之前一直用的是宫格的正方形拼图,但比如对“人”框的截图是这种高宽高比的长方形图片,按照最大边resize最小边等比例缩放后放入宫格中对造成最小边resize太多,整体图片缩小很多。所以本片专门针对高宽高比的图片拼图进行编辑。
本篇的拼图方式有2种:分别是长方形拼图和正方形拼图(即宫格拼图)。其中正方形拼图有4种,从1×1到4×4;长方形拼图有4种,分别是1×2、2×1、2×3、3×2,根据宽高比在哪个范围内以及横向或者纵向来判断按照对应的方式进行拼图。判断流程如下:
n×n的这里不再贴图演示,这里演示非宫格的拼图效果:
1×2:

2×1:

2×3:

3×2:

若是上面的流程图判断不是很清晰的话,可以看下面的数轴更加直观简单:
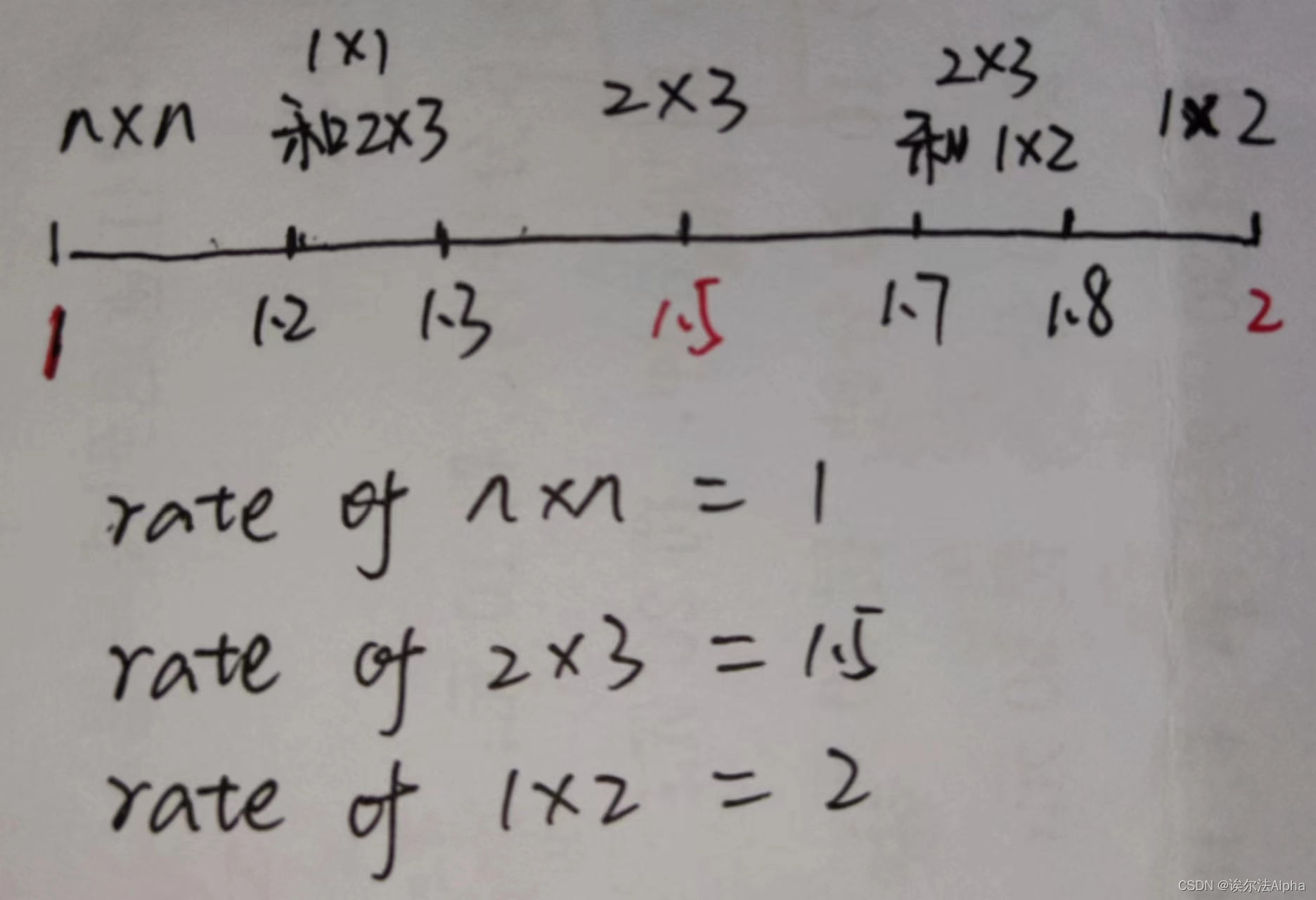
因为1.2到1.3与1.7到1.8是两边的中间区域,所以让这区间的图片同时resize成两个size的图片。
python">'''
5 size
1*1 1*2 2*1 2*3 3*2
'''
import codecs
from genericpath import exists
import random
import PIL.Image as Image
import os
import cv2
import json2txt
import sys
sys.path.append("/data/cch/拼图代码/format_transform")
import modeTxt
import shutil
import cut_bbox
# 图像拼接
def image_compose(idx, ori_tmp, num, save_path, gt_resized_path, bg_resized_path, imgsize, yr, xr, xs, ys):
to_image = Image.new('RGB', (imgsize, imgsize)) #创建一个新图
for y in range(yr):
for x in range(xr):
index = y*xr + x
if index >= len(ori_tmp):
break
open_path = [gt_resized_path, bg_resized_path]
for op in open_path:
if os.path.exists(os.path.join(op, ori_tmp[index])):
to_image.paste(Image.open(os.path.join(op, ori_tmp[index])), (
int(x * xs), int(y * ys)))
break
else:
continue
new_name = os.path.join(save_path, "2022workcloth_pedestrain_" + str(idx) + "_" + str(num) + ".jpg")
if xr == yr:
new_name = os.path.join(save_path, "2022workcloth_square_" + str(idx) + "_" + str(num) + ".jpg")
to_image.save(new_name) # 保存新图
# print(new_name)
return new_name
# 标签拼接
def labels_merge(ori_tmp, new_name, txt_resized_path, txt_pintu_path, yr, xr, xs, ys):
data = ""
for y in range(yr):
for x in range(xr):
index = y*xr + x
if index >= len(ori_tmp):
break
txt_path = os.path.join(txt_resized_path, ori_tmp[index].split(".")[0] + ".txt")
try:
os.path.exists(txt_path)
except:
print(txt_path, "file not exists!")
if os.path.exists(txt_path):
with codecs.open(txt_path, 'r', encoding='utf-8',errors='ignore') as f1:
for line in f1.readlines():
line = line.strip('\n')
a = line.split(' ')
a[2] = str(float(a[2]) + (x * xs))
a[3] = str(float(a[3]) + (y * ys))
a[4] = str(float(a[4]) + (x * xs))
a[5] = str(float(a[5]) + (y * ys))
b =a[0] + ' ' + a[1] + ' ' + a[2] + ' ' + a[3] + ' ' + a[4] + ' ' + a[5]
data += b + "\n"
write_path = os.path.join(txt_pintu_path, os.path.splitext(new_name)[0].split("/")[-1] + ".txt")
with open(write_path, 'w', encoding='utf-8') as f2:
f2.writelines(data)
