paper:Localization Distillation for Dense Object Detection
code1:https://github.com/HikariTJU/LD
code2:https://github.com/open-mmlab/mmdetection/tree/master/configs/ld
背景
定位是目标检测中的一个基本问题,边界框回归是目前目标检测中最流行的定位方法,其中狄拉克Dirac delta分布是符合直觉的并且流行了多年。但是,定位模糊问题即物体无法通过边缘进行准确定位仍然是一个常见的问题。例如,下图中大象的底部边缘和冲浪板的右侧边缘都很难定位。

这个问题对于轻量级检测模型来说更严重。缓解这个问题的一种方法是知识蒸馏(KD),它作为一种模型压缩技术,已经被广泛验证对通过传递大的教师模型学习到的广义知识来提高小的学生模型的性能有帮助。
对于目标检测中的知识蒸馏,之前的工作中已经指出原始的针对分类问题的logit mimicking效率低下,因为它只传递语义知识(即分类)而忽略了定位知识的重要性。因此现有的目标检测KD方法主要聚焦于加强师生之间深度特征的一致性,并利用各种imitation region进行蒸馏。下图展示了三种流行的目标检测KD pipeline
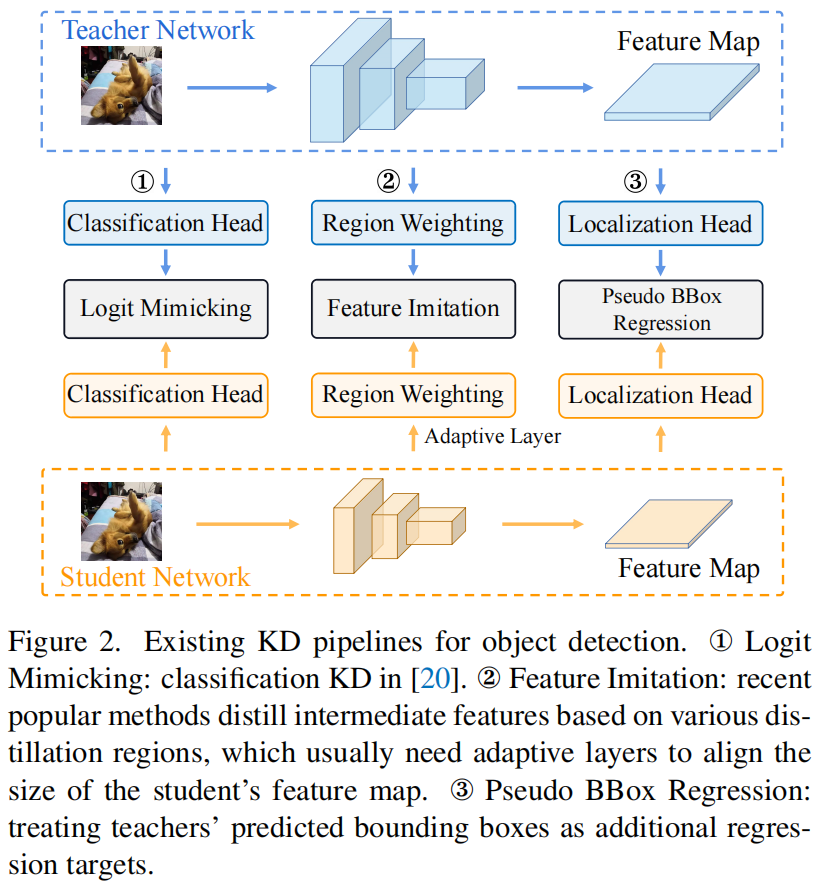
但是因为语义知识和定位知识在特征图上是混合的,很难判断传递每个位置的混合知识对性能的提升是否有帮助以及哪些区域有利于哪类知识的传递。
本文的创新点
针对上述问题,本文提出了一种的新的分治蒸馏策略,分别传递语义知识和定位知识。语义知识还是使用原始的分类Logit蒸馏。对于定位知识,本文重新制定了定位的知识传递过程,并通过将边界框转换成概率分布,提出了一种简单而有效的定位蒸馏(LD)方法。这与之前将教师网络的输出作为额外的回归目标的方法不同(如图2中的Pseudo BBox Regression)。得益于概率分布的表示,本文提出的LD可以有效地将教师网络学到的丰富的定位知识传递给学生模型。此外,基于提出的分治蒸馏策略,作者进一步提出了有价值定位区域(Valuable Localization Region, VLR)来帮助判断哪些区域有助于分类学习哪些区域有助于定位学习。通过实验,本文第一次证明了原始的logit mimicking比feature imitation的效果更好,而且定位知识比语义知识更重要更有效。
方法介绍
Preliminaries
对于一个给定的边界框 \(\mathcal{B}\),传统的表示方法有两种形式即 \(\left \{ x,y,w,h \right \} \)(中心点的坐标和宽高)和 \(\left \{ t,b,l,r \right \} \)(采样点到上下左右边界的距离),这两种形式遵循狄拉克分布只关注ground truth的标签位置而无法建模模糊的边界框即图1中的情况。本文使用General Focal Loss中提出的边界框的概率分布表示(关于GFL的介绍可见Generalized Focal Loss 原理与代码解析),它可以更全面的描述边界框定位的不确定性。设 \(e\in \mathcal{B}\) 表示边界框的一条边,它的值可以表示为如下形式

