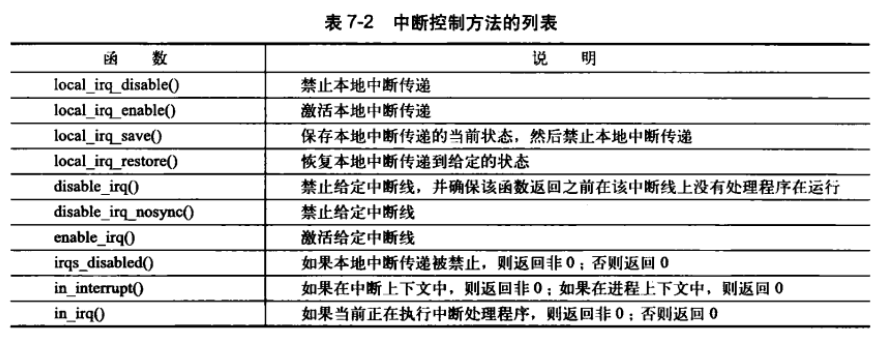
文章来自于:曲終人不散丶@知乎,
连接:https://zhuanlan.zhihu.com/p/157900024, 本文仅用于学术分享,如有侵权,前联系后台做删文处理。

在笔者上一篇文章《一文打尽目标检测NMS——精度提升篇》中,总结了近几年出现的一些可以提升NMS精度的方法。可以看到,NMS由于顺序处理的原因,运算效率较为低下。在笔者的实际项目中,NMS往往能占模型计算总时间的40%甚至更多,极大影响了模型的效率。经过笔者一段时间的调研,关于提升NMS运算速度的方法,在这里也将结合代码进行阶段性总结。
所参考的代码库列举如下:
-
- Faster RCNN pytorch (rbg大神) 的
CUDA NMShttps://github.com/rbgirshick/py-faster-rcnn
- Faster RCNN pytorch (rbg大神) 的
-
- YOLACT团队提出的
Fast NMShttps://github.com/dbolya/yolact
- YOLACT团队提出的
-
- CIoU团队提出的
Cluster NMShttps://github.com/Zzh-tju/CIoU
- CIoU团队提出的
-
- SOLOv2团队提出的
Matrix NMShttps://github.com/WXinlong/SOLO
- SOLOv2团队提出的
-
- Torchvision封装的免编译
CUDA NMS
- Torchvision封装的免编译

得益于GPU的并行计算,我们可以一次性得到IoU的全部计算结果。这一步就已经极大地解决了IoU计算繁琐又耗时的问题。代码如下:
def box_iou(boxes1, boxes2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
boxes1 (Tensor[N, 4])
boxes2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(boxes1.t())
area2 = box_area(boxes2.t())
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # [N,M,2]
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # [N,M,2]
inter = (rb - lt).clamp(min=0).prod(2) # [N,M]
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
到这里为止,以上列出的5种NMS都可以做到,从速度上来说CUDA NMS和torchvision NMS相对底层,编译后使用,速度稍快,但必然损失了一些灵活度,后面会讲。(关于CUDA NMS的教程,有兴趣的小伙伴可以参考faster-rcnn源码阅读:nms的CUDA编程,非常详实。
在有了IoU矩阵之后,接下来就是应该要如何利用它来抑制冗余框。
IoU矩阵的妙用
以下列举的三篇文献,可谓是将IoU矩阵玩出了花,从不同的角度发扬光大,在NMS加速方面也确实走在正轨上。(所用的一些符号,笔者进行了统一)
Fast NMS
Fast NMS是《YOLACT: Real-time Instance Segmentation》一文的其中一个创新点。由于IoU的对称性,即
I
o
U
(
B
i
,
B
j
)
=
I
o
U
(
B
j
,
B
i
)
IoU(B_i,B_j) = IoU(B_j,B_i)
IoU(Bi,Bj)=IoU(Bj,Bi),看出
X
X
X是一个对称矩阵。再加上一个框自己与自己算IoU也是无意义的,因此Fast NMS首先对
X
X
X使用pytorch的triu函数进行上三角化,得到了一个对角线元素及下三角元素都为0的IoU矩阵
X
X
X



