图解YOLO v3 的网络架构和基本流程
近年来,由于在海量数据与计算力的加持下,深度学习对图像数据表现出强大的表示能力,成为了机器视觉的热点研究方向。图像的表示学习,或者让计算机理解图像是机器视觉的中心问题。
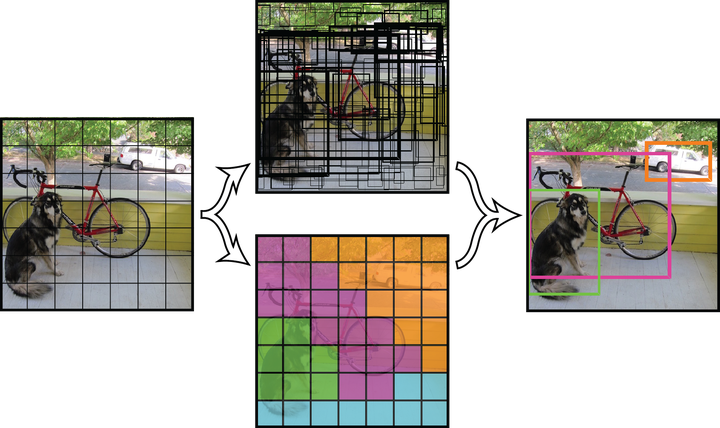
具体来说,图像理解包括分类、定位、检测与分割等单个或组合任务,如下图所示。
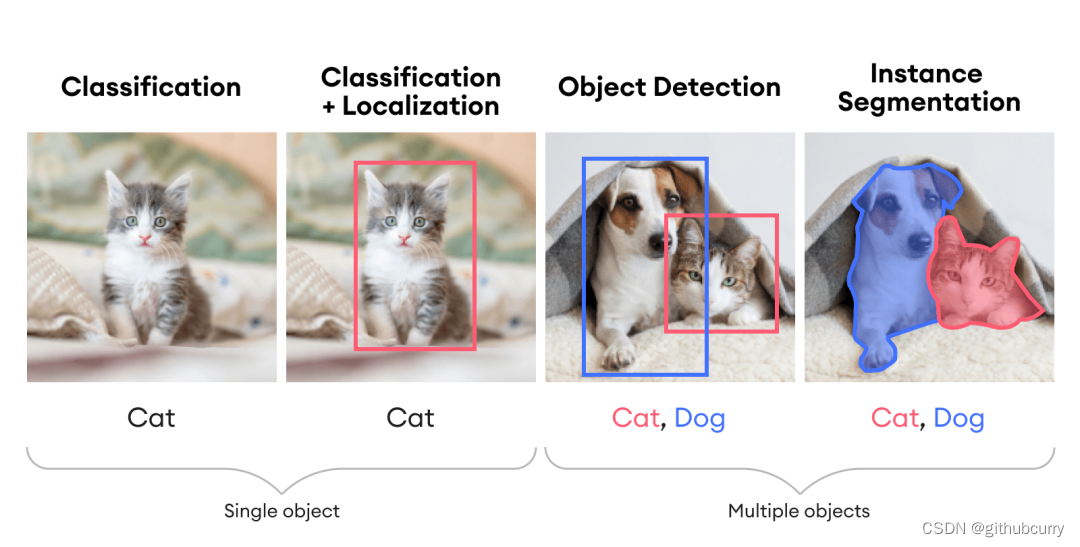
目标检测可以认为是一个将分类和回归相结合的任务。
目标检测的核心问题可以简述为**图像中什么位置有什么物体。**可以分为两类问题
-
定位问题:目标出现在图像中哪个位置(区域)。
-
分类问题:图像的某个区域里的目标属于什么类别。
当然,目标在图像中还存在其他问题,如尺寸问题,即物体具有不同大小;还有形状问题,即物体在各种角度下可以呈现各种形状。
基于深度学习的目标检测算法目前主要分为两类:Two-stage 和 One-stage。
Tow-stage
先生成区域(region proposal,简称 RP),即一个可能包含待检物体的预选框,再通过卷积神经网络进行分类。
