Faster-RCNN代码解读5:主要文件解读-上
前言
因为最近打算尝试一下Faster-RCNN的复现,不要多想,我还没有厉害到可以一个人复现所有代码。所以,是参考别人的代码,进行自己的解读。
代码来自于B站的UP主(大佬666),其把代码都放到了GitHub上了,我把链接都放到下面了(应该不算侵权吧,毕竟代码都开源了_):
b站链接:https://www.bilibili.com/video/BV1of4y1m7nj/?vd_source=afeab8b555e5eb1bfa1e7f267262cbf2
GitHub链接:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
目的
其实UP主已经做了很好的视频讲解了他的代码,只是有时候我还是喜欢阅读博客来学习,另外视频很长,6个小时,我看的时候容易睡着_,所以才打算写博客记录一下学习笔记。
目前完成的内容
第一篇:VOC数据集详细介绍
第二篇:Faster-RCNN代码解读2:快速上手使用
第三篇:Faster-RCNN代码解读3:制作自己的数据加载器
第四篇:Faster-RCNN代码解读4:辅助文件解读
第五篇: Faster-RCNN代码解读5:主要文件解读-上(本文)
目录结构
文章目录
- Faster-RCNN代码解读5:主要文件解读-上
- 1. 前言:
- 2. boxes.py文件解读:
- 2.1 nms函数:
- 2.2 batched_nms函数:
- 2.3 remove_small_boxes函数:
- 2.4 clip_boxes_to_image函数:
- 2.5 box_area函数:
- 2.6 box_iou函数:
- 3. image_list.py文件解读:
- 4. transform.py文件解读:
- 4.1 GeneralizedRCNNTransform类:
- 4.2 _resize_image函数:
- 4.3 resize_boxes函数:
- 5. 总结:
1. 前言:
本文主要介绍Faster-RCNN项目下的network_files文件夹下的内容。这个文件夹是该项目的核心文件夹,主要就是关于Faster-RCNN构建。
由于内容比较多,所以我打算分为上中下三篇来讲解。本篇主要讲解的文件为:
boxes.py
image_list.py
transform.py
在讲解文件之前,要说明一下,在代码中经常出现的一个现象:

就是相同功能的函数,有时候会出现两次,其中的一个上面会带有@torch.jit.unused。onnx表示将模型转为通用开放的神经网络模型,此模型与pytorch、tensorflow等框架无关,两者也是可以互相转换的。
2. boxes.py文件解读:
这个文件主要的作用是:里面定义许多和边界框有关的功能函数,比如nms、计算面积、计算iou等等。下面一一来讲解。
2.1 nms函数:
这个函数是对一张图像的边界框进行NMS处理。
输入参数:
| 参数 | 意义 |
|---|---|
| boxes | 图像的边界框值,格式为Tensor[N, 4] 其中N表示N个边界框,4表示左上角和右下角的4个坐标值 |
| scores | 上述边界框对应的置信度值,格式为Tensor[N] |
| iou_threshold | 阈值,用于NMS处理时判断的依据,即丢弃所有IOU大于阈值的框 |
这个函数的内容只有一句,即:
return torch.ops.torchvision.nms(boxes, scores, iou_threshold)
可见,这个函数其实调用的时pytorch官方实现的nms方法。
2.2 batched_nms函数:
这个函数是以批处理的形式进行NMS操作。
输入参数有三个和上面的相同,就不多说了,只有一个新增的参数,即:
idxs,其是每个边界框的类别索引值,格式为Tensor[N]
函数的内容如下(看注释):
# boxes.numel()返回元素个数
if boxes.numel() == 0:
# 如果boxes中没有值了,就可以结束函数了
return torch.empty((0,), dtype=torch.int64, device=boxes.device)
# 获取所有boxes中最大的坐标值(xmin, ymin, xmax, ymax)
max_coordinate = boxes.max()
# 为每一个类别/每一层生成一个很大的偏移量
# 这里的to只是让生成tensor的dytpe和device与boxes保持一致
offsets = idxs.to(boxes) * (max_coordinate + 1)
# boxes加上对应层的偏移量后,保证不同类别/层之间boxes不会有重合的现象
boxes_for_nms = boxes + offsets[:, None]
# 进行nms操作
keep = nms(boxes_for_nms, scores, iou_threshold)
return keep
2.3 remove_small_boxes函数:
这个函数的主要作用是:删除那些宽高小于阈值的边界框。
输入参数:
| 参数 | 意义 |
|---|---|
| boxes: | 边界框对象 |
| min_size : | 宽高最小值,即阈值 |
函数内容如下:
ws, hs = boxes[:, 2] - boxes[:, 0], boxes[:, 3] - boxes[:, 1] # 预测boxes的宽和高
# keep = (ws >= min_size) & (hs >= min_size) # 当满足宽,高都大于给定阈值时为True
# torch.logical_and即逻辑与,当都为真时才为真
# torch.ge(value,threshold)逐元素比较,当value大于threshold时为True
keep = torch.logical_and(torch.ge(ws, min_size), torch.ge(hs, min_size))