其中 \(x\) 是回归坐标范围是 \([e_{min},e_{max}]\),\(Pr(x)\) 是对应的概率。传统的狄拉克分布表示是上式的特殊形式:当 \(x=e^{gt}\) 时 \(Pr(x)=1\),否则 \(Pr(x)=0\)。通过将连续的回归区间 \([e_{min},e_{max}]\) 转换成均匀离散变量的形式 \(\mathbf{e}=[e_{1},e_{2},...,e_{n}]^{T}\in \mathbb{R}^{n}\),其中 \(e_{1}=e_{min}\),\(e_{n}=e_{max}\),共有 \(n\) 个子区间。给定边界框的每条边都可以用SoftMax函数表示为概率分布。
Localization Distillation
本文提出的LD是从边界框的概率分布表示演变而来的,它最初是为了通用目标检测而设计的,并且携带了丰富的定位信息。图1中的模糊边缘和清晰边缘会分别反映在分布的平整度flatness和尖锐度sharpness上。LD的完整结构如下图所示
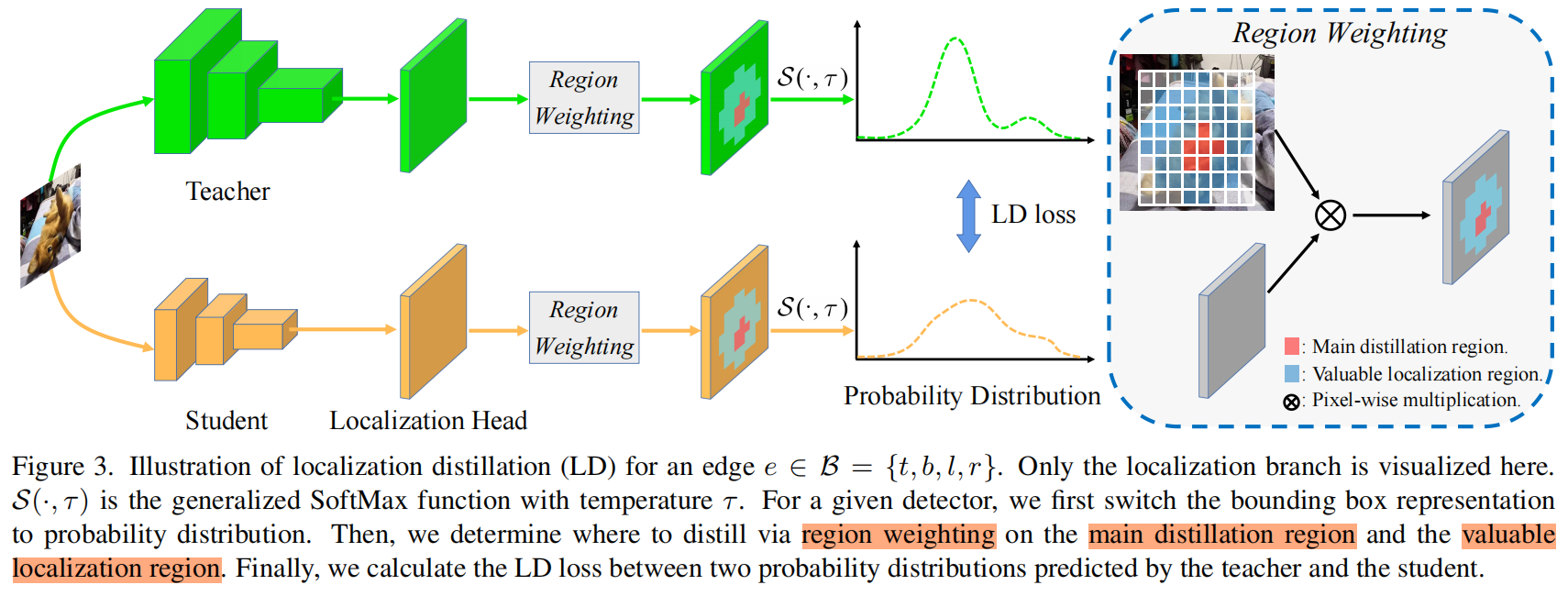
给定一个任意的检测模型,首先将bounding box的表示转换成概率分布的形式,本文选择 \(\mathcal{B}=\left \{ t,b,l,r \right \} \) 作为基本形式,因此当给的是 \(\left \{ x,y,w,h \right \} \) 的形式时先将其转换成 \(\left \{ t,b,l,r \right \} \)。设 \(z\) 为定位头localization head对边 \(e\) 的所有可能位置的预测的 \(n\) 个logits,教师和学生网络分别用 \(z_{T}\) 和 \(z_{S}\) 表示,我们用generalized SoftMax函数 \(\mathcal{S}\left ( \cdot ,\tau \right ) =SoftMax\left ( \cdot/\tau \right ) \) 将 \(z_{T}\) 和 \(z_{S}\) 转换成概率分布 \(p_{T}\) 和 \(p_{S}\)。注意当 \(\tau=1\) 时就等价于原始的softmax函数。当 \(\tau\to 0\) 时它趋向于狄拉克分布,当 \(\tau\to \infty \) 时它趋向于均匀分布。根据经验设置 \(\tau>1\) 来使分布更加平滑,并且使概率分布包含更多信息。通过下式计算两个分布 \(p_{T},p_{S}\in \mathbb{R}^{n}\) 之间的相似度来进行定位蒸馏

其中 \(\mathcal{L}_{KL}\) 表示KL散度损失。然后对边界框 \(\mathcal{B}\) 的四条边的LD可按下式得到