任务流程:特征提取 --> 生成 RP --> 分类/定位回归。
常见 Two-stage 目标检测算法有:R-CNN、Fast R-CNN、Faster R-CNN、SPP-Net 和 R-FCN 等。
One-stage
直接用网络提取图像特征来预测物体位置和分类,因此不需要 RP。
任务流程:特征提取–> 分类/定位回归。
常见的 One-stage 目标检测算法有:YOLO 系列、SSD 和 RetinaNet 等。不过,为了得到最终目标的定位和分类,往往需要后处理。
YOLO v3基本原理
首先,我们先从整体上来看一下 YOLO v3 是如何工作的。YOLO v3 算法通过将图像划分为 NxN 个网格(grid)单元来工作,每个网格单元具有相同大小的区域。这 NxN 个网格单元中的每一个都负责对包含该网格的目标的检测和定位。
相应地,这些网格预测B个相对于它们所在单元格的包围盒相对坐标,以及目标标签和目标出现在单元格中的概率。
由于网格的分辨率比起原图来说已经大大降低,而检测和识别步骤都是针对网格单元来处理的,因此这个方案大大降低了计算量。但是,由于多个单元格用不同的包围盒来预测同一个对象,因此会带来了很多重复的预测框。YOLO v3 使用**非最大值抑制(Non-Maximum Suppression,NMS)**来处理这个问题。
