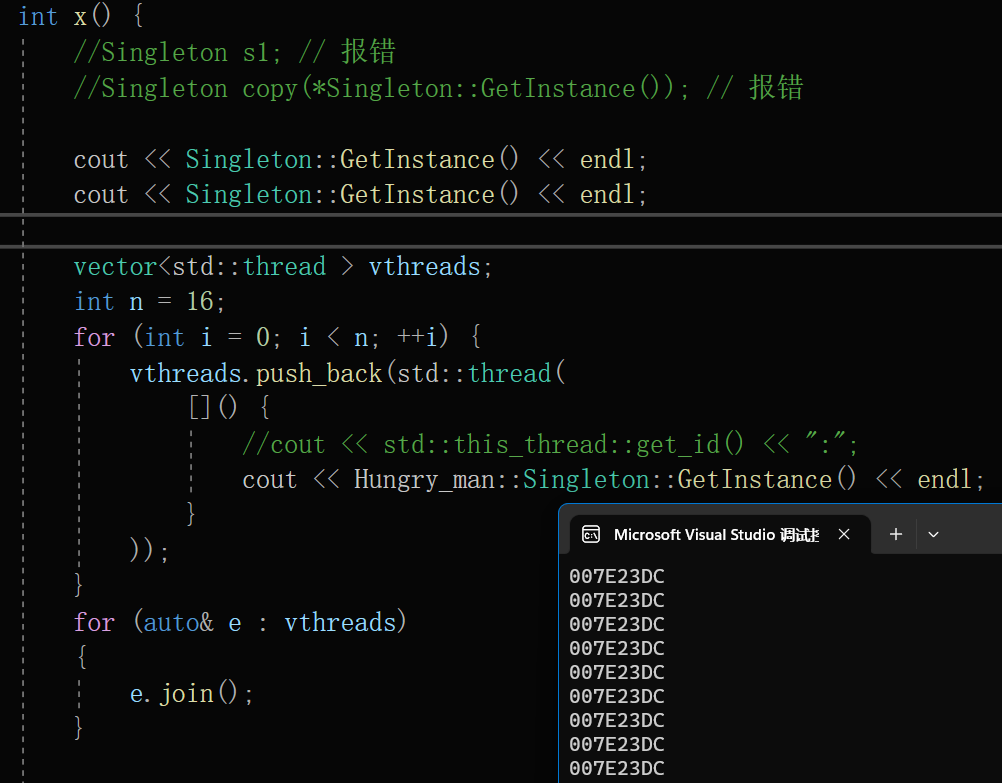
概况
(1)YOLOv3是YOLO系列第一次引入残差连接来解决深度网络中的梯度消失问题(是不是第一次,有待你后面考证),实际用的backbone是DarkNet53
(2)最显著的改进,也是对你涨点贡献最大的一个原因:在三个尺度上,以相同的方式进行目标检测。你别管它是怎么实现的,反正对大目标、小目标和中目标,他都有一定的鲁棒性。
(3)将损失函数从以前的Softmax修改为Logit,也就是对每个类别进行了一个解耦
(4)在最后推理阶段,对3个检测层的预测结果进行了 非最大抑制 NMS
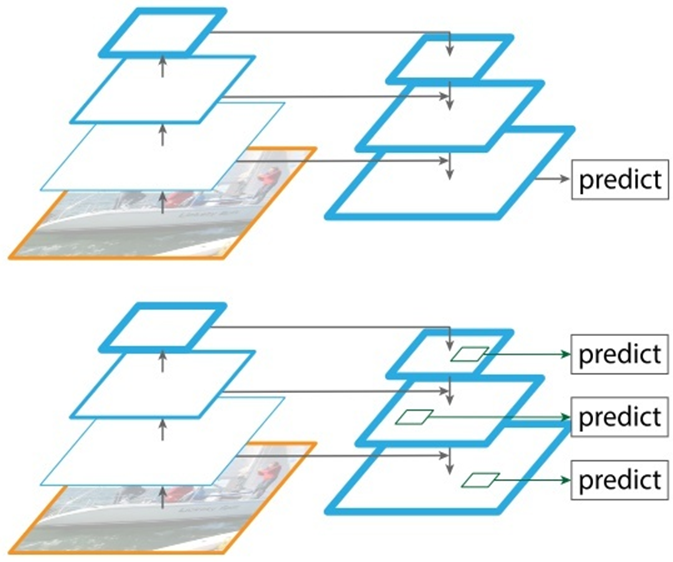
下图左上角粉色的那个网络就是展现着,“引入残差连接”
下图下方那三张大小,由“小”、“中”、“大”的小狗的图片表示的是“对于三个尺寸不同的目标使用相同的方式进行目标检测”

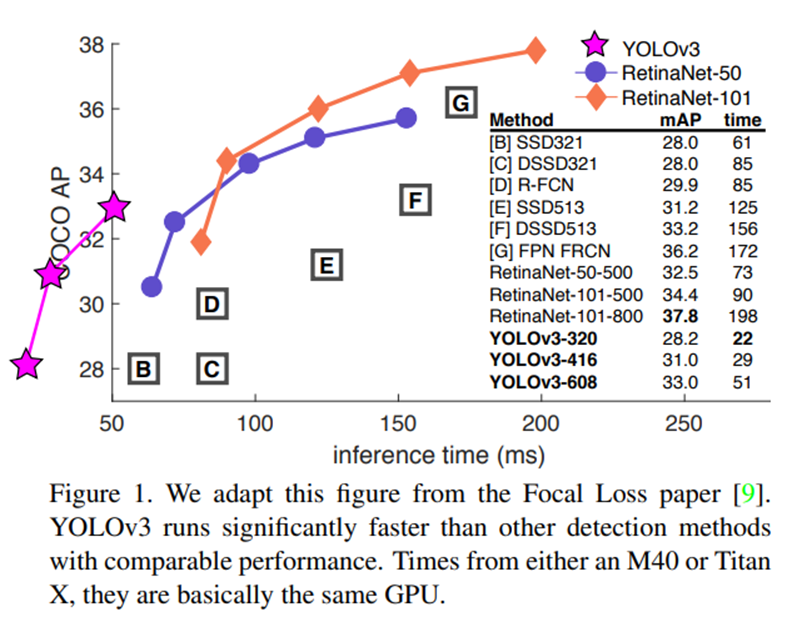
通过下面这个模型速度与精度的示意图,可以看出YOLOv3从速度上远远快于同期的其他模型。
一、Backbone上使用DarkNet53
Backbone改进后效果如何?
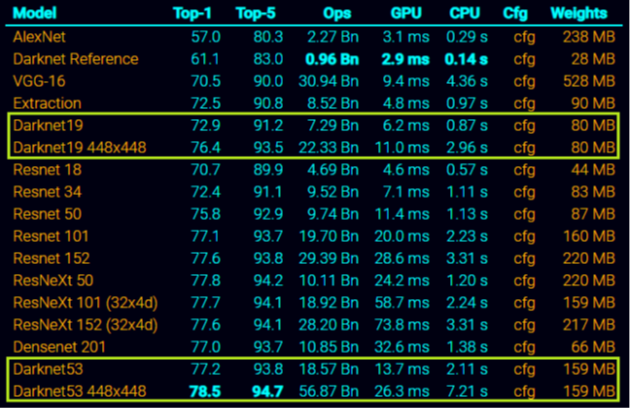
