📺 硬件
Nvidia Jetson Nano
Nvidia Jetson Nano是英伟达推出的深度学习开发板,性价比极高。本人也用过其他国产的深度学习开发板,比如某为的开发套件,难用的一批。Nvidia Jetson Nano上手及其容易,只要是有深度学习基础的人用起来和普通计算机一样,当然CPU的架构不同。但是所有深度学习代码都能在这上面跑,但是需要注意Nano的内存只有4G,性能并不是很好。
[官方Jetson Nano Developer Kit地址]
[Nvidia Jetson Nano官方镜像百度网盘下载地址] ❗ 提取码:sa5e ❗
官方的Nano镜像包含了CUDA10.1和OpenCV,其他的环境需要自己配置。另外并不建议Nano更换为国内源,国内并没有很好的Arm架构Ubuntu源。
💽 软件
要求
①识别类别2类:人和车(汽车、卡车等)。
②轻量化网络:在Nvidia Jetson Nano可以运行。
③当FPS减小时尽量提高网络精度。
网络结构可视化工具推荐

Netron是神经网络、深度学习和机器学习模型的可视化工具。Netron支持ONNX (.onnx, .pb, .pbtxt), Keras (.h5, .keras), Core ML (.mlmodel), Caffe (.caffemodel, .prototxt), Caffe2 (predict_net.pb, predict_net.pbtxt), MXNet (.model, -symbol.json), TorchScript (.pt, .pth), NCNN (.param) and TensorFlow Lite (.tflite)。Netron在实验上支持 PyTorch (.pt, .pth), Torch (.t7), CNTK (.model, .cntk), Deeplearning4j (.zip), PaddlePaddle (.zip, model), Darknet (.cfg), MNN (.mnn), scikit-learn (.pkl), ML.NET (.zip), TensorFlow.js (model.json, .pb) and TensorFlow (.pb, .meta, .pbtxt).
