在PyTorch提供的已经训练好的图像目标检测中,均是R-CNN系列的网络,并且针对目标检测和人体关键点检测分别提供了容易调用的方法。针对目标检测的网络,输入图像均要求使用相同的预处理方式,即先将每张图像的像素值预处理到0 ~1之间,且输入的图像尺寸不是很小即可直接调用。已经预训练的可供使用的网络模型如下表所示。
| 网络类 | 描述 |
| detection.fasterrcnn_resnet50_fpn | 具有Resnet-50-FPN的Fast R-CNN网络模型 |
| detection.maskrcnn_resnet50_fpn | 具有Resnet-50-FPN结构的Mask R-CNN网络模型 |
| detection.keypointrcnn_resnet50_fpn | 具有Resnet-50-FPN结构的Keypoint R-CNN网络模型 |
这些网络同样是在COCO 2017数据集上进行训练的。
1.图像目标检测
在进行图像目标检测时,使用已经预训练好的具有ResNet-50-FPN结构的FastR-CNN网络模型,该网络同样是通过COCO数据集进行预训练,导入已预训练的网络,程序如下所示:
import numpy as np
import torchvision
import torch
import torchvision.transforms as transforms
from PIL import Image,ImageDraw,ImageFont
import matplotlib.pyplot as plt
model=torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()下面从文件夹中读取一张照片,并将其转化为张量,像素值在0~1之间,然后使用导入模型对其进行预测,程序如下:
image=Image.open(r'C:\Users\zex\Downloads\VOCdevkit\VOC2012\JPEGImages\2012_001460.jpg')
transform_d=transforms.Compose([transforms.ToTensor()])
image_t=transform_d(image)#对图像进行变换
pred=model([image_t])在pred输出的结果中主要包括三种值,分别是检测到每个目标的边界框( boxes坐标)、目标所属的类别(labels),以及属于相应类别的得分( scores )。从上面的输出结果中可以发现,找到的目标约有21个,但仅前5个目标得分大于0.5。下面将检测到的目标可视化,并观察检测的具体结果。
首先定义每个类别所对应的标签COCO_INSTANCE_CATEGORY_NAMES,程序如下:
COCO_INSTANCE_CATEGORY_NAMES=[
'__background__','person','bicycle','car','motorcycle',
'airplane','bus','train','truck','boat','traffic light',
'fire hydrant','N/A','stop sign','parking meter','bench',
'bird','cat','dog','horse','sheep','cow','elephant',
'bear','zebra','giraffe','N/A','backpack','umbrella','N/A',
'N/A','handbag','tie','suitcase','frisbee','skis','snowboard',
'surfboard','tennis racket','bottle','N/A','wine glass',
'cup','fork','knife','spoon','bowl','banana','apple',
'sandwich','orange','broccoli','carrot','hot dog','pizza',
'donut','cake','chair','couch','potted plant','bed','N/A',
'dining table','N/A','N/A','toilet','N/A','tv','laptop',
'mouse','remote','keyboard','cell phone','microwave','oven',
'toaster','sink','refrigerator','N/A','book','clock',
'vase','scissors','teddy bear','hair drier','toothbrush'
]针对预测的结果,在可视化之前,需要分别将有效的预测目标数据解读出来,需要提取的信息有每个目标的位置、类别和得分,然后将得分大于0.5的目标作为检测到的有效目标,并将检测到的目标在图像上显示出来,程序如下:
#检测出目标的类别和得分