代码如下:
def fast_nms(self, boxes, scores, NMS_threshold:float=0.5):
'''
Arguments:
boxes (Tensor[N, 4])
scores (Tensor[N, 1])
Returns:
Fast NMS results
'''
scores, idx = scores.sort(1, descending=True)
boxes = boxes[idx] # 对框按得分降序排列
iou = box_iou(boxes, boxes) # IoU矩阵
iou.triu_(diagonal=1) # 上三角化
keep = iou.max(dim=0)[0] < NMS_threshold # 列最大值向量,二值化
return boxes[keep], scores[keep]

优点:
- 1.速度比cython编译加速的Traditional NMS快。(上表截自https://github.com/Zzh-tju/CIoU)
- 可支持与其他提升精度的NMS方法结合。
缺点:
-
Fast NMS会比Traditional NMS抑制更多的框,性能略微下降。 -
比CUDA NMS慢,约0.2ms。
-
.这里有必要解释一下,
为什么Fast NMS会抑制更多的框?我们知道NMS的思想是:当一个框是冗余框,被抑制后,将不会对其他框产生任何影响。但在Fast NMS中,如果一个框 B i B_i Bi 的得分比 B j B_j Bj 高且 B i B_i Bi被抑制了,矩阵 X X X的第 i i i 行正是 B i B_i Bi 与得分低于它的所有框的IoU, 如果 x i j x_{ij} xij这个元素≥NMS阈值的话,那么在取列最大值这个操作时, b b b的第 j j j个元素必然≥NMS阈值,于是很不幸地 B j B_j Bj就被抑制掉了。
也就是在刚刚的例子中,由于第二个框 B 2 B_2 B2 被抑制,那么第二行第四列的0.72就不应该存在,可是Fast NMS允许冗余框去抑制其他框,导致了第四个框 B 4 B4 B4 被错误地抑制了。

不过呢,YOLACT主要针对的是实例分割,mask是从box中裁剪出来的,Fast NMS对mask AP的下降比较轻微,约0.1~0.3的AP,但似乎对目标检测的box AP会下降更多。
Cluster NMS
Cluster NMS出自《Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation》一文。研究者主要旨在弥补Fast NMS的性能下降,期望也利用pytorch的GPU矩阵运算进行NMS,但同时又使得性能保持与Traditional NMS相同。
最开始看到这个名字时,笔者还以为是采取聚类的NMS,这不禁让人想起了今年2月的FeatureNMS。但后来仔细看了过后,发现这里的cluster的含义不一样。

以上是论文的原话,意思是说,cluster是一个框集合,若某一个框A属于这个cluster,则必有cluster中的框与A的IoU≥NMS阈值,且A不会与除这个cluster之外的框有IoU≥NMS阈值。举个简单的例子:

上图中的黑红蓝橙四个框构成一个cluster,而绿色的两个框构成一个cluster,虽然两个cluster之间有相交,但都没有超过NMS阈值,于是这两个框集合不能合并成一个cluster。
然后我们看一下Cluster NMS是怎么做的?
其实就是一个迭代式的Fast NMS。前面的过程与Fast NMS一模一样,都是 B B B按得分降序排列,计算IoU矩阵,上三角化。然后按列取最大值,经过NMS阈值二值化得到一维张量 b b b。但不同于Fast NMS直接输出了 b b b,Cluster NMS而是利用 b b b ,将它展开成一个对角矩阵 E E E 。也就是这个对角矩阵 E E E的对角线元素与 b b b 相同。然后用 E E E 去左乘IoU矩阵 X X X,。然后再按列取最大值,NMS阈值二值化得到一个新的一维张量 b b b,再展开成一个新的对角矩阵 E E E,继续左乘IoU矩阵 X X X。直到出现某两次迭代后, b b b 保持不变了,那么谁该保留谁该抑制也就确定了。
这里借用一下作者在github的流程图。

