文章目录
- 一、背景
- 二、方法
- 2.1 scale-aware attention
- 2.2 spatial-aware attention
- 2.3 task-aware attention
- 2.4 总体过程
- 2.5 和现有的检测器适配
- 2.6 和其他注意力机制的关联
- 三、效果
- 四、代码

论文链接: https://arxiv.org/pdf/2106.08322.pdf
代码链接:https://github.com/microsoft/DynamicHead
出处: CVPR 2021
一、背景
将目标检测中的定位和分类头统一起来一直是一个引人关注的问题,之前的工作尝试了很多方法,但是一直没有得来一个一致的形式。所以,如何提升目标检测头的性能也是一个重要的问题。
主要难点在于:
- head 应该 scale-aware,因为一个图像中会出现多个不同尺度的目标
- head 应该 spatial-aware,因为目标都是在不同视角下的,会有不同形状、角度、位置
- head 应该 task-aware,因为目标可以有多种不同的表达,如bbox、center、corner points,其目标函数和优化方法都是不同的
所以本文中,作者提出了一种新的检测头——dynamic head,来将 scale-awareness, spatial-awareness, task-awareness 进行统一。
假设从 backbone 输出的特征图为 l e v e l × s p a c e × c h n n e l level \times space \times chnnel level×space×chnnel,则统一的检测头可以看成一个 attention learning 问题。如果直接使用 self-attention 的话,计算复杂度很高。
所以,作者将注意力进行了拆分:
- level-wise:scale-aware attention module 在该维度使用,能够学习语义层面的相对重要程度,可以基于尺度来加强每个目标的特征
- spatial-wise:spatial-aware attention module 在该维度使用( h e i g h t × w i d t h height \times width height×width),能够在空间位置上学习有区分力的特征表达
- channel-wise:task-aware attention module 在该维度使用,能够指导不同通道的特征为不同的任务出力(分类、回归、中心点等)。
二、方法
作者针对 detection head 提出了一种统一的 attention mechanism,在 COCO 上提升了1.2%~3.2% 的 AP 。
从 backbone 输出的 L 层多尺度特征图为: F i n = { F i } i = 1 L F_{in}=\{F_i\}_{i=1}^L Fin={Fi}i=1L
- 将这些特征图全都 resize 到中间尺度特征图大小
- 得到四维特征图: F ∈ R L × H × W × C F \in R^{L \times H \times W \times C} F∈RL×H×W×C
- 将上面的四维特征图 reshape 成三维的: F ∈ R L × S × C F \in R^{L \times S \times C} F∈RL×S×C
这三个维度分别有如下表示:
- 不同的 level L L L:不同尺度的目标其实是和不同尺度的层相对应的,根据不同尺度来提升特征学习表达,有利于目标检测的 scale-awareness。
- 不同的空间位置 S S S:提升特征图中不同位置的特征学习,能够提升目标检测的 spatial-awareness
- 不同的任务 C C C:不同的任务其实和不同的 channel 是挂钩的,提升不同 channel 的特征表达能力能够提升目标检测的 task-awareness
三维特征为 F ∈ R L × S × C F \in R^{L \times S \times C} F∈RL×S×C,则通用 self-attention 的形式如下:
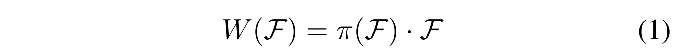
- 其中 pai 为 attention 函数,但传统的方法计算量和显存占用都很大
所以,作者将其拆分为3个串行的 attention,每个子 attention 仅关注单个维度:
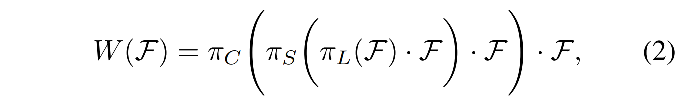
2.1 scale-aware attention
作者首先使用 scale-aware attention 来动态的聚合不同尺度的特征,基于其语义重要性:
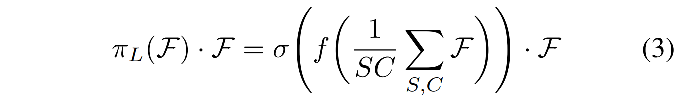
- f ( . ) f(.) f(.) 是线性函数,使用 1x1 卷积实现
- σ ( x ) = m a x ( 0 , m i n ( 1 , x + 1 2 ) ) \sigma(x)=max(0,min(1, \frac{x+1}{2})) σ(x)=max(0,min(1,2x+1)),是一个 hard-sigmoid 函数
2.2 spatial-aware attention
作者基于融合的特征来使用 spatial-aware attention,来让网络更关注于共现于空间位置和特征层级上的突变区域。
考虑到 S 的维度很大,作者分解为了两个步骤:
- 首先,使用可变形卷积,让 attention 学习稀疏特征
- 然后,将不同尺度特征图上的相同位置的特征进行聚合
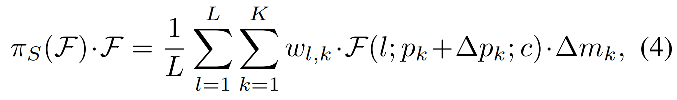
- K 是 sparse sampling location 的数量
- p k + Δ p k p_k+\Delta p_k pk+Δpk 是自学习的空间偏移 Δ p k \Delta p_k Δpk ,注意到突变区域
- Δ m k \Delta m_k Δmk 是位置 p k p_k pk 上的自学习得到的重要性标量
2.3 task-aware attention
为了联合学习,并且归纳不同目标的表达方式,作者在最后使用了 task-aware attention,能够动态的针对不同 task 来控制每个 channel 的开关。
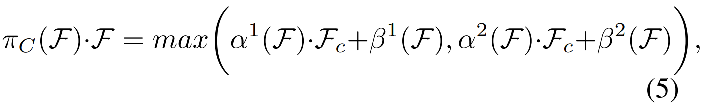
- F c F_c Fc 是第 c 个 channel 上的切片
- [ α 1 , α 2 , β 1 , β 2 ] = θ ( . ) [\alpha^1, \alpha^2, \beta^1, \beta^2]=\theta(.) [α1,α2,β1,β2]=θ(.) 是超参数,学习控制激活阈值, θ ( . ) \theta(.) θ(.) 首先在 L × S L\times S L×S 使用全局平均池化降低维度,然后使用两个全连接层、一个归一化层、一个sigmoid,归一化到 [-1,1]。
2.4 总体过程
因为上述三个步骤是串联进行的,所以,能够多次使用公式二,来堆叠多个 attention blocks,如图 2a 所示。

