大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用4-目标检测任务,利用Faster Rcnn+Resnet50+FPN模型对目标进行预测,目标检测是计算机视觉三大任务中应用较为广泛的,Faster R-CNN 是一个著名的目标检测网络,其主要分为两个模块:Region Proposal Network (RPN) 和 Fast R-CNN。我将会详细介绍使用 ResNet50 作为基础网络并集成 FPN(Feature Pyramid Network)的 FasterRCNN 模型。这个模型可以写为 fasterrcnn_resnet50_fpn。
今天我来实现一下这个功能,每个人都可以操作,代码直接运行。
一、模型结构
1.ResNet50:ResNet是一个深度卷积神经网络,它利用残差块解决了训练过程中的梯度消失问题。ResNet50表示具有50层深度的ResNet模型。这个模型负责从原始图像提取特征。
2.FPN:FPN是一种特征处理架构,它生成多尺度的特征图来处理目标检测中不同大小的物体。FPN在卷积神经网络后面添加额外层来融合不同分辨率的特征,这有助于提高物体检测的准确性。
3.RPN:这是一个小型卷积网络,它在FPN生成的多尺度特征图上运行。RPN的主要目的是为下游的 Fast R-CNN 生成目标的候选框(Region of Interest,简称 RoI)。这是目标检测任务的第一阶段,RPN利用滑动窗口生成多个候选框,它会在不同尺度和纵横比的锚点上生成边界框。
4.Fast R-CNN:该模块接收 RPN 生成的候选框,利用 RoI Align,从不同尺度的特征金字塔图上提取特征,然后使用全连接层进行分类和边框回归。Fast R-CNN 输出检测到的目标类别及其边框位置。
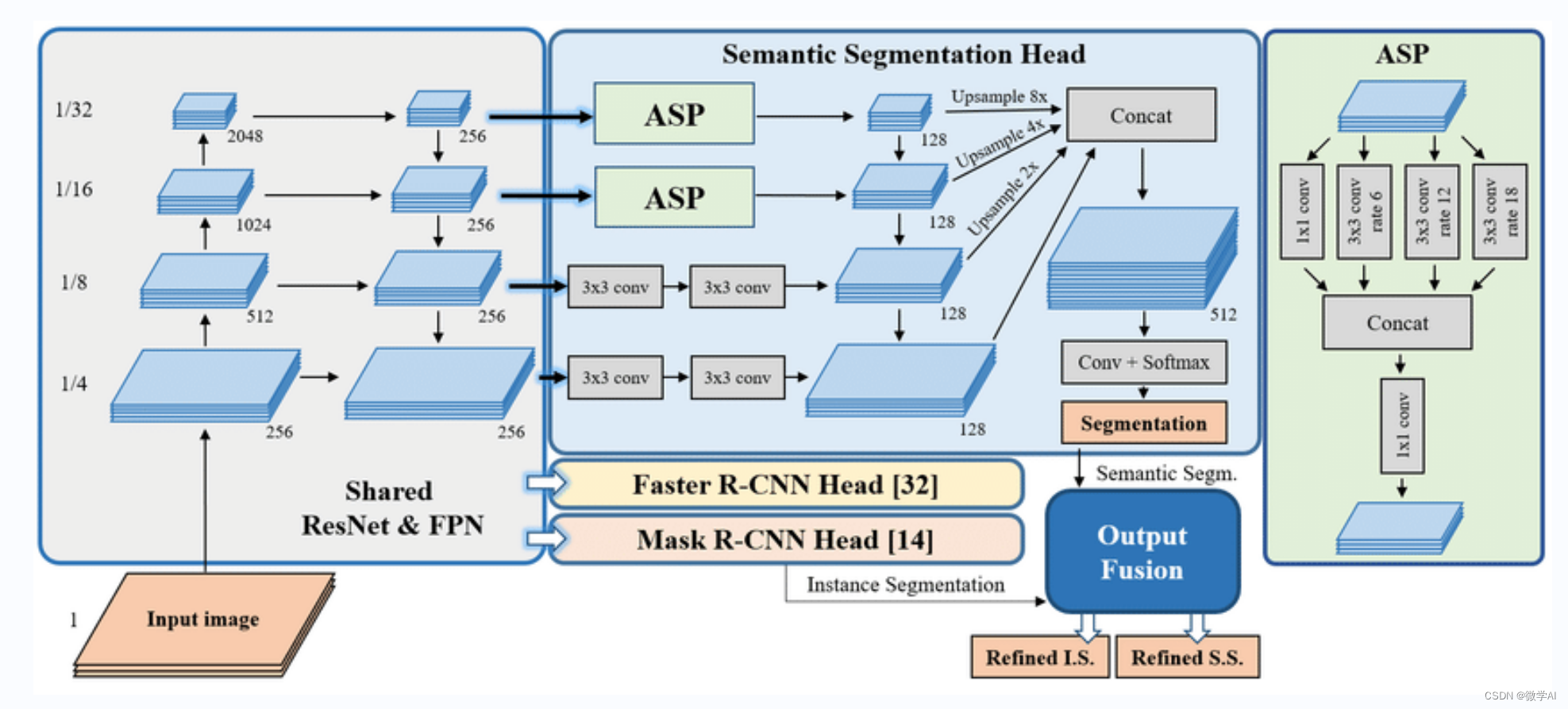
二、模型原理
目标检测过程:特征提取(ResNet50)-> FPN -> RPN -> RoI -> Fast R-CNN。首先,ResNet50 提取原始图像的特征并将这些特征传递给 FPN。接着,FPN生成了多尺度的特征图以适应不同大小的物体。然后,RPN 在由特征金字塔生成的多尺度特征图上运行,生成一系列候选框。RPN的输出会作为 Fast R-CNN 的输入,利用RoI对候选框提取特征后,对结果进行分类和边框回归。
举例说明:
假设我们想将该模型用于自动驾驶场景,检测出行人、汽车和交通信号等。当我们用摄像头获取一帧图像时,首先将这个图像输入到 ResNet50,它会提取出有用的特征供后续进行目标检测。随后,FPN会生成不同尺度的特征图,从而提高对不同大小目标的检测能力。接下来,RPN从这些特征图中生成区域建议(候选框)。这些候选框包含了可能是我们关心物体的区域(行人、汽车等)。最后,Fast R-CNN 利用 RoI 从不同尺度特征图中提取候选框的特征,经过全连接层的处理后,对候选框进行分类和边框回归,最终输出检测结果。在自动驾驶场景下,该模型可以通过分析摄像头捕捉到的图像,快速准确地检测出行人、汽车、交通信号和其他障碍物等,从而帮助车辆做出正确的决策。
三、代码实现
import torchvision
from PIL import Image, ImageDraw, ImageFont
from coco_class import class_names
# 加载COCO数据集预训练模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# 设置模型为评估模式
model.eval()
# 加载图像并进行预处理
image = Image.open('banana.png')
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
image_tensor = transform(image)
image_tensor = image_tensor[:3]
# 利用模型进行预测
predictions = model([image_tensor])