[Netron在线网络结构可视化工具]
[Netron网络结构可视化工具下载地址]
YOLO
[YOLO系列官方主页]
[YOLO:You Only Look Once系列的学习]
[轻量化卷积神经网络]
Nano很适合跑YOLO,不需要安装其他的深度学习框架,Nano上因为性能的限制不可能跑训练,所以建议在服务器上预先训练好网络,再在Nano上测试。所以我选择重新训练网络,首先是数据集,保留人和车类别,修改网络结构。
以下是目前取得的结果:
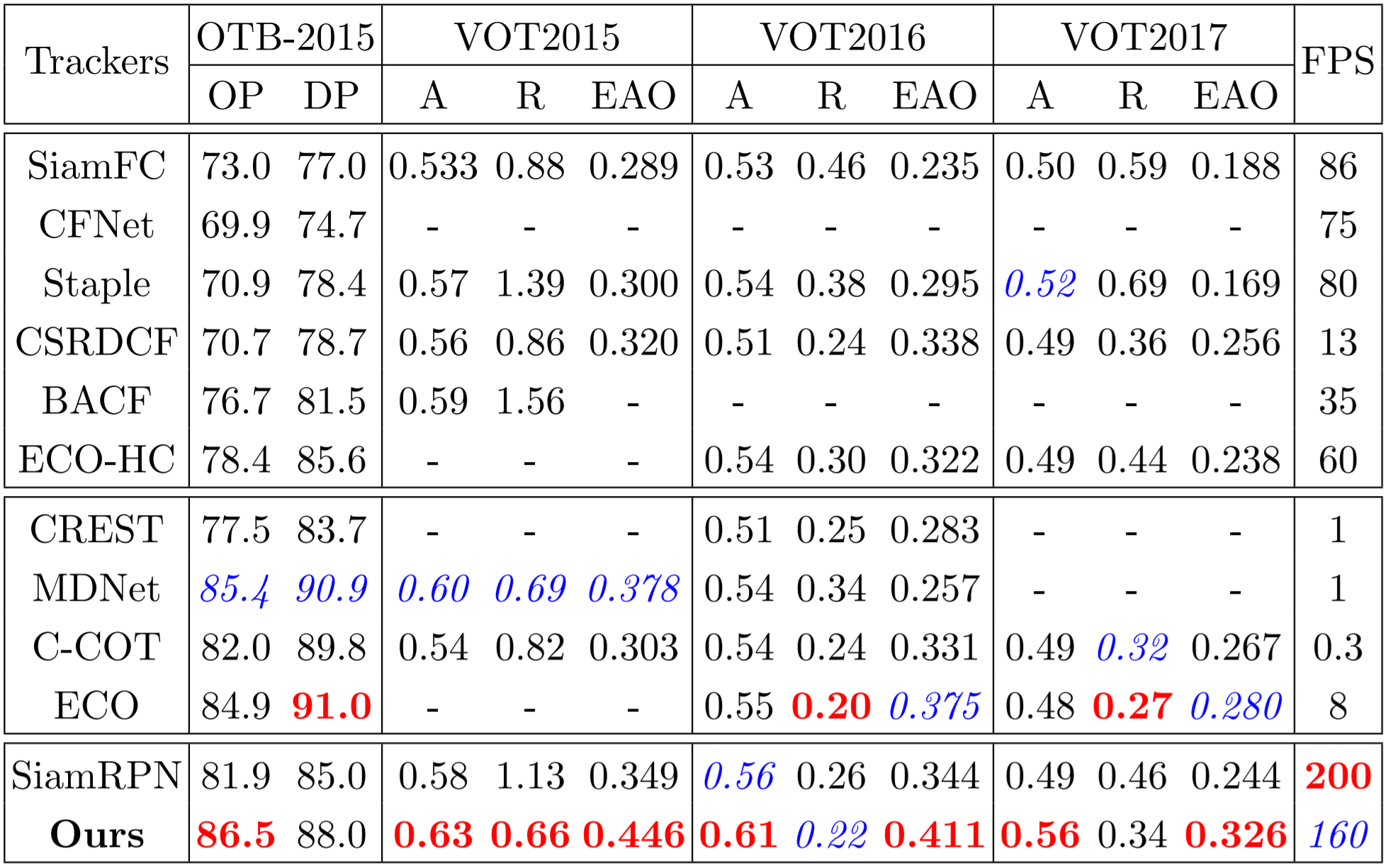
| name | Characteristic | AP(0.5) | AR(0.5:0.95) | Time | FPS(ON Nano) | cfg | weights | model structure | test result* |
|---|---|---|---|---|---|---|---|---|---|
| baseline | 基于官方YOLOv3_tiny的修改 | 0.532 | 0.338 | 76S | 10.0~11.0 | [cfg] | [weights] | [svg] | [coco.json] |
| muti_conv | 多维卷积 | 0.603 | 0.386 | 140S | 5.8~6.5 | [cfg] | [weights] | [svg] | [coco.json] |
| deep* | 深层网络,计算量稍大 | 0.753 | 0.508 | 394S | 1.9 ~ 2.0 | [cfg] oymg | [weights] itpz | [svg] | [coco.json] |
| deep_prune* | 深层网络的模型剪枝 | 0.720 | 0.479 | 273S | 2.9~3.1 | [cfg] | [weights] | [svg] | [coco.json] |
表中*注释的位置,23486_images是COCO2014的Val数据集经过处理的总数(仅包含人和各种车的类别),test result是此数据集的测试结果。deep网络结构参考自 [SlimYOLOv3] ,deep_prune参考自 [YOLOv3-model-pruning] ,测试的配置是RTX 2070。
