Complex-Yolo网络模型的核心思想是用鸟瞰图BEV替换Yolo网络输入的RGB图像。因此,在完成BEV处理之后,模型的训练和推理过程基本和Yolo完全一致。Yolov4中输入的RGB图片的尺寸维度为608x608x3,因此BEV的尺寸维度也为608x608x3,由强度图、高度图和密度图组成。
Complex-Yolov4的数据处理部分详细介绍请参考:详细理解Complex-Yolo(Complex Yolov4)目标检测>三维目标检测算法 — 数据处理(一)_Coding的叶子的博客-CSDN博客。Yolov4的详细介绍网上已经有较多资料进行了详细分析,例如:yolov4的全面详解_无尽的沉默的博客-CSDN博客_yolov4。关于Yolov4的原理,本文不进行详细介绍,仅重点介绍一些需要改动的地方。
算法参考来源于Github上的Complex Yolov4,地址为:https://github.com/maudzung/Complex-YOLOv4-Pytorch。
1 模型数据输入
上一节http分析得出,数据处理后主要返回img_file、rgb_map、targets。假设Batch Size大小为B。img_file存储了image_2中对应图片的路径列表,长度为B。Rgb_map是维度为Bx3X608x608的BEV鸟瞰图。targets为真实标签,Mx8,M为目标总数量,真实标签target由8个维度组成,即batch_id、class_id、x、y、w、l、im、re。其中,x、y、w、l、rz转换成yolo格式,其中rz用欧拉公式转换为虚部(im)和实部(re)。
实际上,获取了鸟瞰图和真实值标签之后,就是一个完整的Yolo目标检测,可以应用在多种二维目标检测网络,不局限于Yolo系列。下面模型的描述部分也基本是对yolov4的描述。
2 锚框anchor设计
锚框基本原理:深度学习目标检测分为两类,即有锚框和无锚框。针对有锚框的目标检测,算法的思路大致是:(1)设计大量的锚框作为候选框;(2)对锚框进行分类和回归,得到最终的目标类别和位置。锚框分为正样本和负样本,正样本是指与真实目标框重叠超过指定阈值的锚框,反之负样本是指与真实目标框目标框重叠小于指定阈值的锚框。对于正样本锚框,我们需要计算其与真实目标框之间的偏差,包括中心坐标、长宽、角度等的偏差,算法回归是这个偏差就是需要回归得到的真实值。
Complex-Yolov4锚框设计:考虑在鸟瞰图视角下,同一类目标的长宽尺寸变化不大,但是目标存在方向信息,所以在设计锚框的时候,本文根据数据集内的外接框分布,定义了三种不同尺寸和两个角度方向:i)车辆尺寸(朝上);i i)车辆尺寸(朝下);i i i)自行车尺寸(朝上);i v)自行车尺寸(朝下);v)行人尺寸(朝左)。
锚框anchor的具体设计过程可以参考:三维点云目标检测 — VoxelNet详解之数据处理 (二)_Coding的叶子的博客-CSDN博客。
3 模型结构
模型的网路结构与Yolov4基本完全一致,其结构图如下所示。Yolov4的详细介绍网上已经有较多资料进行了详细分析,例如:https://blog.csdn.net/hgnuxc_1993/article/details/120724812。关于Yolov4的原理,本文不进行详细介绍,仅重点介绍一些需要改动的地方。
图片
(1)与Yolov4一样,每个位置设置三种尺寸的锚框。
(2)Yolov4针对COCO数据集是有80个类别,而Complex-Yolov4主要针对车辆、行人和自行车三种类别,因此预测类别置信度时占据三个维度。
(3)针对每一个锚框,共有10个维度输出,即x、y、w、h、im、re、conf、cls(3类)。

(4)模型最终输出维度为Bx22743x10,其中22743为锚框的个数,即76x76x3+38x38x3+19x19x3。
(5)在损失函数方面,Complex-Yolo将角度利用欧拉变换转换成了实部和虚部,因次损失函数增加了角度损失。
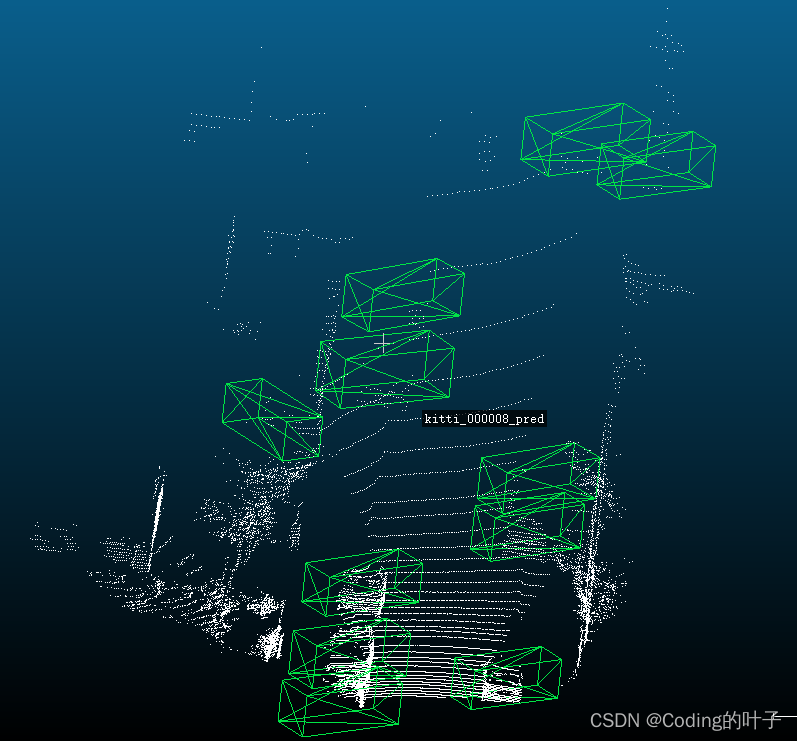
4 预训练模型检测效果可视化
预训练模型下载地址为https://drive.google.com/drive/folders/16zuyjh0c7iiWRSNKQY7CnzXotecYN5vc,如果这个地址下载不了,csdn中的下载地址为:complex_yolov4_pytorch预训练模型-深度学习文档类资源-CSDN下载。
运行命令如下:
python test.py --gpu_idx 0 --pretrained_path ../checkpoints/complex_yolov4/complex_yolov4_mse_loss.pth --cfgfile ./config/cfg/complex_yolov4.cfg --show_image 
5 python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_python三维点云重建
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。