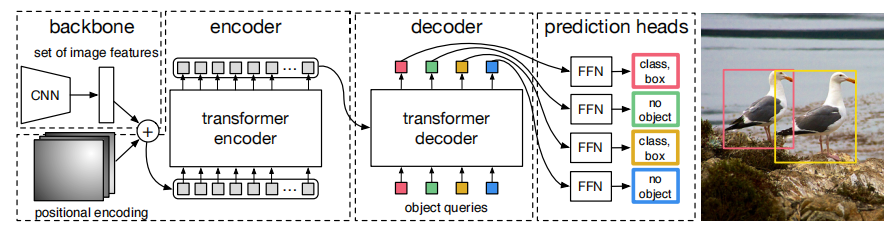
训练流程
1.输入图像经过CNN的backbone获得32倍下采样的深度特征;
2.将图片给拉直形成token,并添加位置编码送入encoder中;
3.将encoder的输出以及Object Query作为decoder的输入得到解码特征;
4.将解码后的特征传入FFN得到预测特征;
5.根据预测特征计算cost matrix,并由匈牙利算法匹配GT,获得正负样本;
6.根据正负样本计算分类与回归loss。
代码实现
书接上回,我们从代码层面讲解了训练步骤1,下面将详细解读DETR如何在encoder中处理token与位置编码的。def forward(self, x, mask, query_embed, pos_embed):可以看到输入transformer forwad函数中的x表示步骤1的32倍下采样特征([2,256,22,38]维度),query_embed是用于decoder的可学习编码(即论文中的object query维度为[100,256]),pos_embed表示位置编码维度与x一致,mask表示图片有效区域(维度为[2,22,38])。
首先,需要将x,pos_embed,mask的h,w二维结构拉直成h*w的一维结构,即将x特征拉直成tokens。然后,x(维度[836,2,256])作为query,query_pos=pos_embed(维度[836,2,256]),query_key_padding_mask=mask(维度[2,836]),将三者送入self.encoder中。
class Transformer(BaseModule):
"""Implements the DETR transformer.
Following the official DETR implementation, this module copy-paste
from torch.nn.Transformer with modifications:
* positional encodings are passed in MultiheadAttention
* extra LN at the end of encoder is removed
* decoder returns a stack of activations from all decoding layers
See `paper: End-to-End Object Detection with Transformers
<https://arxiv.org/pdf/2005.12872>`_ for details.
Args:
encoder (`mmcv.ConfigDict` | Dict): Config of
TransformerEncoder. Defaults to None.
decoder ((`mmcv.ConfigDict` | Dict)): Config of
TransformerDecoder. Defaults to None
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Defaults to None.
"""
def __init__(self, encoder=None, decoder=None, init_cfg=None):
super(Transformer, self).__init__(init_cfg=init_cfg)
self.encoder = build_transformer_layer_sequence(encoder)
self.decoder = build_transformer_layer_sequence(decoder)
self.embed_dims = self.encoder.embed_dims
def init_weights(self):
# follow the official DETR to init parameters
for m in self.modules():
if hasattr(m, 'weight') and m.weight.dim() > 1:
xavier_init(m, distribution='uniform')
self._is_init = True
def forward(self, x, mask, query_embed, pos_embed):
"""Forward function for `Transformer`.
Args:
x (Tensor): Input query with shape [bs, c, h, w] where
c = embed_dims.
mask (Tensor): The key_padding_mask used for encoder and decoder,
with shape [bs, h, w].
query_embed (Tensor): The query embedding for decoder, with shape
[num_query, c].
pos_embed (Tensor): The positional encoding for encoder and
decoder, with the same shape as `x`.
Returns:
tuple[Tensor]: results of decoder containing the following tensor.
- out_dec: Output from decoder. If return_intermediate_dec \
is True output has shape [num_dec_layers, bs,
num_query, embed_dims], else has shape [1, bs, \
num_query, embed_dims].
- memory: Output results from encoder, with shape \
[bs, embed_dims, h, w].
