Faster ILOD:Incremental Learning for Object Detectors based on Faster RCNN
Faster ILOD:基于Faster RCNN的目标检测器增量学习
论文地址:https://arxiv.org/pdf/2003.03901.pdf
代码地址:无
目录
Abstract
1 Introduction
2 Problem Formulation
3 Related Work
3.1 Knowledge Distillation
3.2 KD based Incremental Learning Method
4 Evaluation of Robustness of RPN to In- cremental Object Detection
5 Faster ILOD for Robust Incremental Object Detection
5.1 Object Detection Network
5.2 Multi-Network Adaptive Distillation
6 Experiments
6.1 Dataset and Evaluation Metric
6.2 Implementation Details
6.3 Experiments on VOC Dataset
6.4 Experiments on COCO Dataset
6.5 Discussions
6.6 Evaluations on Detection Speed
7 Conclusion
Abstract
The human vision and perception system is inherently incremental where new knowledge is continually learned over time whilst existing knowledge is retained. On the other hand, deep learning networks are ill-equipped for incremental learning. When a well-trained network is adapted to new categories, its performance on the old categories will dramatically degrade. To address this problem, incremental learning methods have been explored which preserve the old knowledge of deep learning models. However, the state-of-the-art incremental object detector employs an external fixed region proposal method that increases overall computation time and reduces accuracy comparing to Region Proposal Network (RPN) based object detectors such as Faster RCNN. The purpose of this paper is to design an efficient end-to-end incremental object detector using knowledge distillation. We first evaluate and analyze the performance of the RPN-based detector with classic distillation on incremental detection tasks. Then, we introduce multi-network adaptive distillation that properly retains knowledge from the old categories when fine-tuning the model for new task. Experiments on the benchmark datasets, PASCAL VOC and COCO, demonstrate that the proposed incremental detector based on Faster RCNN is more accurate as well as being 13 times faster than the baseline detector.
人类的视觉和感知系统本质上是递增的,随着时间的推移不断学习新知识,同时保留现有知识。另一方面,深度学习网络不适合增量学习。当一个训练好的网络适应新的类别时,它在旧类别上的性能将显著降低。为了解决这个问题,人们探索了增量学习方法,这些方法保留了深度学习模型的旧知识。然而,与基于区域建议网络(RPN)的目标检测器(如Faster RCNN)相比,最先进的增量目标检测器采用了外部固定区域建议方法,该方法增加了总体计算时间并降低了精度。本文的目的是利用知识蒸馏技术设计一种高效的端到端增量目标检测器。我们首先评估和分析了基于RPN的检测器在增量检测任务中的性能。然后,我们引入多网络自适应蒸馏,在为新任务微调模型时适当保留旧类别的知识。在基准数据集PASCAL VOC和COCO上的实验表明,基于Faster RCNN的增量检测器的精度更高,比基线检测器快13倍。
1 Introduction
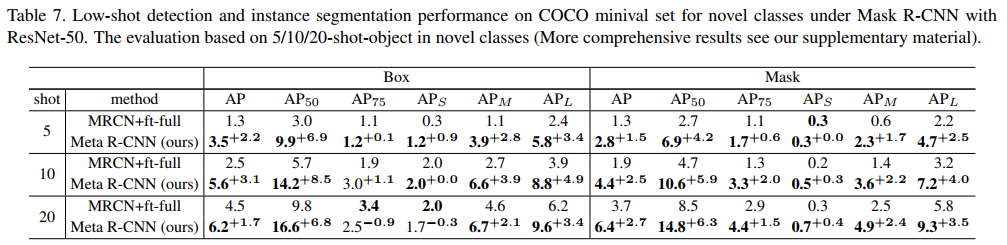
Benefiting from the rapid development of deep learning models, the performance of object detectors has increased dramatically over the years. However, the gap between state-of-the-art performance and the human visual system is still huge. One of the main obstacles is incrementally learning new tasks in the dynamic real-world where new categories of interest can emerge over time. For example, in the pathology area, new sub-types of disease patterns are identified over time due to the continued growth in our knowledge and understanding. An ideal disease pattern detection system should be able to learn a new subtype of disease from the pathology images without losing the ability to detect old disease sub-types. Humans can learn to recognize new categories without forgetting previously learned knowledge. However, when state-of-theart object detectors are fine-tuned for new tasks, they often fail on the previously trained tasks — a problem called catastrophic forgetting (Goodfellow et al., 2014; McCloskey and Cohen, 1989). Figure 1 shows an example of this problem on the PASCAL VOC dataset (Everingham et al., 2010). The normal training shown in Figure 1 is the conventional way to make a detector work well on all tasks — this requires the model to be trained on labeled data from both the old and new tasks. Unfortunately, this retraining procedure is both time-consuming and computationally expensive. This method also requires access to all of the data for all tasks which is quite impractical in many real-life applications due to a variety of reasons. The old training data may be inaccessible as it may have been lost or corrupted, or perhaps it is simply too large, or there may be licensing or distribution issues.
得益于深度学习模型的快速发展,近年来,目标检测器的性能有了显著提高。然而,最先进的模型表现与人类视觉系统之间的差距仍然很大。主要障碍之一是在动态的现实世界中逐步学习新任务,随着时间的推移,新的兴趣类别可能会出现。例如,在病理学领域,由于我们的知识和理解不断增长,随着时间的推移,新的疾病亚型被识别出来。理想的疾病模式检测系统应该能够从病理图像中学习新的疾病亚型,而不丧失检测旧疾病亚型的能力。人类可以学会识别新的类别,而不会忘记以前学到的知识。然而,当对最先进的目标检测器进行微调以适应新任务时,它们往往无法完成先前训练的任务——这一问题称为灾难性遗忘(Goodfello等人,2014年;McCloskey和Cohen,1989年)。图1显示了PASCAL VOC数据集上该问题的示例(Everingham等人,2010)。图1所示的正常训练是使检测器在所有任务上都能正常工作的常规方法——这要求模型在新旧任务的标记数据上进行训练。不幸的是,这种再训练过程既耗时又计算昂贵。由于各种原因,这种方法还需要访问所有任务的所有数据,这在许多实际应用程序中非常不切实际。旧的训练数据可能无法访问,因为它可能已丢失或损坏,或者可能太大,或者可能存在许可或分发问题。
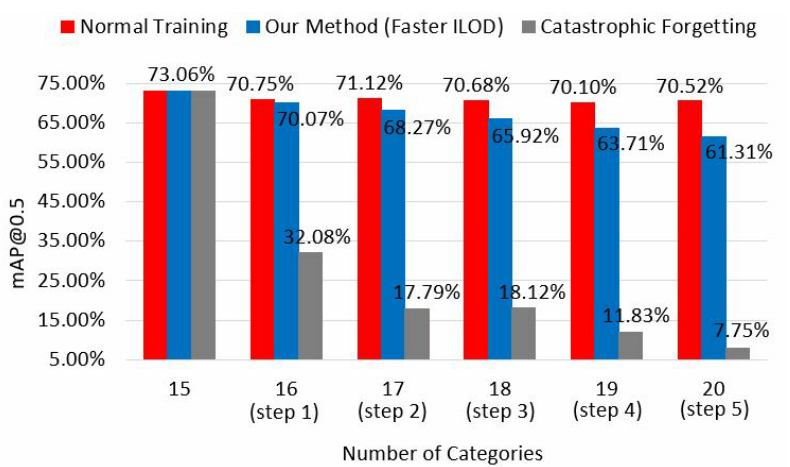
Figure 1: An example of incremental object detection. The model is first trained on 15 categories of the PASCAL VOC dataset followed by the addition of 1 new class in each of 5 steps. During training, only annotations for the current learning classes are provided and all other class objects are ignored. Normal training retrains the model from scratch with all the available data (old and new) which gives the best possible performance. Catastrophic forgetting is what happens when fine-tuning the old class model with just the new class data. Our Faster ILOD method dramatically alleviates the forgetting problem when training on the new class data only. 增量目标检测的示例。该模型首先在PASCAL VOC数据集的15个类别上进行训练,然后在每5个步骤中添加1个新类。在训练期间,只提供当前学习类的注释,而忽略所有其他类目标。正常训练使用所有可用数据(旧数据和新数据)从头开始重新训练模型,从而提供最佳性能。灾难性遗忘是指仅使用新类数据微调旧类模型时发生的情况。我们更快的ILOD方法极大地缓解了仅在新类数据上进行训练时的遗忘问题。
In contrast to image classification where the input image only contains one class of objects, an image for object detection can contain multiple classes of objects. Under incremental object detection scenarios, the classes of objects in one image can come from both the new task and the old tasks. In practice, in incremental training of a previously trained detector for a specific new task, only annotations for the new object are provided and other objects are not annotated which may lead to missing annotations for the previously learned objects. Even if all of the old data is available for normal training, these data need to be re-annotated to contain labels about all classes for all incremental learning tasks learned so far. Figure 2 shows an example of the missing annotation problem. Therefore, compared to incremental classification, incremental detection is a more challenging task, since it not only needs to solve catastrophic forgetting, but also the missing annotations for the old classes in the new data.