下图给出了一个例子,展示了当 N=13 时的 13 x 13 个网格以及由此检测图中目标的大致流程。会涉及很多个包围盒,最后选出三个包围盒来定位和识别目标。

另外,为了兼顾图像中各种尺度的目标,可以使用多个不同分辨率的 NxN 个网格。很快将会看到,YOLO v3 中使用了 3 个尺度。
总体架构
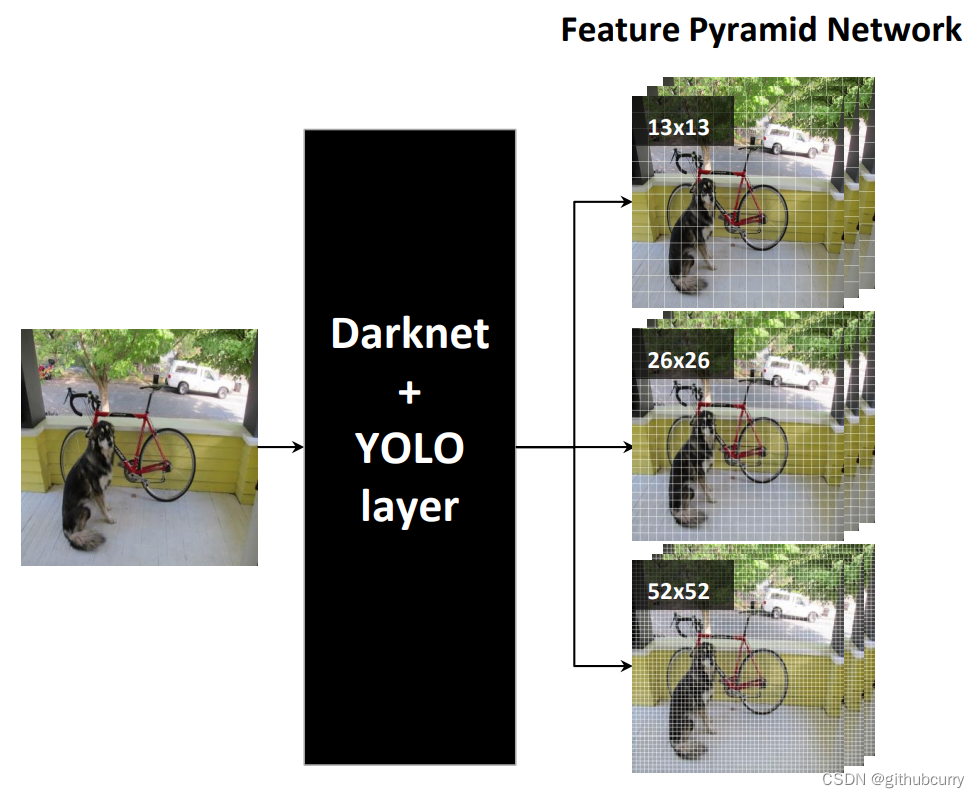
先看一下网络架构,注意它有三个不同分辨率的输出分支。
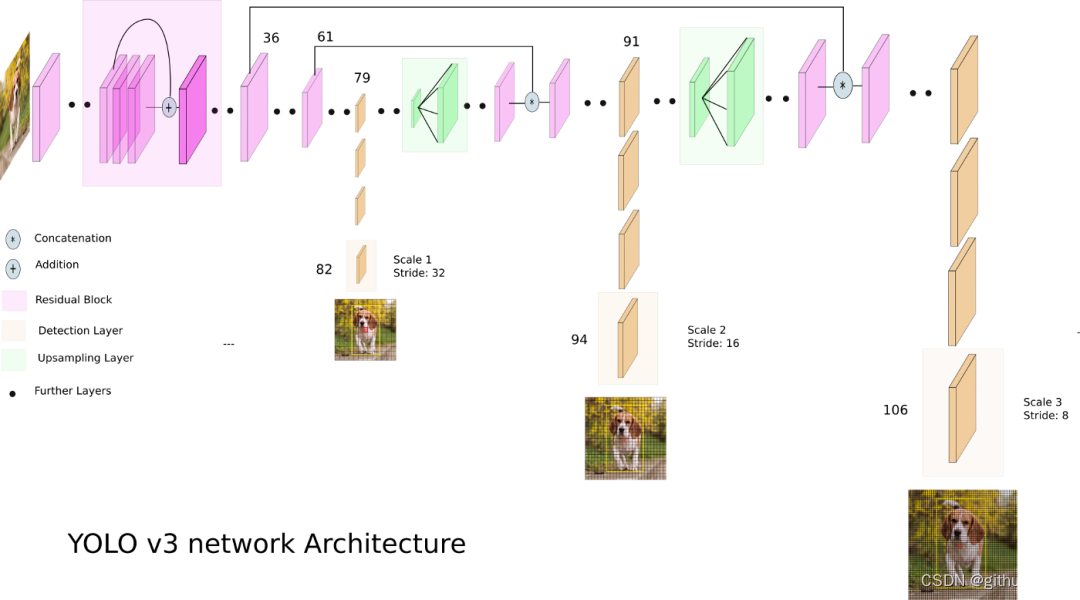
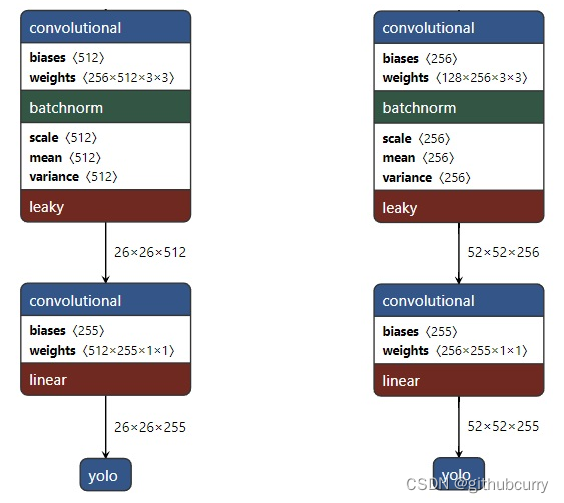
从 Yolo v3 的流程图可以看到,总共有 106 层,实现了对每张图像在大、中、小三个尺度上检测目标。这个网格有三个出口,分别是 82 层、94 层、106 层。
下面看一下更加详细的网络架构图,注意有三个检测结果(Detection Result)。