YOLOv3的backnone是DarkNet53。
——对比DarkNet19可以发现,它比VGG16的的参数量要少(VGG16的模型文件的大小是528MB, DarkNet19的weight是80MB),速度更快了(VGG16=9.4s; DarkNet19=6.2ms),但是精度反而有上升(VGG16=90.0; DarkNet19=91.2)‘
YOLOv2使用的backbone是DarkNet19’
这里DarkNet19为什么参数量降低了这么多?因为VGG中最后一节组件Fully Connected全连接层占用了大量参数。DarkNet19将Fully Connected这一层替换成了别的,所以参数量才降低的这么明显。
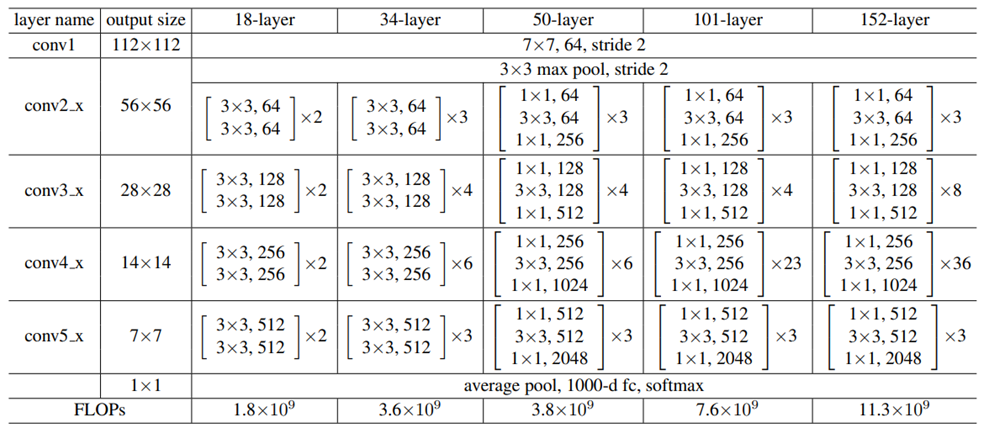
——ResNet101和DarkNet53都具有残差结构。但是DarkNet53相比ResNet101,在参数量差不多的情况下(ResNet101=160MB, DarkNet53=159MB),精度高一点点(ResNet101=93.7, DarkNet53=93.7),速度更快(ResNet101=20ms; DarkNet53=13.7ms)
为什么这样改,会有效果?解释一下
为什么DarkNet19能在减少参数量和包装速度较快的同时,保证精度较高?