与输入图像仅包含一类目标的图像分类不同,用于目标检测的图像可以包含多类目标。在增量目标检测场景下,一幅图像中的目标类可以来自新任务和旧任务。实际上,在针对特定新任务对先前训练过的检测器进行增量训练时,仅提供新目标的注释,而不对其他目标进行注释,这可能导致先前学习过的目标缺少注释。即使所有旧数据都可用于正常训练,这些数据也需要重新注释,以包含迄今为止学习的所有增量学习任务的所有类的标签。图2显示了缺少注释问题的示例。因此,与增量分类相比,增量检测是一项更具挑战性的任务,因为它不仅需要解决灾难性遗忘问题,还需要解决新数据中旧类的缺失注释问题。
Figure 2: An example of the missing annotation problem for incremental object detection (Shmelkov et al., 2017). The model is trained to incrementally learn two tasks: detect human objects and horse objects. First, we label all human objects in the training images for task 1 and use them to train the model. Then, we label all horse objects in the training images for task 2 and use them to train the model. If the training images for task 2 also contain human objects, the labels for them are not provided.增量目标检测的缺失注释问题示例(Shmelkov等人,2017)。该模型经过训练,可以逐步学习两个任务:检测人体和马。首先,我们在任务1的训练图像中标记所有人类目标,并使用它们来训练模型。然后,我们为任务2的训练图像中的所有马对象添加标签,并使用它们来训练模型。如果任务2的训练图像也包含人体目标,则不提供其标签。
To bridge the performance gap between catastrophic forgetting and normal full dataset training, Shmelkov et al. (2017) proposed an incremental object detector using knowledge distillation (Hinton et al., 2015). Their method is based on the largely superseded Fast RCNN (Girshick, 2015) detector which uses an external fixed proposal generator rather than a CNN, so training is not end-to-end. To avoid missing annotation for region proposals, Shmelkov et al. (2017) deliberately chose the external fixed proposal generator of Fast RCNN, so that the proposals would be agnostic to the object categories. The more recent Faster RCNN (Ren et al., 2015) uses a trainable Region Proposal Network (RPN) to boost both accuracy and speed. The RPN-based methods are expected to be fragile to incremental learning, because the unlabeled old class objects are treated as background during retraining of the RPN detector which may adversely affect the RPN proposals on the old classes. In other words, if the retrained RPN is no longer able to detect the old classes by outputting proposals, there is simply no possibility of classifying them.
为了弥补灾难性遗忘和正常完整数据集训练之间的性能差距,Shmelkov等人(2017年)提出了一种使用知识蒸馏的增量目标检测器(Hinton等人,2015年)。他们的方法基于基本上被取代Fast RCNN(Girshick,2015)检测器,该检测器使用外部固定提议生成器而不是CNN,因此培训不是端到端的。为了避免遗漏区域建议框的标注,Shmelkov et al.(2017)故意选择Fast RCNN的外部固定建议框生成器,以便建议框与目标类别无关。最近的Faster RCNN(Ren等人,2015年)使用可训练区域建议网络(RPN)来提高准确性和速度。基于RPN的方法对于增量学习来说是脆弱的,因为在RPN检测器的重新训练期间,未标记的旧类目标被视为背景,这可能会对旧类上的RPN建议产生不利影响。换句话说,如果再训练的RPN不再能够通过输出建议来检测旧类,则根本不可能对它们进行分类。
To address this challenge of incremental learning for RPN-based detectors, we first analyze the capability of RPN on the missing annotation problem for incremental detection. Then, we propose an incremental framework, Faster ILOD, using multi-network adaptive distillation to improve the performance.
为了解决基于RPN的检测器增量学习的挑战,我们首先分析了RPN在增量检测缺失注释问题上的能力。然后,我们提出了一个增量式的框架,更快的ILOD,使用多网络自适应蒸馏来提高性能。
The contributions of this paper are as follows:
• We find that due to its unique anchor selection scheme, in the incremental detection scenario, RPN has the capability to tolerate missing annotations for old class objects to some extent.
• Multi-network adaptive distillation is designed to further boost the accuracy of the proposed incremental object detector.
• Using Faster RCNN (Ren et al., 2015) as the fundamental network, we demonstrate the superior performance of our model on both the PASCAL VOC (Everingham et al., 2010) and COCO (Lin et al., 2014) datasets under several incremental detection settings.
• Our framework is generic and can be applied to any object detectors using the RPN.
本文的贡献如下:
•我们发现,由于其独特的锚框选择方案,在增量检测场景中,RPN能够在一定程度上容忍旧类目标缺少注释。
•多网络自适应蒸馏旨在进一步提高拟议增量目标检测器的精度。
•使用Faster RCNN(Ren et al.,2015)作为基本网络,我们在几种增量检测设置下,在PASCAL VOC(Everingham et al.,2010)和COCO(Lin et al.,2014)数据集上展示了我们模型的卓越性能。
•我们的框架是通用的,可以应用于使用RPN的任何目标检测器。
2 Problem Formulation
Incremental learning for object detection consists of S incremental steps. In each incremental step, only the batch of training data for the new classes (Cn) is accessible. Given an object detection model that is previously trained using images from certain old classes (Co), incremental object detection is the task of retraining the model to maintain the detection of the old classes (Co) whilst detecting the new classes (Cn). We refer to the original model as the old model (teacher model) and the retrained model as the new model (student model). In multi-step incremental detection scenarios (S > 1), for each step, all categories that were trained during any previous steps are called the old classes. In this paper, we follow the protocol used by Shmelkov et al. (2017). More specifically, in this paper, we target the challenging real-life incremental detection scenarios as follows:
用于目标检测的增量学习由S个增量步骤组成。在每个增量步骤中,只能访问新类(Cn)的一批训练数据。给定一个以前使用来自某些旧类(Co)的图像训练的目标检测模型,增量对象检测的任务是重新训练该模型,以在检测新类(Cn)的同时保持旧类(Co)的检测。我们将原始模型称为旧模型(教师模型),将再训练模型称为新模型(学生模型)。在多步骤增量检测场景(S>1)中,对于每个步骤,在任何先前步骤中训练的所有类别都称为旧类。在本文中,我们遵循Shmelkov等人(2017)使用的协议。更具体地说,在本文中,我们针对具有挑战性的现实生活增量检测场景,如下所示:
• In each incremental training step, only training data for the new classes is available; no representative data exemplars of the old classes from previous incremental steps are available.
• Objects from the old classes may appear in the training images of the new detection tasks; however, the annotations for these old class objects are not provided.
• The retrained detector should have the capability to detect objects from both the new classes and the old classes trained in all previous incremental steps.