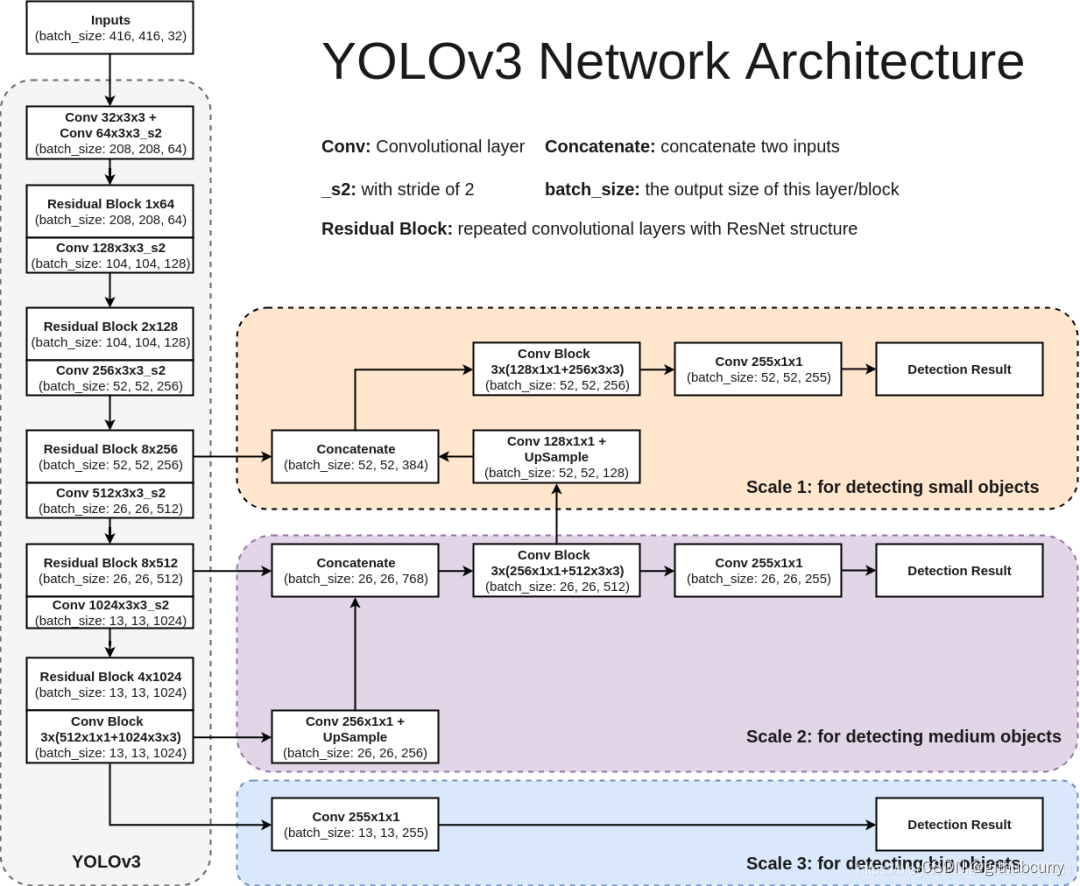
上图左边是 DarkNet-53,是一个深度为 53 层的卷积神经网络,具体的残差块和卷积层如下图所示。
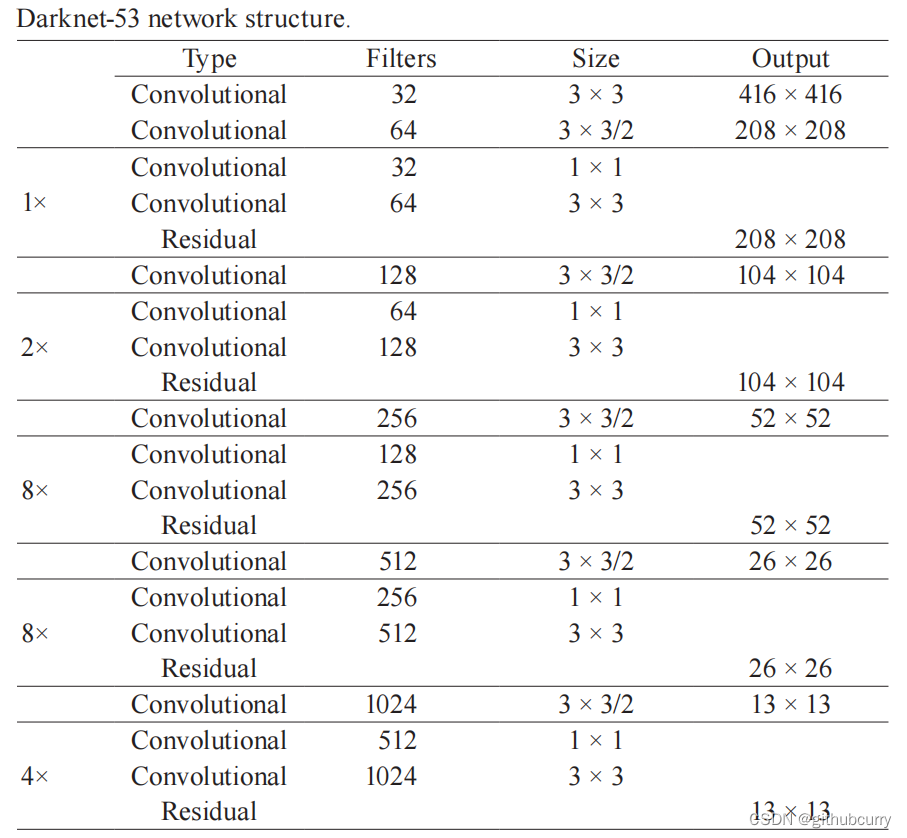
输入图像通过 Darknet 得到三个尺度的特征图,从上往下为 (52×52×256), (26×26×512), (13×13×1024),也就是在三种尺度上进行以便检测到不同大小的目标。也可以结合下面这个更加精炼图来理解。
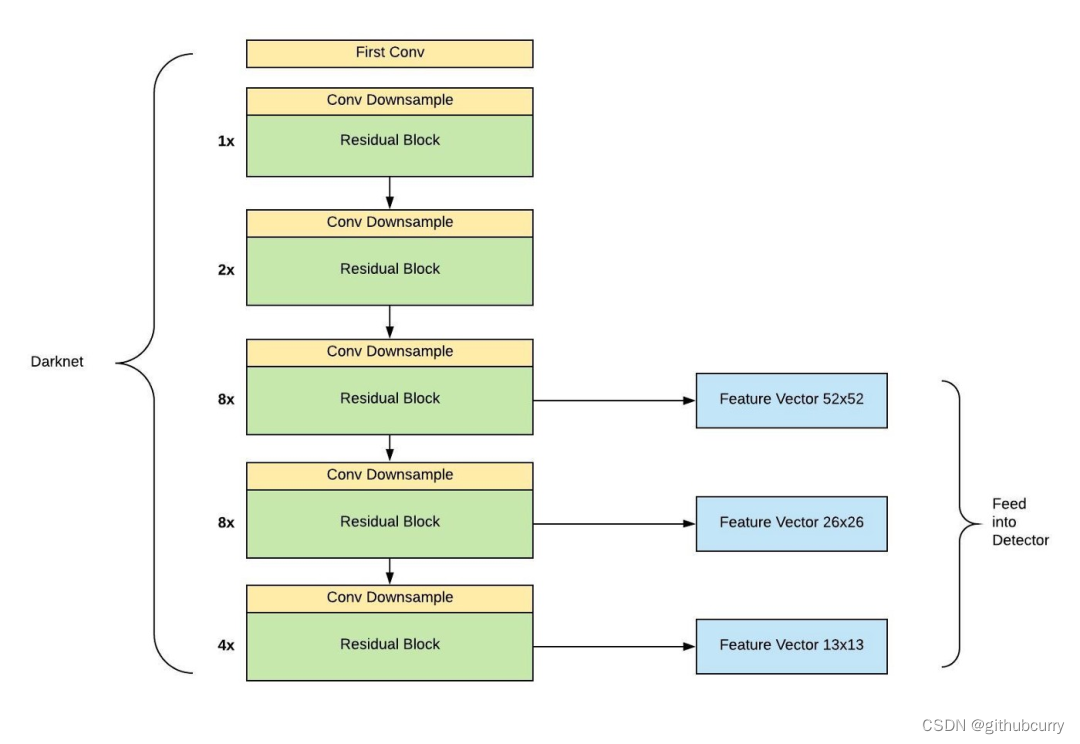
关键步骤
目标检测也可以看作是对图像中的背景和前景作某种理解分析,即从图像背景中分离出感兴趣的目标,得到对于目标的描述<位置,类别>。
由于可能有多个目标存在,模型输出是一个列表,包含目标的位置以及目标的类别。目标位置一般用矩形检测框(bounding box)的中心和宽高来表示。
模型输出值
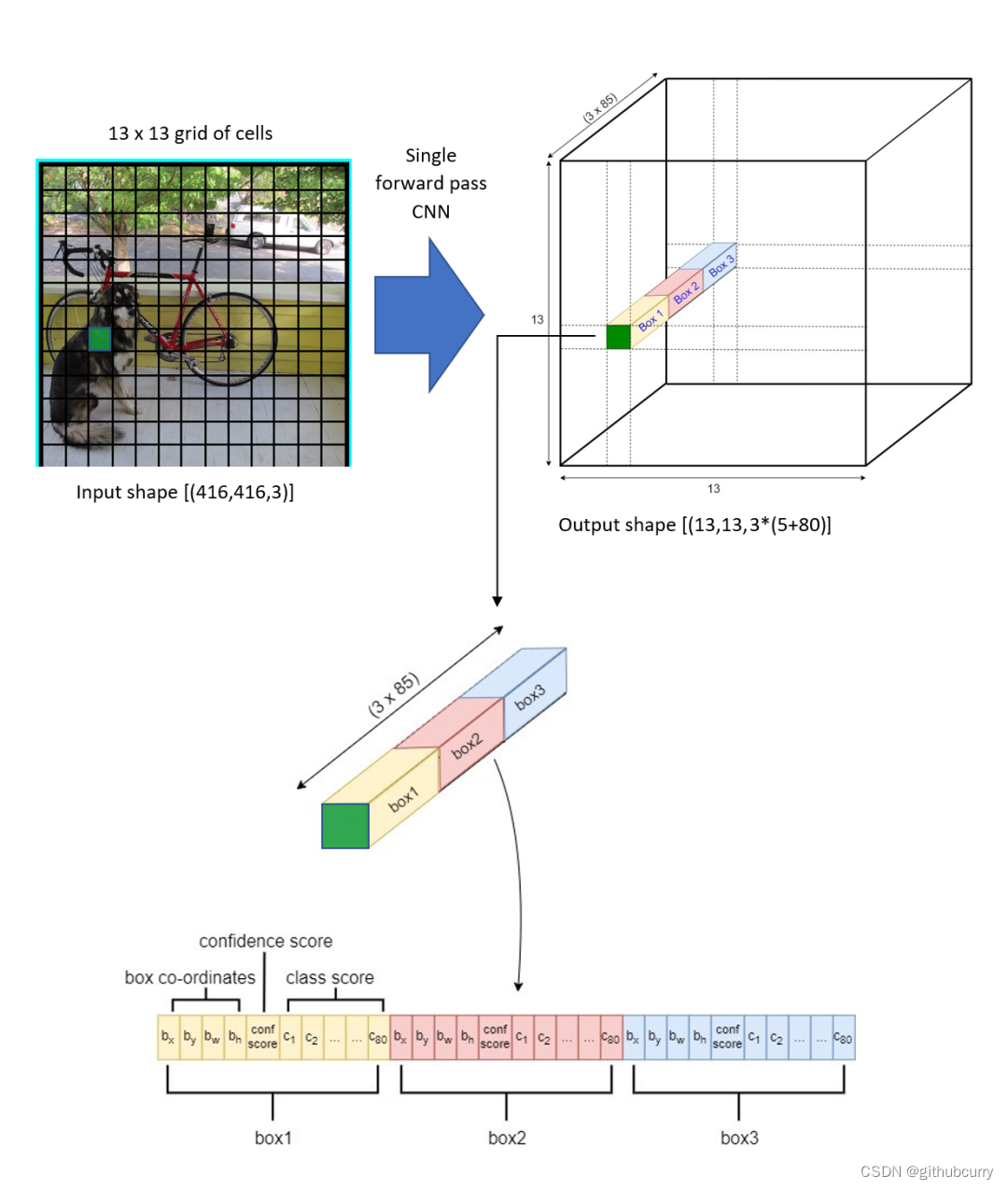