keep = torch.where(keep)[0]
return keep
2.4 clip_boxes_to_image函数:
这个函数的功能是:针对那些坐标超过图像范围的预测框进行裁剪,并将越界的坐标定义为图像边界。
输入参数:
| 参数 | 意义 |
|---|---|
| boxes | 预测边界框,和上面的都一样 |
| size | 图像的宽和高,格式为Tuple[height, width] |
函数内容如下,看注释:
# 获取boxes的维度
dim = boxes.dim()
# 获取box的坐标信息
# boxes_x = [N,2],boxes_y=[N,2]
boxes_x = boxes[..., 0::2] # x1, x2
boxes_y = boxes[..., 1::2] # y1, y2
# 获取图像宽高
height, width = size
# torchvision._is_tracing 与 torch._C._get_tracing_state()
# 是否为JIT跟踪模型,具体我也不是很懂,涉及到了torch的源码内容
if torchvision._is_tracing():
# 首先和图像左上角(0,0)坐标比较,如果边界框x轴比左上角小,则取0
boxes_x = torch.max(boxes_x, torch.tensor(0, dtype=boxes.dtype, device=boxes.device))
# 然后和图像宽度比,即如果坐标比宽度大,则直接取宽度的值
boxes_x = torch.min(boxes_x, torch.tensor(width, dtype=boxes.dtype, device=boxes.device))
# y同x原理一样
boxes_y = torch.max(boxes_y, torch.tensor(0, dtype=boxes.dtype, device=boxes.device))
boxes_y = torch.min(boxes_y, torch.tensor(height, dtype=boxes.dtype, device=boxes.device))
else:
# boxes_x.clamp : 返回限制范围内的数据
boxes_x = boxes_x.clamp(min=0, max=width) # 限制x坐标范围在[0,width]之间
boxes_y = boxes_y.clamp(min=0, max=height) # 限制y坐标范围在[0,height]之间
# 将过滤后的x、y拼接在一起,dim指定维度
clipped_boxes = torch.stack((boxes_x, boxes_y), dim=dim)
return clipped_boxes.reshape(boxes.shape)
2.5 box_area函数:
这个函数的作用,通过坐标来计算边界框的面积,只要用于计算IOU。
输入参数只有一个,即boxes对象。
然后代码也很简单,只有一句:
return (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
boxes的shape为[N,4],其中4表示左上角和右下角四个坐标值。面积,肯定为长乘宽,即x坐标差值和y坐标差值之积。
2.6 box_iou函数:
这个函数的作用就是计算两个边界框的IOU值。
输入参数:两个边界框对象,格式都为Tensor[N, 4]。
函数内容如下:
# 计算面积
area1 = box_area(boxes1)
area2 = box_area(boxes2)
# 寻找两个边界框中:
# 左上角最大的坐标 ---- 相交部分左上角
# 右下角最小的坐标 ---- 相交部分右下角
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2]) # left-top [N,M,2]
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) # right-bottom [N,M,2]
# 计算相交的值
wh = (rb - lt).clamp(min=0) # [N,M,2]
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
# IOU = 交集 / 并集
# 交集 = 两个面积相交的部分
# 并集 = 两个面积相加 减去 交集
iou = inter / (area1[:, None] + area2 - inter)
return iou
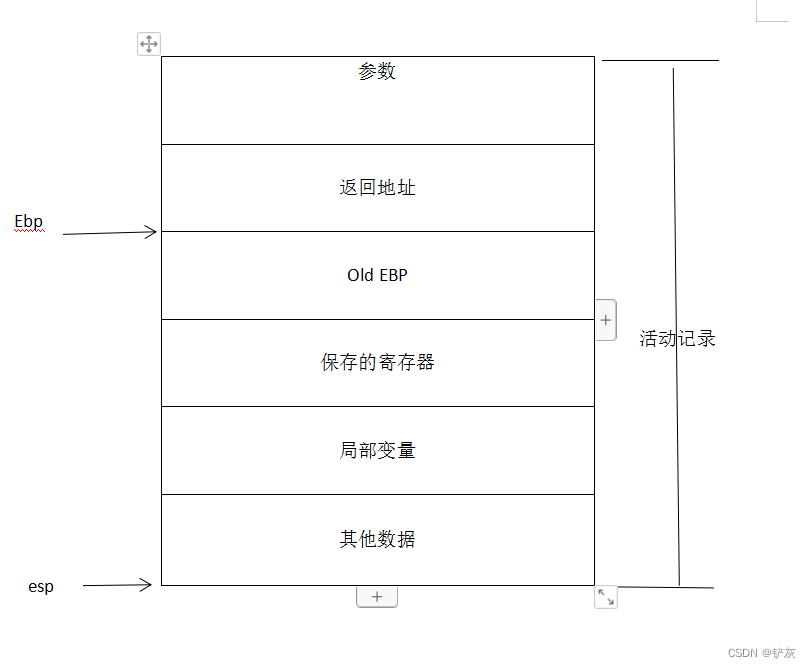
这里说一下,上面相交部分坐标为什么找最大和最小(自己画的图):

3. image_list.py文件解读:
该文件只定义了一个ImageList类,目的是将图像尺寸变换前后的数据关联在一起,方便使用。
__init__方法
输入参数:
| 参数 | 意义 |
|---|---|
| tensors | padding后的图像数据 |
| image_sizes | padding前的图像尺寸,格式为:list[tuple[int, int]] |
初始化方法很简单,就是把传入的参数定义为类变量:
self.tensors = tensors
self.image_sizes = image_sizes
to方法
就是把数据放入指定设备中,和我们平时将模型放入指定设备的to方法类似。