"""
bs, c, h, w = x.shape
# use `view` instead of `flatten` for dynamically exporting to ONNX
x = x.view(bs, c, -1).permute(2, 0, 1) # [bs, c, h, w] -> [h*w, bs, c]
pos_embed = pos_embed.view(bs, c, -1).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(
1, bs, 1) # [num_query, dim] -> [num_query, bs, dim]
mask = mask.view(bs, -1) # [bs, h, w] -> [bs, h*w]
memory = self.encoder(
query=x,
key=None,
value=None,
query_pos=pos_embed,
query_key_padding_mask=mask)
target = torch.zeros_like(query_embed)
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder(
query=target,
key=memory,
value=memory,
key_pos=pos_embed,
query_pos=query_embed,
key_padding_mask=mask)
out_dec = out_dec.transpose(1, 2)
memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)
return out_dec, memory
self.encoder在transformer初始化时已经注册完毕,是来自class DetrTransformerEncoder(TransformerLayerSequence):的对象。从代码forward中可以看到,它没有单独实现这部分代码,而是直接使用父类DetrTransformerEncoder的forward。
class DetrTransformerEncoder(TransformerLayerSequence):
"""TransformerEncoder of DETR.
Args:
post_norm_cfg (dict): Config of last normalization layer. Default:
`LN`. Only used when `self.pre_norm` is `True`
"""
def __init__(self, *args, post_norm_cfg=dict(type='LN'), **kwargs):
super(DetrTransformerEncoder, self).__init__(*args, **kwargs)
if post_norm_cfg is not None:
self.post_norm = build_norm_layer(
post_norm_cfg, self.embed_dims)[1] if self.pre_norm else None
else:
assert not self.pre_norm, f'Use prenorm in ' \
f'{self.__class__.__name__},' \
f'Please specify post_norm_cfg'
self.post_norm = None
def forward(self, *args, **kwargs):
"""Forward function for `TransformerCoder`.
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
x = super(DetrTransformerEncoder, self).forward(*args, **kwargs)
if self.post_norm is not None:
x = self.post_norm(x)
return x
在对TransformerLayerSequence初始化时,通过num_layer(config中设置为6)设置encoder的层数,即self.layers的层数。transformerlayers是从config传入的dict,如下所示,构成self.layers的是BaseTransformerLayer这个类,其中self.pre_norm=False, self.embed_dims=256, 这里因为嵌套的类比较多,看起来有些复杂,我们慢慢剖析。
{‘type’: ‘BaseTransformerLayer’, ‘attn_cfgs’: [{‘type’: ‘MultiheadAttention’, ‘embed_dims’: 256, ‘num_heads’: 8, ‘dropout’: 0.1}], ‘feedforward_channels’: 2048, ‘ffn_dropout’: 0.1, ‘operation_order’: (‘self_attn’, ‘norm’, ‘ffn’, ‘norm’)}
class TransformerLayerSequence(BaseModule):
"""Base class for TransformerEncoder and TransformerDecoder in vision
transformer.
As base-class of Encoder and Decoder in vision transformer.
Support customization such as specifying different kind
of `transformer_layer` in `transformer_coder`.
Args:
transformerlayer (list[obj:`mmcv.ConfigDict`] |
obj:`mmcv.ConfigDict`): Config of transformerlayer
in TransformerCoder. If it is obj:`mmcv.ConfigDict`,
it would be repeated `num_layer` times to a
list[`mmcv.ConfigDict`]. Default: None.
num_layers (int): The number of `TransformerLayer`. Default: None.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
"""
def __init__(self, transformerlayers=None, num_layers=None, init_cfg=None):
super(TransformerLayerSequence, self).__init__(init_cfg)
if isinstance(transformerlayers, dict):
transformerlayers = [
copy.deepcopy(transformerlayers) for _ in range(num_layers)
]
else:
assert isinstance(transformerlayers, list) and \
len(transformerlayers) == num_layers
self.num_layers = num_layers
self.layers = ModuleList()
for i in range(num_layers):
self.layers.append(build_transformer_layer(transformerlayers[i]))
self.embed_dims = self.layers[0].embed_dims
self.pre_norm = self.layers[0].pre_norm
def forward(self,
query,
key,
value,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `TransformerCoder`.
Args:
query (Tensor): Input query with shape
`(num_queries, bs, embed_dims)`.
key (Tensor): The key tensor with shape
`(num_keys, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_keys, bs, embed_dims)`.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`.
