来源:深度之眼 作者:比赛教研部
编辑:学姐
Kaggle OTTO – Multi-Objective Recommender System多目标推荐系统大赛
赛题分析+baseline
1、赛题链接
https://www.kaggle.com/competitions/otto-recommender-system/overview
2、赛题描述
本次比赛的目标是预测电子商务点击、购物车添加和订单。
根据用户的行为记录来预测用户各种行为下次发生交互的商品,这是一个经典的多目标推荐问题。本次比赛的目标是预测电子商务的点击量、购物车的添加量和订单。你将根据用户Session序列中的行为记录来进行推荐。
3、评价指标
这里我们需要对用户的点击,加购,购买行为进行Top-K推荐,我们需要对每一个User的Session序列给出预测的Top-20的Item结果,其评估指标使用Recall进行评估:
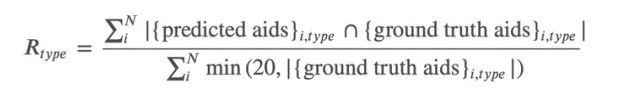
这里我们需要分别对这三种行为分别进行Recall指标计算,最后将三个行为的Recall值进行加权求和,其权值如下:
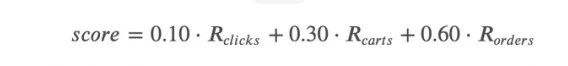
4、数据介绍
我们将数据完全读入,可以看到数据的组织形式如下:
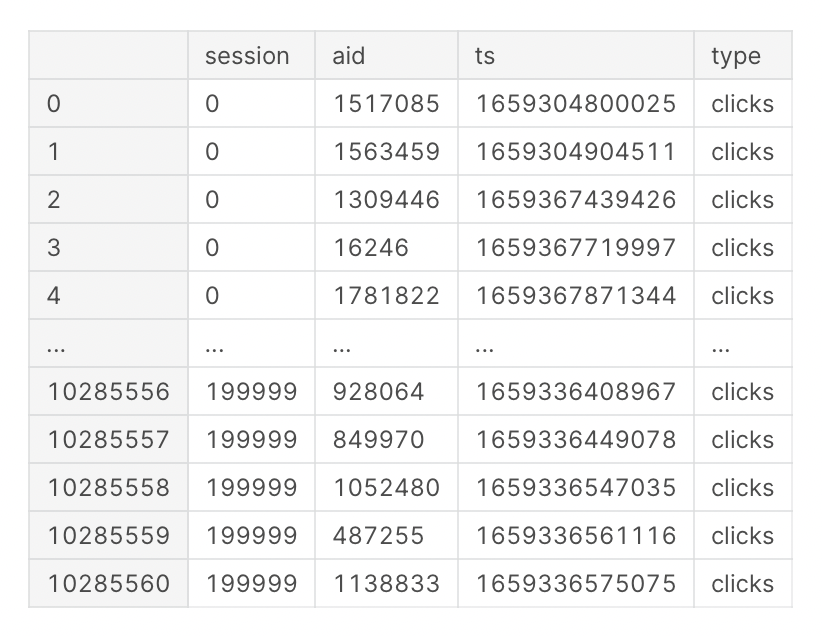
可以看到数据的组织形式十分的简练,但是在训练集里面一共有2亿条数据,数据包含有四列:['session','aid','ts','type'],记录了session的用户的这三种行为,我们挑选几个Session,来根据时间来可视化一下用户的行为类型。
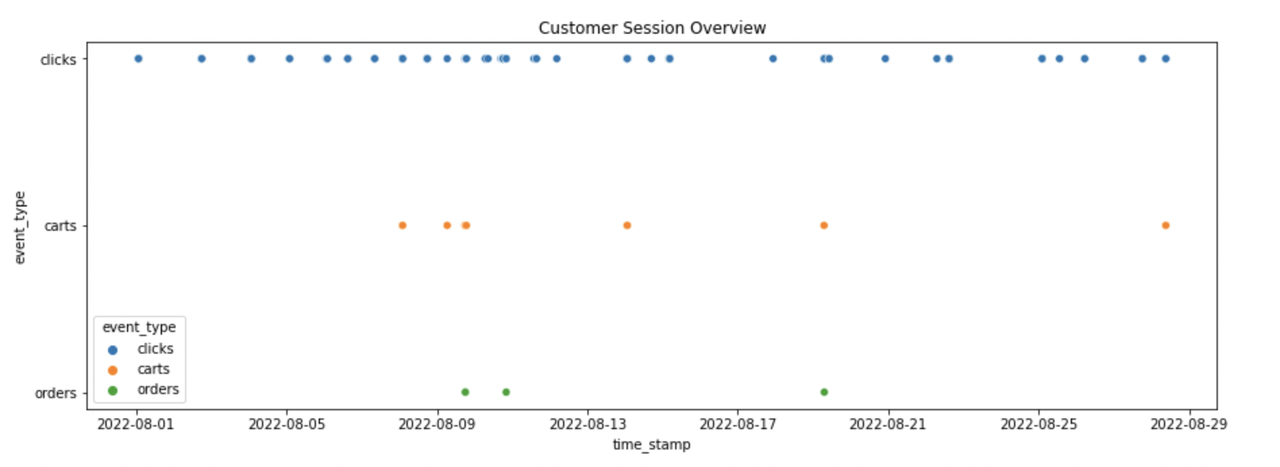
我们对数据中的三种行为的占比进行可视化:
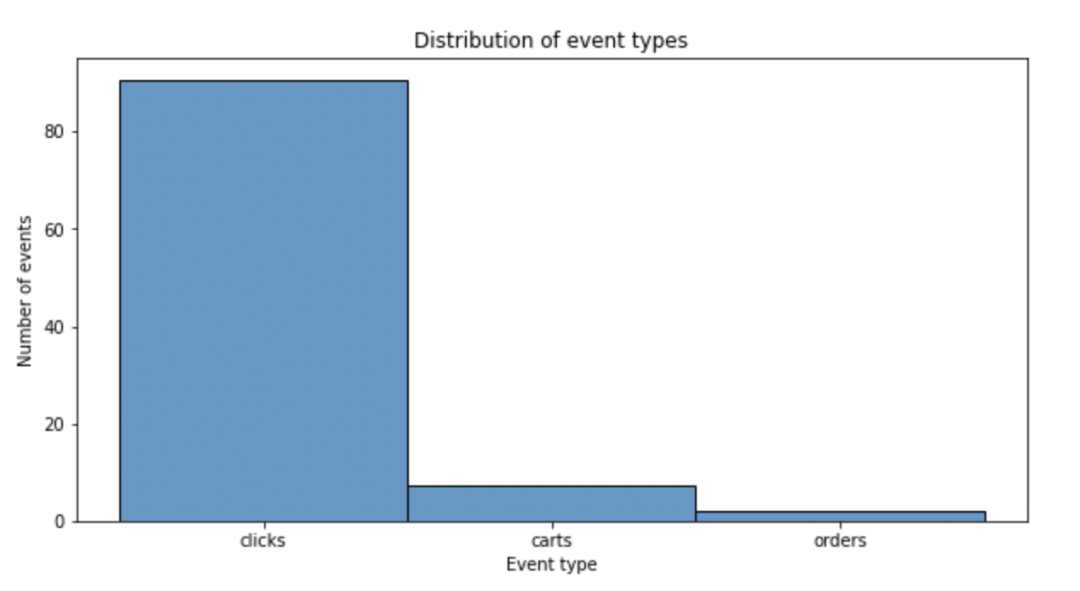
可以看到,用户的绝大多数行为是点击行为,对于加购和购买行为几乎很少。
bassline分析
Item-CF的思路
由于数据量极其的大,我们这里只使用最简单的基于统计的方法来完成此次baseline,这里我们使用Item-CF的思路,通过统计得出Item-Item的相似度矩阵,然后根据用户的行为,推荐出相似的Item以完成Top-20推荐。
由于数据量实在太大,我们这里只采样3000000个session完成下面的baseline。
train_session = random.sample(list(train_df['session'].unique()),config['train_session_num'])
train_df = train_df.query('session in @train_session').reset_index(drop=True)
在过滤完数据之后,我们来生成Item-Pair,这里要注意,每一个Item-Pair都是由在同一天同一个Session中相邻的Item对构成。
def generate_pairs(df): df = df.sort_values(by=['session','ts']) df['aid_next'] = df['aid'].shift(-1) df['session_day'] = df['session'].astype('str')+'_'+df['time_stamp'] df['session_day_count'] = df['session_day'].map(df['session_day'].value_counts()) df['ranking'] = df.groupby(['session_day'])['ts'].rank(method='first', ascending=True) df = df.query('session_day_count!=ranking').reset_index(drop=True)