pred_class=[COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_score=list(pred[0]['scores'].detach().numpy())
#检测出目标的边界框
pred_boxes=[[i[0],i[1],i[2],i[3]] for i in list(pred[0]['boxes'].detach().numpy())]
#只保留识别的概率大于0.5的结果
pred_index=[pred_score.index(x) for x in pred_score if x > 0.5]
#设置图像显示的字体
fontsize=np.int16(image.size[1] / 30)
font1=ImageFont.truetype(r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\SegmentDetection\华文细黑.ttf',fontsize)
#可视化图像
draw=ImageDraw.Draw(image)
for index in pred_index:
box=pred_boxes[index]
draw.rectangle(box,outline='red')
texts=pred_class[index]+':'+str(np.round(pred_score[index],2))
draw.text((box[0],box[1]),texts,fill='red',font=font1)
image.show()上面的程序在可视化图像时,使用ImageDraw.Draw(image)方法,表示要在原始的image图像上相应的位置添加一些元素,draw.rectangle()表示要添加矩形框,draw.text()表示在图像上指定位置添加文本。运行程序后,可得到下图所示的目标检测结果。

2.人体关键点检测
人体骨骼关键点检测主要检测人体的一些关键点,如关节、五官等,通过关键点描述人体骨骼信息。MS COCO数据集是多人人体关键点检测数据集,具有关键点个数为17,图像的样本数多于30万张,也是目前的相关研究中最常用的数据集。在torchvision库中,提供了已经在MS COCO数据集上预训练的keypointrcnn_resnet50_fpn()网络模型,该网络可以用于人体的关键点检测。先导入预训练好的网络模型,程序如下所示:
import torch
import torchvision
model=torchvision.models.detection.keypointrcnn_resnet50_fpn(pretrained=True)
model.eval()
因为该网络的预测输出结果中会有目标检测的结果,即每个人的关键点检测结果。下面先导入目标类别标签和17个关键点的标签,程序如下:
COCO_INSTANCE_CATEGORY_NAMES=[
'__background__','person','bicycle','car','motorcycle',
'airplane','bus','train','truck','boat','traffic light',
'fire hydrant','N/A','stop sign','parking meter','bench',
'bird','cat','dog','horse','sheep','cow','elephant',
'bear','zebra','giraffe','N/A','backpack','umbrella','N/A',
'N/A','handbag','tie','suitcase','frisbee','skis','snowboard',
'surfboard','tennis racket','bottle','N/A','wine glass',
'cup','fork','knife','spoon','bowl','banana','apple',
'sandwich','orange','broccoli','carrot','hot dog','pizza',
'donut','cake','chair','couch','potted plant','bed','N/A',
'dining table','N/A','N/A','toilet','N/A','tv','laptop',
'mouse','remote','keyboard','cell phone','microwave','oven',
'toaster','sink','refrigerator','N/A','book','clock',
'vase','scissors','teddy bear','hair drier','toothbrush'
]
COCO_PERSON_KEYPOINT_NAMES=['nose','left_eye','right_eye','left_ear','right_ear',
'left_shoulder','right_shoulder','left_elbow','right_elbow',