•在每个增量培训步骤中,只有新类别的训练数据可用;以前增量步骤中的旧类的代表性数据示例不可用。
•新检测任务的训练图像中可能会出现来自旧类的目标;但是,没有提供这些旧类目标的注释。
•重新训练的探测器应能够从所有先前增量步骤中训练的新类和旧类中检测目标。
3 Related Work
Our work focuses on applying Knowledge Distillation (KD) to RPN-based object detectors to improve both speed and accuracy in incremental scenarios. In this section, we introduce the background of KD followed by a discussion about its application to incremental learning scenarios.
我们的工作重点是将知识蒸馏(KD)应用于基于RPN的目标检测器,以提高增量场景中的速度和准确性。在本节中,我们将介绍KD的背景,然后讨论其在增量学习场景中的应用。
3.1 Knowledge Distillation
KD was first introduced by Hinton et al. (2015) for classification model compression. Model compression transfers the knowledge learned from a high performance cumbersome source model to a small target model. The intuition behind KD is that the relative probabilities of incorrect answers can reveal the potential relations between different categories. For example, in handwritten digit recognition, 7 is more likely to be confused with 1 than 8. Thus, during model compression, it is advantageous to train the target model by outputs from the source model instead of ground truth labels. Romero et al. (2015) proposed hint learning to improve the performance of model compression which distills information from feature maps of the source model. Chen et al. (2017) adopted both the distillation method of Hinton et al. (2015) and hint learning of Romero et al. (2015) to detection model compression. Heo et al. (2019) proposed a pre-ReLU feature distillation method to improve the distillation quality for model compression.
KD首先由Hinton等人(2015)引入,用于分类模型压缩。模型压缩将从高性能、繁琐的源模型学到的知识转移到小目标模型。KD的关键在于,错误答案的相对概率可以揭示不同类别之间的潜在关系。例如,在手写数字识别中,7比8更容易与1混淆。因此,在模型压缩期间,通过源模型的输出而不是groundtruth标签来训练目标模型是有利的。Romero et al.(2015)提出了提示学习,以提高从源模型的特征映射中提取信息的模型压缩性能。Chen et al.(2017)采用Hinton et al.(2015)的蒸馏方法和Romero et al.(2015)的提示学习来检测模型压缩。Heo等人(2019)提出了一种pre-ReLU特征蒸馏方法,以提高模型压缩的蒸馏质量。
3.2 KD based Incremental Learning Method
As the KD method has the capability to transfer the knowledge of one model to another model, it has become one of the most commonly used tools for incremental learning. When applying KD to incremental learning, the old model output for new data is combined with its ground truth information to train the new model. We first discuss related methods for incremental classification followed by methods for incremental detection.
由于KD方法能够将一个模型的知识转移到另一个模型,因此它已成为增量学习最常用的工具之一。将KD应用于增量学习时,将新数据的旧模型输出与其基础真值信息相结合,训练新模型。我们首先讨论了增量分类的相关方法,然后讨论了增量检测的方法。
Li and Hoiem (2017) first applied KD to incremental learning and built an incremental classifier called LwF. The LwF method does not require any old data to be stored and uses KD as an additional regularization term on the loss function to force the new model to follow the behavior of the old model on old tasks. Zhou et al. (2019) proposed a multi-model distillation method called M2KD which directly matches the category outputs of the current classification model with those of the corresponding old models. Mask based pruning is used to compress the old models in M2KD. Rebuffi et al. (2017) introduced a KD-based incremental classification method called iCaRL. iCaRL stores some old data by selecting representative exemplars from each of the old classes based on herding. The stored old exemplars and new data are combined to train the new model. However, as only limited exemplars are stored, there is a prediction bias towards the new classes due to data size imbalance between the old and new classes. Castro et al. (2018) kept all final classification layers during incremental learning for distillation to alleviate this data imbalance. Wu et al. (2019a) proposed using a few balanced old and new data batches to train additional two-parameter offset for the model output to remove the bias.
Li和Hoiem(2017)首先将KD应用于增量学习,并构建了一个称为LwF的增量分类器。LwF方法不需要存储任何旧数据,并使用KD作为损失函数的附加正则化项,以强制新模型在旧任务上遵循旧模型的行为。Zhou等人(2019)提出了一种称为M2KD的多模型蒸馏方法,该方法将当前分类模型的类别输出与相应旧模型的类别输出直接匹配。在M2KD中使用基于掩码的剪枝来压缩旧模型。Rebuffi等人(2017年)介绍了一种基于KD的增量分类方法,称为iCaRL。iCaRL通过基于羊群效应从每个旧类中选择具有代表性的样本来存储一些旧数据。将存储的旧样本和新数据结合起来训练新模型。然而,由于只存储有限的示例,由于新旧类之间的数据大小不平衡,因此存在对新类的预测偏差。Castro等人(2018年)在蒸馏增量学习期间保留所有最终分类层,以缓解数据不平衡。Wu等人(2019a)建议使用一些平衡的新旧数据批次来训练模型输出的额外两个参数偏移量,以消除偏差。
In contrast to classification, research on incremental object detection is quite limited in the literature. Shmelkov et al. (2017) adapted the incremental classification method LwF of (Li and Hoiem, 2017), and proposed an incremental object detector where no old data is available. In this paper, we call their method Incremental Learning Object Detector (ILOD). As ILOD is based on the Fast RCNN (Girshick, 2015) detector, it uses an external proposal generator such as EdgeBox (Zitnick and Dollár, 2014) or MCG (Arbeláez et al., 2014) to generate region proposals. Shmelkov et al. (2017) deliberately chose the external fixed proposal generator of Fast RCNN to ensure that proposals would be agnostic to object categories. In our experiments, we show that our proposed method can perform well on more the efficient RPN-based detectors such as Faster RCNN (Ren et al., 2015).
与分类相比,增量目标检测的研究在文献中相当有限。Shmelkov等人(2017)采用了LwF的增量分类方法(Li和Hoiem,2017),并在没有旧数据的情况下提出了一种增量目标检测器。在本文中,我们称他们的方法为增量学习目标检测器(ILOD)。由于ILOD基于快速RCNN(Girshick,2015)检测器,它使用外部建议框生成器,如EdgeBox(Zitnick and Dollár,2014)或MCG(Arbeláez等人,2014)生成区域建议框。Shmelkov等人(2017年)故意选择Fast RCNN的外部固定建议框生成器,以确保建议框与目标类别无关。在我们的实验中,我们表明,我们提出的方法可以在更高效的基于RPN的检测器上表现良好,例如Faster RCNN(Ren等人,2015)。
Hao et al. (2019) proposed an end-to-end incremental object detector. In their experiments, they divided the data classes into multiple class groups and trained their model to incrementally learn the class groups. For both training and testing of each class group, they specifically ignored all images that contain objects from multiple class groups. This process artificially ensures that the training images for the new classes do not contain any old objects and thus avoids the missing annotation problem. However, in real-life applications, there is a high likelihood that the input image may contain objects from both the old and new classes
Hao等人(2019)提出了一种端到端增量目标检测器。在他们的实验中,他们将数据类划分为多个类组,并训练他们的模型以逐步学习类组。对于每个类组的训练和测试,他们特别忽略了包含来自多个类组的目标的所有图像。此过程人为地确保新类的训练图像不包含任何旧目标,从而避免缺少注释的问题。然而,在实际应用中,输入图像很可能包含来自旧类和新类的目标
Chen et al. (2019) also had a similar motivation and proposed a distillation method for incremental object detection. However, their proposed method is only evaluated on the VOC dataset over three settings without comparison to the state-of-the-art method. Moreover, the experimental results are not clearly presented with specific accuracy in two settings. Li et al. (2019) proposed a one-stage incremental object detector based on RetinaNet (Lin et al., 2017). In their experiments, they did not mention how they handle the annotations for old classes on new data and they only performed one-step incremental detection on the VOC dataset.