分辨率最低的输出分支对应的结果是 13 x 13 x 255 ,下图展示了在 13 x 13 特征图上的检测结果,特征图上的一个像素对应一个网格,每个网格会有 3 个预测框,每个预测框具有(5 + C)个值,其中前 5 个数对应包围盒的位置以及属于目标的可能性,C 表示类别数。

具体来看,最后输出的结果为:每个网格单元对应一个 B x ( 5 + C) 维向量,B表示一个网格可以预测包围盒的数目,C上面已经说了,5个数值中的前 4个对应包围盒的中心位子和宽高值 (tx,ty,tw,th) 和 1个目标置信度po。
这个结果的含义大致清楚了,但是还有个小问题,就是这个输出是根据什么信息计算而来呢?
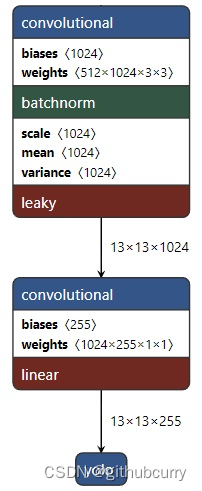
如下图所示,在前一层得到的特征图上再接一个核大小为 1x1 的卷积层得到最终的输出,即由每个网点的特征向量(1024 维)转化为我们需要的输出,即包围盒、目标置信度以及类别信息。
上面说了,在这个尺度上会检测 3 个预测框,把它们拼接在一起,得到完整的结果示意图如下。
另外两个尺度上类似,它们对应的分支输出如下两个图所示。