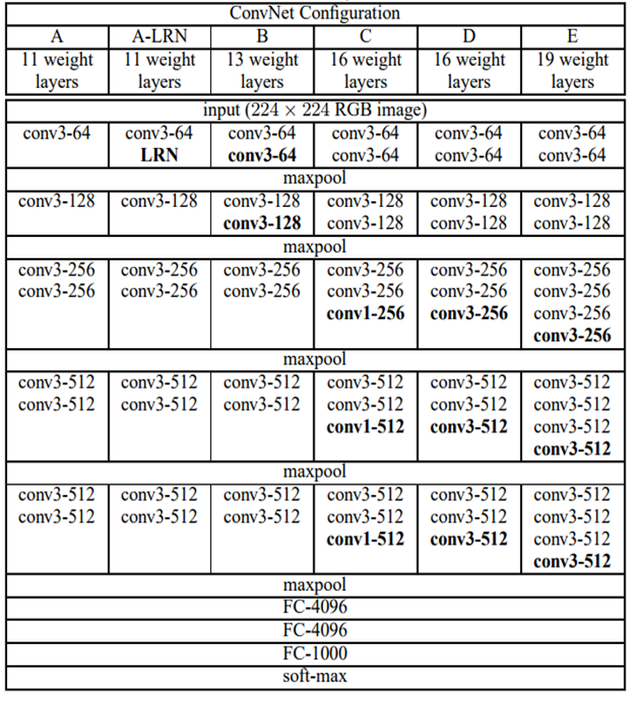
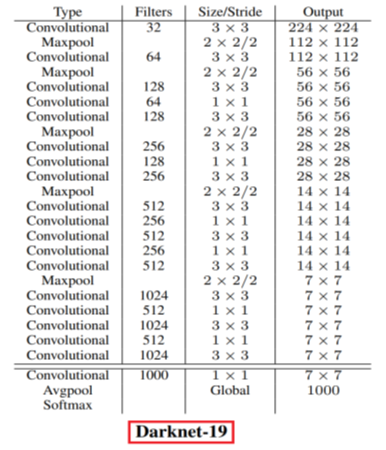
参数量的减少和速度较快归功于:首先可以看到VGG16最后几个模块是3个Fully Connect层。而右边的DarkNet19则完全抛弃掉Fully Connected这个组件,继而以1×1卷积在模型的结尾替换掉FC层的位置。FC层在这里起作用的是过渡(transition),比如你看Dark19每隔着几个套件就有一个1×1卷积,主要就是用于衔接不同组件的。
VGG16这个图中那些出现多次数字比如512和256指的是channel数。而DarkNet19的通道数则是图中Filters这一列
为什么我们需要残差连接?
为什么在VGG系列和DarkNet19发布的2006年,当时的网络最深就是到19层,比如在那一年VGG系列最深就是VGG19,无法更深呢?
何凯明在他的ResNet论文中给出的解答。网络越深,training error和testing error越来越大,精度相较于浅层网络还会有所下降。因为随着网络的加深,会出现梯度弥散(梯度消失),很多的有关特征的信息会消失在网络的更深层处,导致没法呈现最佳效果。当然在ResNet这篇文章中,作者何凯明提出了 残差连接 Residual Block的设计结构,使得网络得以突破19层这个frontier,向继续深里面扩展。
什么是残差连接?
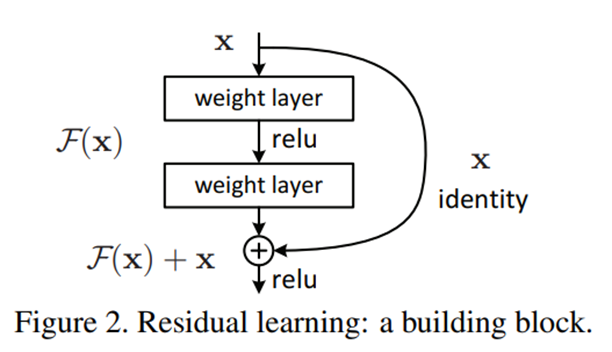
经过各种卷积处理过后的输出数据和没经过各种处理的原始输入数据加在一起,就是残差连接
加入残差连接的好处?