Valuable Localization Region
之前的工作大多通过最小化 \(l_{2}\) 损失来迫使学生网络mimic教师网络的深度特征,但有一个问题:我们是否应该不加判断的利用整个imitation region来提取混合知识?答案是否,之前已经有工作指出知识的分布模式在分类和定位中是不同的。因此,本文提出了有价值定位区域(valueblae localization region, VLR)来进一步提高蒸馏的效率。具体而言,将蒸馏区域划分为主要蒸馏区域main distillation region和有价值蒸馏区域valuable distillation region。主要蒸馏区域直觉上可以根据标签分配label assignment直接确定,即检测头中的positive locations。有价值蒸馏区域可以通过下面的Algorithm 1得到

首先,对于FPN的第 \(l\) 层,我们计算所有anchor box \(\mathbf{B}^{a}_{l}\) 和所有gt box \(\mathbf{B}^{gt}\) 之间的DIoU矩阵 \(\mathbf{X}_{l}\)。然后,设定DIoU的阈值下限 \(\alpha_{vl}=\gamma\alpha_{pos}\),其中 \(\alpha_{pos}\) 是标签分配中正样本的IoU阈值。VLR可以定义成 \(\mathbf{V}_{l}=\left \{ \alpha_{vl}\leqslant \mathbf{X}_{l}\leqslant\alpha_{pos} \right \} \)。我们的方法只有一个超参 \(\gamma\),它控制着VLR的范围。当 \(\gamma=0\) 时,所有DIoU满足 \(0\leqslant x_{i_{l}j}\leqslant \alpha_{pos}\) 的位置都作为VLRs。当 \(\gamma \to 1 \) 时,VLR逐渐缩小为空。这里我们使用DIoU,因为它给予靠近对象中心的位置更高的优先级。
Overall Distillation Process
训练学生网络的完整损失函数如下
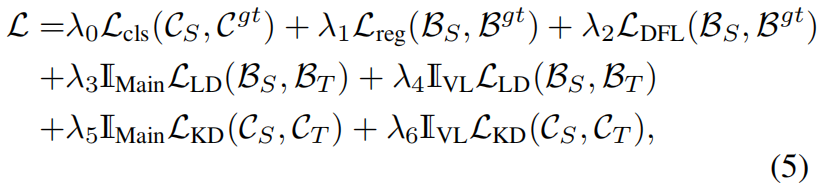
其中前三项是基于回归的检测模型中分类和回归分支原本的损失项,\(\mathcal{L}_{cls}\) 是分类损失,\(\mathcal{L}_{reg}\) 是边界框回归损失,\(\mathcal{L}_{DFL}\) 是distribution focal loss。\(\mathbb{I}_{Main}\) 和 \(\mathbb{I}_{VL}\) 分别是主要蒸馏区域和有价值蒸馏区域的mask,\(\mathcal{L}_{KD}\) 是KD loss,\(\mathcal{C}_{S}\) 和 \(\mathcal{C}_{T}\) 分别是学生网络和教师网络分类头的输出logit,\(\mathcal{C}^{gt}\) 是样本类别标签。所有的蒸馏损失项都根据其类型用相同的权重进行加权,例如LD损失遵循边框回归,KD遵循分类。此外值得一提的是,因为LD损失具有足够的指导能力,DFL损失可以舍去。