网络会在 3 个尺度上分别检测,每个尺度上每个网格点都预设 3 个包围盒,所以整个网络共检测到 13×13×3 + 26×26×3 + 52×52×3 = 10647个包围盒。
那么这里的 3 个预设包围盒又是怎么回事呢?
其实每个网格单元可以对目标的包围盒进行一定数量的猜测,比如下图中的示例,黄色网格单元进行两次包围盒(蓝色框)预测以定位人的位置。
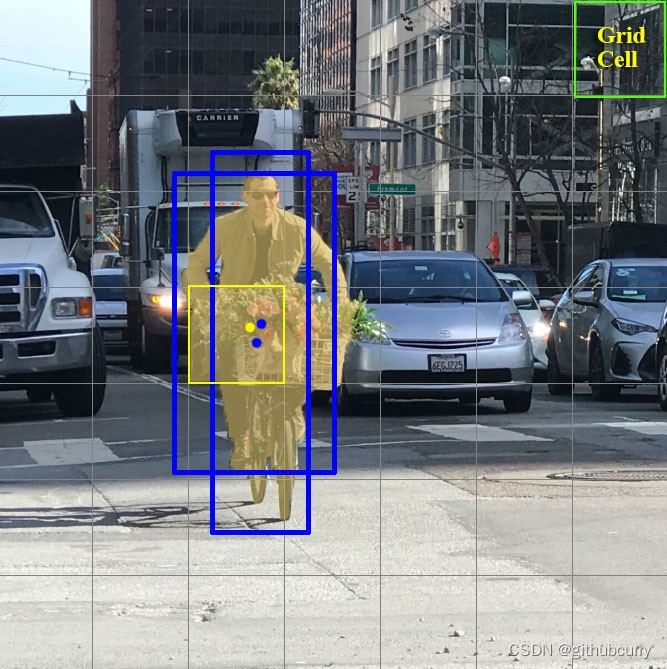
而 YOLO v3 中采用 3 个预设包围盒,但值得注意的是这里限定只能检测同一个目标。
先验包围盒
还有一个问题,每个网格对应的包围盒怎么取呢?理论上,包围盒可以各种各样,但是这样的话就需要大量计算。
为了节省计算,不妨预先了解一下在图像中出现的目标一般具有怎么样的包围盒。可以通过在数据集 VOC 和 COCO 上使用聚类法寻找一般目标的包围盒尺寸。
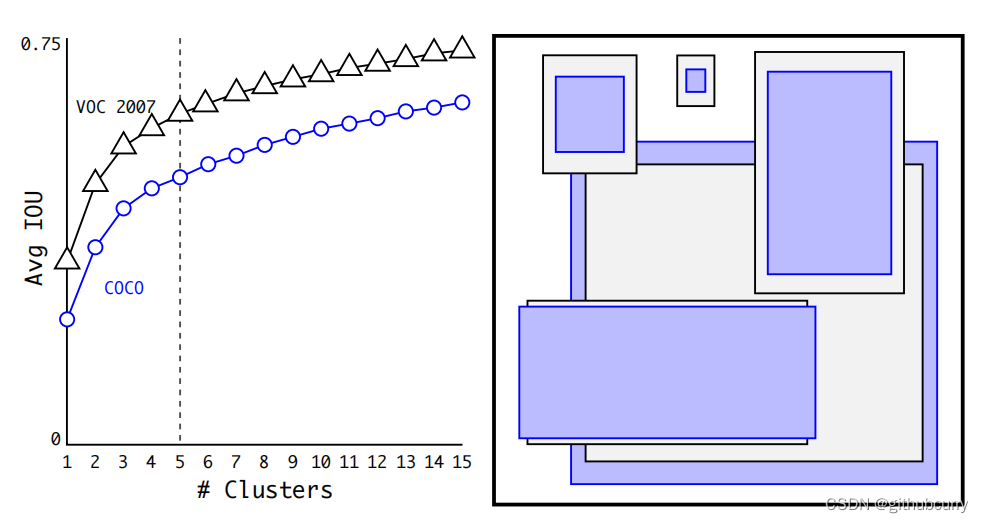
在包围盒的维度上运行 k-means 聚类,以获得良好先验。左图显示了我们在选择 k 时得到的平均 IOU。在 YOLO v2 中,作者选择k=5,此时在模型的召回率与复杂性之间具有较好的平衡。右图显示了 VOC 和 COCO 的相对质心。两组先验都倾向于更薄、更高的盒子,而 COCO 的尺寸变化比 VOC 更大。
