和下的 P o s Pos Pos 是一个集合,我们知道在训练的时候,会根据 IOU(SSD 里好像是大于 0.5) 对 Default box(其实和 anchor 的含义一样)与 Ground truth box(后面统称 gt box)进行匹配,如果 第 i i i 个 default box 与 第 j j j 个 gt box 匹配上了,那么这个 default box i i i 就会被放入 P o s Pos Pos 的集合中,表示 positive,也就是被标记成了正样本。
- N N N:是正样本集合 P o s Pos Pos 的总数,表示有 N N N 个 default box 与 gt box 匹配上了。
- m ∈ { c x , c y , w , h } m \in \left\{ cx, cy, w, h \right\} m∈{cx,cy,w,h}:这四个值是 anchor 的位置参数,表示中心点的坐标和 anchor 的尺寸。
- x i j p x_{ij}^p xijp:可以理解为唯一标识 flag,如果 default box i i i 与 gt box j j j 是匹配的,gt box 的类别是 p p p,则为1,否则 0。
- l i m l_i^m lim:是预测值,也就是 bounding box 与 default box 的偏移值,不是真实的坐标,具体的转换在下面给出。
- g ^ j m \hat{g}_j^m g^jm:是真实值,是 gt box 与 default box 的偏移值。
偏移值的计算
回到前面提到的偏移值,如果 default box
i
i
i 的位置参数是
{
d
i
c
x
,
d
i
c
y
,
d
i
w
,
d
i
h
}
\{ d_i^{cx}, d_i^{cy}, d_i^{w}, d_i^{h} \}
{dicx,dicy,diw,dih},gt box
j
j
j 的位置参数是
{
g
j
c
x
,
g
j
c
y
,
g
j
w
,
g
j
h
}
\{ g_j^{cx}, g_j^{cy}, g_j^{w}, g_j^{h} \}
{gjcx,gjcy,gjw,gjh},我们就可以算出真实值对应的偏移量
{
g
^
j
c
x
,
g
^
j
c
y
,
g
^
j
w
,
g
^
j
h
}
\{ \hat{g}_j^{cx}, \hat{g}_j^{cy}, \hat{g}_j^{w}, \hat{g}_j^{h} \}
{g^jcx,g^jcy,g^jw,g^jh}:
g
^
j
c
x
=
(
g
j
c
x
−
d
i
c
x
)
d
i
w
g
^
j
w
=
log
(
g
j
w
d
i
w
)
g
^
j
c
y
=
(
g
j
c
y
−
d
i
c
y
)
d
i
h
g
^
j
h
=
log
(
g
j
h
d
i
h
)
\begin{align*} \hat{g}_j^{cx} = \frac{(g_j^{cx} - d_i^{cx})}{d_i^w} & \space\space\space\space\space\space\space\space\space \hat{g}_j^{w} = \log\left( \frac{g_j^w}{d_i^w} \right)\\ \hat{g}_j^{cy} =\frac{ (g_j^{cy} - d_i^{cy})}{d_i^h} & \space\space\space\space\space\space\space\space\space \hat{g}_j^{h} = \log\left( \frac{g_j^h}{d_i^h} \right) \end{align*}
g^jcx=diw(gjcx−dicx)g^jcy=dih(gjcy−dicy) g^jw=log(diwgjw) g^jh=log(dihgjh)同理,我们也可以通过预测得到的 bounding box 参数
{
b
i
c
x
,
b
i
c
y
,
b
i
w
,
b
i
h
}
\{b_i^{cx}, b_i^{cy}, b_i^{w}, b_i^{h} \}
{bicx,bicy,biw,bih} ,来计算得到 bounding box 的偏移量,也就是预测值
l
l
l。
l
i
c
x
=
(
b
i
c
x
−
d
i
c
x
)
d
i
w
l
i
w
=
log
(
b
i
w
d
i
w
)
l
i
c
y
=
(
b
i
c
y
−
d
i
c
y
)
d
i
h
l
i
h
=
log
(
b
i
h
d
i
h
)
\begin{align*} l_i^{cx} = \frac{(b_i^{cx} - d_i^{cx})}{d_i^w} & \space\space\space\space\space\space\space\space\space l_i^{w} = \log\left( \frac{b_i^w}{d_i^w} \right)\\ l_i^{cy} =\frac{ (b_i^{cy} - d_i^{cy})}{d_i^h} & \space\space\space\space\space\space\space\space\space l_i^{h} = \log\left( \frac{b_i^h}{d_i^h} \right) \end{align*}
licx=diw(bicx−dicx)licy=dih(bicy−dicy) liw=log(diwbiw) lih=log(dihbih)
中心点的偏移量计算是很好理解的,为什么宽高的偏移量要用 log 函数来算呢?