'left_wrist','right_wrist','left_hip','right_hip','left_knee',
'right_knee','left_ankle','right_ankle']
17个关键点分别是鼻子、左眼、右眼、左耳朵、右耳朵、左肩、右肩、左胳膊肘、右胳膊肘、左手腕、右手腕、左臀、右臀、左膝、右膝、左脚踝和右脚踝,分别使用1~17标号表示。
下面从文件夹中读取一张图像,并对该图像中的人物目标和关键点进行预测,程序如下所示:
image=Image.open(r"C:\Users\zex\Desktop\3.29兼职\person.png")
transforms_d=transforms.Compose([transforms.ToTensor()])
image_t=transforms_d(image)
pred=model([image_t])
print(pred)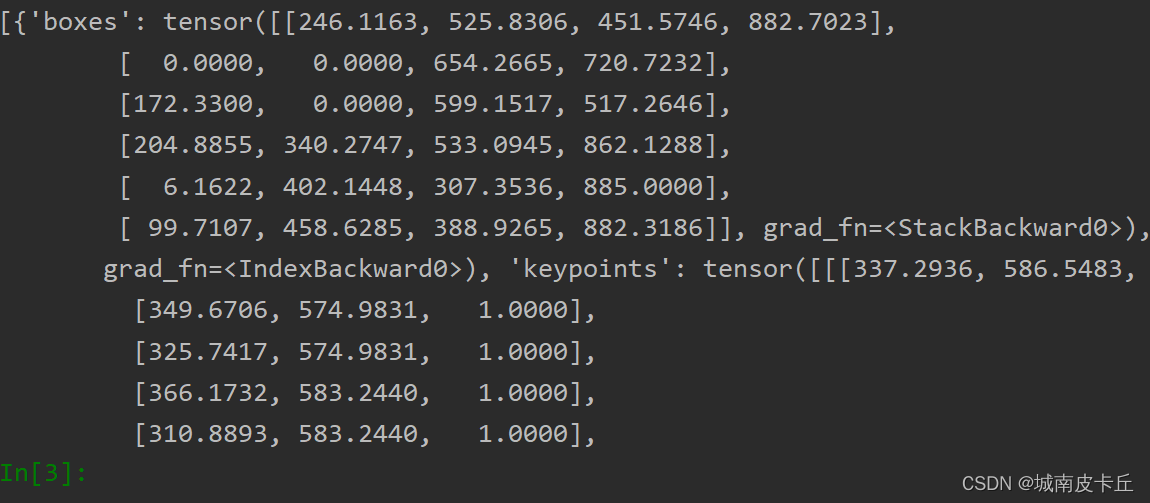
上面的程序对图像进行预测后在pred的结果中包含以下内容:
(1)boxes:检测出目标的位置。
(2)labels:检测出目标的分类。
(3) scores:检测出目标为对应分类的得分
(4) keypoints:检测出N个实例中每个实例的K个关键位置,其中每个点的数据格式为[x,y, visibility],如果visibility =0,表示关键点不可见。
(5) keypoints__scores:表示每个关键点的相应得分。
从输出的检测结果中发现,图像中检测出了三个目标,但并不是每个目标得分都很高,下面先可视化得分高于0.5的目标,程序如下所示:
#检测出目标的类别和得分
pred_classes=[COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_score=list(pred[0]['scores'].detach().numpy())
#检测出目标的边界框
pred_boxes=[[i[0],i[1],i[2],i[3]] for i in list(pred[0]['boxes'].detach().numpy())]
#只保留识别的概率大于0.5的结果
pred_index=[pred_score.index(x) for x in pred_score if x > 0.5]
#设置图像显示的字体
fontsize=np.int16(image.size[1] / 30)
font1=ImageFont.truetype(r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\SegmentDetection\华文细黑.ttf')
#可视化图像
image2=image.copy()
draw=ImageDraw.Draw(image2)
for index in pred_index:
box=pred_boxes[index]
draw.rectangle(box,outline='red')
texts=pred_classes[index]+':'+str(np.round(pred_score[index],2))
draw.text((box[0],box[1]),texts,fill='red',font=font1)
image2.show()

下面可视化出该人物和网络检测到的关键点位置,程序如下所示:
pred_index=[pred_score.index(x) for x in pred_score if x >0.5]
pred_keypoint=pred[0]['keypoints']
#检测到实例的关节点
pred_keypoint=pred_keypoint[pred_index].detach().numpy()
#可视化出关键点的位置
fontsize=np.int16(image.size[1] /50)
r=np.int16(image.size[1] /150)#圆的半径
font1=ImageFont.truetype(r'E:\PythonWorkSpace\pytorch_project\pytorch_demo\SegmentDetection\华文细黑.ttf',fontsize)
#可视化图像
image3=image.copy()
draw=ImageDraw.Draw(image3)
#对实例数量索引
for index in range(pred_keypoint.shape[0]):
keypoints=pred_keypoint[index]
for i in range(keypoints.shape[0]):
x=keypoints[i,0]
y=keypoints[i,1]
visi=keypoints[i,2]
if visi>0:
draw.ellipse(xy=(x-r,y-r,x+r,y+r),fill=(255,0,0))
texts=str(i+1)
draw.text((x+r,y-r),texts,fill='red',font=font1)
image3.show()