之所以要把原始数据再加给输出数据,是因为某些特征会在经过那一堆卷积的过程中消失掉(也就是梯度消失),通过加入原始数据就可以找回丢失的特征或者丢失的信息。不用残差连接你就捕捉不到这些有用的信息或者特征,自然分数就会低。
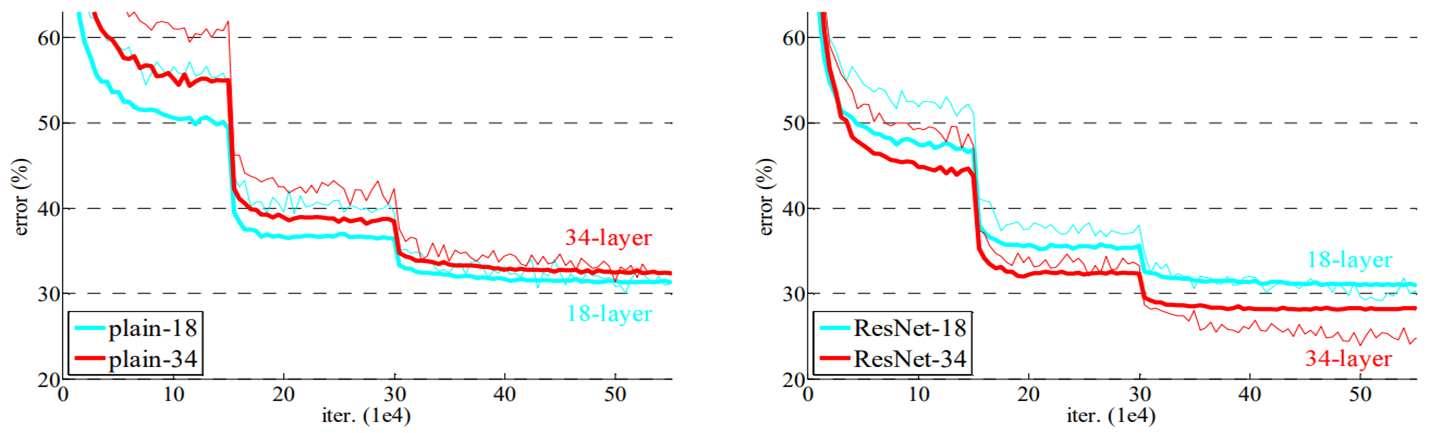
加入残差模型之前浅蓝色线(18层网络)的error是低于红线(34层网络)。但是一旦加入残差连接,红线里面低于浅蓝色线,深层网络的误差低于浅层网络。
既然ResNet这么好,为什么作者在YOLOv3里面没有直接“拿来主义”,直接拿ResNet过来作为backbone,而是执意要自己设计一个新的backbone DarkNet53?
因为ResNet模型太大了(参数太多了),这会降低推理速度,影响实时性。
相比ResNet,DarkNet-53做了哪些改进?
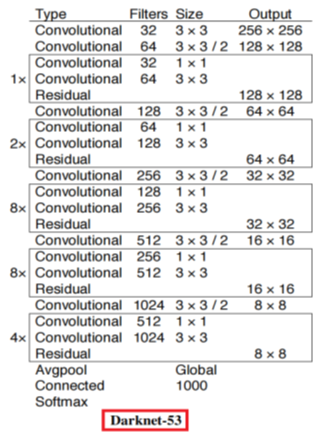
相同点:
都是用了Stride=2的3×3卷积代替max-pooling操作(二者效果差不多,都是一片3×3的区域降维成一个数字,只不过一个是取这9个数字中的max,一个是用卷积运算,把9个数整合成一个数字)
都是用了残差结构
不同点:
卷积层套件中卷积的个数更少。下图中倒数第二列101-layer可以看到ta的卷积核堆叠个数都是3个(看ResNet图右边第二列有四行,四个格子,每个格子里面都有三行,表示三个卷积)。而右边的DarkNet53每个卷积套件,只堆叠2个卷积
最后一层的通道数更少。DarkNet53最后一层的通道数为1024,而ResNet101最后一层通道数是2048,是DarkNet53的两倍。
残差块的个数(注意这里说的不是卷积核的个数,而是一个残差块重复串行多少次),ResNet101用的是(3,4,23,3),而DarkNet的是(1,2,8,4)。后者的残差块个数设计更合理,前者的残差块设计有一定的冗余性
ResNet101和DarkNet53 performance 对比

二者在精度差不多的情况下(Top5,一个是93.7,一个是93.8),速度提高了50%(BFLOP/s,ResNet101是1039,而DarkNet53是1457)
二、Feature Pyramid Network(FPN)的加入

加入FPN的目的:
为了识别不同的尺度的目标,比如大目标、小目标、中型尺寸的目标。
backnone上不同深度的网络层会产生不同大小分辨率(尺寸大小不同)的特征图。不同深度层包含的语义信息也是有差距的,比如高分辨率的图(较浅层网络的特征图)具有较低层次low level语义信息semantic information的特征,不具有high level semantic information,对于分类任务是不友好的,但是对于定位任务的帮助就较大。
(a)Featurized image pyramid: 将图片缩放后(缩放成 大尺度、中尺度、小尺度),每一个尺度的图片,都提取一个图像特征,分别进行一个object的识别。注意这里对图片进行放缩使用的是人工设计的特征,还没使用CNN
(b),(c)和(d)以及FPN都是使用CNN卷积神经网络 来提取特征,这是因为(1)避免手工设计特征,减少了工作量(2)CNN可以学习到更高层的语义信息(3)CNN对于尺度变化更鲁棒(不同尺度,比如同样是CNN在大尺度、小尺度、中尺度上性能都差不多的好,不会说识别个小目标,性能变差了很多。当然这是相对而言的。)