整个方法的总体框架如图 1 所示,可以使用任何 backbone 来生成多尺度金字塔特征图,然后resize,生成 3 维特征图,输入本文提出的 dynamic head。
然后,使用多个 block 进行特征提取。
dynamic head 的输出可以用于不同任务。
如图 1 所示,从 backbone 输出的特征图有很多噪声,由于和预训练的 ImageNet 的域不同,经过 scale-aware attention module 后,特征图对不同尺度的前景有更好的响应。经过 spatial-aware attention module 后,特征图更加稀疏,并且能聚焦于前景目标的突变区域。经过 task-aware attention module 后,特征图会基于不同的下游任务来被重新调整。

2.5 和现有的检测器适配
1、单阶段检测器
单阶段检测器中,一般都是使用 backbone 来抽取密集特征,然后使用多个子网络头来实现不同的任务。
但是,目标分类子网络和位置回归子网络其实有很大不同
所以,使用本文作者提出的动态 attention module,能够灵活的适用于不同任务,如图2b所示。
2、两阶段检测器
量阶段检测器会使用 ROI-pooling 来抽取提议区域,所以首先在 ROI-pooling 之前使用 scale 和 spatial attention,然后使用 task attention 来代替全连接层,如图 2c 所示。
2.6 和其他注意力机制的关联
1、Deformable
可变形卷积能够通过引入 sparse sampling 来提高效果,大多应用于 backbone 中来提高特征的表达能力,很少用于检测头。
2、Non-local
Non-local 一般被用来建立长距离依赖关系,可以看做是建立本文中 L × S L \times S L×S 的关系
3、Transformer
Transformer 类似于建立 S × C S \times C S×C 的关系
也就是说,这三个 attention 机制都建立了局部的 attention,所以,本文相当于高效的实现了将多个不同的维度结合的事情。
三、效果
1、消融实验验证每个维度 attention 的效果