# 涂黑处理
def pintu2black(txt_pintu_path, save_path, label_black, label_del, to_black_num, to_black_min_num):
files = os.listdir(txt_pintu_path)
for file in files:
img_path = os.path.join(save_path, os.path.splitext(file)[0] + ".jpg")
img_origal = cv2.imread(img_path)
data = ""
with codecs.open(txt_pintu_path+"/"+file, encoding="utf-8", errors="ignore") as f1:
for line in f1.readlines():
line = line.strip("\n")
a = line.split(" ")
xmin = int(eval(a[2]))
ymin = int(eval(a[3]))
xmax = int(eval(a[4]))
ymax = int(eval(a[5]))
if ((xmax - xmin < to_black_num) and (ymax - ymin < to_black_num)) or \
((xmax - xmin < to_black_min_num) or (ymax - ymin < to_black_min_num)) \
or a[1] in label_black:
img_origal[ymin:ymax, xmin:xmax, :] = (0, 0, 0)
cv2.imwrite(img_path, img_origal)
line = ""
if a[1] in label_del:
line = ""
if line:
data += line + "\n"
with open(txt_pintu_path+"/"+file, 'w', encoding='utf-8') as f2:
f2.writelines(data)
# print(data)
def gt_distribute(imgSave_path, ori, ori_spec, gt_resized_path, txt_path, gt_range):
image_names = os.listdir(imgSave_path)
for image_name in image_names:
imgPath = os.path.join(imgSave_path, image_name)
img = cv2.imread(imgPath)
[img_h, img_w, _] = img.shape
max_len = max(img_h, img_w)
print(image_name, max_len)
state = ""
rate = 0
if max_len == img_w:
state = "horizontal"
rate = img_w / img_h
else:
state = "vertical"
rate = img_h / img_w
if rate < 1.2:
for index in range(len(gt_range)):
if gt_range[index][0] <= max_len < gt_range[index][1]:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, gt_range[index][0], index+1, state, True)
ori_spec[index].append(gt_resized_name)
continue
# gt_resize函数的参数True为最长边resize,False为最短边resize,意在resize后的最短、最长边都不会超出格子的最短、最长边
if 1.2 <= rate <= 1.3:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, imgsize, 1, state, True)
ori_spec[0].append(gt_resized_name) # 1:1
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/3), 2, state, False)
if state == "horizontal":
ori[2].append(gt_resized_name) # 2:3
else:
ori[3].append(gt_resized_name) # 3:2
if 1.3 < rate < 1.7:
if rate <= 1.5:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/3), 1, state, False)
else:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/2), 1, state, True)
if state == "horizontal":
ori[2].append(gt_resized_name) # 2:3
else:
ori[3].append(gt_resized_name) # 3:2
if 1.7 <= rate <= 1.8:
gt_resized_name_1 = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/2), 1, state, True)