(b)Single feature map和(c)Pyramidal feature hierarchy相比(a)Feature image pyramid的使用卷积神经网络实现特征的下采样,而不是手工提取特征。
YOLOv1和YOLOv2采用的是(b)single feature map
(b)和(c)的不同是,(b)仅仅在网络的最后一层进行目标检测这个任务。而(c)在 大尺度、中尺度、小尺度上都会各自进行一次识别
SSD是在YOLOv1和YOLOv2以后推出的一个目标检测模型。它相当于在图(c)的基础上再多深入几层,然后在更深的那几层里再出来三个不同尺度的目标检测头。SSD的作者这样设计是为了避免使用包含低级语义信息的特征。但是也正是因为如此,它错失了低级语义信息(高分辨率语义信息。)同时也因为网络过于深,深到这种程度是冗余的,造成推理速度变慢,实时性不强。
基于(a)(b)(c)的以下不足,
(a)Featurized image pyramid,特征化的图像金字塔,的问题在于用手工设计的特征层,挨个提取,很冗余。因为你使用卷积的话,每个channel共享同一个卷积核的参数。卷积核参数共享,极大降低了参数量。
(b)Single feature map,单尺度:改进:用卷积神经网络自动化提取特征、参数量较小的提取特征,取代了手工设计提取特征。缺点:也就是只在最深的那一层连接一个head做识别,那么可能会大目标识别的很好,小目标是识别的就差了,造成不同尺寸目标识别的performance不鲁棒(性能不稳定)。
(c)Pyramidal feature hierarchy:改进:比起(b)的改进是不只有最深的那个层次一个识别head,在不同深度的层上有多个head。缺点:但是不同深度的语义层时间没有一个很好的关联,这三个检测头各自独立之间没有什么信息的融合
所以FPN, 图(d), 做了下列改进
(1)减少参数量/计算量,保持现有的深度(下采样:8倍、16倍、32倍),不和SSD那样冗余的把网络做深。

(2)融合 更深层/低分辨率/高层语义信息丰富(高层语义信息丰富利于分类任务) 和 更浅层/高分辨率/.底层语义信息/空间信息丰富。
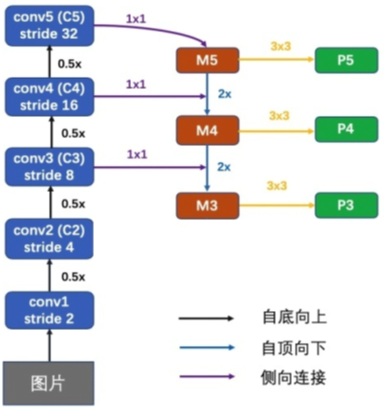
具体方式是:左边先用卷积进行多次下采样,然后再把最深层次的语义信息上采样,然后和浅一点的层进行融合,然后多次上采样然后融合得到多层次的语义信息,然后在连接head进行目标检测。
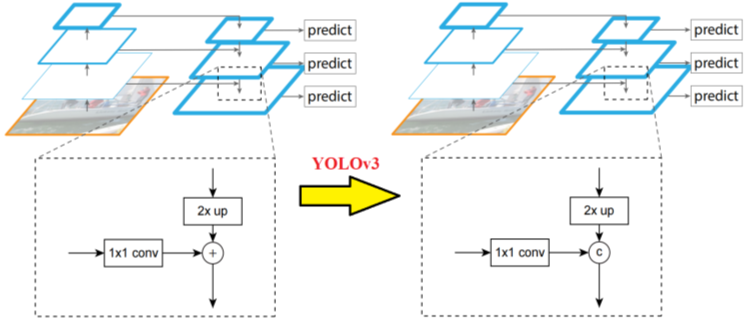
融合的方式这里要注意,这里的融合使用的不是point-wise add,逐个元素相加,而是使用的concate 拼接的方式。因为,逐元素相加,会掩盖一些梯度信息,也就是掩盖一些比较重要的特征。但是使用concate融合是不改变被融合的两个特征的 重要度 的,也就是两个特征都被当做重要性差不多的特征来平等对待。
三、Anchor-based
YOLOv3是Anchor-based的方法。
假设输入图像是416×416的RGB三通道的图像。YOLOv3会产生3个尺度的特征图,分别是大尺寸、中尺寸、小尺寸。这三种尺寸对应法的Grid Cell(网格)个数分别为13×13, 26×26,52×52。之所以Grid Cell的个数是这3种,因为每种尺度的一个Grid Cell这个正方形的长和宽分别为32个像素、16、8。