而在 YOLO v3 中,通过聚类选出了 个先验包围盒: (10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
包围盒预测
有了预设的先验包围盒,怎么来计算实际包围盒呢?总不能直接套到每个网格单元处就完事了吧。
YOLO v3 引入一个机制,可以适当调整预设包围盒来生成实际的包围盒。下图中的公式将网络输出值 (tx,ty,th,tw) 转换得到实际的包围盒信息 (bx,by,bw,bh)。
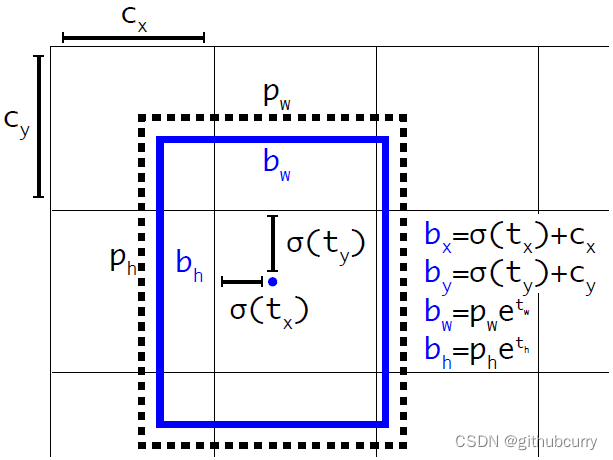
或者参考下图,
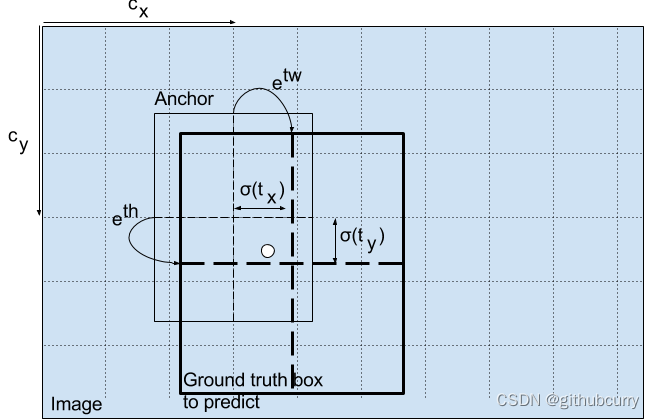
预测出包围盒中心点相对于网格单元左上角的相对坐标。
包围盒后处理
YOLO v3 模型的输出并没有直接给出包含目标的包围盒,而是包含所有网格单元对应结果的张量,因此需要一些后处理步骤来获得结果。