4. transform.py文件解读:
该文件的主要作用是:**定义数据的前处理和后处理方法。**前处理方法比如标准化处理、将尺寸不同的大小图片打包为一个batch等等。后处理方法比如将边界框映射回原尺寸上(因为为了不同尺寸图像可以打包在一起,改变了图像尺寸,所以需要映射回去)。另外,正是因为改变了图像尺寸,所以需要定义上面的ImageList类。
4.1 GeneralizedRCNNTransform类:
首先,看GeneralizedRCNNTransform类,是该文件的核心部件。
__init__方法
输入参数:
| 参数 | 意义 |
|---|---|
| min_size | 指定图像的最小边长范围 |
| max_size | 指定图像的最大边长范围 |
| image_mean | 指定图像在标准化处理中的均值 |
| image_std | 指定图像在标准化处理中的方差 |
代码内容很简单,首先判断输入的值是不是列表或者元组,如果不是,则转为元组:
if not isinstance(min_size, (list, tuple)):
min_size = (min_size,)
然后,把输入参数转为类变量即可:
self.min_size = min_size # 指定图像的最小边长范围
self.max_size = max_size # 指定图像的最大边长范围
self.image_mean = image_mean # 指定图像在标准化处理中的均值
self.image_std = image_std # 指定图像在标准化处理中的方差
normalize方法:
这个方法的就是对图像进行标准化处理。
具体内容看注释:
# 获取数据类型和设备信息 cpu or gpu
dtype, device = image.dtype, image.device
# 均值 + 方差,转为tensor格式
mean = torch.as_tensor(self.image_mean, dtype=dtype, device=device)
std = torch.as_tensor(self.image_std, dtype=dtype, device=device)
# 进行标准化
# [:, None, None]: shape [3] -> [3, 1, 1],让维度和图像保持相同【channel、w、h】
return (image - mean[:, None, None]) / std[:, None, None]
resize方法:
这个方法的作用就是将图片缩放到指定大小范围内,并同时缩放其boxes信息。
传入的参数:
| 参数 | 意义 |
|---|---|
| image | 输入的图片 |
| target | 输入图片的相关信息(包括bboxes信息) 这个就是我们定义dataset的时候返回的值之一 |
首先,获取图像宽和高:
# image = [channel, height, width]
# 获取宽高
h, w = image.shape[-2:]
判断处于训练状态还是验证状态,因为不同的状态传入的min_size参数格式不同:
# 判断是训练还是验证
if self.training:
# 指定输入图片的最小边长,注意是self.min_size不是min_size
# min_size: int ; self.min_size: tuple
size = float(self.torch_choice(self.min_size))
else:
# FIXME assume for now that testing uses the largest scale
# 指定输入图片的最小边长,注意是self.min_size不是min_size
size = float(self.min_size[-1])
然后将图片送入_resize_image函数中(具体方法看下面的4.2内容,这里不说),改变图像的尺寸:
# if 条件不用管,两者的目的都是相同的
if torchvision._is_tracing():
image = _resize_image_onnx(image, size, float(self.max_size))
else:
image = _resize_image(image, size, float(self.max_size))
缩放完图片后,肯定需要缩放一下图片对应的box了。但在此之前,首先判断target是否为空,为空表示这个图像根本没有对象,直接跳过即可。否则,就可以缩放box信息了:
# 如果target为空,则结束函数
if target is None:
return image, target
# 从target获取boxes值
bbox = target["boxes"]
# 根据图像的缩放比例来缩放bbox
# 原来: [h, w] ; 缩放的要求: image.shape[-2:]
bbox = resize_boxes(bbox, [h, w], image.shape[-2:])
# 添加缩放后的值
target["boxes"] = bbox
其中,缩放box的函数叫做resize_boxes,其接收三个参数:
待缩放的box
缩放前尺寸
缩放后尺寸
该函数内容看下面的4.3内容。
batch_images方法:
该方法的作用是**将大小不同的图像打包一个batch。**这里值得一提的是,在图像分类中,我们的输入图像大小是固定的,因此可以直接打包为一个batch,不需要我们单独实现,而在检测中,输入图像大小不同,因此需要将图像变为同一尺寸再打包。
这里,作者选择的打包思路为:获取一批图像的最大尺寸,以它为模板,其余图像与它左上角对齐,然后其余图像与最大图像相比少的部分填充为0。见下图示意:

作者就是按照这个思路进行实现的:
# 分别计算一个batch中所有图片中的最大channel(3), height, width
max_size = self.max_by_axis([list(img.shape) for img in images])
# 将刚刚获得的size取离32最近的整数倍值,一种玄学,就是32的倍数更利于训练,比如2的n次方
stride = float(size_divisible)
# 将height向上调整到stride的整数倍
max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride)
# 将width向上调整到stride的整数倍
max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride)
# 构建训练batch:[batch, channel, height, width]
batch_shape = [len(images)] + max_size
# 创建shape为batch_shape且值全部为0的tensor
# images[0]中的索引无所谓,只是利用new_full方法,即以batch_shape为shape创建一个tensor,其值全为0
batched_imgs = images[0].new_full(batch_shape, 0)
for img, pad_img in zip(images, batched_imgs):
# 将输入images中的每张图片复制到新的batched_imgs的每张图片中,对齐左上角,保证bboxes的坐标不变
# 这样保证输入到网络中一个batch的每张图片的shape相同
# 0 : img.shape[0],channel维度 ; : img.shape[1] : 图像高 ; : img.shape[2],图像高
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
其中,还有一个方法就是max_by_axis,见下面。
max_by_axis方法:
这个方法的作用,就是找出图像中通道数、宽、高最大的值。当然,通道数都是一样的,为3。
它这个方法用两层循环实现,实现的思路有点类似排序算法中的冒泡排序,就是先找一个临时变量作为最大值,然后不断比较,谁大谁替代:
# 将索引为0的值给maxes
maxes = the_list[0]
# 从索引为1的开始遍历
for sublist in the_list[1:]:
# 将当前索引的值与前一个最大的值比较,如果比它大,则重新设置最大值
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
# 返回最大值
return maxes
forward方法:
这个方法是该类的前向传播过程。
输入参数:
| 参数 | 意义 |
|---|---|
| images | 输入图像列表(一个batch的数量) |
| targets | 图像对应的信息 |
首先,将输入图像参数转为列表:
# 获取图像列表
images = [img for img in images]
然后,遍历图像,对每个图像进行标准化和缩放处理:
# 遍历图像
for i in range(len(images)):
# 复制一份图像
image = images[i]
# 判断target是否为空,
target_index = targets[i] if targets is not None else None
# 判断图片维度是否为3
if image.dim() != 3:
raise ValueError("images is expected to be a list of 3d tensors "
"of shape [C, H, W], got {}".format(image.shape))
# 对图像进行标准化处理
image = self.normalize(image)
# 对图像和对应的bboxes缩放到指定范围
image, target_index = self.resize(image, target_index)
# 替换图像
images[i] = image
# 判断图像是否为空
if targets is not None and target_index is not None:
# 替换target,即替换resize后的box
targets[i] = target_index
接着,将图片打包为一个batch,而由于最后需要将box映射回原图像,因此需要记录resize后的尺寸(尺寸可能不同)和打包后的尺寸(尺寸都相同了):
# 记录resize后的图像尺寸。此时图片的尺寸可能不同
image_sizes = [img.shape[-2:] for img in images]
# 将images打包成一个batch,此时图像大小尺寸相同了
images = self.batch_images(images)
# 指定image_list格式
image_sizes_list = torch.jit.annotate(List[Tuple[int, int]], [])
# 遍历image_sizes
for image_size in image_sizes:
# 如果image_size长度为2,报错
assert len(image_size) == 2
# 将值打包为一个tuple,传入一个list中,符合image_sizes_list格式
image_sizes_list.append((image_size[0], image_size[1]))