具体步骤
baseline
在yolov3-tiny.cfg文件中,通过查找[yolo],找到网络结构的两个yolo层,
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=80
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
将其中的classes=80改为classes=2。注意这里还需要改两个地方,2个[yolo]结构前面的[convolutional]层的通道数需要修改: f i l t e r s = 3 × ( c l a s s e s + 5 ) filters=3×(classes+5) filters=3×(classes+5)也就是filters=21。
训练
运行:
./darknet detector train cfg/coco.data cfg/yolov3-tiny.cfg darknet53.conv.74
如果需要记录训练过程可以运行:
./darknet detector train cfg/coco.data cfg/yolov3-tiny.cfg darknet53.conv.74 >> train.txt
这样会记录下运行的过程但是不会在terminal中打印。
如果继续训练运行:
./darknet detector train cfg/coco.data cfg/yolov3-tiny.cfg backup/yolov3-tiny.backup
训练完成后会在backup文件夹中生成yolov3-tiny_final.weights文件。
测试
此测试只在COCO2014Val数据集上进行测试,本人未找到任何COCO2014Test数据集的标签数据。运行:
./darknet detector valid cfg/coco.data cfg/yolov3-tiny.cfg backup/yolov3-tiny_final.weights
运行结束后会在results文件夹下生成coco_results.json文件,并打印出:
Total Detection Time: 76.561128 Seconds
运行[coco_eval.py]。注意需要修改coco_eval.py文件中cocoGt_file、cocoDt_file的路径分别为下载的label.json路径和运行生成的coco_results.json文件。运行后会打印:
loading annotations into memory...
Done (t=1.45s)
creating index...
index created!
23443
Loading and preparing results...
DONE (t=2.25s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=22.27s).
Accumulating evaluation results...
DONE (t=1.07s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.249
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.532
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.208
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.057
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.292
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.482
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.127
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.299
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.338
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.137
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.401
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.579
应用
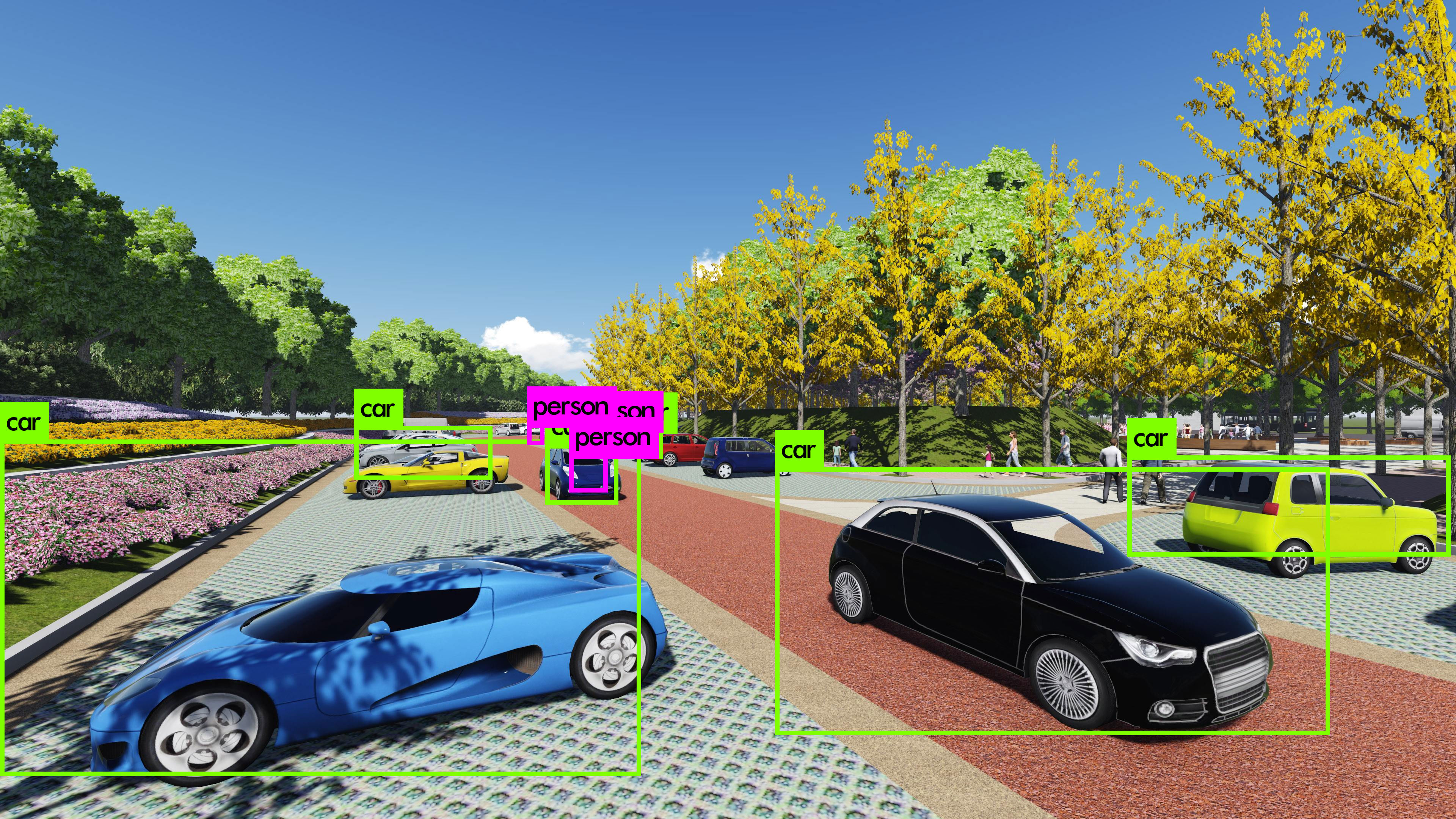
muti_conv
下载muti_conv的cfg文件,与baseline训练方法相同将yolov3-tiny.cfg改为muti_conv.cfg。
muti_conv的网络结构是受到[MixNet]的启发,对浅层的特征进行多维卷积提取,如下图所示:
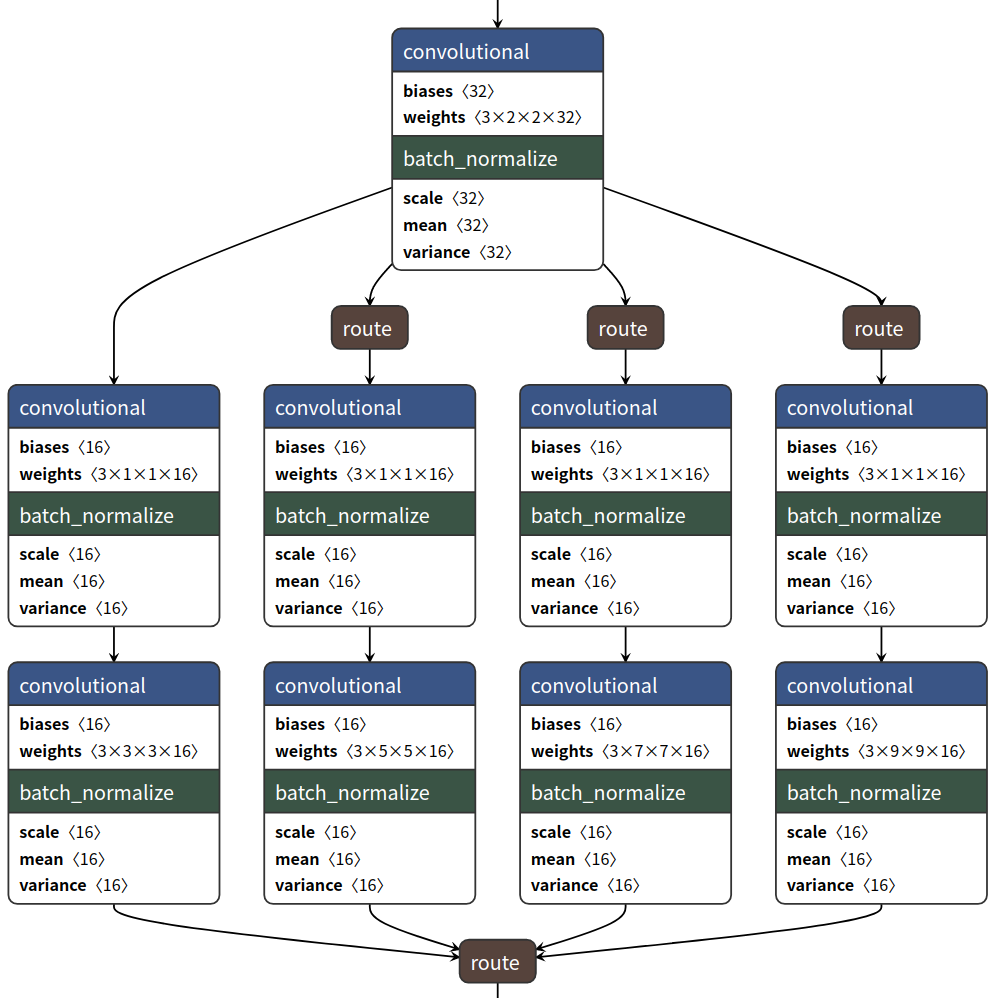
在原先yolov3-tiny中,只有3×3的卷积核,这里我引入了多维卷积核:3×3、5×5、7×7和9×9四种。并在之后结合更多维的特征。经过长时间的训练和测试后得到:
Total Detection Time: 140.834962 Seconds
loading annotations into memory...
Done (t=1.50s)
creating index...
index created!
23475
Loading and preparing results...
DONE (t=3.22s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=26.13s).
Accumulating evaluation results...
DONE (t=1.26s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.301
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.603
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.268
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.093