实验结果
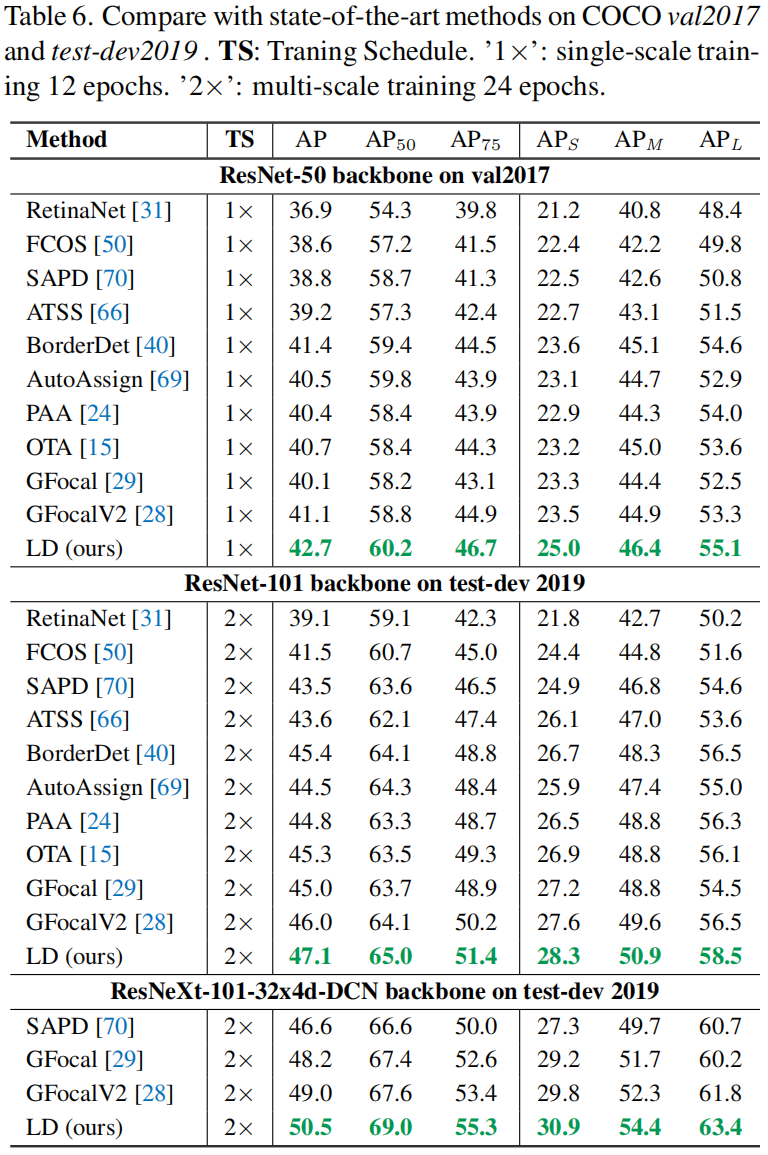
Comparison with the State-of-the-Arts
代码解析
以mmdetection的实现为例,在mmdetection/mmdet/models/detectors/kd_one_stage.py中,提取了教师网络的head输出out_teacher
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
"""
Args:
img (Tensor): Input images of shape (N, C, H, W).
Typically these should be mean centered and std scaled.
img_metas (list[dict]): A List of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
:class:`mmdet.datasets.pipelines.Collect`.
gt_bboxes (list[Tensor]): Each item are the truth boxes for each
image in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): Class indices corresponding to each box
gt_bboxes_ignore (None | list[Tensor]): Specify which bounding
boxes can be ignored when computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
x = self.extract_feat(img) # (2,3,300,300)
# [(2,256,38,38),(2,256,19,19),(2,256,10,10),(2,256,5,5),(2,256,3,3)]
with torch.no_grad():
teacher_x = self.teacher_model.extract_feat(img)
# [(2,256,38,38),(2,256,19,19),(2,256,10,10),(2,256,5,5),(2,256,3,3)]
out_teacher = self.teacher_model.bbox_head(teacher_x)