Chen等人(2019)也有类似的想法,提出了一种用于增量目标检测的蒸馏方法。然而,他们提出的方法仅在三种设置下的VOC数据集上进行评估,而没有与最先进的方法进行比较。此外,在两种情况下,实验结果并没有以特定的准确度清晰地呈现出来。Li等人(2019年)提出了一种基于RetinaNet的单级增量目标检测器(Lin等人,2017年)。在他们的实验中,他们没有提到如何处理新数据上旧类的注释,他们只对VOC数据集执行一步增量检测。
In contrast to the previous works, we target designing a high performance incremental object detector for reallife applications where new task images may also contain objects from the old classes, but the annotations for the old classes are not present. In addition, we perform experiments for both one-step and multi-step incremental learning on two detection benchmark datasets — PASCAL VOC (Everingham et al., 2010) and COCO (Lin et al., 2014).
与以前的工作不同,我们的目标是为现实生活中的应用程序设计一个高性能的增量目标检测器,其中新任务图像可能也包含来自旧类的对象,但不存在旧类的注释。此外,我们在两个检测基准数据集(PASCAL VOC(Everingham et al.,2010)和COCO(Lin et al.,2014)上进行了一步和多步增量学习实验。
4 Evaluation of Robustness of RPN to In- cremental Object Detection
For supervised learning, correct annotation is very important to guarantee the performance of the trained model. Thus, some previous literature (Hao et al., 2019; Shmelkov et al., 2017) assumed that during incremental training, the missing annotations for the old class objects would adversely affect RPN performance. Based on this assumption, researchers have adopted several methods to avoid this problem. Shmelkov et al. (2017) used the fixed external proposal generator of Fast RCNN to acquire proposals agnostic to categories. Hao et al. (2019) carefully chose the training data to avoid old class objects appearing in new class data.
对于监督学习,正确的标注对于保证训练模型的性能非常重要。因此,一些以前的文献(Hao等人,2019年;Shmelkov等人,2017年)认为,在增量训练期间,旧类目标缺少注释会对RPN性能产生不利影响。基于这一假设,研究人员采取了几种方法来避免这一问题。Shmelkov等人(2017年)使用Fast RCNN的固定外部建议框生成器获取与类别无关的建议框。Hao等人(2019)仔细选择了训练数据,以避免旧类目标出现在新类数据中。
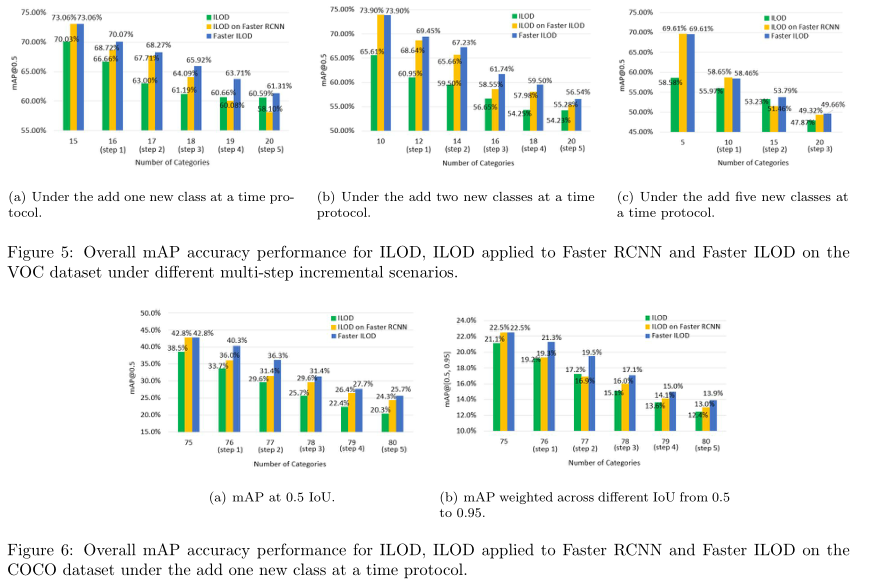
Before designing our own framework, we first evaluate how the RPN network behaves during incremental learning. To that end, we applied the KD method in ILOD (Shmelkov et al., 2017) to the Faster RCNN (Ren et al.2015) detector and followed the same training strategy to train the model. The training strategy is described in detail in Section 6. In all of our experiments, ILOD applied to Faster RCNN outperforms the original ILOD method due largely to the underlying superiority of Faster RCNN. More specifically, according to Table 1, for onestep incremental experiments on the VOC dataset, under adding 1, 5 and 10 classes protocol, ILOD applied to Faster RCNN outperforms the original ILOD by 0.45%, 3.63% and 0.11%, respectively.
在设计我们自己的框架之前,我们首先评估RPN网络在增量学习期间的行为。为此,我们将ILOD(Shmelkov et al.,2017)中的KD方法应用于 Faster RCNN(Ren et al.2015)检测器,并遵循相同的训练策略来训练模型。第6节详细描述了训练策略。在我们的所有实验中,应用于 Faster RCNN的ILOD优于原始ILOD方法,这主要是由于 Faster RCNN的潜在优势。更具体地说,根据表1,对于VOC数据集上的一步增量实验,在添加1、5和10类协议下,应用于 Faster RCNN的ILOD分别比原始ILOD高出0.45%、3.63%和0.11%。
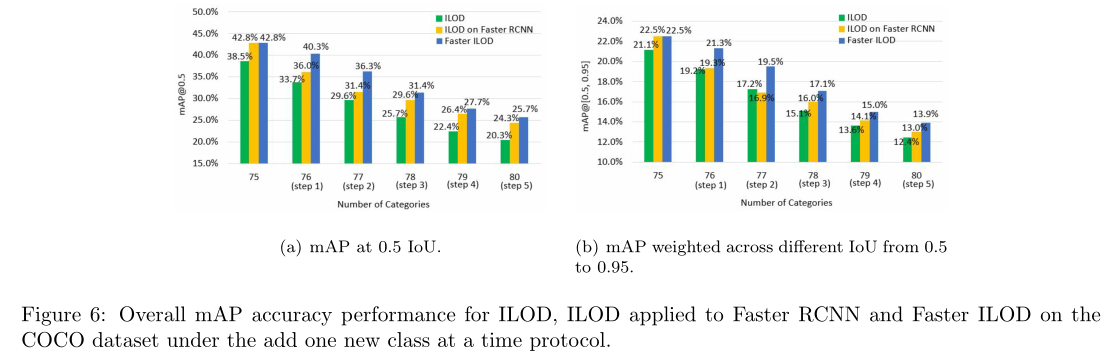
 According to Table 2, for one-step incremental experiments on the COCO dataset, under adding 5, 10 and 40 classes protocol, ILOD applied to Faster RCNN outperforms original ILOD by 4.1%, 3.3% and 3.0%, respectively at 0.5 IoU. According to Figure 5, for multi-step incremental experiments on the VOC dataset, under each time adding 1, 2 and 5 classes protocol, ILOD applied to Faster RCNN outperforms original ILOD by an average 1.32%, 4.11% and 0.79%, respectively. According to Figure 6, for multi-step incremental experiments on the COCO dataset, under each time adding 1 class protocol, ILOD applied to Faster RCNN outperforms the original ILOD by an average 3.2% at 0.5 IoU. In summary, unlike what was assumed by Shmelkov et al. (2017) and Hao et al. (2019), we see that, the performance of Faster RCNN is not greatly affected in the case of incremental learning where the annotations of old classes are not provided in the new data.
According to Table 2, for one-step incremental experiments on the COCO dataset, under adding 5, 10 and 40 classes protocol, ILOD applied to Faster RCNN outperforms original ILOD by 4.1%, 3.3% and 3.0%, respectively at 0.5 IoU. According to Figure 5, for multi-step incremental experiments on the VOC dataset, under each time adding 1, 2 and 5 classes protocol, ILOD applied to Faster RCNN outperforms original ILOD by an average 1.32%, 4.11% and 0.79%, respectively. According to Figure 6, for multi-step incremental experiments on the COCO dataset, under each time adding 1 class protocol, ILOD applied to Faster RCNN outperforms the original ILOD by an average 3.2% at 0.5 IoU. In summary, unlike what was assumed by Shmelkov et al. (2017) and Hao et al. (2019), we see that, the performance of Faster RCNN is not greatly affected in the case of incremental learning where the annotations of old classes are not provided in the new data.