smooth L1 loss
SSD 是用到 smooth L1 loss 来计算真实值与预测值之间的差异: s m o o t h L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \mathbf{smooth_{L1}}(x) =\begin{cases} 0.5x^2 & \text{ if } |x|< 1 \\ |x| -0.5 & \text{ otherwise } \end{cases} smoothL1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
这篇文章我觉得解释得挺清晰的,比较了 L1 loss, L2 loss 和 smooth L1 loss 三者之间的优劣。也提到了 loc loss 的演进。
bounding box 回归损失函数,也就是用于定位边界框的损失函数,其演进线路如下:
我记得 YOLOv1 的损失函数,在计算位置损失的时候,还是使用的欧式距离,也就是所谓的 L2 loss。
L1 loss 是求两个数之间的绝对值距离,导数是常数(小于 0 则为 -1,大于等于 0 则为 1),在零点处是不平滑的;
L2 loss 是两个数之间差的平方,导数是 2 x 2x 2x(也可以看出,受到 x x x 的影响很大),但是在零点处是平滑的。多个 L2 loss 求和再平均也叫做 MSE loss (Mean Square Error)。
而我们的主角 smooth L1 loss,如名字所见,是平滑版的 L1 loss,导数为: d s m o o t h L 1 ( x ) d x = { x if ∣ x ∣ < 1 ± 1 otherwise \frac{ \mathrm{d} \space \mathbf{smooth_{L1}}(x)}{\mathrm{d}x} =\begin{cases} x & \text{ if } |x|< 1 \\ \pm1 & \text{ otherwise } \end{cases} dxd smoothL1(x)={x±1 if ∣x∣<1 otherwise 在零点附近都是平滑的,而且在其它区间都是常数,也不会出现 L2 loss 随着 x x x 的增大而在损失函数中占据主导地位。
置信率损失 L c o n f L_{conf} Lconf
下面就讲一下分类的置信率损失 L c o n f L_{conf} Lconf,完整的公式如下: L c o n f ( x , c ) = − ∑ i ∈ P o s N x i j p log c ^ i p − ∑ i ∈ N e g log c ^ i 0 where c ^ i p = exp ( c i p ) ∑ p exp ( c i p ) L_{conf}(x, c) = - \sum_{i \in Pos}^N x_{ij}^p\log{\hat{c}_i^p} - \sum_{i\in Neg} \log{\hat{c}_i^0} \space\space\space\space \text{where} \space\space\space\space \hat{c}_i^p=\frac{\exp{(c_i^p)}}{\sum_p \exp{(c_i^p)}} Lconf(x,c)=−i∈Pos∑Nxijplogc^ip−i∈Neg∑logc^i0 where c^ip=∑pexp(cip)exp(cip),从公式的形态,可以看出来是二元交叉熵。没错,其实 softmax loss 就相当于交叉熵和 softmax 的组合,先看看最后的 softmax 公式: c ^ i p = exp ( c i p ) ∑ p exp ( c i p ) \hat{c}_i^p=\frac{\exp{(c_i^p)}}{\sum_p \exp{(c_i^p)}} c^ip=∑pexp(cip)exp(cip)
- c i p c_i^p cip: 对于分类的部分,一般网络的全连接层会输出 P P P 个类别的向量,在 SSD 因为要考虑背景(背景是分类 0),这个长度为 P + 1 P+1 P+1 的向量经过 softmax 之后,所有值的和会被限制为 1。其中置信率最大的值即是 c i p c_i^p cip(目前这个值还没经过归一化),这表示 anchor i i i 是的类别是 p p p 的可能性最大。
- c ^ i p \hat{c}_i^p c^ip:是通过对 c i p c_i^p cip 进行 softmax 而得到的,表示 anchor i i i 是分类 p p p 的概率,值是位于 0~1 之间的。
然后就是主公式的各个参数的具体含义:
- x i j p x_{ij}^p xijp:含义同上面位置损失提到的,如果 anchor i i i 与 gt box j j j 是匹配的,gt box 的类别是 p p p,则为1,否则 0。
- c ^ i 0 \hat{c}_i^0 c^i0:就是背景的分类概率(负样本)。
其实这个公式也没什么难理解的。
大致就是这么多了,如果大家有什么不清楚的地方或者是文章哪里写错了,欢迎评论留言。