gt_resized_name_2 = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/2), 2, state, False)
if state == "horizontal":
ori[2].append(gt_resized_name_1) # 2:3
ori[0].append(gt_resized_name_2) # 1:2
else:
ori[3].append(gt_resized_name_1) # 3:2
ori[1].append(gt_resized_name_2) # 2:1
# if 1.8 < rate <= 2.2:
if 1.8 < rate:
if rate <= 2:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, int(imgsize/2), 1, state, False)
else:
gt_resized_name = gt_resize(gt_resized_path, txt_path, image_name, img, imgsize, 1, state, True)
if state == "horizontal":
ori[0].append(gt_resized_name) # 1:2
else:
ori[1].append(gt_resized_name) # 2:1
def gt_resize(gt_resized_path, txt_path, image_name, img, img_size, x, state, flag):
if not os.path.exists(gt_resized_path):
os.mkdir(gt_resized_path)
[img_h, img_w, _] = img.shape
img_read = [0, 0, 0]
if state == "horizontal":
if flag:
precent = img_size / img_w
img_read = cv2.resize(img, (img_size, int(img_h * precent)), interpolation=cv2.INTER_CUBIC)
else:
precent = img_size / img_h
img_read = cv2.resize(img, (int(img_w * precent), img_size), interpolation=cv2.INTER_CUBIC)
else:
if flag:
precent = img_size / img_h
img_read = cv2.resize(img, (int(img_w * precent), img_size), interpolation=cv2.INTER_CUBIC)
else:
precent = img_size / img_w
img_read = cv2.resize(img, (img_size, int(img_h * precent)), interpolation=cv2.INTER_CUBIC)
img_resized = gt_resized_path + "/" + image_name.split(".")[0] + "_" + str(x) + ".jpg"
cv2.imwrite(img_resized, img_read)
txt_name = txt_path + "/" + image_name.split(".")[0] + ".txt"
txt_resized_name = gt_resized_path + "/" + image_name.split(".")[0] + "_" + str(x) + ".txt"
if os.path.exists(txt_name):
data = ""
with codecs.open(txt_name, 'r', encoding='utf-8',errors='ignore') as f1:
for line in f1.readlines():
line = line.strip('\n')
a = line.split(' ')
a[2] = str(float(a[2]) * precent)
a[3] = str(float(a[3]) * precent)
a[4] = str(float(a[4]) * precent)
a[5] = str(float(a[5]) * precent)
b =a[0] + ' ' + a[1] + ' ' + a[2] + ' ' + a[3] + ' ' + a[4] + ' ' + a[5]
data += b + "\n"
with open(txt_resized_name, 'w', encoding='utf-8') as f2:
f2.writelines(data)
return img_resized.split("/")[-1]
if __name__ == "__main__":
images_path = '/data/cch/000test/images' # 图片集地址
json_path = "/data/cch/000test/json"
save_path = '/data/cch/pintu_data/test/workcloth/save1'
tmp = "/data/cch/000test/tmp"
#----------------------------------------------------------------
