深度学习的目标检测算法,通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整(回归)区域边界,从而更准确地预测目标的真实边界框(ground-truth bounding box)。
目标检测算法会需要做两个事情:
- 推荐区域框是否有目标
(positive or negative),是分类任务; - 调整这些区域框,不断逼近到目标真实框,是回归任务。
就针对目标检测算法的传统区域框推荐和深度学习的方法,问了chatGPT,他给出了下面的回答。给与我们借鉴,帮助我们理解。

传统的目标框推选方法,我们暂时就先不考虑。针对基于anchor的方法,我们通过最常用的anchor based(anchor box)和anchor free,和no anchor来展开。
一、什么是Anchor
anchor也叫做锚,预先设置目标可能存在的大概位置,然后再在这些预设边框的基础上进行精细化的调整。而它的本质就是为了解决标签分配的问题。
anchor是如何生成的?锚作为一系列先验框信息,其生成涉及以下几个部分:
- 用网络提取特征图的点来定位边框的位置;
- 用锚的尺寸来设定边框的大小;
- 用锚的长宽比来设定边框的形状。
引入anchor的目的:
通过设置不同尺度,不同大小的先验框,就有更高的概率出现对于目标物体有良好匹配度的先验框约束,在锚框的约束下使模型的精准度和召回率都有了质的提升。
anchor_basedanchor_box_24">一、anchor based(anchor box)
anchor box中,anchor位于所讨论的滑动窗口的中心,用与之关联的scale和aspect ratio,默认是3 scales和3 aspect ratio,于是对于每个sliding window有k=9个anchors。于是对于一个w x h的卷积特征图,共有w x h x 9个anchor,(faster rcnn大约2400个)
在 Faster R-CNN 中,为了回归出检测框的位置,首先通过 RPN 网络产生一组候选框,其中每个候选框是由一个先验框(anchor box)和一个偏移量(offset)相加得到的。而这个偏移量就是通过回归网络对先验框进行预测得到的。最终的检测框则是由先验框加上这个偏移量得到的。
在训练阶段,我们需要通过优化网络参数来让偏移量的预测结果更接近于真实的目标框。因此,我们需要一个损失函数来度量预测框与真实框之间的差距。而这个损失函数通常会包含两个部分,即分类损失和回归损失。
对于回归损失部分,可以使用 L1 损失函数、 L2 损失函数,或smooth L1 loss。而为了使回归损失更准确,通常会将偏移量的计算方式转换为相对于先验框的坐标差异。具体来说:

- 通过对预测框
pd的坐标与先验框anchor的坐标进行差分,得到一个预测框相对于先验框的偏移量。 - 通过对标注框
gt的坐标与先验框anchor的坐标进行差分,即真实框相对于先验框的坐标差异(偏移量)。 - 最终,回归网络会学习将先验框
anchor的位置和尺度,调整到更接近真实框anchor的位置和尺度。
因此,对于每个候选框,我们需要计算其预测框与真实框之间的偏移量,而这个偏移量是相对于先验框的坐标差异。因此,我们需要先对预测框和真实框的坐标分别与对应的先验框坐标进行差分,然后再将它们之间的差异作为回归的目标。
为什么要学习偏移量而不是实际值?(Why are offsets learned instead of actual values?)
这个做法可以让回归目标更加准确,并且可以使训练更稳定。如果直接对预测框和真实框之间的(x,y,w,h)坐标做回归,则容易受到不同大小、不同长宽比的目标框的影响,导致回归不稳定。
anchor box的缺点(CornerNet论文指出):
- 需要许多的
anchor boxes:这是因为检测器被训练来分类每个锚盒是否与一个地面真值盒充分重叠,并且需要大量的锚盒来确保与大多数地面真值盒充分重叠。
2.anchor boxes的使用引入了许多超参数和设计选择。include how many boxes, what sizes, and what aspect ratios.这样的选择在很大程度上是通过特别的启发式做出的,当与多尺度体系结构结合使用时,可能会变得更加复杂
anchor box的缺点(Feature Selective Anchor-Free Module for Single-Shot Object Detection):
heuristic-guided feature selection:即 Anchor Box 依赖先验的设定,需要手动选择 Anchor Box 的大小和长宽比,并且这些选择通常是根据经验和启发式规则来进行的,因此可能会导致不同目标的 Anchor Box 不够准确或者不够匹配。overlap-based anchor sampling:anchor box通常需要对预测框与真实框之间的重叠程度进行计算,并根据重叠程度的大小来选择和训练正负样本。具体来说,如果预测框与某个真实框的重叠程度大于某个阈值,那么就认为这个预测框是一个正样本,否则是负样本。而在选择正负样本时,通常会选择与真实框重叠程度最大的 Anchor Box 作为正样本,并且对其它与真实框重叠程度较大的 Anchor Box 进行负样本训练。