# ImageList类:将两者关联一起
# images :打包后一个独立的tensor变量
# image_sizes_list: 打包前的图像尺寸信息
# 主要方便后期绘图,因为图像原尺寸就在xml文件中,所以需要记录一下resiz后的尺寸和打包后的尺寸
image_list = ImageList(images, image_sizes_list)
# 得到即将输入backbone的信息
return image_list, targets
postprocess方法:
这个方法就是对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上)。
输入参数:
| 参数 | 意义 |
|---|---|
| result | 网络的预测结果(bbox信息和类别信息) |
| image_shapes | 图像预处理缩放后(即打包处理后)的尺寸 |
| original_image_sizes | 图像的原始尺寸(即缩放到指定范围后的尺寸) |
首先,判断是否为训练模式,如果是,则不需要后处理:
# 如果为训练模式,不需要后处理
if self.training:
return result
然后,进行缩放映射,还是使用resize_boxes方法,这个很简单:
# 遍历每张图片的预测信息,将boxes信息还原回原尺度
for i, (pred, im_s, o_im_s) in enumerate(zip(result, image_shapes, original_image_sizes)):
# 获取预测结果的boxes信息
boxes = pred["boxes"]
# 通过resize_boxes(box信息,原始尺寸,要转为的尺寸)
boxes = resize_boxes(boxes, im_s, o_im_s) # 将bboxes缩放回原图像尺度上
# 替换
result[i]["boxes"] = boxes
4.2 _resize_image函数:
作用:改变图像大小尺寸。
输入参数:
| 参数 | 意义 |
|---|---|
| image | 输入图像 |
| self_min_size | 允许的最小尺寸 |
| self_max_size | 允许的最大尺寸 |
这个函数的实现思路为:首先获取图像宽高,并设定宽高中的最大值和最小值;接着,用允许的最小尺寸除以图像宽高的最小值,得到缩放因子;如果图像最大尺寸乘以缩放因子小于允许的最大尺寸,那么可以进行图像的缩放工作了,否则还需要修改缩放因子。
代码具体内容看注释:
# 获取图像原尺寸信息
im_shape = torch.tensor(image.shape[-2:])
min_size = float(torch.min(im_shape)) # 获取高宽中的最小值
max_size = float(torch.max(im_shape)) # 获取高宽中的最大值
scale_factor = self_min_size / min_size # 根据指定最小边长和图片最小边长计算缩放比例
# 如果使用该缩放比例计算的图片最大边长大于指定的最大边长
if max_size * scale_factor > self_max_size:
# 重新指定缩放因子
scale_factor = self_max_size / max_size # 将缩放比例设为指定最大边长和图片最大边长之比
# interpolate利用插值的方法缩放图片
# image[None]操作是在最前面添加batch维度[C, H, W] -> [1, C, H, W]
# 原因:bilinear(双线性插值)只支持4D Tensor
image=torch.nn.functional.interpolate(image[None],scale_factor=scale_factor,mode="bilinear",recompute_scale_factor=True,align_corners=False)[0]
4.3 resize_boxes函数:
作用:将boxes参数根据图像的缩放情况进行相应缩放。
输入参数:
| 参数 | 意义 |
|---|---|
| boxes | 待缩放的box |
| original_size | 图像缩放前的尺寸 |
| new_size | 图像缩放后的尺寸 |
首先,获取宽、高的缩放因子:
# 获取宽度和高度方向的缩放因子
# 下面的/为除号
ratios = [
torch.tensor(s, dtype=torch.float32, device=boxes.device) /
torch.tensor(s_orig, dtype=torch.float32, device=boxes.device)
for s, s_orig in zip(new_size, original_size)
]
ratios_height, ratios_width = ratios
接着,获取box的四个坐标信息,并乘以缩放因子,得到新的坐标值,最后再将其拼接返回即可:
# boxes [minibatch, 4],
# boxes.unbind(1)表示在4这个维度展开,得到坐标值
xmin, ymin, xmax, ymax = boxes.unbind(1)
# 缩放
xmin = xmin * ratios_width
xmax = xmax * ratios_width
ymin = ymin * ratios_height
ymax = ymax * ratios_height
# 将坐标拼接,然后返回去
return torch.stack((xmin, ymin, xmax, ymax), dim=1)
5. 总结:
从这一篇开始就是讲解Faster-RCNN的具体架构实现了,本篇主要讲解了其中的辅助文件功能和作用。其中比较重要的文件是transform.py。