# imgSave_path = "/data/cch/pintu_data/test/workcloth/images"
# jsonSava_path = "/data/cch/pintu_data/test/workcloth/json"
# if not os.path.exists(imgSave_path):
# os.mkdir(imgSave_path)
# else:
# shutil.rmtree(imgSave_path)
# os.mkdir(imgSave_path)
# if not os.path.exists(jsonSava_path):
# os.mkdir(jsonSava_path)
# else:
# shutil.rmtree(jsonSava_path)
# os.mkdir(jsonSava_path)
# cut_bbox.main(images_path, json_path, imgSave_path, ["person"], 0) # person切图
# cuts = os.listdir(imgSave_path)
# for cut in cuts:
# if not os.path.splitext(cut)[-1] == ".json":
# continue
# json_f = os.path.join(imgSave_path, cut)
# shutil.move(json_f, jsonSava_path)
#----------------------------------------------------------------
if not os.path.exists(save_path):
os.mkdir(save_path)
else:
shutil.rmtree(save_path)
os.mkdir(save_path)
if not os.path.exists(tmp):
os.mkdir(tmp)
else:
shutil.rmtree(tmp)
os.mkdir(tmp)
bg_resized_path = os.path.join(tmp, "bg_resized")
gt_resized_path = os.path.join(tmp, "gt_resized")
txt_path = os.path.join(tmp, "txt") # 原数据txt
txt_pintu_path = os.path.join(tmp, "txt_pintu")
os.mkdir(txt_path)
os.mkdir(txt_pintu_path)
label_black = ["other"]
label_del = ["del"]
imgsize = 416
to_black_num = 15
to_black_min_num = 5
img_threshold = [1 / 2 * 1.2, 1 / 2 * 1.4, 1 / 6 * 1.3, 1 / 6 * 1.5] # 每个size的图拼阈值
img_threshold_spec = [0.3, 1 / 4 * 1.8, 1 / 9 * 1.7, 1 / 16 * 1.6]
gt_range = [[imgsize, 10000], [int(imgsize/2), 10000], [int(imgsize/3), imgsize], [int(imgsize/4), int(imgsize/2)]]
json2txt.main_import(jsonSava_path, txt_path)
ori = []
for i in range(4):
ori.append([]) # 存放顺序 1:2 2:1 2:3 3:2
ori_spec = []
for i in range(4):
ori_spec.append([]) # 存正方形小图
gt_distribute(imgSave_path, ori, ori_spec, gt_resized_path, txt_path, gt_range) # 不同size的小图放入对应容器中
idx = 1
for ori_m in ori_spec: # n×n拼图
if len(ori_m) == 0:
idx += 1
continue
img_threshold_spec[idx-1] *= len(ori_m)
if idx == 1 and img_threshold_spec[idx-1] > 80:
img_threshold_spec[idx-1] = 80
num = 0
random.shuffle(ori_m)
picknum = idx * idx
if len(ori_m) < picknum:
img_threshold_spec[idx-1] = 1
index = 0
while num < int(img_threshold_spec[idx-1]):
ori_tmp = []
if idx == 1:
new_name = image_compose(idx, [ori_m[num]], num, save_path, gt_resized_path,\
bg_resized_path, imgsize, idx, idx, imgsize/idx, imgsize/idx)
labels_merge([ori_m[num]], new_name, gt_resized_path, txt_pintu_path, idx,\
idx, imgsize/idx, imgsize/idx)