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.354
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.548
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.142
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.342
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.386
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.170
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.455
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.643
应用
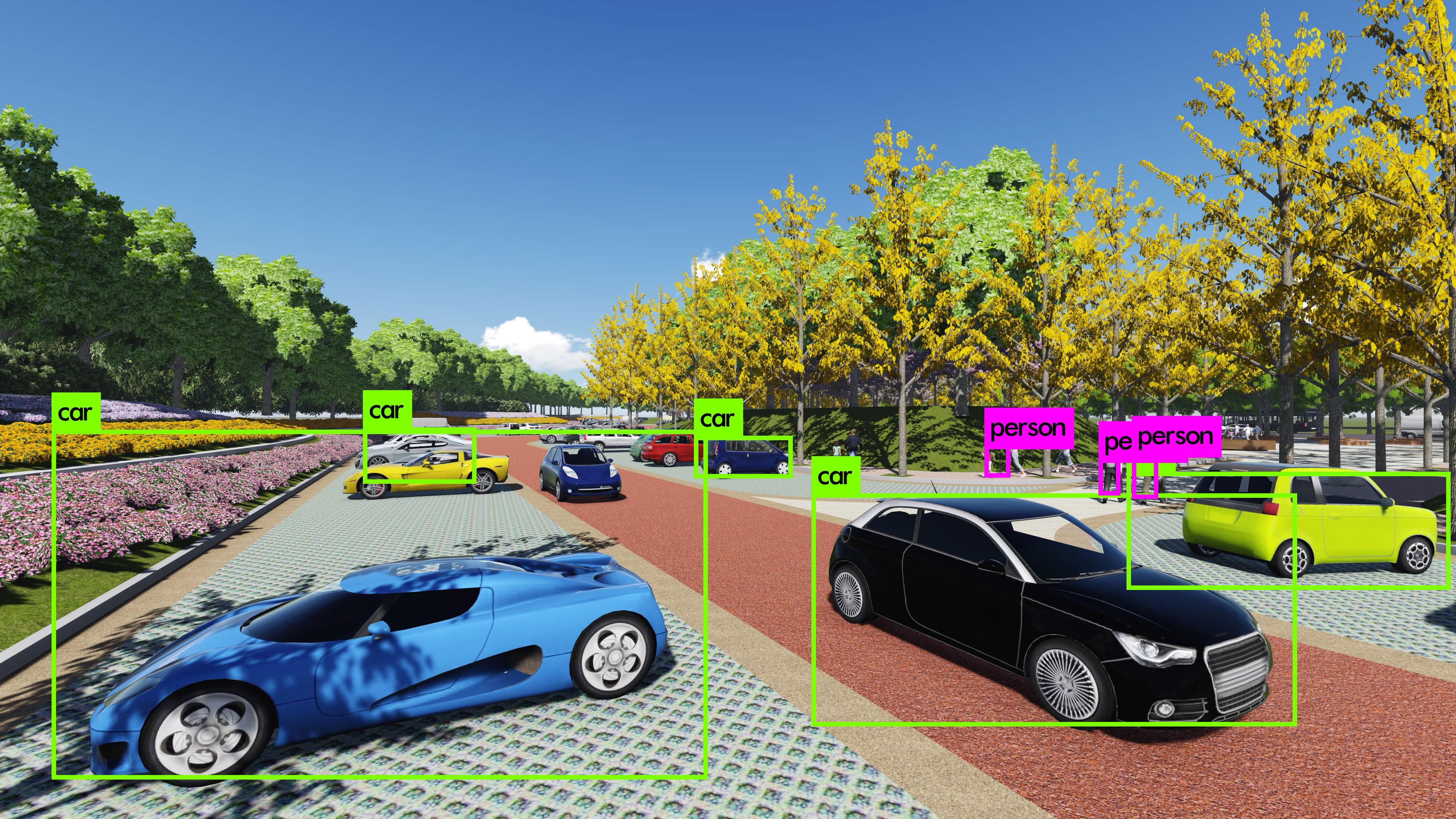
deep
deep网络的结构是参考了 [SlimYOLOv3] ,SlimYOLOv3是从YOLOv3-spp上经过模型剪枝得到,YOLOv3-spp由于计算量大、内存需求大不能在Nano上运行,但是SlimYOLOv3可以在Nano上以1.9 ~ 2.0帧/秒运行,极大的保证了准确率。SlimYOLOv3中采用了大量的残差模块,如下图所示:

不断的加深残差结构的数量保证了网络性能更好,经过训练和测试得到:
Total Detection Time: 394.622764 Seconds
loading annotations into memory...
Done (t=1.79s)
creating index...
index created!
23486
Loading and preparing results...
DONE (t=2.90s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=119.78s).
Accumulating evaluation results...