对于每个Grid Cell会对应3个Anchor Box.(每个Grid Cell对应哪三个anchor box,怎么画,我现在还不是很清楚)。下面这个有狗的三张图片,黄色是对狗的一个识别。蓝色的那三个框,是对于位于图片最中间的那个Grid Cell画的3个Anchor Box。
那么在下面这张小狗的图片上,我们总共产生了(13×13+26×26+52×52)×3=10647个检测框

13×13检测大尺寸的目标。
13是这样来的,以32倍下采样为标准,计算下采样后的特征图尺寸416/32=13。13×13的特征图上每一个点就对应现在这一个Grid Cell,一如特征图上有13×13个点,13×13的Grid Cell上有13×13个点,是一一对应的。
(因为(1)格子大,能装进这个格子或者这个格子和别的格子合并后组成的矩形区域较大,所以可以把大目标框进去(2)针对一个格子的话,格子大,相比格子小的情况,更可能看到狗这个object的全局。如果是右边52×52,假定识别的是狗脖子上那个小铃铛这个小目标,用大的格子会框到大量铃铛外面、和铃铛无关的区域;而使用52×52的格子,就恰好可以用几个小格子、十分精确地把铃铛框出来,使得与铃铛无关的区域尽可能少的被囊括)
26×26检测中型尺寸中目标
52×52检测小型尺寸的目标
不同尺度的特征图,应该使用 大小不同的 Grid Cell,从而能够更好的适应这个特征图,检测出尺寸大小不同的目标。
注意上面那个例子里图片的清晰度-模糊程度,其实是不合理的,但是为了简单,我就不重新制作一个图了,你懂这么回事就行了。具体哪里不合理,如下:三个尺度不同的特征图应该展现出右侧 小尺寸特征图 分辨率格外高、图片格外清晰, 左边这个 大尺寸特诊图 经过了多次卷积,应该格外模糊。
我们最终检测结束,需要计算模型的损失Loss。这个Loss是由(1)object所属类别(2)object的bounding box的坐标(3)bouding box里面含有这个object。的置信度、
object属于的类别,根据微软COCO数据集,有80个类别
bouding box的坐标的话,只需要4个数据就可定位这个识别框。bbox的中心点的横坐标、纵坐标,bbox的宽和高
置信度的话,就是一个值域在[0,1]之间的一个数字。这个置信度评估的是这个框中有可能有object的可能性的大小。
因此算下来一共需要80+4+1=85个数字就能把这个loss计算所需的原始数据准备出来。
对于上面这Grid Cell,里面每一个网格,都对应了85个维度的Tensor
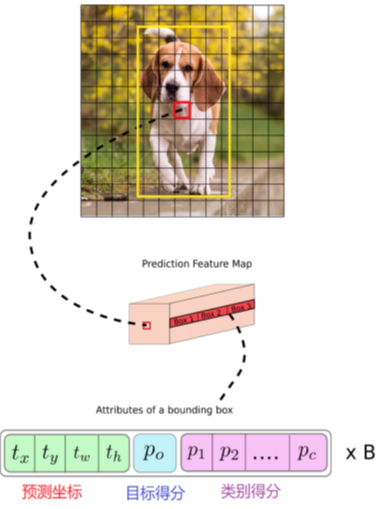
那么loss是由哪些对于每个Grid Cell,都对应这一个85维的Tensor。
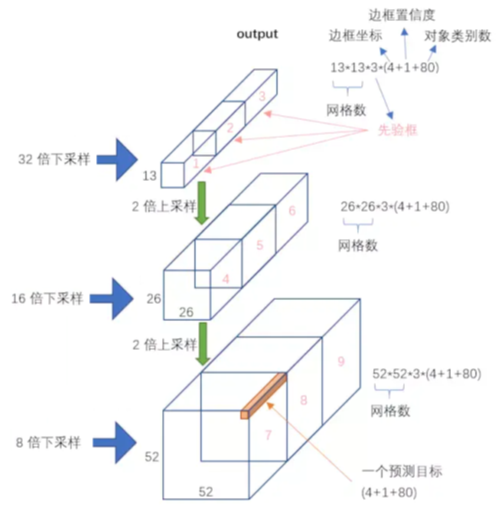
你可能会好奇,8倍下采样、16倍下采样、32倍下采样对应的那个检测头 detection head最后的output有多少个数字?我们来一起计算一下
32倍下采样,得到尺寸为13×13的feature map,每一个grid cell上有3个anchor box,每个anchor box上是一个85个元素组成的tensor
所以32倍下采样的output的元素数字是(13×13)×3×85、
16倍下采样的output元素个数是 (26×26)×3×85