- 单独使用 level、spatial、channel attention,分别能带来 0.9、2.4、1.3 AP 的提升。
- 联合使用 L+S ,提升了 2.9 AP
- 联合使用三个 attention,共提升了 3.6 AP。
2、消融实验验证每个维度 attention 学习到的东西

图 3 展示了 scale-aware module 的不同 level 的 scale ratio 的趋势,scale ratio 是使用高分辨率图的学习权重除以低分辨率图的学习权重得到的,数据集为 coco val2017。
可以看出,scale-aware attention 模块会调节高分辨率图向低分辨率图,低分辨率图向高分辨率图,来平滑尺度的不同。这足以证明 scale-aware attention 的学习能力。

图 4 展示了使用不同数量的 attention 模块的效果,使用 attention 模块之前,特征图有更多的噪声,且难以注意到前景目标。使用 attention 模块之后,网络会更加注意到前景目标上和突变区域位置,这足以证明 spatial-aware attention 的学习能力。
3、Head 深度的探索
作者验证了不同 dynamic head 深度的效果,并且对比了其效果和计算量,如表 2 所示。
head 效果可以提升,直到数量上升到 8,并且增加的计算量可以忽略不计。

4、和现有目标检测器的适配
作者将其应用到了 RCNN、RetinaNet、ATSS、FCOS、ReoPoints,普遍带来了 1.2~3.2 AP 的提升。

5、和 SOTA 的比较



四、代码
以 ATSS 代码为例
- 输入图像假设为: [4, 3, 896, 1152]
- 经过 backbone 得到金字塔特征图,取 p3-p7:[4, 256, 112, 160], [4, 256, 56, 80], [4, 256, 28, 40], [4, 256, 14, 20], [4, 256, 7, 10]
- 将该金字塔特征图输入 dynamic head:
import torch
import torch.nn.functional as F
from torch import nn
from detectron2.modeling.backbone import Backbone
from .deform import ModulatedDeformConv
from .dyrelu import h_sigmoid, DYReLU
class Conv3x3Norm(torch.nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(Conv3x3Norm, self).__init__()
self.conv = ModulatedDeformConv(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn = nn.GroupNorm(num_groups=16, num_channels=out_channels)
def forward(self, input, **kwargs):
x = self.conv(input.contiguous(), **kwargs)
x = self.bn(x)
return x
class DyConv(nn.Module):
def __init__(self, in_channels=256, out_channels=256, conv_func=Conv3x3Norm):
super(DyConv, self).__init__()
self.DyConv = nn.ModuleList()
self.DyConv.append(conv_func(in_channels, out_channels, 1))
self.DyConv.append(conv_func(in_channels, out_channels, 1))
self.DyConv.append(conv_func(in_channels, out_channels, 2))
self.AttnConv = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, 1, kernel_size=1),
nn.ReLU(inplace=True))
self.h_sigmoid = h_sigmoid()
self.relu = DYReLU(in_channels, out_channels)
self.offset = nn.Conv2d(in_channels, 27, kernel_size=3, stride=1, padding=1)
self.init_weights()
def init_weights(self):
for m in self.DyConv.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, 0, 0.01)
if m.bias is not None:
m.bias.data.zero_()
for m in self.AttnConv.modules():
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, 0, 0.01)
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
next_x = {}
feature_names = list(x.keys()) # ['p3', 'p4', 'p5', 'p6', 'p7']
# [4, 256, 112, 160], [4, 256, 56, 80], [4, 256, 28, 40], [4, 256, 14, 20], [4, 256, 7, 10]
for level, name in enumerate(feature_names):
feature = x[name]
offset_mask = self.offset(feature) # [4, 27, 112, 160]
offset = offset_mask[:, :18, :, :] # [4, 18, 112, 160]
mask = offset_mask[:, 18:, :, :].sigmoid() # [4, 9, 112, 160]
conv_args = dict(offset=offset, mask=mask)
temp_fea = [self.DyConv[1](feature, **conv_args)] # [4, 256, 112, 160]
# level=0: len(temp_fea)=2, temp_fea 是 level 0、level 1 特征组合得到的
# level=1: len(temp_fea)=3, temp_fea 是 level 0、level 1 和 level 2 特征组合得到的
# level=2: len(temp_fea)=3, temp_fea 是 level 1、level 2 和 level 3 特征组合得到的
# level=3: len(temp_fea)=3, temp_fea 是 level 2、level 3 和 level 4 特征组合得到的
# level=4: len(temp_fea)=2, temp_fea 是 level 3、level 4 特征组合得到的
if level > 0:
temp_fea.append(self.DyConv[2](x[feature_names[level - 1]], **conv_args))
if level < len(x) - 1:
temp_fea.append(F.upsample_bilinear(self.DyConv[0](x[feature_names[level + 1]], **conv_args),
size=[feature.size(2), feature.size(3)])) # len(temp_fea)=2, temp_fea[0]=temp_fea[1]=[4, 256, 112, 160]
attn_fea = []
res_fea = []
for fea in temp_fea:
res_fea.append(fea) # len=2, res_fea[0] = [4, 256, 112, 160]
attn_fea.append(self.AttnConv(fea)) # attn_fea[0] =[4, 1, 1, 1]
res_fea = torch.stack(res_fea) # level=0: [2, 4, 256, 112, 160], level=1: [3, 4, 256, 56, 80],
spa_pyr_attn = self.h_sigmoid(torch.stack(attn_fea)) # [2, 4, 1, 1, 1]
mean_fea = torch.mean(res_fea * spa_pyr_attn, dim=0, keepdim=False) # [4, 256, 112, 160]
next_x[name] = self.relu(mean_fea)
return next_x # [4, 256, 112, 160], [4, 256, 56, 80], [4, 256, 28, 40], [4, 256, 14, 20], [4, 256, 7, 10]
class DyHead(Backbone):
def __init__(self, cfg, backbone):
super(DyHead, self).__init__()
self.cfg = cfg
self.backbone = backbone
in_channels = cfg.MODEL.FPN.OUT_CHANNELS
channels = cfg.MODEL.DYHEAD.CHANNELS
dyhead_tower = []
for i in range(cfg.MODEL.DYHEAD.NUM_CONVS):
dyhead_tower.append(
DyConv(
in_channels if i == 0 else channels,
channels,
conv_func=Conv3x3Norm,
)
)
self.add_module('dyhead_tower', nn.Sequential(*dyhead_tower))
self._out_feature_strides = self.backbone._out_feature_strides
self._out_features = list(self._out_feature_strides.keys())
self._out_feature_channels = {k: channels for k in self._out_features}
self._size_divisibility = list(self._out_feature_strides.values())[-1]
@property
def size_divisibility(self):
return self._size_divisibility
def forward(self, x):
x = self.backbone(x)
dyhead_tower = self.dyhead_tower(x)
return dyhead_tower
(dyhead_tower): Sequential(
(0): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(2): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(3): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(4): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(5): DyConv(
(DyConv): ModuleList(
(0): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(1): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=1, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
(2): Conv3x3Norm(
(conv): ModulatedDeformConv(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=2, dilation=1, padding=1, groups=1, deformable_groups=1, bias=True)
(bn): GroupNorm(16, 256, eps=1e-05, affine=True)
)
)
(AttnConv): Sequential(
(0): AdaptiveAvgPool2d(output_size=1)
(1): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace=True)
)
(h_sigmoid): h_sigmoid(
(relu): ReLU6(inplace=True)
)
(relu): DYReLU(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=256, out_features=64, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=64, out_features=1024, bias=True)
(3): h_sigmoid(
(relu): ReLU6(inplace=True)
)
)
)
(offset): Conv2d(256, 27, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)