# 处理预测结果并输出
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("arial.ttf", 30) # 设置字体大小和样式
for box, label, score in zip(predictions[0]['boxes'], predictions[0]['labels'], predictions[0]['scores']):
if score > 0.5:
draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline='red')
label_name = class_names[label.item()]
draw.text((box[0], box[1]), str(label_name), fill='red', font=font) # 在图片上打印分类名称
image.show()其中coco_class.py文件是加载coco数据集中的类别:
class_names = {
0: 'background',
1: 'person',
2: 'bicycle',
3: 'car',
4: 'motorcycle',
5: 'airplane',
6: 'bus',
7: 'train',
8: 'truck',
9: 'boat',
10: 'traffic light',
11: 'fire hydrant',
12: 'N/A',
13: 'stop sign',
14: 'parking meter',
15: 'bench',
16: 'bird',
17: 'cat',
18: 'dog',
19: 'horse',
20: 'sheep',
21: 'cow',
22: 'elephant',
23: 'bear',
24: 'zebra',
25: 'giraffe',
26: 'N/A',
27: 'backpack',
28: 'umbrella',
29: 'N/A',
30: 'N/A',
31: 'handbag',
32: 'tie',
33: 'suitcase',
34: 'frisbee',
35: 'skis',
36: 'snowboard',
37: 'sports ball',
38: 'kite',
39: 'baseball bat',
40: 'baseball glove',
41: 'skateboard',
42: 'surfboard',
43: 'tennis racket',
44: 'bottle',
45: 'N/A',
46: 'wine glass',
47: 'cup',
48: 'fork',
49: 'knife',
50: 'spoon',
51: 'bowl',
52: 'banana',
53: 'apple',
54: 'sandwich',
55: 'orange',
56: 'broccoli',
57: 'carrot',
58: 'hot dog',
59: 'pizza',
60: 'donut',
61: 'cake',
62: 'chair',
63: 'couch',
64: 'potted plant',
65: 'bed',
66: 'N/A',
67: 'dining table',
68: 'N/A',
69: 'N/A',
70: 'toilet',
71: 'N/A',
72: 'tv',
73: 'laptop',
74: 'mouse',
75: 'remote',
76: 'keyboard',
77: 'cell phone',
78: 'microwave',
79: 'oven',
80: 'toaster',
81: 'sink',
82: 'refrigerator',
83: 'N/A',
84: 'book',
85: 'clock',
86: 'vase',
87: 'scissors',
88: 'teddy bear',
89: 'hair drier',
90: 'toothbrush'
}运行结果:




这里可以识别目标的位置信息和类别信息,后续还要针对视频的进行识别分类。