8倍下采样的output元素个数是 (52×52)×3×85
四、bbox坐标表示:相对坐标

YOLOv3 为了 预测出目标的bouding box的绝对位置, 先定位到这一个点是属于哪一个Grid Cell的,然后再预测出这个点 相对于Grid Cell左上角这个点的 出相对位置, 然后再根据bouding box中心点相对于Grid Cell左上角的相对坐标,进一步计算 推算 出bbox的绝对位置。 具体来说,就是先预测出(tx, ty, tw, th, t0),然后通过以下坐标偏移公式计算得到bbox的位置大小和置信度。
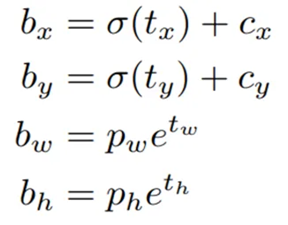
简单说,回归的不是绝对坐标,而是相对于Grid Cell左上角那个点的相对坐标
相当于我们给了Grid Cell一个先验知识,这个先验知识是:这个目标就在某一个Grid Cell里面,你只需要回归一个相对于Grid Cell的坐标值即可。
tx, ty, tw, th是首先拿到的模型预测输出。然后他们通过下面这一连串的处理,得到目标中心点(bx, by)和bouding box的宽bw和高bh。
cx和cy表示Grid Cell左上角这个点的横坐标和纵坐标。比如假设某层特征图的大小
对于目标中心点bx和by的得到,这一连串的处理,包括,先把tx和ty过一个函数(sigmoid函数 )然后在加上Grid Cell的的坐标cx和cy,就可以得到真实中心点的坐标bx和by。
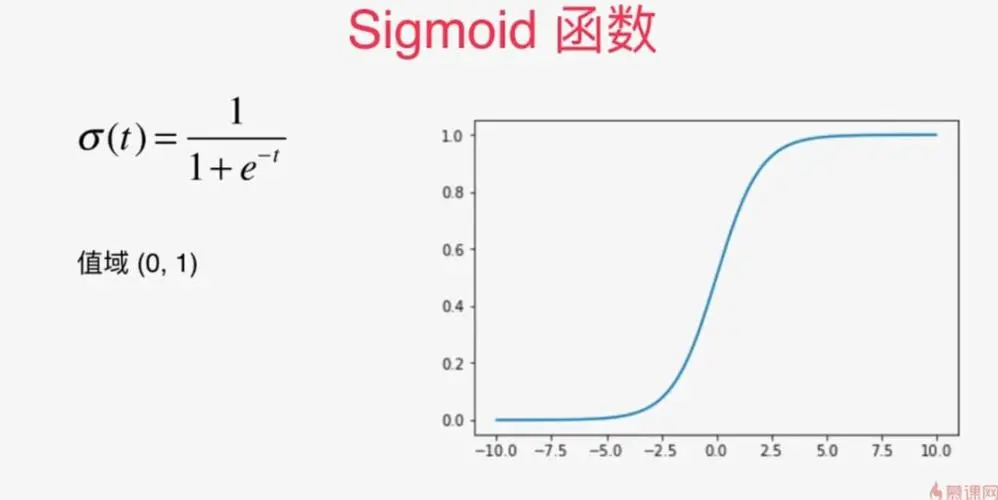
这里使用sigmoid函数是因为。sigmoid函数能够把输入的区间上的任何一组数据,放缩投影到
这个区间,输出这个结果就像一个百分比数字一样。因为cx是anchor box左上角那个点的横坐标,一个anchor box的长和宽最大就是1个像素,就像被左上角点横坐标
j加上的这个不大于1的数字
,很好的刻画了,从anchor box左上角点
向右下方这1×1的这个方框里面每个可能的点的横纵坐标。
为什么使用相对位置?
因为如果预测绝对位置的话,在训练的时候不容易收敛的。因此采用相对位置,网络更容易收敛到一个比较好的结果。
训练这几个坐标值的时候,采用了平方和损失。原因是这种方式的误差可以很快的计算出来。只不过,这种平方和损失,现在已经不使用了。
Confidence置信度的计算使用这个公式计算。Confidence= P(Object)×IoU 。
这个置信度指的是是这个bouding box里面含有这个object的置信度,也就是这个bbox预测的有多么准。
这里这个P(object)要么是0,要么是1。这个bbox里面如果有object,P(object)=1。如果这个bbox框出的区域里面没有object,也就是说bbox里面框出的不是前景而是背景,那么P(Object)=0。
也就是说,当bbox里面框出的区域有object,confidence就是object的预测框和真实框之间的IoU.如果bbox里面框出的区域没有object,这个confidence就是0。
五、正负样本的匹配
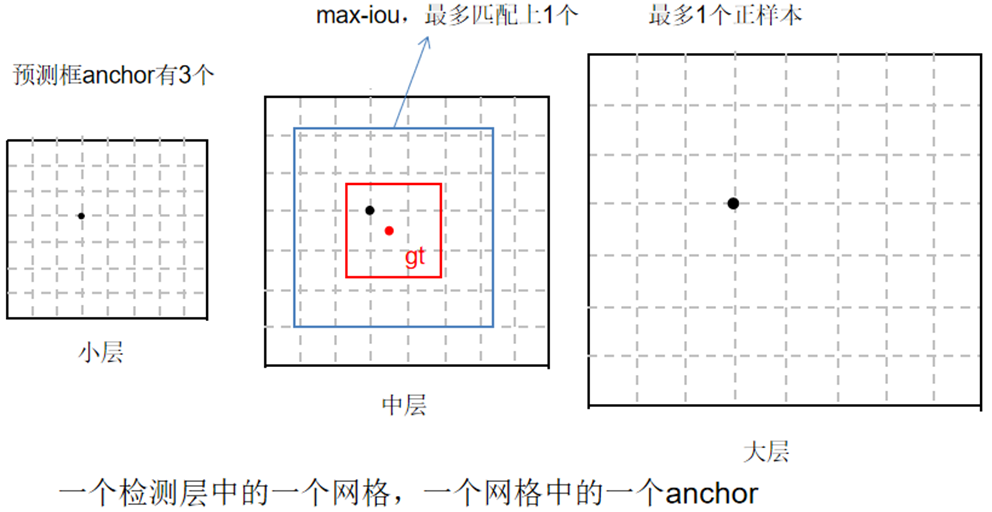
大尺寸、中尺寸、小尺寸 三个尺度 对同一张图使用三个不同数量的Grid Cell,就被称为有三个anchor。
每个anchor里面这个一个个小格子叫 Grid Cell.