DONE (t=5.71s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.425
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.754
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.426
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.225
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.488
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.166
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.445
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.508
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.341
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.567
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.699
应用
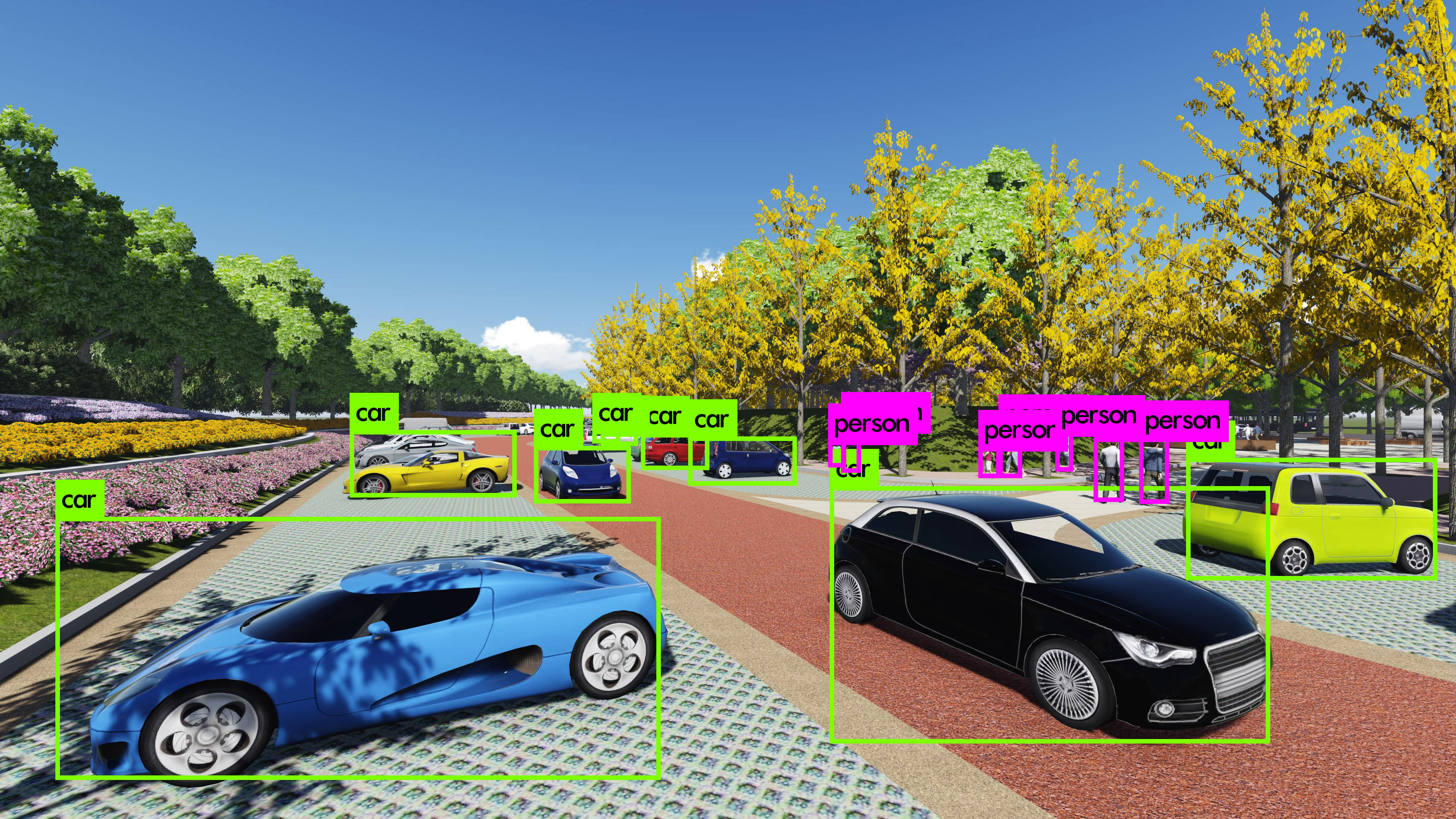
deep_prune
deep_prune网络的结构是参考自 [YOLOv3-model-pruning]。其相当于是对于deep网络的剪枝,网络深度和特征通道数减少,以至于其在Nano可以2.9~3.1帧/秒运行。
pythonTotal Detection Time: 273.457744 Seconds
loading annotations into memory...
Done (t=1.45s)
creating index...
index created!
23469
Loading and preparing results...
DONE (t=2.58s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=110.36s).
Accumulating evaluation results...