Default: None.
attn_masks (List[Tensor], optional): Each element is 2D Tensor
which is used in calculation of corresponding attention in
operation_order. Default: None.
query_key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_queries]. Only used in self-attention
Default: None.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_keys]. Default: None.
Returns:
Tensor: results with shape [num_queries, bs, embed_dims].
"""
for layer in self.layers:
query = layer(
query,
key,
value,
query_pos=query_pos,
key_pos=key_pos,
attn_masks=attn_masks,
query_key_padding_mask=query_key_padding_mask,
key_padding_mask=key_padding_mask,
**kwargs)
return query
在TransformerLayerSequence的forward中,我们看到在init初始化好的self.layers,它是个Modulelist,里面重复了6次layer,layer是BaseTransformerLayer这个类的对象。
在BaseTransformerLayer初始化里,self.batch_first=False,operation_order里面按序存放了算子名称,如下所示,self_attn指MultiheadAttention,norm表示layer norm,ffn就是FFN。num_attn表示operation_order的self_attn自注意力和cross_attn交叉注意力出现的次数。在encoder中,operation_order存放了一个self_attn,self_attn与cross_attn具体区别会在下面讲到。
(‘self_attn’, ‘norm’, ‘ffn’, ‘norm’)
attn_cfgs存放了如下参数,添加batch_first属性为False,并使用attn_cfgs初始化attention,attention是来自MultiheadAttention的对象,其中token的维度为256,多头数为8,dropout系数是0.1。
[{‘type’: ‘MultiheadAttention’, ‘embed_dims’: 256, ‘num_heads’: 8, ‘dropout’: 0.1}]
接下来num_ffns表示operation_order中FFN的个数,同样构建ffn_cfgs存放FFN需要的参数,其中embed_dims与attention保持一致即256,self.norms用来指向layer norm。
class BaseTransformerLayer(BaseModule):
"""Base `TransformerLayer` for vision transformer.
It can be built from `mmcv.ConfigDict` and support more flexible
customization, for example, using any number of `FFN or LN ` and
use different kinds of `attention` by specifying a list of `ConfigDict`
named `attn_cfgs`. It is worth mentioning that it supports `prenorm`
when you specifying `norm` as the first element of `operation_order`.
More details about the `prenorm`: `On Layer Normalization in the
Transformer Architecture <https://arxiv.org/abs/2002.04745>`_ .
Args:
attn_cfgs (list[`mmcv.ConfigDict`] | obj:`mmcv.ConfigDict` | None )):
Configs for `self_attention` or `cross_attention` modules,
The order of the configs in the list should be consistent with
corresponding attentions in operation_order.
If it is a dict, all of the attention modules in operation_order
will be built with this config. Default: None.
ffn_cfgs (list[`mmcv.ConfigDict`] | obj:`mmcv.ConfigDict` | None )):
Configs for FFN, The order of the configs in the list should be
consistent with corresponding ffn in operation_order.
If it is a dict, all of the attention modules in operation_order
will be built with this config.
operation_order (tuple[str]): The execution order of operation
in transformer. Such as ('self_attn', 'norm', 'ffn', 'norm').
Support `prenorm` when you specifying first element as `norm`.
Default:None.
norm_cfg (dict): Config dict for normalization layer.
Default: dict(type='LN').
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
batch_first (bool): Key, Query and Value are shape
of (batch, n, embed_dim)
or (n, batch, embed_dim). Default to False.
"""
def __init__(self,
attn_cfgs=None,
ffn_cfgs=dict(
type='FFN',
embed_dims=256,
feedforward_channels=1024,
num_fcs=2,
ffn_drop=0.,
act_cfg=dict(type='ReLU', inplace=True),
),
operation_order=None,
norm_cfg=dict(type='LN'),
init_cfg=None,
batch_first=False,
**kwargs):
super(BaseTransformerLayer, self).__init__(init_cfg)
self.batch_first = batch_first
num_attn = operation_order.count('self_attn') + operation_order.count(
'cross_attn')
if isinstance(attn_cfgs, dict):
attn_cfgs = [copy.deepcopy(attn_cfgs) for _ in range(num_attn)]
else:
assert num_attn == len(attn_cfgs), f'The length ' \
f'of attn_cfg {num_attn} is ' \
f'not consistent with the number of attention' \
f'in operation_order {operation_order}.'