根据表2,对于COCO数据集上的一步增量实验,在添加5、10和40类情况下,应用于Faster RCNN的ILOD在0.5 IoU时分别比原始ILOD高4.1%、3.3%和3.0%。根据图5,对于VOC数据集上的多步骤增量实验,在每次添加1、2和5类协议下,应用于更快RCNN的ILOD分别比原始ILOD平均高出1.32%、4.11%和0.79%。根据图6,对于COCO数据集上的多步骤增量实验,在每次添加1类协议下,应用于Faster RCNN的ILOD在0.5 IoU下的平均性能优于原始ILOD 3.2%。总之,与Shmelkov et al.(2017)和Hao et al.(2019)的假设不同,我们发现,在增量学习的情况下,在新数据中没有提供旧类注释的情况下,Faster RCNN的性能不会受到很大影响。

Surprisingly, the RPN network is relatively robust towards missing annotations. This behavior has also been observed by Wu et al. (2019b). In their experiments, after dropping 30% of the annotations, the performance of Faster RCNN only decreases by 5% (Wu et al., 2019b). The task of RPN is to take the features of an image as input and output a set of category agnostic possible object proposals. To that end, the RPN network randomly samples 256 anchors in an image to train a binary classifier, where the sampled positive and negative anchors have a ratio of up to 1:1 (Ren et al., 2015). An anchor is labeled as positive if it has the highest IoU overlap with a ground truth bounding box or the IoU overlap with a ground truth box is higher than a threshold (e.g. 0.7). An anchor is labeled as negative if the IoU overlap with any ground truth box is lower than a threshold (e.g. 0.3). Anchors that are neither positive nor negative do not contribute to RPN training. During incremental learning, the ground truth information for the old class objects are not provided. However, during RPN training, the method randomly samples 256 anchors from many thousands of anchors. This means that the risk of a selected negative anchor bounding a well localized old category object is quite low. Note further that a large proportion of the new class images may not contain any old class objects, so their annotations will be perfectly correct. It appears that the main problem of missing annotation is that the number of positive samples used to train the RPN is reduced, since the positive anchors for the old classes are missing.
令人惊讶的是,RPN网络对丢失的注释相对健壮。Wu等人(2019b)也观察到了这种行为。在他们的实验中,在删除30%的注释后,Faster RCNN的性能仅下降5%(Wu等人,2019b)。RPN的任务是将图像的特征作为输入并输出一组类别无关的可能目标。为此,RPN网络对图像中的256个锚随机采样以训练二值分类器,其中采样的正锚和负锚的比率高达1:1(Ren等人,2015)。如果锚点与groundtruth边界框的IoU重叠最高,或者与groundtruth框的IoU重叠高于阈值(例如0.7),则锚点标记为正。如果IoU与任何地面真值框的重叠低于阈值(例如0.3),则锚定标记为负。非正非负的锚框对RPN训练没有帮助。在增量学习过程中,不提供旧类目标的groundtruth信息。然而,在RPN训练期间,该方法从数千个锚中随机抽取256个锚。这意味着,选定的负锚点包围本地化良好的旧类别目标的风险非常低。进一步注意,大部分新类图像可能不包含任何旧类对象,因此它们的注释将是完全正确的。缺少注释的主要问题似乎是用于训练RPN的正样本数量减少,因为缺少旧类的正锚框。
Figure 3 shows an example to demonstrate the working principle for the RPN network. Three ratios (0.5, 1, 2) and five scales (2, 4, 8, 16, 32) are used for anchor generation. The anchor stride is set to 16. The example image has image size of 480 × 364 pixels, so 10350 anchors are generated. After filtering repeated and excessively small anchors, 8874 anchors are available to be used. With annotations for both the horse and person objects being provided, there are 26 positive anchors and 7307 negative anchors. Assume the task is to incrementally learn to detect horse (new class), and the person category is regarded as the old class. With only ground truth annotation for the horse object (new class) being provided, there are 22 positive (horse) anchors and 7476 negative anchors. Within these 7476 negative anchors, 4 positive anchors containing the person object (old class) are wrongly regarded as negative anchors. The false negative rate is just 0.05%. On the other hand, assume the task is to incrementally learn to detect a person (new class), and the horse category is regarded as the old class. With only ground truth annotation for the person object (new class) being provided, there are 4 positive (person) anchors and 8705 negative anchors. Within these 8705 negative anchors, 22 positive anchors containing the horse object (old class) are wrongly regarded as negative anchors. The false negative rate is now 0.25%.
图3显示了演示RPN网络工作原理的示例。锚框生成使用三个比率(0.5、1、2)和五个刻度(2、4、8、16、32)。锚定步幅设置为16。示例图像的图像大小为480×364像素,因此生成10350个锚。过滤重复和过小的锚框后,可使用8874个锚。提供了马和人目标的注释后,有26个正锚框和7307个负锚框。假设任务是逐步学习检测horse(新类),并且person类别被视为旧类。由于仅为马目标(新类)提供了groundtruth注释,因此有22个正(马)锚框和7476个负锚框。在这7476个负锚点中,包含person目标(旧类)的4个正锚点被错误地视为负锚点。假阴性率仅为0。05%. 另一方面,假设任务是递增地学习检测一个人(新类),马类被视为旧类。由于仅为person对象(新类)提供了groundtruth注释,因此有4个正(person)锚框和8705个负锚框。在这8705个负锚困困中,包含horse对象(旧类)的22个正锚框被错误地视为负锚框。假阴性率现在是0.25%.
Offsetting the adverse effects of missing annotation in the ILOD method, although distillation is only applied at the final outputs, the gradients of the distillation loss back-propagate through the entire network and will tend to encourage both the RPN and feature extractor to recognize old classes. This helps explain why RPN training is not catastrophically affected by the missing annotations — at least not over the range of our experiments, such as one and several-step incremental settings.
为了抵消ILOD方法中缺少注释的不利影响,尽管蒸馏仅应用于最终输出,但蒸馏损失的梯度会在整个网络中反向传播,并将倾向于鼓励RPN和特征提取器识别旧类。这有助于解释为什么RPN训练不会受到缺失注释的灾难性影响——至少不会超过我们的实验范围,例如一步和几步增量设置。
5 Faster ILOD for Robust Incremental Object Detection
There remains an accuracy gap between the ILOD method applied to RPN-based detectors and full data training. For example, according to Figure 5, for the VOC dataset, the full data training result is 69.50% but under multi-step incremental learning, all the results for ILOD applied to Faster RCNN are less than 60% accuracy. According to Figure 6, for the COCO dataset, the full data training result is 42.71% at 0.5 IoU but under multi-step incremental setting, the result for ILOD applied to Faster RCNN is only 24% at 0.5 IoU. In this section, we propose a novel multi-network adaptive distillation method to further narrow the gap. We first discuss the backbone network used for our model and then discuss each component of our proposed method.
