一、前言
2019 年 4 月,在北京举行的智源学者计划启动暨联合实验室发布会上,北京旷视科技有限公司与北京智源人工智能研究院共同发布了全球最大的目标检测数据集 : Objects365。
该数据集总共包含63万张图像,覆盖365个类别,高达1000万框数,具有规模大、质量高、泛化能力强的特点,远超Pascal VOC、COCO等传统数据集。
关于Objects365的论文在两年一度的计算机视觉顶会 ICCV 2019 中发表,同时在不久前结束的谷歌目标检测赛 Open Images Challenge 2019 – Object Detection Track 中排名前三的队伍都使用了 Objects365 作为额外数据集并取得 mAP 平均提升 2 至 3 个百分点。
Objects365是一个广泛用于目标检测和场景理解的大规模图像数据集。该数据集旨在提供丰富的视觉场景和多样的目标类别,以促进计算机视觉研究和算法的发展。
以下是Objects365数据集的主要特点和介绍:
- 视觉场景多样性:Objects365数据集包含了丰富多样的视觉场景,涵盖了室内和室外、城市和乡村、自然和人工等多种不同环境。这使得研究者可以在更广泛的场景下进行目标检测和场景理解的研究。
- 目标类别丰富性:数据集中包含了超过365个不同的目标类别,涵盖了人类、动物、交通工具、家具、食物等广泛的物体类别。这使得研究者可以探索更多种类的目标检测问题,并进行更全面的场景理解研究。
- 大规模数据集:Objects365数据集包含了超过200万个标注的图像样本,以及每个样本中目标的位置和类别标签。这样的大规模数据集可以支持大规模训练和深度学习算法的发展。
- 多标签和多实例标注:每个图像样本在标注时可以包含多个目标实例,并且每个目标实例可以具有多个类别标签。这种多标签和多实例标注的方式更贴近真实世界的情况,并提供了更复杂的目标检测和场景理解任务。
- 挑战性和变化性:Objects365数据集中的图像具有不同的拍摄条件、视角、光照和遮挡等变化因素。这使得数据集更具挑战性,可以用于评估和比较不同算法在复杂场景下的性能表现。
Objects365数据集可以用于目标检测、目标跟踪、场景理解、图像分割等计算机视觉任务的研究和评估。它为研究者提供了一个全面且多样化的数据集,促进了计算机视觉算法在实际场景中的应用和发展。
二、数据集的规模
数据集包括人、衣物、居室、浴室、厨房、办公、电器、交通、食物、水果、蔬菜、动物、运动、乐器14个大类,平均每一类有大约26个小类。
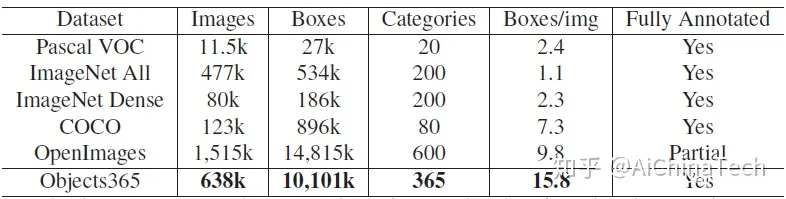
Objects365与其他数据集的比较:
如上图所示,比起COCO数据集,Objects365 具有 5 倍的图像数量、4 倍的类别数量、以及 10 倍以上标注框数量。
在数量上,唯一规模超过 Objects365 的 OpenImages 数据集具有标注精度不高及覆盖不全等明显缺点 (partially annotated),这对模型训练会带来严重影响。
比起 OpenImages,Objects365 具有每张图中所有物体都被标注的优势,这在 Boxes / img这列 (15.8 vs. 9.8) 得到体现:在类别数少 (365 vs. 500) 的情况下达到平均每张图包含 1.6 倍的标注框。
三、数据集的质量
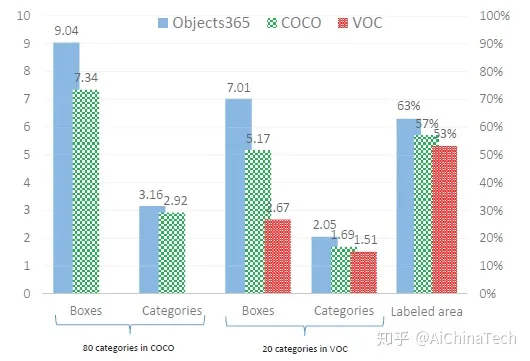
如图所示,即便只考虑 Objects365 在 COCO 和 VOC 数据集中的 80 类和 20 类,在每张图像平均框数和类别数这两项指标上,Objects365 依然优于 COCO 和 VOC。
标注过程中减少了漏标,平均标注区域占比也超过 COCO 和 VOC。


物都有精准的标注框。
四、泛化能力
比起上述两项,鉴定一个数据集质量很重要的一项指标便是其泛化能力。
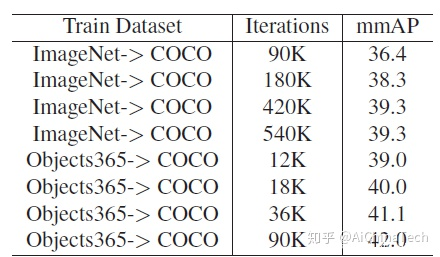
预训练数据集与 ImageNet 的比较
如图所示,比起传统预训练数据集 ImageNet,使用 Objects365 预训练可达到在训练时间缩短至六分之一 (90K 次迭代 vs. 540K 次迭代) 的情况下 mMAP 提升 2.7 个百分点(检测模型使用ResNet50 + FPN 作为 Backbone 的 Faster RCNN)。
另外,在其他计算机视觉任务,如行人检测、语义/场景分割等,中使用 Objects365 作为预训练数据集都可达到速度与精度的明显提升,详情可参照论文。
五、结语
随着近年来计算机视觉技术的飞速发展,算法对数据的要求也越来越高。不论是目标检测或语义分割等传统任务,又或是目标关系等新推出或还未推出的新任务,现有的数据集显然不能满足需求。
相对于算法,优质数据集往往能对模型效果带来更大的提升,无论是数据规模又或是标注质量,Objects365 都为计算机视觉技术树立了新的里程碑。