sim_aids = df.groupby('aid').apply(lambda df: Counter(df.aid_next).most_common(50)).to_dict()
sim_aids = {aid: Counter(dict(top)) for aid, top in sim_aids.items()}
return sim_aids
在完成计算Item-Item的相似度之后,我们就可以来根据相似度矩阵来进行推荐了,其推荐函数如下:
def recommend(aids,popular_items):
if len(aids) >= 20:
return aids[-20:]
aids = set(aids)
new_aids = Counter()
for aid in aids:
new_aids.update(sim_aids.get(aid, Counter()))
top_aids2 = [aid2 for aid2, cnt in new_aids.most_common(40) if aid2 not in aids]
final_rec_list = list(aids) + top_aids2[:20 - len(aids)]
if len(final_rec_list)<20:
return final_rec_list + popular_items[:20-len(final_rec_list)]
else:
return final_rec_list
这样就可以完成对用户的推荐了,这里要注意,我们对不同行为的推荐结果都是相同的,由于只有点击行为的数据是非常丰富的,对于其他行为,数据是非常少的,所以这里就直接对这三个行为进行了相同的推荐。
test_df = test_df.sort_values(["session", "type", "ts"]) test_session_dict = test_df.groupby('session')['aid'].agg(list).to_dict() session_id_list = [] item_id_list = []
popular_items = list(train_df['aid'].value_counts().index)
for session_id,session_item_list in tqdm(test_session_dict.items()): item_list = recommend(session_item_list,popular_items)
session_id_list.append(session_id)
item_id_list.append(list(item_list))
res_df = pd.DataFrame() res_df['session_type'] = session_id_list res_df['labels'] = [' '.join([str(l) for l in lls]) for lls in item_id_list]
res_list = [] for type_ in [0,1,2]: temp_df = copy.deepcopy(res_df) temp_df['session_type'] = temp_df['session_type'].apply(lambda x:'{}{}'.format(x,id2type[type])) res_list.append(temp_df) res_df = pd.concat(res_list,axis=0)
可以看到,我们这次的Baseline的代码非常简单,而且效率非常的高,使用Kaggle自带的CPU环境只需要10分钟+就可以完成全流程的跑测,线上得分:0.553,虽然这个得分不是很高,但是这个baseline跑测效率较高,代码结构易懂,其潜力还是很大的~
百场比赛top方案资料包🚀🚀🚀
关注“KGMking”回复“比赛”免费获取
码字不易,欢迎大家点赞评论收藏!