首先,需要根据阈值和模型输出的目标置信度来淘汰一大批包围盒。而剩下的包围盒中很可能有好几个围绕着同一个目标,因此还需要继续淘汰。这时候就要用到非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以认为求局部最优解。用在此处的基本思路就是选择目标置信度最大的包围盒,然后排除掉与之 IoU 大于某个阈值的附近包围盒。
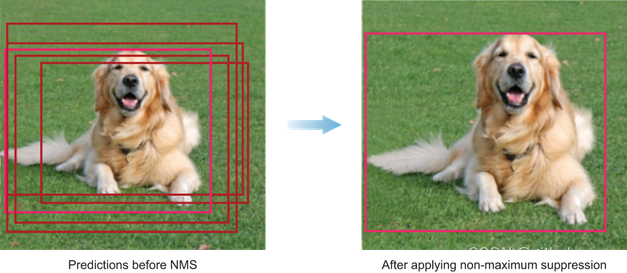
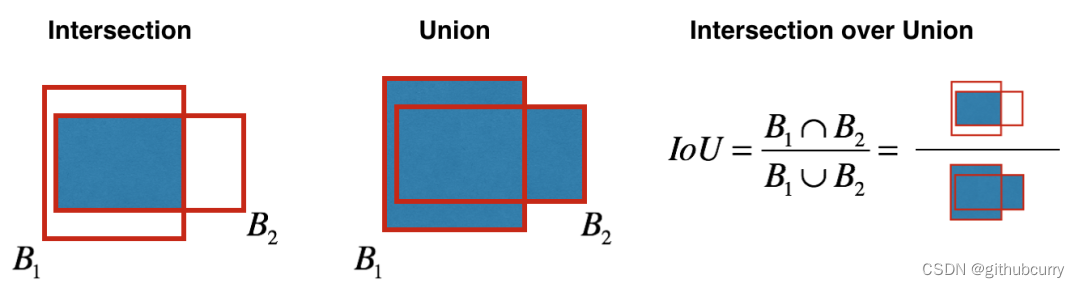
而两个包围盒的 IoU 计算如下,
损失函数
由于网络的输出值比较多,因此损失函数也具有很多项,但总体还是清晰的,这里不作展开。

代码
网上基于 PyTorch或者 TF等库的 YOLO v3 实现版本很多,可以直接拿来训练使用。下面是网上随手下载的几个图像的测试结果,看着效果还可以。


总结
先回顾下面这个图,看看是否了解每个步骤的含义。
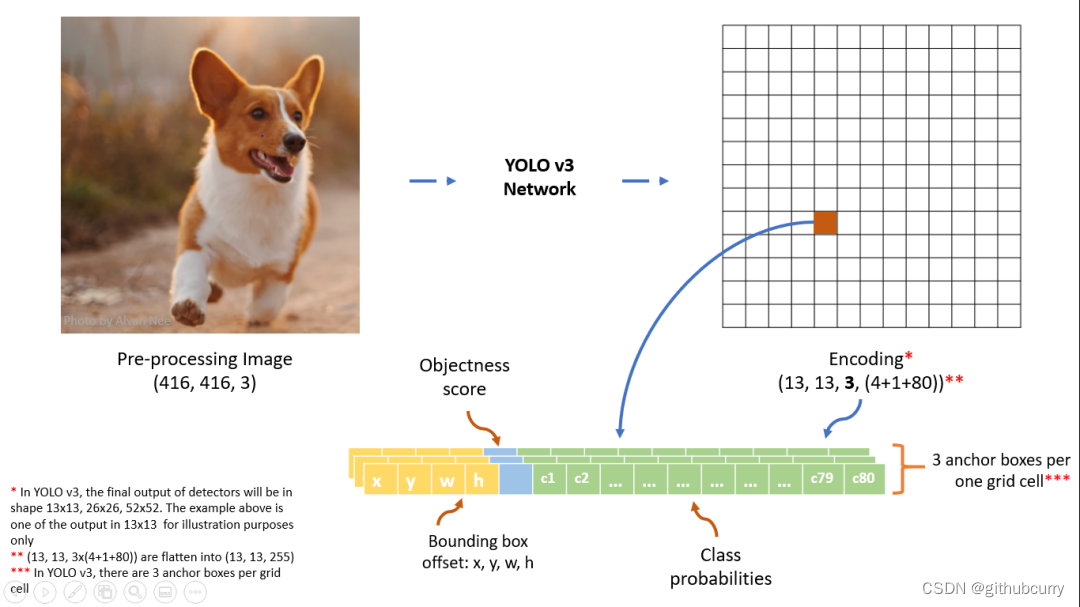
然后再用一个图来总结一下流程,
接下来根据输出的目标置信度淘汰一大批包围盒,在使用非极大值抑制继续淘汰一批,最后剩下检测到的目标,下图是这些步骤的简化版本演示图。