以笔者的角度看,这种利用矩阵左乘的方式,其实就是在省略上一次Fast NMS迭代中被抑制的框对其他框的影响。
因为我们知道一个对角矩阵左乘一个矩阵,就是在做行变换啊,对应行是1,乘完的结果这一行保持不变,如果对应行是0,乘完的结果就是把这一行全部变成0。而
b
b
b中某个元素若是0,就代表这个位置是冗余框,于是乘完之后,这个冗余框在下一次的迭代中就不再对其他框产生影响。为什么这里要强调下一次迭代?是因为这个迭代过程
b
b
b会不断发生变动!可能某个框这会儿是冗余框,到了下一次迭代又变成了保留框。但是但是!到了最终 (其实未必是迭代满n次),
b
b
b 就保持不变了!你说奇怪不?这里论文还给出了一个命题,说Cluster NMS的输出结果与Traditional NMS的结果一模一样。
论文里还给出了对这个命题的证明,又是数学数学数学!大致一看是利用数学归纳法证的,感兴趣的可以去看论文,这里请允许我跳过。
def cluster_nms(self, boxes, scores, NMS_threshold:float=0.5):
'''
Arguments:
boxes (Tensor[N, 4])
scores (Tensor[N, 1])
Returns:
Fast NMS results
'''
scores, idx = scores.sort(1, descending=True)
boxes = boxes[idx] # 对框按得分降序排列
iou = box_iou(boxes, boxes).triu_(diagonal=1) # IoU矩阵,上三角化
C = iou
for i in range(200):
A=C
maxA = A.max(dim=0)[0] # 列最大值向量
E = (maxA < NMS_threshold).float().unsqueeze(1).expand_as(A) # 对角矩阵E的替代
C = iou.mul(E) # 按元素相乘
if A.equal(C)==True: # 终止条件
break
keep = maxA < NMS_threshold # 列最大值向量,二值化
return boxes[keep], scores[keep]
好了,至此Cluster NMS算是完成了对Fast NMS性能下降的弥补。我们直接看结果好了

嗯,效果还是可以的,保持了AP与AR一样,运算效率比Fast NMS下降了一些,毕竟是迭代Fast NMS的操作,但也比Traditional NMS快多了。
以为这样就完了?接下来才是重头戏!
这里又分为两个部分,一个是实用上的,另一个是理论上的。先说一下实用上的。
之前说过基于pytorch的NMS方法灵活度要比CUDA NMS更高,就在于这些基于pytorch的NMS是高层语言编写,专为研究人员开发,矩阵运算清晰简洁,于是乎可以很方便地与一些能够提升精度的NMS方法结合!正所谓强强联合,于是就诞生出了又快又好的一系列Cluster NMS的变体。
论文里主要举了三种变体:
(1) 得分惩罚机制SPM(Score Penalty Mechanism)


def SPM_cluster_nms(self, boxes, scores, NMS_threshold:float=0.5):
'''
Arguments:
boxes (Tensor[N, 4])
scores (Tensor[N, 1])
Returns:
Fast NMS results
'''
scores, idx = scores.sort(1, descending=True)
boxes = boxes[idx] # 对框按得分降序排列
iou = box_iou(boxes, boxes).triu_(diagonal=1) # IoU矩阵,上三角化
C = iou
for i in range(200):
A=C
maxA = A.max(dim=0)[0] # 列最大值向量
E = (maxA < NMS_threshold).float().unsqueeze(1).expand_as(A) # 对角矩阵E的替代
C = iou.mul(E) # 按元素相乘
if A.equal(C)==True: # 终止条件
break
scores = torch.prod(torch.exp(-C**2/0.2),0)*scores #惩罚得分
keep = scores > 0.01 #得分阈值筛选
return boxes[keep], scores[keep]
(2). +中心点距离
说到底DIoU就是该团队提出来的,那怎能不用上中心点距离呢?于是论文在两个方面添加了中心点距离。一个是IoU矩阵直接变成DIoU矩阵,由于DIoU也是满足尺度不变性的,所以完全没问题,相距很远的框之间的DIoU会变成负数,不过不影响过程。第二个是基于上面的SPM,公式如下:


加了这两个变体之后,AP与AR得到了明显的改善,速度也是略微下降,很香
(3) 加权平均法Weighted NMS

def Weighted_cluster_nms(self, boxes, scores, NMS_threshold:float=0.5):
'''
Arguments:
boxes (Tensor[N, 4])
scores (Tensor[N, 1])
Returns:
Fast NMS results
'''
scores, idx = scores.sort(1, descending=True)
boxes = boxes[idx] # 对框按得分降序排列
iou = box_iou(boxes, boxes).triu_(diagonal=1) # IoU矩阵,上三角化
C = iou
for i in range(200):
A=C
maxA = A.max(dim=0)[0] # 列最大值向量
E = (maxA < NMS_threshold).float().unsqueeze(1).expand_as(A) # 对角矩阵E的替代
C = iou.mul(E) # 按元素相乘
if A.equal(C)==True: # 终止条件
break
keep = maxA < NMS_threshold # 列最大值向量,二值化
weights = (C*(C>NMS_threshold).float() + torch.eye(n).cuda()) * (scores.reshape((1,n)))
xx1 = boxes[:,0].expand(n,n)
yy1 = boxes[:,1].expand(n,n)
xx2 = boxes[:,2].expand(n,n)
yy2 = boxes[:,3].expand(n,n)
weightsum=weights.sum(dim=1) # 坐标加权平均
xx1 = (xx1*weights).sum(dim=1)/(weightsum)
yy1 = (yy1*weights).sum(dim=1)/(weightsum)
xx2 = (xx2*weights).sum(dim=1)/(weightsum)
yy2 = (yy2*weights).sum(dim=1)/(weightsum)
boxes = torch.stack([xx1, yy1, xx2, yy2], 1)
return boxes[keep], scores[keep]
接下来说一下Cluster NMS理论上的好处。
Cluster NMS的迭代次数通常少于Traditional NMS的迭代次数。
这一优点,从理论上给了它使用CUDA编程更进一步加速的可能。大致意思是说,平常我们在做NMS时,迭代都是顺序处理每一个cluster的。在Traditional NMS中,虽然不同的cluster之间本应毫无关系,但计算IoU重复计算了属于不同cluster之间的框,顺序迭代抑制的迭代次数也仍然保持不变。
但在Cluster NMS中,使用这种行变换的方式,就可以将本应在所有cluster上迭代,化简为只需在一个拥有框数量最多的cluster上迭代就够了(妙啊)。不同的cluster间享有相同的矩阵操作,且它们互不影响。这导致迭代次数最多不超过一张图中最大cluster所拥有的框的个数。也就是下面这种情形

上图中共有10个检测框,分成了3个cluster,它的IoU矩阵(被NMS阈值二值化了)在右边。Cluster NMS做迭代的次数最多不超过4次,因为上图中框数量最多的那个cluster(红色)一共只有4个框。而实际上这张图使用Cluster NMS,只需迭代2轮便结束了。
因此这带来的好处是时间复杂度的下降。特别是对于一张图中有很多个cluster时,效果更为显著。比如这种情形,密密麻麻的狗狗



Matrix NMS
Matrix NMS出自《SOLOv2: Dynamic, Faster and Stronger》,也是利用排序过后的上三角化的IoU矩阵。不同在于它针对的是mask IoU。我们知道mask IoU的计算会比box IoU计算更耗时一些,特别是在Traditional NMS中,会加剧运算开销。因此Matrix NMS将mask IoU并行化是它最大的一个贡献。然后论文同样采取了得分惩罚机制来抑制冗余mask。具体代码如下:



优点:
-
实现了mask IoU的并行计算,对于box-free的密集预测实例分割模型很有使用价值。
-
与Fast NMS一样,只需一次迭代。
缺点: -
与Fast NMS一样,直接从上三角IoU矩阵出发,可能造成过多抑制。
总结:
-
- CUDA NMS与Torchvision NMS稍快于以上三种基于pytorch实现的NMS,但比较死板,改动不易。
-
- Cluster NMS基本可以取代Fast NMS,且与其他提升精度的方法的有机结合,使它又快又好。(目前作者团队的代码库只提供了得分惩罚法,+中心点距离,加权平均法三种。)
-
- Matrix NMS也可以参考Cluster NMS的方式先得到一个与Traditional NMS一样的结果后,再进行后续处理。
-
- 三种基于pytorch的NMS方法,只依赖于矩阵操作,无需编译。
-
- 将2D检测的NMS加速方法推广至3D检测,应该也是很有价值的。
参考文献
- YOLACT: Real-time Instance Segmentation. ICCV 2019
- Enhancing Geometric Factors in Model Learning and Inference for Object
Detection and Instance Segmentation. Arxiv 2020.05 - SOLOv2: Dynamic, Faster and Stronger. Arxiv 2020.03