self.num_attn = num_attn
self.operation_order = operation_order
self.norm_cfg = norm_cfg
self.pre_norm = operation_order[0] == 'norm'
self.attentions = ModuleList()
index = 0
for operation_name in operation_order:
if operation_name in ['self_attn', 'cross_attn']:
if 'batch_first' in attn_cfgs[index]:
assert self.batch_first == attn_cfgs[index]['batch_first']
else:
attn_cfgs[index]['batch_first'] = self.batch_first
attention = build_attention(attn_cfgs[index])
# Some custom attentions used as `self_attn`
# or `cross_attn` can have different behavior.
attention.operation_name = operation_name
self.attentions.append(attention)
index += 1
self.embed_dims = self.attentions[0].embed_dims
self.ffns = ModuleList()
num_ffns = operation_order.count('ffn')
if isinstance(ffn_cfgs, dict):
ffn_cfgs = ConfigDict(ffn_cfgs)
if isinstance(ffn_cfgs, dict):
ffn_cfgs = [copy.deepcopy(ffn_cfgs) for _ in range(num_ffns)]
assert len(ffn_cfgs) == num_ffns
for ffn_index in range(num_ffns):
if 'embed_dims' not in ffn_cfgs[ffn_index]:
ffn_cfgs[ffn_index]['embed_dims'] = self.embed_dims
else:
assert ffn_cfgs[ffn_index]['embed_dims'] == self.embed_dims
self.ffns.append(
build_feedforward_network(ffn_cfgs[ffn_index],
dict(type='FFN')))
self.norms = ModuleList()
num_norms = operation_order.count('norm')
for _ in range(num_norms):
self.norms.append(build_norm_layer(norm_cfg, self.embed_dims)[1])
BaseTransformerLayer初始化介绍完之后,程序继续来到其forward中,在上面分析self.encoder的forward时,我们已经知道传到这里的参数:x作为query,query_pos=pos_embed,query_key_padding_mask=mask。我们在self.operation_order的循环里首先进入self_attn这个if分支,即进入MultiheadAttention的对象中,这里要注意 temp_key = temp_value = query,即qkv都是x。
def forward(self,
query,
key=None,
value=None,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `TransformerDecoderLayer`.
**kwargs contains some specific arguments of attentions.
Args:
query (Tensor): The input query with shape
[num_queries, bs, embed_dims] if
self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
value (Tensor): The value tensor with same shape as `key`.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`.
Default: None.
attn_masks (List[Tensor] | None): 2D Tensor used in
calculation of corresponding attention. The length of
it should equal to the number of `attention` in
`operation_order`. Default: None.
query_key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_queries]. Only used in `self_attn` layer.
Defaults to None.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_keys]. Default: None.
Returns:
Tensor: forwarded results with shape [num_queries, bs, embed_dims].
"""
norm_index = 0
attn_index = 0
ffn_index = 0
identity = query
if attn_masks is None:
attn_masks = [None for _ in range(self.num_attn)]
elif isinstance(attn_masks, torch.Tensor):
attn_masks = [
copy.deepcopy(attn_masks) for _ in range(self.num_attn)
]
warnings.warn(f'Use same attn_mask in all attentions in '
f'{self.__class__.__name__} ')
else:
assert len(attn_masks) == self.num_attn, f'The length of ' \
f'attn_masks {len(attn_masks)} must be equal ' \
f'to the number of attention in ' \
f'operation_order {self.num_attn}'
for layer in self.operation_order:
if layer == 'self_attn':
temp_key = temp_value = query
query = self.attentions[attn_index](
query,
temp_key,
temp_value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=query_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn':
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
看到MultiheadAttention的初始化,上面已经讲过这些参数,这里就没啥好介绍的,略过了。。。
class MultiheadAttention(BaseModule):
"""A wrapper for ``torch.nn.MultiheadAttention``.
This module implements MultiheadAttention with identity connection,
and positional encoding is also passed as input.
Args:
embed_dims (int): The embedding dimension.
num_heads (int): Parallel attention heads.
attn_drop (float): A Dropout layer on attn_output_weights.