应用于基于RPN的检测器的ILOD方法与完整数据训练之间存在精度差距。例如,根据图5,对于VOC数据集,完整数据训练结果为69.50%,但在多步骤增量学习下,应用于Faster RCNN的所有ILOD结果的准确度均低于60%。根据图6,对于COCO数据集,完整数据训练结果在0.5 IoU时为42.71%,但在多步增量设置下,应用于更快RCNN的ILOD结果在0.5 IoU时仅为24%。在本节中,我们提出了一种新的多网络自适应蒸馏方法,以进一步缩小差距。我们首先讨论用于我们的模型的主干网络,然后讨论我们提出的方法的每个部分。
5.1 Object Detection Network
Our proposed method for incremental object detection is illustrated by Figure 4. It comprises two models: a teacher model (Nte) and a student model (Nst). The teacher model is a frozen copy of the original detector which detects objects from the old categories (Cte= Co). The student model is the adapted model that needs to be trained to detect objects from both the old and new categories (Cst= Co∪ Cn). It is also initially a copy of the original detector but the number of outputs in the last layer is increased to predict for the additional new classes. We use Faster RCNN (Ren et al., 2015) as our backbone network. Faster RCNN is a two-stage end-to-end object detector which consists of three parts: (1) A Convolutional Neural Network (CNN) based feature extractor to provide features; (2) a Region Proposal Network (RPN) to produce regions of interest (RoIs); (3) a class-level classification and bounding box regression network (RCN) to generate the final prediction for each of the proposals from RPN (Chen et al., 2017). In order to create a high performance incremental object detector, it is important to properly account for all three components.
我们提出的增量目标检测方法如图4所示。它包括两个模型:教师模型(Nte)和学生模型(Nst)。教师模型是原始检测器的冻结副本,用于检测旧类别中的目标(Cte=Co)。学生模型是需要训练的适应模型,用于检测新旧类别中的目标(Cst= Co∪ Cn)。它最初也是原始检测器的副本,但最后一层的输出数量增加,以预测额外的新类。我们使用 Faster RCNN(Ren等人,2015)作为骨干网络。 Faster RCNN是一种两级端到端目标检测器,它由三部分组成:(1)基于卷积神经网络(CNN)的特征抽取器,用于提供特征;(2) 区域建议网络(RPN),用于产生感兴趣的区域(ROI);(3) 类级分类和边界框回归网络(RCN),用于根据RPN生成每个方案的最终预测(Chen等人,2017年)。为了创建高性能的增量目标检测器,必须正确考虑所有三个部分。
5.2 Multi-Network Adaptive Distillation
To make a model remember what it learned before, similar to ILOD (Shmelkov et al., 2017), we adapt knowledge distillation. But unlike ILOD which only performs one-step distillation at the final outputs, we perform multi-network distillation on the feature maps, RPN and RCN outputs. In addition, knowledge distillation is originally developed for model compression which only requires the preservation of learned knowledge. Incremental learning requires not only maintaining learned knowledge, but also learning new knowledge from the new classes. Thus, directly applying distillation loss to force the student model to follow the behavior of the teacher model will simply prevent new data learning. To solve this problem, we propose adaptive distillation which uses the teacher model outputs as a lower bound to adaptively distill old knowledge.
为了让模型记住以前学到的东西,类似于ILOD(Shmelkov等人,2017),我们采用了知识蒸馏。但与ILOD只在最终输出执行一步蒸馏不同,我们对特征映射、RPN和RCN输出执行多网络蒸馏。此外,知识蒸馏最初是为模型压缩而开发的,它只需要保存所学的知识。增量学习不仅需要保持所学知识,还需要从新课程中学习新知识。因此,直接应用蒸馏损失迫使学生模型遵循教师模型的行为将简单地阻止新的数据学习。为了解决这个问题,我们提出了一种自适应蒸馏算法,该算法以教师模型的输出作为下限,自适应地提取旧知识。
Feature Distillation: The desired feature extractor needs to provide features that are effective for both old and new categories. To build the desired feature extractor, we utilize normalized adaptive distillation with a L1loss. Specifically, all feature maps are normalized to obtain the corresponding zero-mean feature maps,˜Fte and˜Fst, from the teacher model and student model, respectively. For each activation in the feature map, we then check its value from the student model (˜fst∈˜Fst) with the corresponding value from the teacher model (˜fte∈˜Fte). If the teacher’s activation,˜fte, has a higher value, a loss is generated to force the student model to increase its value for this input, since this activation is important for the old classes. On the other hand, if the student’s activation,˜fst, has a higher value, the loss is zero since this activation is likely important for the new classes. The feature distillation loss is:
特征蒸馏:所需的特征提取程序需要提供对新旧类别都有效的特征。为了构建所需的特征提取器,我们使用了具有l1损失的归一化自适应蒸馏。具体地说,所有特征映射都被归一化,以分别从教师模型和学生模型获得相应的零均值特征映射![]() 和
和![]() 。对于特征图中的每个激活,我们然后从学生模型中检查其值
。对于特征图中的每个激活,我们然后从学生模型中检查其值![]() 与教师模型的相应值
与教师模型的相应值![]() 。如果教师的激活
。如果教师的激活![]() 具有更高的值,则会产生损失,迫使学生模型增加此输入的值,因为此激活对于旧类很重要。另一方面,如果学生的激活
具有更高的值,则会产生损失,迫使学生模型增加此输入的值,因为此激活对于旧类很重要。另一方面,如果学生的激活![]() 具有更高的值,则损失为零,因为该激活可能对新类别很重要。蒸馏损失:
具有更高的值,则损失为零,因为该激活可能对新类别很重要。蒸馏损失:
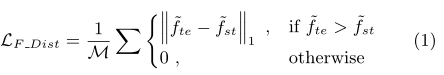
where te and st subscripts refer to teacher and student networks respectively and M is the total number of activation values in the feature map.
其中te和st下标分别指教师和学生网络,M是特征图中激活值的总数。
RPN Distillation: The desired RPN needs to provide proposals for objects from both new and old classes. Similar to feature distillation loss, we use the teacher model RPN output as a lower bound to force the student model to choose anchors according to both the training data from the new classes and the teacher model RPN output. In addition, the bounding box regression can provide incorrect values since the real valued regression output is unbounded and partially trained only at positive anchors. Inspired by the distillation method used for detection model compression by Chen et al. (2017), we use a threshold, T , to control regression. In our experiments, empirically we set T = 0.1. For RPN distillation, L2loss is used. Suppose N is the total number of anchors, q is the RPN classification output, and r is the RPN bounding box regression output. The RPN distillation loss is:
RPN蒸馏:所需的RPN需要为新类和旧类中的目标提供建议。与特征提取损失类似,我们使用教师模型RPN输出作为下界,迫使学生模型根据新类别的训练数据和教师模型RPN输出选择锚框。此外,边界框回归可能提供不正确的值,因为实值回归输出是无界的,并且仅在正锚点处进行部分训练。受Chen等人(2017)用于检测模型压缩的蒸馏方法的启发,我们使用阈值T来控制回归。在我们的实验中,我们根据经验设置T=0.1。对于RPN蒸馏,使用L2loss。假设N是锚的总数,q是RPN分类输出,r是RPN边界框回归输出。RPN蒸馏损失为:
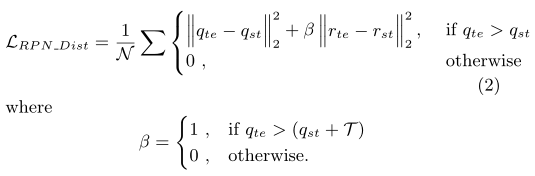
RCN Distillation: The desired RCN needs to predict each RoI for both old and new classes in an unbiased manner. We follow the method in ILOD (Shmelkov et al.,2017) to perform RCN distillation. More specifically, for each image, we randomly choose 64 out of 128 RoIs with the smallest background score according to the RPN output from the teacher model. Then these proposals are fed into the RCN of the student model and the final outputs of the teacher model are used as targets for the old classes. The outputs of student model on the new classes are not included in the RCN distillation. For each RoI classification output, p, we subtract the mean over the class dimension to get the zero-mean classification result, ˜ p. We use L2loss for the distillation. Let K be the total number of sampled RoIs, Cobe the number of old classes including background, and t be the bounding box regression result. The RCN distillation loss is then written as:
RCN蒸馏:所需的RCN需要以无偏的方式预测新旧类别的每个RoI。我们遵循ILOD(Shmelkov等人,2017年)中的方法进行RCN蒸馏。更具体地说,对于每幅图像,我们根据教师模型的RPN输出,从128个背景分数最小的ROI中随机选择64个。然后将这些建议框输入到学生模型的RCN中,并将教师模型的最终输出用作旧类别的目标。新课程的学生模型输出不包括在RCN中。对于每个RoI分类输出p,我们减去类维度上的平均值,得到零平均分类结果p。我们使用L2loss进行蒸馏。设K为采样ROI总数,Cobe为包含背景的旧类数,t为边界盒回归结果。然后将RCN蒸馏损失写为:
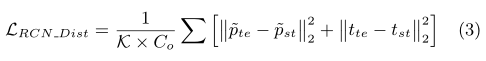
Total Loss Function: The overall loss (Ltotal) will be the weighted summation of the standard Faster R-CNN loss (Ren et al., 2015), feature distillation loss (1), RPN distillation loss (2), and RCN distillation loss (3). Hyperparameters λ1, λ2and λ3help to balance each loss term, and are empirically set to 1.