else:
if len(ori_m) > picknum:
if index >= len(ori_m):
random.shuffle(ori_m)
index = 0
ori_tmp = ori_m[index:index+picknum]
index = index + picknum
else:
ori_tmp = ori_m.copy()
new_name = image_compose(idx, ori_tmp, num, save_path, gt_resized_path, \
bg_resized_path, imgsize, idx, idx, imgsize/idx, imgsize/idx) #调用函数
labels_merge(ori_tmp, new_name, gt_resized_path, txt_pintu_path, idx,\
idx, imgsize/idx, imgsize/idx)
ori_tmp.clear()
num += 1
print(idx, num, len(ori_m))
idx += 1
idx = 1
for ori_n in ori: # 长方形拼图
if len(ori_n) == 0:
idx += 1
continue
# ori_path = os.path.join(save_path, "ori_" + str(idx) + ".txt")
img_threshold[idx-1] *= len(ori_n)
# if idx == 1 and img_threshold[idx-1] > 80:
# img_threshold[idx-1] = 80
num = 0
random.shuffle(ori_n)
picknum = 0
if idx == 1 or idx == 2: # 1×2或2×1 拼2张
picknum = 2
elif idx == 3 or idx == 4: # 2×3或3×2 拼6张
picknum = 6
if len(ori_n) < picknum:
img_threshold[idx-1] = 1
index = 0
while num < int(img_threshold[idx-1]):
ori_tmp = []
[yr, xr, xs, ys] = 1, 1, 0, 0 # x,y的图片张数 小图粘贴到大图的左上角起始坐标
# if idx == 1:
# new_name = image_compose(idx, [ori_n[num]], num, save_path, gt_resized_path, bg_resized_path, imgsize, yr, xr, xs, ys)
# labels_merge([ori_n[num]], new_name, gt_resized_path, txt_pintu_path, yr, xr, xs, ys)
# else:
if len(ori_n) > picknum:
# random.sample(ori_n, picknum)
if index >= len(ori_n):
random.shuffle(ori_n)
index = 0
ori_tmp = ori_n[index:index+picknum]
index = index + picknum
else:
ori_tmp = ori_n.copy()
if idx == 1:
[yr, xr, xs, ys] = 2, 1, imgsize, imgsize/2
elif idx == 2:
[yr, xr, xs, ys] = 1, 2, imgsize/2, imgsize
elif idx == 3:
[yr, xr, xs, ys] = 3, 2, imgsize/2, imgsize/3
elif idx == 4:
[yr, xr, xs, ys] = 2, 3, imgsize/3, imgsize/2
new_name = image_compose(idx, ori_tmp, num, save_path, gt_resized_path, bg_resized_path, imgsize, yr, xr, xs, ys) #调用函数
labels_merge(ori_tmp, new_name, gt_resized_path, txt_pintu_path, yr, xr, xs, ys)
ori_tmp.clear()
num += 1
print(idx, num, len(ori_n))
idx += 1
pintu2black(txt_pintu_path, save_path, label_black, label_del, to_black_num, to_black_min_num)
modeTxt.txt2darknet(txt_pintu_path, save_path, save_path)
shutil.rmtree(tmp)
- 这里的拼图同样也是带文件的拼图,相应的label也会随之改变。
- resize的函数相较于以前版本的加了个布尔类型的flag参数,用来判断是用最大边resize还是用最小边resize,意在不会使得最大边或者最小边都不超出格子。
比如:1.3 < rate < 1.7的图片是拼2×3的,还要再判断是否<=1.5。如果<=1.5,flag要为False即用最短边resize,因为假设格子的最长边为3最短边为2,如果此时用图片的最长边resize成3的话,最短边等比例缩放不管rate为1.3或无限接近1.5都会大于2。