# ([(2,20,38,38),(2,20,19,19),(2,20,10,10),(2,20,5,5),(2,20,3,3)],
# [(2,68,38,38),(2,68,19,19),(2,68,10,10),(2,68,5,5),(2,68,3,3)])
losses = self.bbox_head.forward_train(x, out_teacher, img_metas,
gt_bboxes, gt_labels,
gt_bboxes_ignore)
return losses
在mmdetection/mmdet/models/dense_heads/ld_head.py的Line 121调用ld loss,其中soft_corners就是上面的out_teacher[1]取pos_inds后的输出
# ld loss
loss_ld = self.loss_ld(
pred_corners,
soft_corners,
weight=weight_targets[:, None].expand(-1, 4).reshape(-1),
avg_factor=4.0)具体如下
def knowledge_distillation_kl_div_loss(pred,
soft_label,
T,
detach_target=True):
r"""Loss function for knowledge distilling using KL divergence.
Args:
pred (Tensor): Predicted logits with shape (N, n + 1).
soft_label (Tensor): Target logits with shape (N, N + 1).
T (int): Temperature for distillation.
detach_target (bool): Remove soft_label from automatic differentiation
Returns:
torch.Tensor: Loss tensor with shape (N,).
"""
assert pred.size() == soft_label.size()
target = F.softmax(soft_label / T, dim=1)
if detach_target:
target = target.detach()
kd_loss = F.kl_div(
F.log_softmax(pred / T, dim=1), target, reduction='none').mean(1) * (
T * T)
return kd_loss注意,在mmdet的实现中只实现了Main LD,即上面的pos_inds只考虑了Main Region,在原文中完整的蒸馏应该是Main KD + Main LD + VLR LD,这里需要参考官方实现https://github.com/HikariTJU/LD/issues/44。
另外,当检测模型是anchor-based时才可以按照文中计算DIoU矩阵的方式计算VLR,当模型是anchor-free时,VLR是全部的负样本区域。