总损失函数:总损失(Ltotal)是标准Faster R-CNN损失(Ren等人,2015)、特征蒸馏损失(1)、RPN蒸馏损失(2)和RCN蒸馏损失(3)的加权总和。超参数λ1、λ2和λ3有助于平衡每个损失项,并根据经验设置为1。

6 Experiments
We call our proposed method Faster ILOD as it is designed to work with Faster RCNN. In this section, we compared our Faster ILOD method with the original ILOD method as well as ILOD applied to Faster RCNN.
我们称我们提出的方法为 Faster ILOD,因为它设计用于 Faster RCNN。在本节中,我们将我们的 Faster ILOD方法与原始ILOD方法以及应用于 Faster RCNN的ILOD进行了比较。
6.1 Dataset and Evaluation Metric
In our experiments, two detection benchmark datasets are used, PASCAL VOC 2007 (Everingham et al., 2010) and COCO 2014 (Lin et al., 2014). VOC 2007 comprises 10k images of 20 object categories — 5k for training and 5k for testing. COCO 2014 comprises 164k images of 80 object categories — 83k for training, 40k for validation and 41k for testing. For the evaluation metric, we use mean average precision (mAP) at 0.5 Intersection over Union (IoU) for both datasets and also use mAP weighted across different IoU from 0.5 to 0.95 for COCO. To validate our method, we have investigated several incremental settings for these two datasets, such as one-step and multi-step addition. The sequence of categories is arranged according to the category names in alphabetical order.
在我们的实验中,使用了两个检测基准数据集,PASCAL VOC 2007(Everingham et al.,2010)和COCO 2014(Lin et al.,2014)。VOC 2007包含20个对象类别的10k图像-5k用于训练,5k用于测试。COCO 2014包含80个目标类别的164k图像,其中83k用于培训,40k用于验证,41k用于测试。对于评估指标,我们使用两个数据集在0.5相交于联合(IoU)处的平均精度(mAP),也使用COCO在0.5到0.95之间的不同IoU上的mAP加权。为了验证我们的方法,我们研究了这两个数据集的几个增量设置,例如一步和多步加法。类别的顺序按照类别名称的字母顺序排列。
6.2 Implementation Details
The results for ILOD (Shmelkov et al., 2017) are generated using their public implementation. Edge-Boxes (Zitnick and Doll´ ar, 2014) is used to generate the external proposals. Faster ILOD and ILOD applied to Faster RCNN are implemented using PyTorch. For a fair comparison of our approach with ILOD (Shmelkov et al., 2017), we use the same backbone network (ResNet-50 (He et al., 2016)) and similar training strategy mentioned in their paper. In the first step of training, we set the learning rate to 0.001, decaying to 0.0001 after 30k iterations, and momentum is set to 0.9. The network is trained using 40k iterations for VOC and 400k iterations for COCO. In the following incremental steps, learning rate is set to 0.0001. The network is trained using 5k-10k iterations when only one class is added and the same number of iterations as the first step if multiple classes are added at once.
ILOD的结果(Shmelkov等人,2017年)是使用其公共实施生成的。边缘框(Zitnick和Doll'ar,2014)用于生成外部建议框。 Faster ILOD和应用于 Faster RCNN的ILOD是使用PyTorch实现的。为了将我们的方法与ILOD(Shmelkov等人,2017年)进行公平比较,我们使用了相同的主干网(ResNet-50(He等人,2016年))和他们论文中提到的类似训练策略。在训练的第一步中,我们将学习率设置为0.001,经过30k次迭代后衰减为0.0001,动量设置为0.9。网络使用40k迭代(VOC)和400k迭代(COCO)进行训练。在以下增量步骤中,学习率设置为0.0001。当只添加一个类时,网络使用5k-10k迭代进行训练,如果同时添加多个类,则迭代次数与第一步相同。
6.3 Experiments on VOC Dataset
Table 1 shows the results for one-step incremental settings when the number of new classes equals 1, 5 and 10, respectively. In all three settings, Faster ILOD is more accurate than both ILOD and ILOD applied to Faster RCNN. Under these settings, we also performed experiments on Faster ILOD without adaptive feature distillation to prove the efficiency of each part of our method. Compared to the experimental results for multi-step increments, we see the improvement is not significant in the one-step settings. This is likely because one-step increments require a small amount of fine-tuning on the old model and the catastrophic forgetting and missing annotation problems might not be significant, which provides little room for improvement. When we retrain the old model in the multiple incremental steps, the build-up of detection errors due to catastrophic forgetting and missing annotation are approximately exponential on the old classes. So this is a more difficult scenario.
表1显示了当新类的数量分别为1、5和10时,一步增量设置的结果。在所有三种设置中,Faster ILOD比应用于Faster RCNN的ILOD和ILOD更精确。在这些设置下,我们还对没有自适应特征提取的Faster ILOD进行了实验,以证明我们方法的每个部分的有效性。与多步增量的实验结果相比,我们发现在一步设置下,改进并不显著。这可能是因为一步增量需要在旧模型上进行少量微调,而灾难性的遗忘和注释缺失问题可能并不严重,这几乎没有改进的余地。当我们在多个增量步骤中重新训练旧模型时,由于灾难性遗忘和注释缺失导致的检测错误在旧类上近似呈指数增长。所以这是一个更困难的场景。

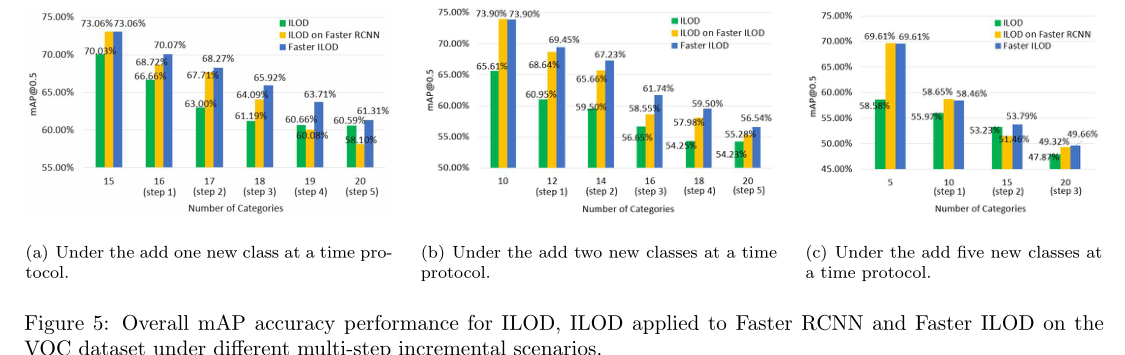
We have also investigated the results under multi-step incremental scenarios. Figure 5(a) shows the performance of Faster ILOD, ILOD and ILOD applied to Faster RCNN, when first training with 15 classes followed by the addition of 1 class for 5 steps. Observing from Figure 5(a), under the add one new class at a time protocol, Faster ILOD outperforms ILOD and ILOD applied to Faster RCNN in each incremental step and the average performance gain is 3.44% and 2.12% respectively. Figure 5(b) shows the performance of three models under the condition of first training with 10 classes followed by addition of 2 classes for 5 times. Under this incremental setting, Faster ILOD also performs best for all five incremental steps and the average accuracy improvement is 5.78% towards ILOD and 1.67% towards ILOD applied to Faster RCNN. Figure 5(c) shows the performance of three models under the condition of first training with 5 classes followed by addition of 5 classes for 3 times. Under this incremental scenario, Faster ILOD outperforms ILOD applied to Faster RCNN except the first step and always has better accuracy than ILOD. The average accuracy increase is 1.61% towards ILOD and 0.83% towards ILOD applied to Faster RCNN.
