深度学习论文: Task-Specific Context Decoupling for Object Detection及其PyTorch实现
Task-Specific Context Decoupling for Object Detection
PDF: https://arxiv.org/pdf/2303.01047.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
目标检测还需要定位出图像中每个感兴趣目标所在的位置和类别信息,但是定位和分类两个子任务对特征上下文的偏好并不一致,其中,定位需要更多的边界感知特征来准确地回归边界框,而分类任务则需要更多的语义上下文信息。两者之间存在一种空间不对齐(spatial misalignment)的问题。

通过实验,作者提出全连接头可能更适合分类任务,而卷积头则更适合定位任务,这是因为fc-head比conv-head具备更高的空间敏感性,具有更强的区分完整对象和部分对象的能力,但对于回归整个对象并不稳健。本文同样围绕这个方向提出了一种新颖的即插即用的特定于任务的上下文解耦头(Task-Specific COntext DEcoupling, TSCODE),通过进一步解开两个任务的特征编码来提升网络整体的性能。
2 Task-Specific Context Decoupling (TSCODE)
2-1 Motivation and Framework
现有的方法通常都是利用解耦头来为每个任务学习不同的特征上下文。如下

然而,不同head输入的特征却是相同的,作者认为这必然会导致分类和定位之间的仍然会有影响。于是,本文提倡对于分类任务应该生成空间粗糙但语义信息更强的的特征编码,而对于定位任务则需要提供包含更多边缘信息的高分辨率特征图,以更好地回归对象边界。

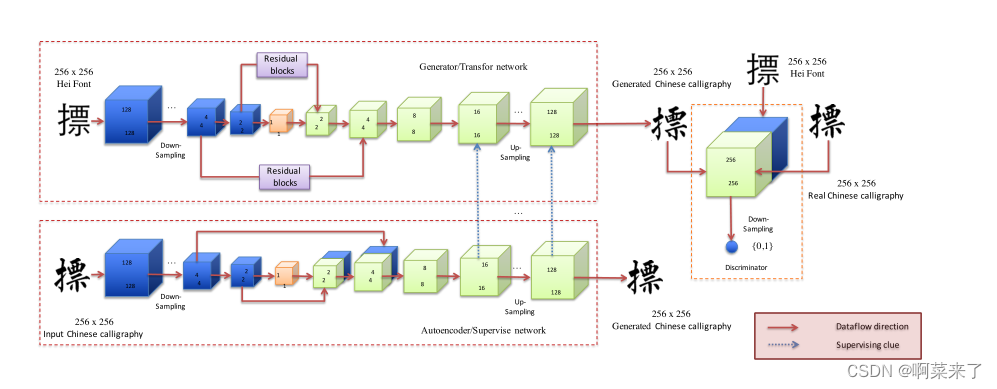
基于此提出如下架构

TSCODE整体的网络架构与常规的单阶段目标检测器并无多大差异,都是包含Backbone、Neck和Head。其中骨干网络充当特征提取器从输入图像生成多尺度特征图。随后通过类似于FPN或BiFPN之类的特征金字塔结构进行深、浅层的特征融合,最后再分别输入到头部进行相应的解码输出。需要注意的是,这里TSCODE接收来自中间三个层级输出的特征图,并生成用于分类和定位的解耦特征图。更重要的是,TSCODE是即插即用的,可以很容易地集成到大多数流行的检测器中,无论是Anchor-based还是Anchor-free。
2-2 Semantic Context Encoding for Classification
分类任务需要更丰富的上下文语义信息。而深层特征便是具备这一特性,因此,融合来自深层的特征,将丰富的语义信息嵌入到当前特征图中。

2-3 Detail-Preserving Encoding for Localization
回归任务则需要更丰富的空间细节信息,这一点浅层特征能够提供所需要的。因此,将浅层的信息引导回流至下一层特征图中。
此外,当前层级的特征以两个相邻层特征相关度较高,而其它层级的输出特征由于跨度太大可能会导致“语义鸿沟”(Semantic Gap),因此通常都会优先考虑相邻层的特征融合。这里借鉴了U-Net的思想完成了一次改造。

3 Experiments