Default: 0.0.
proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
Default: 0.0.
dropout_layer (obj:`ConfigDict`): The dropout_layer used
when adding the shortcut.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
batch_first (bool): When it is True, Key, Query and Value are shape of
(batch, n, embed_dim), otherwise (n, batch, embed_dim).
Default to False.
"""
def __init__(self,
embed_dims,
num_heads,
attn_drop=0.,
proj_drop=0.,
dropout_layer=dict(type='Dropout', drop_prob=0.),
init_cfg=None,
batch_first=False,
**kwargs):
super(MultiheadAttention, self).__init__(init_cfg)
if 'dropout' in kwargs:
warnings.warn(
'The arguments `dropout` in MultiheadAttention '
'has been deprecated, now you can separately '
'set `attn_drop`(float), proj_drop(float), '
'and `dropout_layer`(dict) ', DeprecationWarning)
attn_drop = kwargs['dropout']
dropout_layer['drop_prob'] = kwargs.pop('dropout')
self.embed_dims = embed_dims
self.num_heads = num_heads
self.batch_first = batch_first
self.attn = nn.MultiheadAttention(embed_dims, num_heads, attn_drop,
**kwargs)
self.proj_drop = nn.Dropout(proj_drop)
self.dropout_layer = build_dropout(
dropout_layer) if dropout_layer else nn.Identity()
在看到MultiheadAttention的forward,qkv都是x(维度[836,2,256]),query_pos=key_pos=pos_embed,在q,k上都加上位置编码,将图片位置信息与token结合。self.attn就是多头自注意力,细节在ViT中讲过,这里就不赘述了,最后,return的时候加上了残差以及droupout。
这里进行的是self_attn自注意力,即qkv=x,同时q,k需要加上位置编码。
从MultiheadAttention的forward出来后,又重新进入BaseTransformerLayer的forward,继续进入FFN以及layer norm。这个过程会重复6次。至此,self.encoder的工作就结束了。
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_pos=None,
attn_mask=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `MultiheadAttention`.
**kwargs allow passing a more general data flow when combining
with other operations in `transformerlayer`.
Args:
query (Tensor): The input query with shape [num_queries, bs,
embed_dims] if self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
If None, the ``query`` will be used. Defaults to None.
value (Tensor): The value tensor with same shape as `key`.
Same in `nn.MultiheadAttention.forward`. Defaults to None.
If None, the `key` will be used.
identity (Tensor): This tensor, with the same shape as x,
will be used for the identity link.
If None, `x` will be used. Defaults to None.
query_pos (Tensor): The positional encoding for query, with
the same shape as `x`. If not None, it will
be added to `x` before forward function. Defaults to None.
key_pos (Tensor): The positional encoding for `key`, with the
same shape as `key`. Defaults to None. If not None, it will
be added to `key` before forward function. If None, and
`query_pos` has the same shape as `key`, then `query_pos`
will be used for `key_pos`. Defaults to None.
attn_mask (Tensor): ByteTensor mask with shape [num_queries,
num_keys]. Same in `nn.MultiheadAttention.forward`.
Defaults to None.
key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
Defaults to None.
Returns:
Tensor: forwarded results with shape
[num_queries, bs, embed_dims]
if self.batch_first is False, else
[bs, num_queries embed_dims].
"""
if key is None:
key = query
if value is None:
value = key
if identity is None:
identity = query
if key_pos is None:
if query_pos is not None:
# use query_pos if key_pos is not available
if query_pos.shape == key.shape:
key_pos = query_pos
else:
warnings.warn(f'position encoding of key is'
f'missing in {self.__class__.__name__}.')
if query_pos is not None:
query = query + query_pos
if key_pos is not None:
key = key + key_pos
# Because the dataflow('key', 'query', 'value') of
# ``torch.nn.MultiheadAttention`` is (num_query, batch,
# embed_dims), We should adjust the shape of dataflow from
# batch_first (batch, num_query, embed_dims) to num_query_first
# (num_query ,batch, embed_dims), and recover ``attn_output``
# from num_query_first to batch_first.
if self.batch_first:
query = query.transpose(0, 1)
key = key.transpose(0, 1)
value = value.transpose(0, 1)
out = self.attn(
query=query,
key=key,
value=value,
attn_mask=attn_mask,
key_padding_mask=key_padding_mask)[0]
if self.batch_first:
out = out.transpose(0, 1)
return identity + self.dropout_layer(self.proj_drop(out))
程序返回到transformer的forward中,由self.encoder输出的memory维度为[836,2,256],它重新作为self.decoder的k与v。在self.decoder中,它的q=target,target是维度为[836,2,256]且值为0的tensor,key_pos=pos_embed,query_pos=query_embed, key_padding_mask=mask,这些参数传入到BaseTransformerLayer的forward中。
memory = self.encoder(
query=x,
key=None,
value=None,
query_pos=pos_embed,
query_key_padding_mask=mask)
target = torch.zeros_like(query_embed)
# out_dec: [num_layers, num_query, bs, dim]
out_dec = self.decoder(
query=target,
key=memory,
value=memory,
key_pos=pos_embed,
query_pos=query_embed,
key_padding_mask=mask)
out_dec = out_dec.transpose(1, 2)
memory = memory.permute(1, 2, 0).reshape(bs, c, h, w)
return out_dec, memory
self.decoder中的self.operation_order如下所示,包含了self_attn自注意力与cross_attn交叉注意力模块,num_layers=6。
(‘self_attn’, ‘norm’, ‘cross_attn’, ‘norm’, ‘ffn’, ‘norm’)
self_attn自注意力模块上面介绍过,需要注意的是,self.decoder第一次self_attn时,q=target(target维度为[836,2,256],值为0),temp_key = temp_value = query,在进入self.attentions后,qkv=0。
进入cross_attn分支,query来自self_attn,key=value=memory,即k,v是来自self.encoder生成的特征(维度为[836,2,256])。cross_attn交叉注意力与self_attn自注意力的区别在于,交叉注意力的query不等于key,value,qkv来源不同。 需要注意的是,这里的query_pos是object query(可学习编码[100,256]),在attention中,query需要与object query相加生成新的query。可以这么理解,在多头注意力中,加入了object query后,就如同添加100个可学习的anchor,这些anchor会与k计算相似度,并通过softmax归一化后作为value的系数,形成新的特征。通过学习,object query可以分别总结归纳出他们各自感兴趣的位置信息,从而帮助DETR完成目标检测的任务。
if query_pos is not None:
query = query + query_pos
if key_pos is not None:
key = key + key_pos
if layer == 'self_attn':
temp_key = temp_value = query
query = self.attentions[attn_index](
query,
temp_key,
temp_value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=query_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
**kwargs)
attn_index += 1
identity = query
由于DETR没有先验anchor,收敛难度大。为了更好优化梯度,将6层decoder输出的feature都保存下来,并分别分配给 auxiliary decoding losses。至此,self.decoder讲解完毕。
class DetrTransformerDecoder(TransformerLayerSequence):
"""Implements the decoder in DETR transformer.
Args:
return_intermediate (bool): Whether to return intermediate outputs.
post_norm_cfg (dict): Config of last normalization layer. Default:
`LN`.
"""
def __init__(self,
*args,
post_norm_cfg=dict(type='LN'),
return_intermediate=False,
**kwargs):
super(DetrTransformerDecoder, self).__init__(*args, **kwargs)
self.return_intermediate = return_intermediate
if post_norm_cfg is not None:
self.post_norm = build_norm_layer(post_norm_cfg,
self.embed_dims)[1]
else:
self.post_norm = None
def forward(self, query, *args, **kwargs):
"""Forward function for `TransformerDecoder`.
Args:
query (Tensor): Input query with shape
`(num_query, bs, embed_dims)`.
Returns:
Tensor: Results with shape [1, num_query, bs, embed_dims] when
return_intermediate is `False`, otherwise it has shape
[num_layers, num_query, bs, embed_dims].
"""
if not self.return_intermediate:
x = super().forward(query, *args, **kwargs)
if self.post_norm:
x = self.post_norm(x)[None]
return x
intermediate = []
for layer in self.layers:
query = layer(query, *args, **kwargs)
if self.return_intermediate:
if self.post_norm is not None:
intermediate.append(self.post_norm(query))
else:
intermediate.append(query)
return torch.stack(intermediate)
整个DETR的模型框架到这里就告一段落了,下面我们继续讲解label assignment以及相应的loss,看看DETR是如何优雅的解决端到端目标检测任务的。