我们还研究了多步增量场景下的结果。图5(a)显示了Faster ILOD、ILOD和应用于Faster RCNN的ILOD的性能,当第一次使用15个类进行训练,然后添加1个类进行5个步骤时。从图5(a)中可以看出,在每次添加一个新类协议下,Faster ILOD在每个增量步骤中都优于ILOD和应用于Faster RCNN的ILOD,平均性能增益分别为3.44%和2.12%。图5(b)显示了三个模型在第一次训练(10节课)和第二次训练(5次)的情况下的性能。在这种增量设置下,对于所有五个增量步骤,Faster ILOD也表现得最好,平均精度提高为ILOD的5.78%,应用于Faster RCNN的ILOD的平均精度提高为1.67%。图5(c)显示了三个模型在第一次训练(5节课)和第三次增加5类的情况下的性能。在这种增量场景下,除第一步外,Faster ILOD优于应用于Faster RCNN的ILOD,并且总是比ILOD具有更好的精度。对于ILOD和Faster RCNN+ILOD的平均精度分别提高了1.61%和0.83%。
6.4 Experiments on COCO Dataset
For our experiments on the COCO dataset, we use train set and valminusminival set as our training data and minival set as our testing data. Table 2 shows the results under one-step incremental settings, where the number of new classes is 5, 10 and 40, respectively. Figure 6 shows the results for multi-step incremental detection under the add one new class at a time protocol. In both scenarios, Faster ILOD provides the best detection accuracy. In particular, under multi-step incremental detection shown in Figure 6, Faster ILOD outperforms ILOD and ILOD applied to Faster RCNN in all steps and has an average gain of 5.92% and 2.74% (1.88% and 1.53%) respectively at 0.5 IoU (weighted across different IoU from 0.5 to 0.95).
在COCO数据集上的实验中,我们使用训练集和最小值集作为训练数据,最小值集作为测试数据。表2显示了一步增量设置下的结果,其中新类的数量分别为5、10和40。图6显示了“一次添加一个新类”协议下多步骤增量检测的结果。在这两种情况下,Faster ILOD提供了最佳的检测精度。特别是,在图6所示的多步增量检测下,Faster ILOD在所有步骤中都优于应用于Faster RCNN的ILOD和ILOD,并且在0.5 IoU(在不同IoU之间从0.5到0.95加权)下,平均增益分别为5.92%和2.74%(1.88%和1.53%)。

6.5 Discussions
To explore how learning different categories affects the model performance on the same incremental setting, under the one-step incremental learning scenario, we performed the experiments on adding different categories on the VOC dataset. These experiments indicate that our method can always achieve improvements in different learning sequence. Table 3 shows the results for incrementally learning the new class (TV and aeroplane). It also shows the results for incrementally learning the more challenging person category. Comparing with other categories, incrementally learning person category is more challenging since ‘person’ objects often appear with many other category objects in one image. In VOC training data, there are 2008 out of 5011 images containing person objects. Within the 2008 training images, there are 3641 other objects (40.87% missing annotation) which belong to 19 old categories. As for person category, the amount of training data is large, the model is trained for 40,000 instead of 10,000 iterations for convergence. For all three different categories, our proposed Faster ILOD outperforms ILOD applied to Faster RCNN. According to Table 3, the improvement of our adaptive distillation method for person category is higher than aeroplane and TV categories which have fewer missing annotations (55 and 408, respectively) and fewer training data (238 and 256, respectively). Although the missing annotation percentage for TV category is high (60.40%), it only comes from 9 old categories.
为了探索在相同增量设置下学习不同类别对模型性能的影响,在一步增量学习场景下,我们在VOC数据集上进行了添加不同类别的实验。这些实验表明,我们的方法在不同的学习序列中总能取得改进。表3显示了增量学习新类别(电视和飞机)的结果。它还显示了增量学习更具挑战性的人员类别的结果。与其他类别相比,增量学习人员类别更具挑战性,因为“人员”目标通常与其他许多类别目标一起出现在一张图像中。在VOC训练数据中,5011张图像中有2008张包含人物对象。在2008年的训练图像中,有3641个其他对象(40.87%缺少注释),属于19个旧类别。对于人员类别,由于训练数据量大,模型训练次数由10000次迭代改为40000次迭代进行收敛。对于所有三种不同的类别,我们提出的Faster ILOD优于应用于Faster RCNN的ILOD。根据表3,我们针对人员类别的自适应蒸馏方法的改进程度高于飞机和电视类别,飞机和电视类别缺少注释(分别为55和408)和训练数据(分别为238和256)较少。虽然电视类别的缺失注释百分比较高(60.40%),但它仅来自9个旧类别。

In summary, for different categories, they will face different difficulty levels for incremental learning. We conjecture that the difficulty levels are related to three items: (1) the amount of training data; (2) the number of old categories co-occurring in the new training data; (3) the percentage of missing annotations in the training data. Therefore, the challenge of incremental learning is different under different incremental learning scenarios which leads to different accuracy improvements of our method.
总之,对于不同的类别,他们将面临不同的增量学习难度。我们推测难度水平与三个项目有关:(1)训练数据量;(2) 新训练数据中同时出现的旧类别的数量;(3) 训练数据中缺少批注的百分比。因此,在不同的增量学习场景下,增量学习的挑战是不同的,这导致了我们的方法的不同精度改进。
6.6 Evaluations on Detection Speed
As the original ILOD code is built in Tensorflow, to fairly compare the detection speeds for ILOD and Faster ILOD, we rebuilt ILOD on Pytorch. All experiments were performed on an NVIDIA Tesla V100 GPU. Average detection time per image of ILOD and Faster ILOD with ResNet-50 (He et al., 2016) on the VOC dataset is 1396.66 ms and 109.52 ms respectively. As ILOD relies on an external proposal generator to acquire proposals, the inference speed of ILOD is about 13 times slower than Faster ILOD due to the fixed proposal network.
由于最初的ILOD代码是在Tensorflow中构建的,为了公平地比较ILOD和 Faster IILOD的检测速度,我们在Pytorch上重建了ILOD。所有实验均在NVIDIA Tesla V100 GPU上进行。VOC数据集上每幅ILOD图像的平均检测时间为1396.66 ms,使用ResNet-50(He等人,2016年)的 Faster ILOD图像的平均检测时间为109.52 ms。由于ILOD依赖外部提案生成器获取建议框,由于固定的提案网络,ILOD的推理速度比 Faster ILOD慢13倍左右。
7 Conclusion
In this paper, we find that the RPN network is relatively robust towards missing annotations for old classes on incremental object detection and then propose a novel end-to-end framework, Faster ILOD. By adaptively distilling the old information in multi-networks, the proposed method aims to preserve the capabilities of the detector on old classes with limited affect towards the learning on new classes. Our method shows superior results on the PASCAL VOC and COCO datasets and outperforms the state-of-the-art incremental detector (Shmelkov et al., 2017) by a large margin in most cases
在本文中,我们发现RPN网络对增量目标检测中的旧类注释缺失具有相对鲁棒性,并提出了一种新的端到端框架,即Faster ILOD。通过在多个网络中自适应地提取旧信息,该方法旨在保持检测器在旧类上的能力,而对新类的学习影响有限。我们的方法在PASCAL VOC和COCO数据集上显示了优异的结果,并且在大多数情况下大大优于最先进的增量检测器(Shmelkov等人,2017)