YOLOv3所使用的正负样本匹配规则只给每一个Ground Truth分配一个正样本(注意:这里的重点是只分配一个正样本,只分配一个哦,太少了吧!)。正样本的成立的前提是,IoU大于你设定的阈值。这个正样本是在所有的predicted bouding box找一个与GT重叠区域最大(IoU值最大)的预测框。
如果一个样本不是正样本(predicted bouding box里面在ground truth上实际没有object),连object都没有,那自然更没有object的位置和object的类别了,自然也就没有定位损失和类别损失。但是这些负样本是有置信度损失的,因为置信度损失评估是是bbox里面有无object这一项。
但是上面这种正负样本匹配规则导致了一个结果,大部分的样本都是负样本(大量的predicted bouding box里面实际是并没有object的),正样本只占总样本的极小的一部分。这种极度的样本不均衡如何处理呢?YOLOv3的作者尝试引入Focal Loss来缓解这一问题。但是效果并不好,原因是负样本值参与了置信度的损失,对Loss的影响占比很小(因为负样本的confidence就是0,很小会影响到置信度的损失,这一点,我也不是很懂)。
上面这样设计正负样本匹配机制的坏处是,正样本的数量过于少,使得网络难以训练。(既然大多数的情况都是负样本,也就是bouding box打错了的情况,那我这个模型为了accuracy,进来所有的样本都判定为负样本以后,accuracy不就高了吗?样本极度不均衡的情况下,导致模型从正例、负例的样本中什么有价值的信息都没学到,变成一个见到样本就判定为负样本的机器。网络训练失败。)
那么为了解决这一个问题,在正例的选择上就选择,predicted 和 GT的IoU最大的前三名作为正例,就使得正例的数量变多了,
六、损失函数
YOLOv3的Loss分3个部分

(1)bouding box坐标误差,bbox loss,用bbox中心点(x,y)和bbox的宽w和高h。
bbox中心点的损失的评估是一个squared error平方误差的损失, 横纵坐标的真实值减预测值再平方求和。这样得出来的结果就是
bbox宽和高,先开根号,在predicted和GT做差平方求和
然后损失函数的前两行通过乘以来实现加权平均
(2)置信度误差,obj loss,也就是评估这个bouding box里面是否有object,别管哪个类别的object 人类、汽车、公交车、摩托车 都不重要,重要的是有没有object。
(3)类别误差,class loss,80个类别里属于每个类别的误差。
置信度损失和类别损失都使用的是cross entropy交叉熵损失 (logit)。置信度损失使用的是一个二分类的损失,类别损失是一个多分类的损失。
YOLOv3以前的YOLO使用的是softmax做多分类,YOLOv3开始才使用的cross entropy。softmax输出是多个类别。之所以这样替换、升级,是因为softmax有一个不同类别之间相互抑制、非此即彼,这个object的类别要么属于A这个类别、要么属于B这个类别、这个object的类别不可以同时既是A类别也是B类别(当然属于A B两个类别的置信度肯定是有高的、有低的)。但是softmax(logit)可以把这些类别解耦出来,可以解决这种类别的冲突问题。
这里注意我计算类别损失 class loss的时候,只有我们算出我们是正样本的情况下,我们才计算我们的分类损失(这里有有点不懂,正样本就是predicted预测的类别和GT丽的真实类别一致的时候才是正样本,为什么不使用分类错误的样本也进来算分类错误呢?)
对于置信度损失,不管bbox里面有没有目标,不管是正样本还是负样本,我们都要计算置信度损失。
上面这个损失函数里面有一些参数,解释如下。
表示的是13×13(32倍下采样),26×26(16倍下采样),52×52(8倍下采样)这三个anchor
B代表每个网格产生的B个候选框
和
是这几个损失函数的加权平均 的 权重
表示在i,j处box有目标,有的话为1,没有的话为0
表示在i,j处box没有目标,有的话为1,没有的话为0