DONE (t=5.37s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.398
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.720
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.393
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.183
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.454
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.637
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.164
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.424
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.479
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.292
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.537
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.705
应用
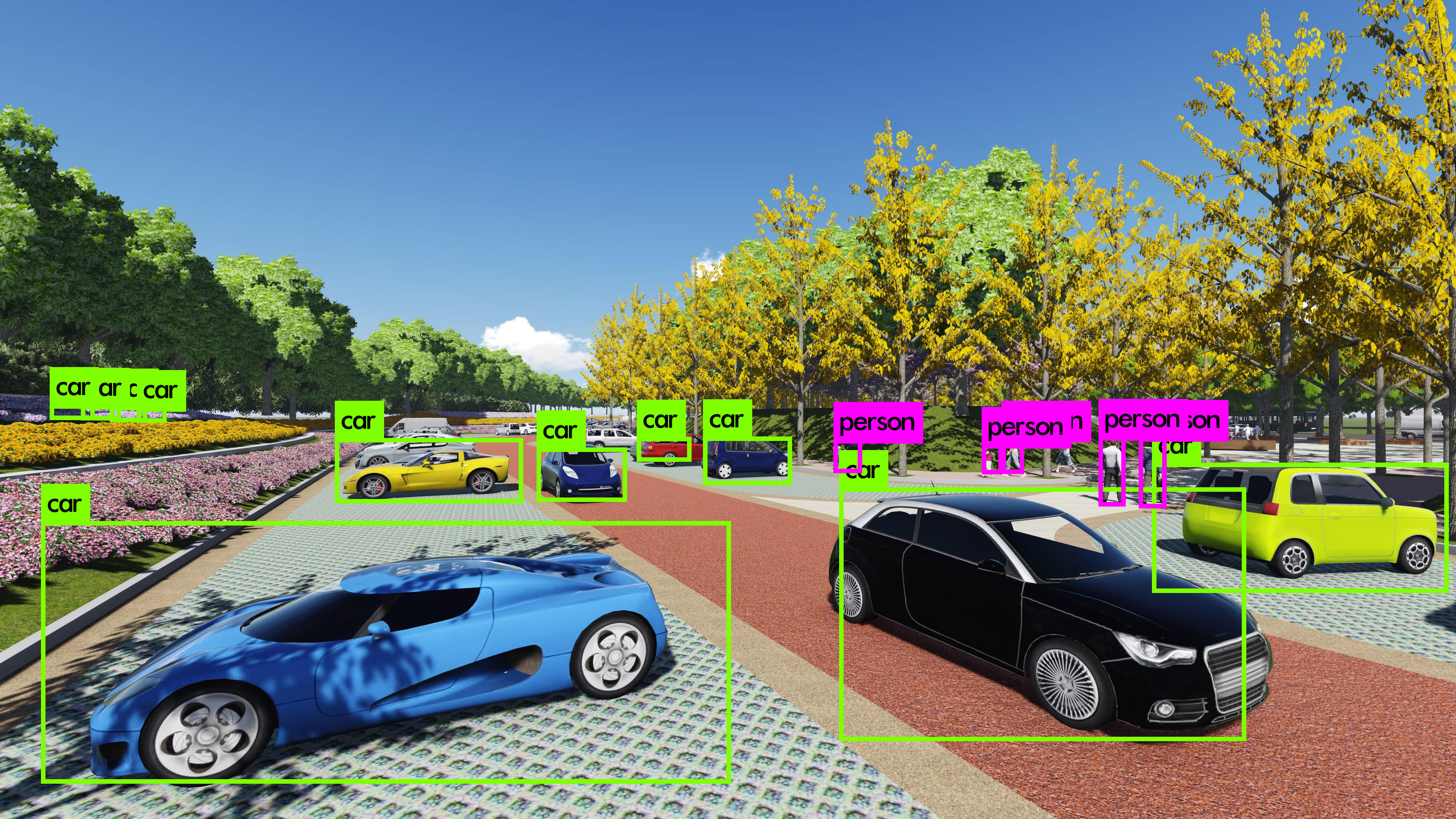
传送门
[目标检测]
[YOLO:You Only Look Once系列的学习]
[在Nvidia Jetson Nano上利用YOLO进行目标检测的实践过程]