然而,这种重叠程度的计算和样本的选择可能会导致一些问题。例如在目标比较密集的场景中,多个 Anchor Box 可能会同时对同一个目标进行检测,并且重叠部分可能会被不同的 Anchor Box 所计算。此时,就可能会出现样本之间的重复和冲突,导致训练过程不稳定或者产生错误的样本选择。
anchor_free_56">二、anchor free
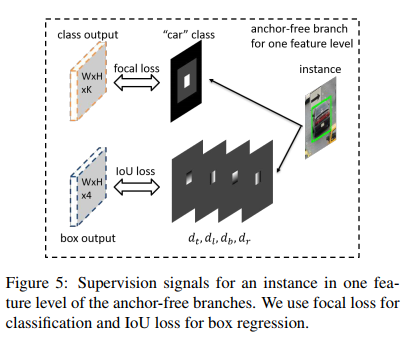
在论文:Feature Selective Anchor-Free Module for Single-Shot Object Detection 中,引入了anchor free的思想。他的提出主要是为了解决anchor based的两个不足的。
- anchor based需要预设anchor的大小,尽管kmean采用聚类的方式提高了anchor大小的科学性,但是他依旧对于每个实例来说,不是最优的。anchor free直接没有了预设宽高信息,采用学习的方式,预测宽高。
- anchor free和FPN特征金字塔结合,动态地将每个目标实例分配到最合适的特性级别。大型锚框通常与上部特征图相关联,而小型锚框则与下部特征图相关联,这是基于这样的假设:更高维的特征图具有更适合检测大目标的语义信息,而更低维的特征图具有更适合检测小目标的细粒度细节。
在inference阶段,对于一个中心点pixel的坐标(i,j)预测的bounding box,需要预测相较于中心点的偏移量 top, left, bottom, and right boundaries of predict bounding box ,最后和坐标(i,j)计算得到最终bounding box的坐标。
在train阶段,采用IOU loss,计算方式为先根据网络输出的预测偏移量和中心点,计算得到预测的bounding box的坐标,然后与ground truth的bounding box的坐标进行IOU计算,用1减去IOU的值作为损失函数进行模型的优化。
优点:
- 泛化能力强:无需人工预设宽高,全靠预测,因此可以更好地适应各种目标尺寸和形状,从而具有更好的通用性。
- 去除anchor尺寸选择:由于anchor-free方法在目标定位过程中直接预测目标中心点和边界框的偏移量,因此可以减少由于anchor box选择不当而导致的误差。
- anchor-free方法在生成检测结果时需要对特征图上的每个像素点进行处理,因此可以更好地捕获目标的细节信息,从而具有更好的检测精度和定位精度。
缺点:
- 不适合于通用目标检测,容易受到目标形状、姿态等因素的影响。但是FPN的结合,能够弥补这个问题。
anchor_77">三、no anchor
no anchor就是不再采用anchor的方式进行Bbox提议,具有代表形状的就是DETR。
在DETR中,将anchor提议proposal的任务,交给了可学习的object queries(100个)。通过可视化object queries可以发现,不同的query询问的关键位置是不同的,类似于anchor box的目标大小和尺寸有些像。
经过这个过程后,transformer提议的100个256,就可以经过ffn(feed forward network),预测出100个类别和box。它相比于anchor based更加的灵活,更少的人工参与,都交由模型自己学习。
这块内容,也常常被称作NMS Free,因为DETR直接对候选框进行预测,得到的都是需要的目标,无需NMS操作。
四、总结
anchor box的宽高信息是设定已知的,通过kmean等方式聚类得到;anchor free的宽高信息是预测出来的,不需要提前预设;anchor box和anchor free在bounding box预测阶段,都是将预测坐标问题转化为预测与gt的offset,再进一步得到预测的坐标;但是一个是相较于anchor的,一个是相较于中心点pixel的。anchor box和anchor free在网络结构设计上也有一些差异。Anchor box需要预定义anchor的大小和比例,然后在每个anchor上预测物体类别和位置偏移量,因此需要使用多个不同尺度和比例的特征图来检测不同大小和形状的物体;而Anchor free则直接在每个像素点上进行物体类别和位置偏移量的预测,因此只需要使用单一尺度的特征图即可。这使得Anchor free具有更简单的网络结构和更少的计算量。anchor free相较于anchor box更灵活。Anchor box的anchor是固定的,如果目标形状和大小与anchor不匹配,可能会导致预测不准确,泛化性低,需要使用更多的anchor来覆盖所有情况。而Anchor free则可以根据目标的实际形状和大小进行预测,更加灵活和精准。
针对上面的内容,希望带着怀疑的目光来看,很多也是自己的理解。如果发现什么疑问,或错误的地方,欢迎评论区指出。一起进步
更多内容,建议参考这里: